Syntactically-guided Information Maintenance in Sentence Comprehension
Pith reviewed 2026-05-25 06:15 UTC · model grok-4.3
The pith
Rational comprehenders use syntactic structure to selectively maintain information needed for future predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
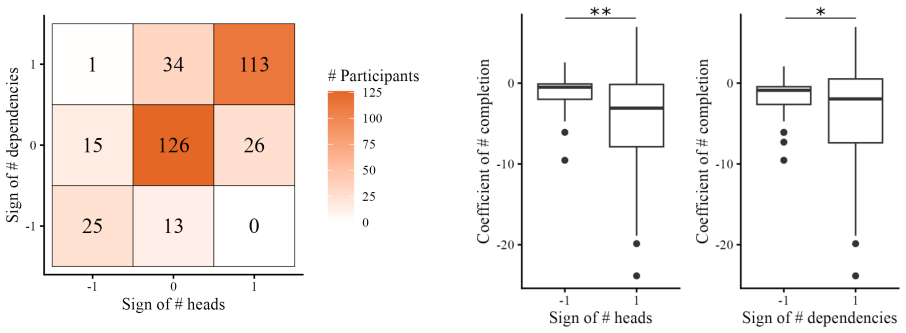
We hypothesize that rational language users selectively maintain information that is crucial for future prediction, guided by syntactic structure. Two factors affect maintenance cost: the number of predicted heads and the number of incomplete dependencies. Although these factors have been treated as competing hypotheses in the literature, our account predicts that they are not reducible to one another. We show this is the case in a naturalistic reading time dataset in Japanese. We further show that there is a tradeoff such that readers that slow down for maintenance tend to benefit more from predictability.
What carries the argument
Syntactically guided selective maintenance, where the number of predicted heads and incomplete dependencies separately determine what information is kept in working memory.
If this is right
- Maintenance costs increase separately with each additional predicted head and each additional incomplete dependency.
- The two factors cannot be reduced to a single underlying quantity.
- Readers who slow down for maintenance obtain greater processing benefits from high-predictability words.
- The separation and tradeoff are absent or undetectable in comparable English data.
Where Pith is reading between the lines
- Language-processing models should maintain separate counters for predicted heads and incomplete dependencies instead of a single memory-load variable.
- The account may account for why maintenance effects appear more clearly in head-final languages than in head-initial ones.
- Similar selective-maintenance logic could be tested in non-linguistic sequential tasks such as melody prediction or motor planning.
Load-bearing premise
The naturalistic Japanese reading-time dataset cleanly isolates maintenance costs from predicted heads and incomplete dependencies without confounds from other lexical or discourse factors.
What would settle it
A statistical result in the Japanese reading-time data showing that the effects of predicted heads and incomplete dependencies are indistinguishable from each other or that no positive correlation exists between maintenance slowdowns and predictability benefits.
Figures




read the original abstract
Maintaining information in context is essential in successful real-time language comprehension, but maintenance is cognitively costly and can slow processing. We hypothesize that rational language users selectively maintain information that is crucial for future prediction, guided by syntactic structure. Under this view, two factors affect maintenance cost: the number of predicted heads and the number of incomplete dependencies. Although these factors have been treated as competing hypotheses in the literature, our account predicts that they are not reducible to one another. We show this is the case in a naturalistic reading time dataset in Japanese, a language in which the two factors contrast particularly clearly. We further show that there is a tradeoff such that readers that slow down for maintenance tend to benefit more from predictability, providing additional support for the proposed account. These patterns are not evident in English, however, and we highlight some issues to be resolved to understand the contribution of syntax in memory-efficient processing of various languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript hypothesizes that rational language users selectively maintain information crucial for future prediction during sentence comprehension, with maintenance costs determined by two syntactic factors: the number of predicted heads and the number of incomplete dependencies. These factors are claimed to be non-reducible to one another. The authors report that this non-reducibility is supported by regression analysis on a naturalistic Japanese reading-time dataset (where the factors contrast clearly), along with evidence of a tradeoff such that readers who slow down for maintenance benefit more from predictability; the patterns are absent in English.
Significance. If the empirical results hold after appropriate controls, the work would provide a substantive contribution by offering a unified, syntax-guided account that reconciles previously competing maintenance hypotheses and demonstrates language-specific effects on memory-efficient processing.
major comments (1)
- [Abstract] Abstract, paragraph 3: The claim that the Japanese dataset supports non-reducibility of the two syntactic predictors rests on a regression yielding independent coefficients. However, the abstract supplies no information on the exact statistical model, the full set of covariates (lexical frequency, length, discourse factors, etc.), or collinearity diagnostics between predicted heads and incomplete dependencies. Without these, it is impossible to determine whether residual confounds prevent cleanly isolating the claimed independent contributions.
Simulated Author's Rebuttal
We thank the referee for their comments. We address the concern about statistical details in the abstract below. The full manuscript contains the requested information on the model and controls.
read point-by-point responses
-
Referee: [Abstract] Abstract, paragraph 3: The claim that the Japanese dataset supports non-reducibility of the two syntactic predictors rests on a regression yielding independent coefficients. However, the abstract supplies no information on the exact statistical model, the full set of covariates (lexical frequency, length, discourse factors, etc.), or collinearity diagnostics between predicted heads and incomplete dependencies. Without these, it is impossible to determine whether residual confounds prevent cleanly isolating the claimed independent contributions.
Authors: We agree that the abstract, as a concise summary, omits these specifics. The Methods section details the linear mixed-effects regression, including all covariates (log frequency, length, previous RT, discourse factors) and collinearity checks (VIF < 2 for both syntactic predictors). Both predictors show independent effects when modeled jointly. We will revise the abstract to note the regression model and standard controls used. revision: yes
Circularity Check
No circularity: non-reducibility shown via external empirical regression
full rationale
The paper's central claim is that an account of syntactically-guided maintenance predicts the number of predicted heads and incomplete dependencies are not reducible to one another, and this is demonstrated by regression coefficients on an external naturalistic Japanese reading-time dataset. No derivation step reduces a quantity to its own inputs by construction, no fitted parameter is relabeled as a prediction, and no load-bearing premise rests on self-citation chains. The result is self-contained against the external data benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rational language users selectively maintain information that is crucial for future prediction, guided by syntactic structure.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We hypothesize that rational language users selectively maintain information that is crucial for future prediction, guided by syntactic structure... two factors affect maintenance cost: the number of predicted heads and the number of incomplete dependencies.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery theorems unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show this is the case in a naturalistic reading time dataset in Japanese... there is a tradeoff such that readers that slow down for maintenance tend to benefit more from predictability.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Reading time and vocabu- lary rating in the Japanese language: Large-scale Japanese reading time data collection using crowd- sourcing. InProceedings of the 13th Language Re- sources and Evaluation Conference (LREC 2022), pages 5178–5187, Marseille, France. European Lan- guage Resources Association. Masayuki. Asahara, Hiroshi. Kanayama, Takaaki. Tanaka, Y...
work page 2022
-
[2]
InProceedings of the 11th International Conference on Language Resources and Evaluation (LREC 2018)
Universal Dependencies version 2 for Japanese. InProceedings of the 11th International Conference on Language Resources and Evaluation (LREC 2018). Masayuki Asahara, Kikuo Maekawa, Mizuho Imada, Sachi Kato, and Hikari Konishi
work page 2018
-
[3]
1965.Aspects of the theory of syntax
Noam Chomsky. 1965.Aspects of the theory of syntax. MIT Press. Morten H. Christiansen and Nick Chater
work page 1965
-
[4]
How linguis- tics learned to stop worrying and love the language models.Behavioral and Brain Sciences, page 1–98. Edward Gibson. 1991.A Computational Theory of Human Linguistic Processing: Memory Limitations and Processing Breakdown. Ph.D. thesis, Carnegie Mellon University. Edward Gibson
work page 1991
-
[5]
Predictive power of word surprisal for reading times is a linear function of language model quality. InProceedings of the 8th Workshop on Cognitive Modeling and Com- putational Linguistics (CMCL 2018), pages 10–18, Salt Lake City, Utah. Association for Computational Linguistics. Michael Hahn, Richard Futrell, Roger Levy, and Ed- ward Gibson
work page 2018
-
[6]
Information-Theoretic Storage Cost in Sentence Comprehension
Information-theoretic storage cost in sentence comprehension.arXiv preprint arXiv:2602.18217. Yuki Kamide and Don Mitchell
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Probabilistic Syntax. InProbabilistic Linguistics. The MIT Press. David Marr. 1982.Vision. WH Freeman, San Fransisco, CA. George A. Miller and Noam Chomsky
work page 1982
-
[8]
Release of pre-trained mod- els for the Japanese language. InProceedings of the 2024 Joint International Conference on Computa- tional Linguistics, Language Resources and Evalua- tion (LREC-COLING 2024). Edward. P. Stabler
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.