Knowledge Graph Representations for LLM-Based Policy Compliance Reasoning
Pith reviewed 2026-05-07 05:58 UTC · model grok-4.3
The pith
Knowledge graphs from policy documents improve large language models' accuracy on compliance reasoning tasks, with auto-discovered schemas matching formal ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Augmenting large language models with knowledge graphs built from AI policy documents improves performance on policy question-answering tasks. The gains appear across all five tested models and across tasks that require entity lookup, relation finding, and cross-policy inference. An open schema discovered by an LLM itself produces scores that match or exceed those from a hand-crafted formal ontology.
What carries the argument
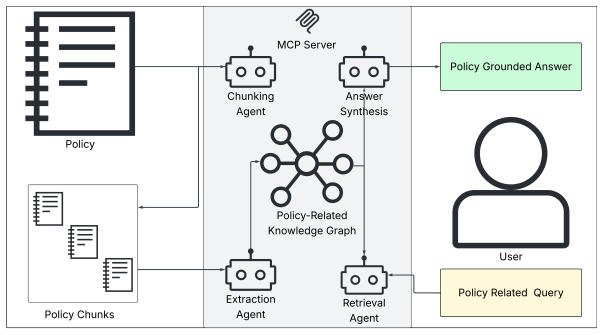
The agentic framework that extracts policy text into knowledge graphs under a chosen schema and retrieves relevant subgraphs to support the language model's answers to compliance questions.
Load-bearing premise
The 42 policy QA tasks and the combination of heuristic scoring with LLM-as-judge evaluation faithfully measure genuine policy compliance reasoning without artifacts from task design or judge bias.
What would settle it
Evaluating the same KG-augmented models on a fresh set of policy compliance questions created independently and scored by human experts would determine whether the reported improvements reflect real capability or depend on the original task and scoring setup.
Figures
read the original abstract
The risks posed by AI features are increasing as they are rapidly integrated into software applications. In response, regulations and standards for safe and secure AI have been proposed. In this paper, we present an agentic framework that constructs knowledge graphs (KGs) from AI policy documents and retrieves policy-relevant information to answer questions. We build KGs from three AI risk-related polices under two ontology schemas, and then evaluate five LLMs on 42 policy QA tasks spanning six reasoning types, from entity lookup to cross-policy inference, using both heuristic scoring and an LLM-as-judge. KG augmentation improves scores for all five models, and an open, LLM-discovered schema matches or exceeds the formal ontology.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an agentic framework that extracts knowledge graphs from three AI risk-related policy documents under both a formal ontology and an LLM-discovered schema. It then augments five LLMs with retrieved KG information and evaluates them on 42 policy QA tasks spanning six reasoning types (entity lookup to cross-policy inference), using both heuristic scoring and an LLM-as-judge. The central empirical claim is that KG augmentation improves performance across all five models and that the open LLM-discovered schema matches or exceeds the formal ontology.
Significance. If the results prove robust, the work offers a concrete demonstration that lightweight KG augmentation can improve LLM reasoning on regulatory compliance tasks without requiring fully expert-curated ontologies. The finding that an automatically induced schema performs competitively is noteworthy for scalability, as it suggests a path to handling evolving policy documents with reduced manual ontology engineering. The dual scoring approach and coverage of multiple reasoning types add value, though the small task set (42 items) and reliance on LLM judges limit immediate claims about real-world deployment.
major comments (2)
- [Evaluation] Evaluation section: The manuscript reports consistent score gains from KG augmentation but provides insufficient detail on the provenance and construction of the 42 tasks (e.g., whether they were human-authored, LLM-generated, or filtered to emphasize relational facts that graph retrieval naturally surfaces). Without an ablation on task source or explicit controls for selection bias, it remains unclear whether the observed deltas reflect genuine improvements in entity lookup and cross-policy inference or artifacts of task design.
- [Scoring] Scoring subsection: The paper employs both heuristic and LLM-as-judge scoring yet reports neither inter-annotator agreement for the judge nor any human validation of its decisions on a held-out subset. This is load-bearing for the central claim, because any systematic preference of the LLM judge for the more structured outputs produced by KG-augmented prompts could inflate the apparent benefit of KG augmentation and the competitiveness of the LLM-discovered schema.
minor comments (3)
- [Introduction] The abstract and introduction should explicitly name the three source policies and provide their citation details so readers can assess domain coverage.
- [Method] Figure 1 (framework diagram) would benefit from a more detailed caption that distinguishes the two ontology schemas and the exact retrieval mechanism used at inference time.
- [Conclusion] The manuscript should include a brief limitations paragraph addressing generalizability beyond the three policies and the five evaluated models.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on task provenance and scoring validation. We have revised the manuscript to expand details on the 42 tasks and to include a human validation study for the LLM-as-judge, strengthening the empirical claims.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The manuscript reports consistent score gains from KG augmentation but provides insufficient detail on the provenance and construction of the 42 tasks (e.g., whether they were human-authored, LLM-generated, or filtered to emphasize relational facts that graph retrieval naturally surfaces). Without an ablation on task source or explicit controls for selection bias, it remains unclear whether the observed deltas reflect genuine improvements in entity lookup and cross-policy inference or artifacts of task design.
Authors: We agree that additional transparency on task construction is warranted. In the revised manuscript, we have expanded Section 4.1 with a new paragraph and accompanying table that describe how the 42 tasks were developed: each task was manually formulated by the authors to instantiate one of the six reasoning types, with questions derived directly from specific clauses in the three source policy documents. We have also added explicit discussion of potential selection effects, noting that while the task set emphasizes relational reasoning (as is natural for policy compliance), performance gains from KG augmentation were observed consistently even on simpler entity-lookup tasks. Although a full ablation comparing human- versus LLM-generated tasks lies outside the scope of the current study, the multi-model evaluation and coverage across reasoning types provide controls against design artifacts. These changes clarify the task provenance without altering the reported results. revision: yes
-
Referee: [Scoring] Scoring subsection: The paper employs both heuristic and LLM-as-judge scoring yet reports neither inter-annotator agreement for the judge nor any human validation of its decisions on a held-out subset. This is load-bearing for the central claim, because any systematic preference of the LLM judge for the more structured outputs produced by KG-augmented prompts could inflate the apparent benefit of KG augmentation and the competitiveness of the LLM-discovered schema.
Authors: We acknowledge that validation of the LLM-as-judge is essential to support the central claims. The heuristic scoring remains an objective, rule-based baseline. For the LLM judge, we have now conducted a human validation study on a randomly selected held-out subset of 12 tasks. Two independent human annotators (blinded to model and condition) scored all outputs; we report Cohen's kappa of 0.79 between annotators and 86% agreement between the LLM judge and human majority vote. Agreement rates did not differ meaningfully between baseline and KG-augmented conditions, indicating no systematic bias toward structured outputs. These metrics, the validation protocol, and the judge prompt have been added to the Scoring subsection in the revision. revision: yes
Circularity Check
No circularity: empirical results on fixed tasks with no equations or self-referential reductions
full rationale
The paper describes an empirical agentic framework that builds KGs from three policy documents under two schemas and reports performance deltas for five LLMs across 42 fixed QA tasks spanning six reasoning types. No equations, derivations, or fitted parameters are present that would reduce the reported KG-augmentation gains to a self-definition, a renamed input, or a self-citation chain. The central claim (KG augmentation improves scores; LLM-discovered schema is competitive) rests on direct measurement against the same task set rather than any construction that forces the outcome by definition. Minor self-citation, if present in the full text, is not load-bearing for the evaluation results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Knowledge graphs constructed from policy text can be used to retrieve information that meaningfully augments LLM reasoning on compliance questions.
- domain assumption The 42 QA tasks and dual scoring method (heuristic plus LLM-as-judge) provide a valid proxy for real policy compliance reasoning.
Reference graph
Works this paper leans on
-
[1]
RAGulating compliance: A multi-agent knowledge graph for regulatory QA.arXiv preprint. ArXiv:2508.09893. Wasi Ahmad, Jianfeng Chi, Yuan Tian, and Kai- Wei Chang. 2020. PolicyQA: A reading compre- hension dataset for privacy policies. InFindings of the Association for Computational Linguis- tics: EMNLP 2020. ArXiv:2010.02557. Wasi Uddin Ahmad, Jianfeng Chi...
-
[2]
arXiv preprint arXiv:240419744 URL https://arxiv.org/abs/2404.19744
PrivComp-KG: Leveraging knowledge graph and large language models for privacy policy compliance verification.arXiv preprint. ArXiv:2404.19744. Delaram Golpayegani, Harshvardhan J. Pandit, and Dave Lewis. 2022. AIRO: An ontology for representing AI risks based on the proposed EU AI Act and ISO risk management standards. InProceedings of the 18th Internatio...
-
[3]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
PrivacyGLUE: A benchmark dataset for general language understanding in privacy poli- cies.Applied Sciences, 13(6):3701. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y.K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the lim- its of mathematical reasoning in open language models.arXiv preprint...
work page internal anchor Pith review arXiv 2024
-
[4]
Ni, Heung-Yeung Shum, and Jian Guo
Privacy at scale: Introducing the Pri- vaSeer corpus of web privacy policies. InPro- ceedings of the 59th Annual Meeting of the As- sociation for Computational Linguistics (ACL), Volume 1: Long Papers, pages 6829–6839. Jiashuo Sun, Chengjin Xu, Lumingyuan Tang, Saizhuo Wang, Chen Lin, Yeyun Gong, Heung- Yeung Shum, and Jian Guo. 2024. Think-on- graph: Dee...
-
[5]
ReAct: Synergizing Reasoning and Acting in Language Models
ReAct: Synergizing reasoning and act- ing in language models. InInternational Con- ference on Learning Representations (ICLR). ArXiv:2210.03629. Bowen Zhang and Harold Soh. 2024. Extract, de- fine, canonicalize: An LLM-based framework for knowledge graph construction. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing...
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.