Optimal Functional Incentives for Control: The Linear-Quadratic Case with Bilinear Incentives
Pith reviewed 2026-05-07 08:18 UTC · model grok-4.3
The pith
For long horizons, the optimal bilinear incentive in linear-quadratic systems becomes independent of the follower's private cost parameter.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
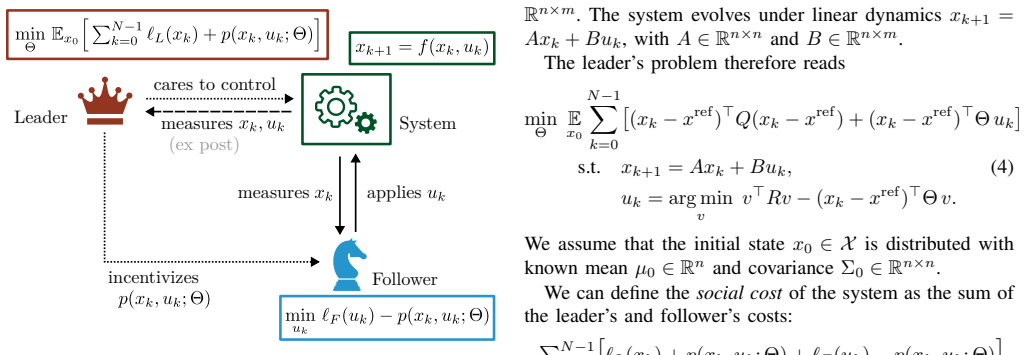
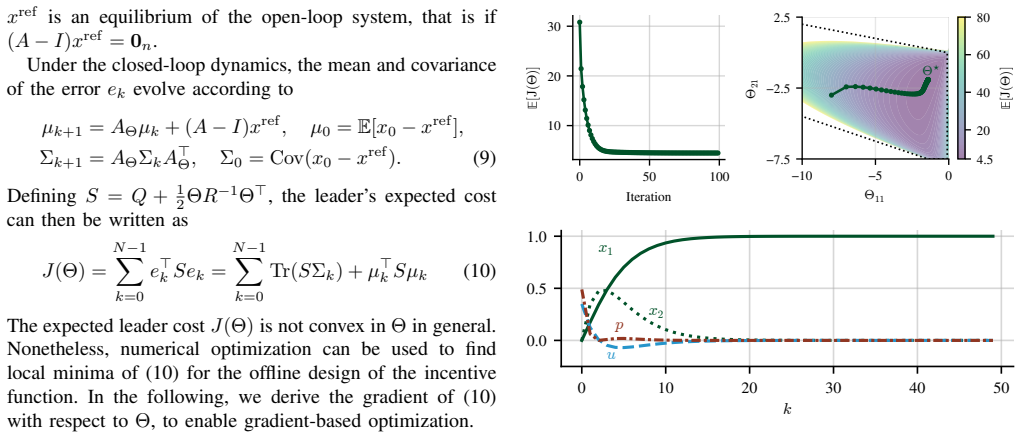
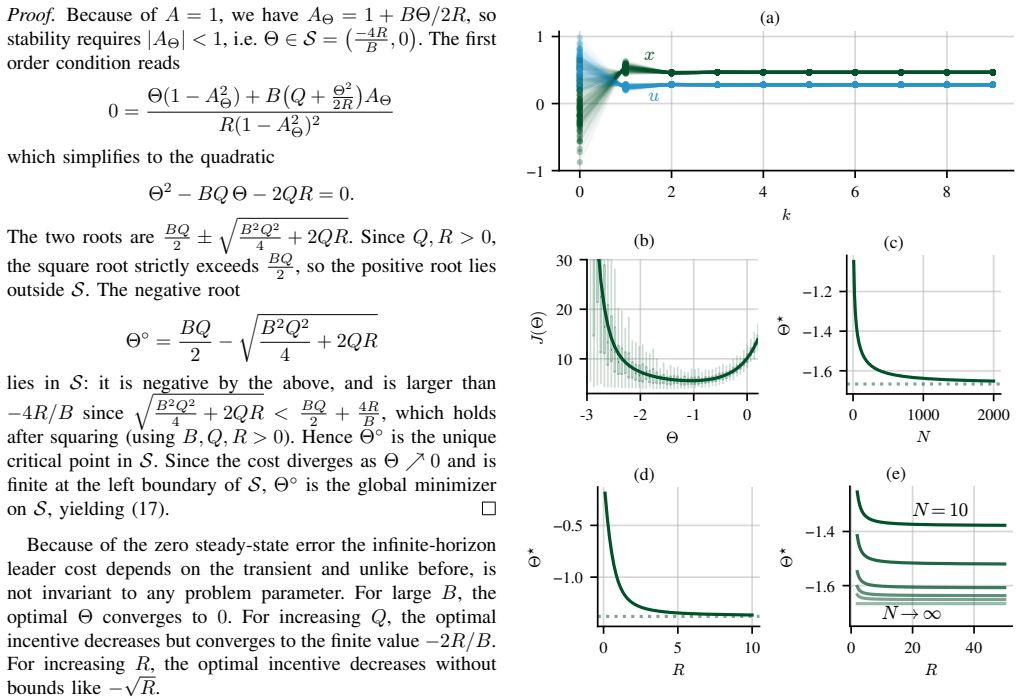
We formalize incentive design as a discrete-time bi-level optimal control problem. For the linear-quadratic case with bilinear incentives and myopic follower, we establish a necessary and sufficient stability condition for the induced closed-loop system, derive a closed-form expression for the gradient of the expected leader cost with respect to the incentive parameter matrix, and obtain a fully closed-form cost expression in the scalar setting. Based on the latter, we provide explicit characterizations of the optimal incentive parameter in the infinite-horizon limit and the limit of high follower cost. For long horizons, the optimal incentive becomes independent of the follower's private成本
What carries the argument
The bi-level optimal control problem in which the leader chooses a fixed bilinear incentive matrix to minimize its cost given the myopic follower's best-response trajectory in linear-quadratic dynamics.
If this is right
- The induced closed-loop system is stable under an explicitly stated necessary and sufficient condition.
- The gradient of the leader's expected cost admits a closed-form expression usable for gradient-based optimization of the incentive.
- In the scalar linear-quadratic setting the leader cost has a fully closed-form expression.
- In the infinite-horizon limit the optimal incentive parameter is independent of the follower's cost parameter.
- In the high follower-cost limit an explicit form for the optimal incentive is available.
Where Pith is reading between the lines
- Leaders could deploy such incentives in long-running systems without needing accurate estimates of follower costs.
- The same independence may hold in other linear or mildly nonlinear systems if analogous asymptotic analysis applies.
- The result offers a concrete route to robust mechanism design in networked control problems where private information is unavoidable.
- Relaxing the myopic assumption would be a natural next step to test whether similar decoupling occurs under forward-looking followers.
Load-bearing premise
The follower is myopic and optimizes only the current step while the incentive is restricted to bilinear form.
What would settle it
A simulation or analysis with a non-myopic follower that plans over multiple future steps in which the optimal incentive still depends on the private cost parameter even for arbitrarily long horizons would disprove the independence result.
Figures

read the original abstract
We study the design of functional incentive mechanisms for dynamical systems, in which a leader designs a fixed incentive function to motivate a self-interested follower to actuate the system beneficially over an extended horizon, without real-time revision of the incentive. This stands in contrast to the adaptive paradigm, in which the incentive is itself a continuously updated control variable. We formalize the problem as a discrete-time bi-level optimal control problem and derive analytical results for the linear-quadratic case with bilinear incentives and a myopic follower. Specifically, we establish a necessary and sufficient stability condition for the induced closed-loop system, derive a closed-form expression for the gradient of the expected leader cost with respect to the incentive parameter matrix, and obtain a fully closed-form cost expression in the scalar setting. Based on the latter, explicit characterizations of the optimal incentive parameter are provided in two asymptotic regimes: the infinite-horizon limit and the limit of high follower cost. For long horizons, the optimal incentive is shown to become independent of the follower's private cost parameter, with direct implications for robust mechanism design under private information.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies the design of fixed functional incentives for a leader to steer the behavior of a self-interested myopic follower in a discrete-time linear-quadratic dynamical system. The incentive is restricted to a bilinear form with a fixed parameter matrix. The authors formulate this as a bi-level optimal control problem and, for the LQ case, derive a necessary and sufficient stability condition for the induced closed-loop dynamics, a closed-form gradient of the leader's expected cost with respect to the incentive parameters, and an explicit cost expression in the scalar case. They then characterize the optimal incentive parameters in the infinite-horizon limit and the high follower-cost limit, highlighting that in the long-horizon regime the optimal incentive becomes independent of the follower's private cost parameter.
Significance. Should the technical results hold under the stated assumptions, the paper contributes analytical tools for mechanism design in control systems by providing explicit expressions that avoid numerical optimization in the scalar LQ setting. The independence of the optimal incentive from private information in the infinite-horizon case has potential implications for designing robust incentives without requiring knowledge of the follower's cost parameters, which is relevant for applications in economics of control and robust mechanism design.
major comments (1)
- [§6 (infinite-horizon limit)] The claim that the optimal incentive becomes independent of the follower's private cost parameter for long horizons (abstract and the infinite-horizon analysis) is obtained under the myopic follower assumption introduced in the problem setup. If the follower instead solves a true multi-step dynamic program, the private quadratic cost coefficient couples into the entire state trajectory through the fixed bilinear incentive, and the leader's infinite-horizon cost would generally retain dependence on this parameter. Since this independence is central to the claimed implications for robust mechanism design under private information, the manuscript should either demonstrate that the result persists without the myopic assumption or explicitly restrict the claim to the myopic case with a discussion of its limitations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and will incorporate revisions to strengthen the presentation of our assumptions and their implications.
read point-by-point responses
-
Referee: [§6 (infinite-horizon limit)] The claim that the optimal incentive becomes independent of the follower's private cost parameter for long horizons (abstract and the infinite-horizon analysis) is obtained under the myopic follower assumption introduced in the problem setup. If the follower instead solves a true multi-step dynamic program, the private quadratic cost coefficient couples into the entire state trajectory through the fixed bilinear incentive, and the leader's infinite-horizon cost would generally retain dependence on this parameter. Since this independence is central to the claimed implications for robust mechanism design under private information, the manuscript should either demonstrate that the result persists without the myopic assumption or explicitly restrict the claim to the myopic case with a discussion of its limitations.
Authors: We agree that the independence result in the infinite-horizon limit is derived specifically under the myopic follower assumption, which is stated in the problem setup, abstract, and throughout the analysis (including the closed-loop dynamics and cost derivations in Section 6). Our formulation models the follower as optimizing only the current-stage quadratic cost plus the bilinear incentive at each time step, without forward-looking optimization over the full horizon. This myopic behavior decouples the follower's private cost parameter from the long-run trajectory in a manner that yields the observed independence. We will revise the manuscript to more explicitly restrict all claims regarding independence and robust mechanism design implications to the myopic case. This includes adding a dedicated paragraph in the introduction and Section 6 discussing the limitations: for non-myopic followers solving a true multi-period dynamic program, the incentive would indeed couple the private cost into the entire trajectory, generally preserving dependence on the parameter and requiring separate analysis for robust design. We do not claim the result holds beyond the myopic setting. revision: yes
Circularity Check
Derivations self-contained from bi-level formulation; no circular reductions or load-bearing self-citations identified
full rationale
The paper starts from an explicit bi-level optimal control formulation with a myopic follower and bilinear incentive, then derives the stability condition, gradient expression, and scalar closed-form leader cost directly from the resulting closed-loop dynamics and quadratic costs. The infinite-horizon independence result is obtained by taking the mathematical limit of that derived closed-form expression, not by re-fitting or re-defining any quantity in terms of itself. No step reduces a claimed prediction to a parameter fitted from the same data or to an ansatz imported via self-citation; the myopic assumption is stated up-front and the derivations remain internal to the stated model. External benchmarks or machine-checked results are not required here because the chain is algebraic and does not invoke prior author theorems as the sole justification for the central independence claim.
Axiom & Free-Parameter Ledger
free parameters (1)
- incentive parameter matrix
axioms (2)
- domain assumption The underlying system is linear with quadratic costs.
- domain assumption The follower is myopic and responds optimally to the fixed incentive at each step.
invented entities (1)
-
bilinear incentive function
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A Perspective on Incentive Design: Challenges and Op- portunities,
L. J. Ratliff, R. Dong, S. Sekar, and T. Fiez, “A Perspective on Incentive Design: Challenges and Op- portunities,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 2, no. 1, pp. 305–338, May 2019
work page 2019
-
[2]
L. J. Ratliff and T. Fiez, “Adaptive Incentive Design,” IEEE Transactions on Automatic Control, vol. 66, no. 8, pp. 3871–3878, Aug. 2021
work page 2021
-
[3]
An Incentive-Based Online Optimization Framework for Distribution Grids,
X. Zhou, E. Dall’Anese, L. Chen, and A. Simonetto, “An Incentive-Based Online Optimization Framework for Distribution Grids,”IEEE Transactions on Auto- matic Control, vol. 63, no. 7, pp. 2019–2031, Jul. 2018
work page 2019
-
[4]
Feed- back Optimization of Incentives for Distribution Grid Services,
G. Cavraro, J. Comden, and A. Bernstein, “Feed- back Optimization of Incentives for Distribution Grid Services,”IEEE Control Systems Letters, vol. 8, pp. 1505–1510, 2024
work page 2024
-
[5]
PRIME: Fast Primal-Dual Feedback Optimization for Markets with Application to Optimal Power Flow,
N. J. Behr, M. Bianchi, K. Moffat, S. Bolognani, and F. D ¨orfler, “PRIME: Fast Primal-Dual Feedback Optimization for Markets with Application to Optimal Power Flow,” inIEEE Conference on Decision and Control, Dec. 2025
work page 2025
-
[6]
Adaptive Incentive Design With Learning Agents,
C. Maheshwari, K. Kulkarni, M. Wu, and S. Sastry, “Adaptive Incentive Design With Learning Agents,” IEEE Transactions on Automatic Control, pp. 1–16, 2025
work page 2025
-
[7]
Active Distribution Grids Providing V oltage Support: The Swiss Case,
S. Karagiannopoulos, C. Mylonas, P. Aristidou, and G. Hug, “Active Distribution Grids Providing V oltage Support: The Swiss Case,”IEEE Transactions on Smart Grid, vol. 12, no. 1, pp. 268–278, Jan. 2021
work page 2021
-
[8]
V oltage Support Procurement in Transmission Grids: Incentive Design via Online Bilevel Games,
Z. Jiang, S. Bolognani, and G. Belgioioso, “V oltage Support Procurement in Transmission Grids: Incentive Design via Online Bilevel Games,” inIEEE Confer- ence on Decision and Control, Dec. 2025
work page 2025
-
[9]
Incentivizing Market and Control for Ancillary Services in Dynamic Power Grids,
K. Uchida, K. Hirata, and Y . Wasa, “Incentivizing Market and Control for Ancillary Services in Dynamic Power Grids,” inSmart Grid Control: Overview and Research Opportunities, Springer International Pub- lishing, 2019, pp. 47–58
work page 2019
-
[10]
Y . Wasa, K. Hirata, and K. Uchida, “Optimal agency contract for incentive and control under moral hazard in dynamic electric power networks,”IET Smart Grid, vol. 2, no. 4, pp. 594–601, Dec. 2019
work page 2019
-
[11]
A control- theoretic view on incentives,
Y .-C. Ho, P. B. Luh, and G. J. Olsder, “A control- theoretic view on incentives,”Automatica, vol. 18, no. 2, pp. 167–179, Mar. 1982
work page 1982
-
[12]
Affine Incentive Schemes for Stochastic Systems with Dynamic Information,
T. Basar, “Affine Incentive Schemes for Stochastic Systems with Dynamic Information,” inAmerican Control Conference, Jun. 1982
work page 1982
-
[13]
Y .-P. Zheng and T. Basar, “Existence and deriva- tion of optimal affine incentive schemes for Stack- elberg games with partial information: A geometric approach,”International Journal of Control, vol. 35, no. 6, pp. 997–1011, Jun. 1982
work page 1982
-
[14]
Optimal and Near- Optimal Incentive Strategies in the Hierarchical Con- trol of Markov Chains,
V . R. Saksena and J. B. Cruz, “Optimal and Near- Optimal Incentive Strategies in the Hierarchical Con- trol of Markov Chains,” inAmerican Control Confer- ence, Jun. 1983
work page 1983
-
[15]
Closed-loop Stackelberg solution to a multistage linear-quadratic game,
B. Tolwinski, “Closed-loop Stackelberg solution to a multistage linear-quadratic game,”Journal of Op- timization Theory and Applications, vol. 34, no. 4, pp. 485–501, Aug. 1981
work page 1981
-
[16]
A nonlinear incentive strategy for multi- stage Stackelberg games with partial information,
S.-y. Zhang, “A nonlinear incentive strategy for multi- stage Stackelberg games with partial information,” in IEEE Conference on Decision and Control, Dec. 1986
work page 1986
-
[17]
Optimal incentive strategy for leader-follower games,
X. Liu and S. Zhang, “Optimal incentive strategy for leader-follower games,”IEEE Transactions on Automatic Control, vol. 37, no. 12, pp. 1957–1961, Dec. 1992
work page 1957
-
[18]
An approach to discrete-time incentive feedback Stackelberg games,
M. Li, J. Cruz, and M. Simaan, “An approach to discrete-time incentive feedback Stackelberg games,” IEEE Transactions on Systems, Man, and Cybernet- ics - Part A: Systems and Humans, vol. 32, no. 4, pp. 472–481, Jul. 2002
work page 2002
-
[19]
Aggregation and Linearity in the Provision of Intertemporal Incentives,
B. Holmstrom and P. Milgrom, “Aggregation and Linearity in the Provision of Intertemporal Incentives,” Econometrica, vol. 55, no. 2, pp. 303–328, 1987. JSTOR:1913238
work page 1987
-
[20]
The Theory of Incen- tives I : The Principal-Agent Model,
J.-J. Laffont and D. Martimort, “The Theory of Incen- tives I : The Principal-Agent Model,” Feb. 2001
work page 2001
-
[21]
Re- verse Stackelberg games, part II: Results and open issues,
N. Groot, B. De Schutter, and H. Hellendoorn, “Re- verse Stackelberg games, part II: Results and open issues,” inIEEE International Conference on Control Applications, Oct. 2012
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.