Enhancing multimodal affect recognition in healthcare: the robustness of appraisal dimensions over labels within age groups and in cross-age generalisation
Pith reviewed 2026-05-07 06:39 UTC · model grok-4.3
The pith
Appraisal dimensions from emotion theory outperform categorical labels in multimodal affect recognition across age groups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Appraisal dimensions consistently outperformed categorical labels in multimodal affect recognition models. Within each age corpus, appraisal models showed greater predictive accuracy and stability. In cross-corpus evaluation between young and older adults, categorical labels performed at chance levels while appraisal dimensions maintained performance above chance. Mixed-corpus training did not improve generalization beyond within-corpus training. These results highlight the advantages of appraisal dimensions for cross-age affect recognition in AI-assisted healthcare.
What carries the argument
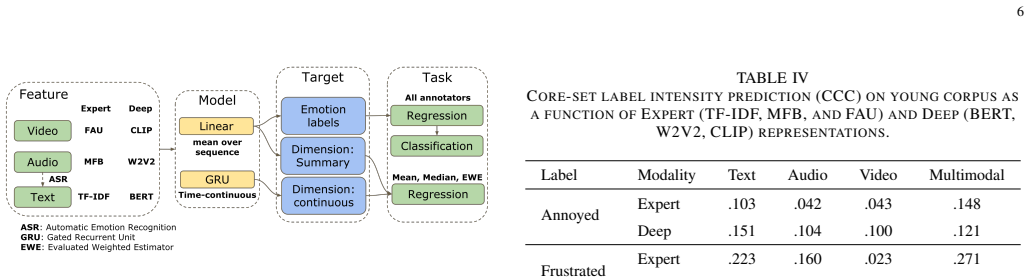
Appraisal dimensions borrowed from appraisal theories of emotion, used as continuous target variables in multimodal machine learning models for affect prediction. These dimensions capture evaluative aspects of emotional experience and enable better generalization across age groups than discrete categorical labels.
If this is right
- Multimodal fusion and deep learning representations improve emotion modeling when paired with appraisal dimensions.
- Appraisal dimensions enable more stable affect recognition for AI interventions across age populations.
- Training on combined young and older adult data does not enhance cross-age generalization beyond age-specific models.
- An API for time-continuous emotion prediction can support further research in affective computing and behavioral sciences.
Where Pith is reading between the lines
- If appraisal dimensions prove more generalizable, affect recognition systems in healthcare could be deployed more broadly without extensive age-specific data collection.
- Similar robustness advantages might appear when comparing appraisal dimensions to labels across other demographic factors such as culture or clinical conditions.
- Developers could prioritize appraisal-based models to make cognitive training and similar AI tools more adaptive to users' emotional states regardless of age.
Load-bearing premise
The annotations of appraisal dimensions and categorical labels were performed consistently and without systematic differences in quality or context between the young-adult and older-adult datasets.
What would settle it
Re-annotating both corpora with the same protocol and annotators then finding that appraisal dimensions lose their cross-age advantage would falsify the robustness claim.
Figures


read the original abstract
The integration of artificial intelligence (AI) into healthcare has advanced significantly, yet affect recognition remains a major challenge, particularly in AI-assisted interventions such as Computerized Cognitive Training (CCT). The THERADIA-WoZ corpus was developed to enable multimodal affect recognition in the context of AI-driven CCT, focusing on an older adult population. This study extends the corpus by introducing a dataset collected from young adults, allowing direct comparison of affect recognition models across age groups. Our objective was to assess whether multimodal models based on dimensions borrowed from appraisal theories outperform those based on categorical labels and to evaluate their generalisation power across age corpora. After comparing both corpora, models were trained and tested using within-corpus, cross-corpus, and mixed-corpus evaluation. Results revealed that appraisal dimensions consistently outperformed categorical labels across all conditions, demonstrating greater predictive accuracy and stability. Notably, categorical labels failed to generalise across age corpora, as performance dropped to chance levels in cross-corpus evaluation. In contrast, appraisal dimensions maintained predictive performance above chance, reinforcing their robustness for cross-age affect recognition. Furthermore, training on both corpora did not improve generalisation beyond within-corpus training. The findings support the theoretical and practical advantages of appraisal dimensions over categorical labels in affective computing. They also highlight the importance of multimodal fusion and deep learning representations for emotion modeling. To facilitate future research, we provide an API for researchers interested in time-continuous emotion prediction, offering valuable tools for behavioral sciences to enhance the measurement of emotional states in various experimental settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a new young-adult multimodal affect dataset to complement the existing THERADIA-WoZ older-adult corpus and compares appraisal-dimension-based models against categorical-label-based models for emotion recognition in healthcare contexts such as Computerized Cognitive Training. Using within-corpus, cross-corpus, and mixed-corpus evaluation protocols, the authors report that appraisal dimensions consistently yield higher accuracy and stability than categorical labels; notably, categorical models drop to chance levels in cross-age generalization while appraisal models remain above chance. The work concludes that appraisal representations are more robust for cross-age generalization and releases an API for time-continuous prediction.
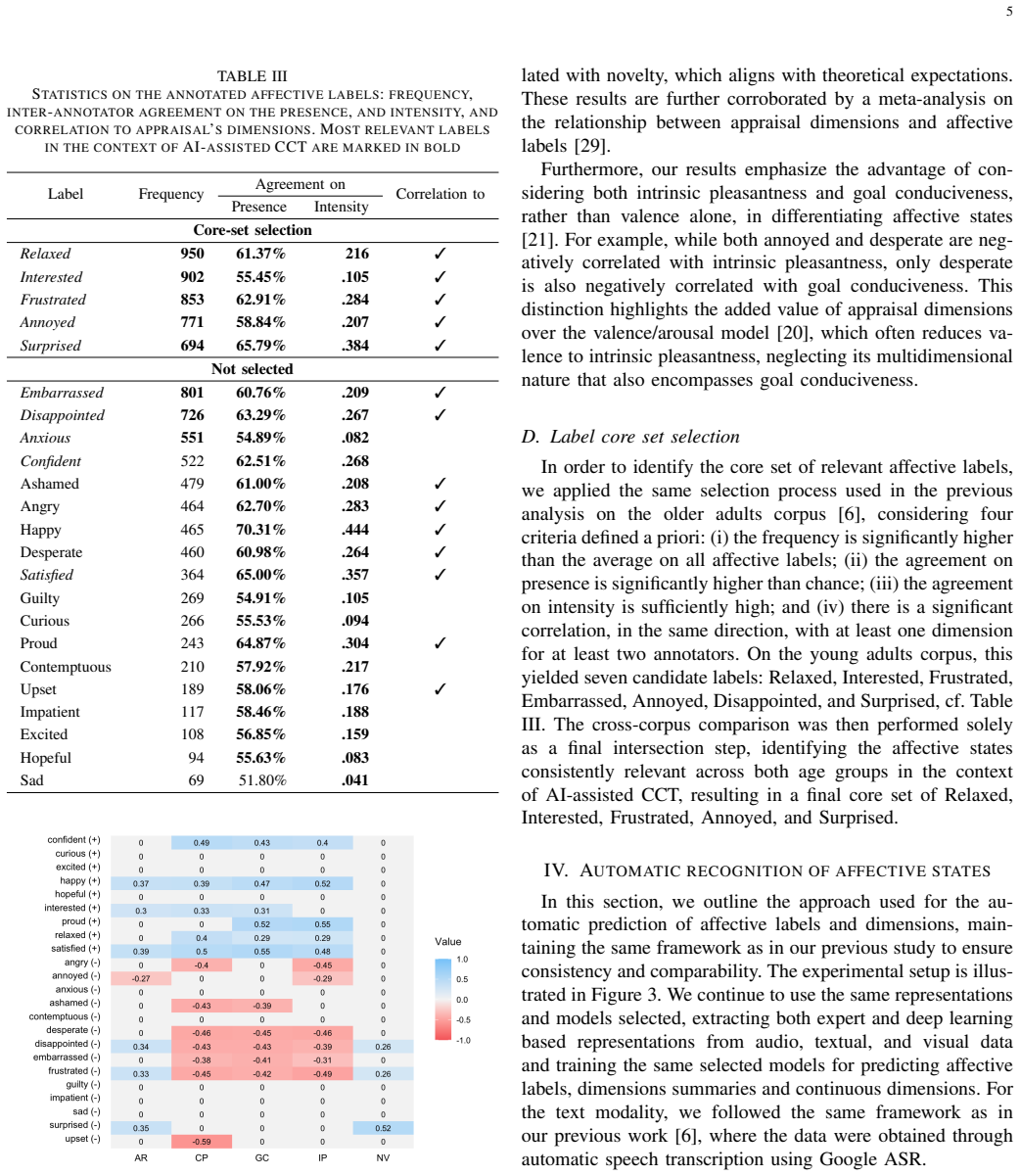
Significance. If the central claims hold after verification of annotation protocols and methodological details, the results would provide concrete empirical support for the practical advantages of appraisal-theory dimensions over discrete labels in affective computing. This could influence the design of age-robust emotion-aware AI systems for healthcare, particularly interventions targeting older adults, and the open API would enable reproducible time-continuous modeling in behavioral research.
major comments (3)
- [Methods] Methods section: No inter-rater reliability statistics (Krippendorff’s alpha, ICC, or equivalent) are reported for either the categorical labels or the appraisal dimensions in the young-adult corpus or the THERADIA-WoZ older-adult corpus. Because the central claim attributes the cross-corpus performance gap to intrinsic properties of the two representations rather than differences in label quality or annotation consistency, these metrics are required to rule out the alternative explanation that lower agreement on categorical labels in one corpus drives the observed drop to chance levels.
- [Results] Results and Evaluation sections: The abstract and results report performance differences and generalization outcomes but supply no information on model architectures, modality-specific feature sets, fusion strategy, training procedures, hyperparameter selection, exact sample sizes per split, or statistical significance testing (including confidence intervals or p-values for the reported differences). These omissions prevent independent verification of the claimed superiority and stability of appraisal dimensions.
- [Corpus Description] Corpus and Annotation subsections: The manuscript does not provide a side-by-side comparison of annotation guidelines, rater training, task instructions, or rater demographics between the two corpora. Any systematic differences in labeling context or quality could artifactually favor appraisal dimensions in the cross-corpus tests; explicit confirmation of matched protocols is therefore necessary to support the robustness interpretation.
minor comments (3)
- [Abstract] Abstract: Numerical performance values, effect sizes, and the precise definition of 'chance level' (e.g., random guessing baseline for the label set) should be stated to allow readers to gauge the magnitude of the reported differences.
- [Discussion] Discussion: The statement that mixed-corpus training 'did not improve generalisation beyond within-corpus training' would benefit from quantitative ablation results or direct comparison tables showing the relevant metrics.
- [Figures/Tables] Figure and table captions: Ensure all performance metrics are accompanied by standard deviations or confidence intervals and that axis labels clearly indicate the evaluation setting (within, cross, or mixed).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights important areas for improving the transparency and rigor of our manuscript. We address each major comment point by point below and will revise the manuscript to incorporate the requested information and clarifications.
read point-by-point responses
-
Referee: [Methods] Methods section: No inter-rater reliability statistics (Krippendorff’s alpha, ICC, or equivalent) are reported for either the categorical labels or the appraisal dimensions in the young-adult corpus or the THERADIA-WoZ older-adult corpus. Because the central claim attributes the cross-corpus performance gap to intrinsic properties of the two representations rather than differences in label quality or annotation consistency, these metrics are required to rule out the alternative explanation that lower agreement on categorical labels in one corpus drives the observed drop to chance levels.
Authors: We agree that inter-rater reliability metrics are necessary to strengthen the interpretation of our results. The revised manuscript will include Krippendorff’s alpha (and ICC where appropriate) for both categorical labels and appraisal dimensions in each corpus, computed from the available annotations. These will be reported in the Methods section alongside the annotation procedures. We will also discuss how the observed agreement levels compare across representation types and corpora to address the potential confounding explanation. revision: yes
-
Referee: [Results] Results and Evaluation sections: The abstract and results report performance differences and generalization outcomes but supply no information on model architectures, modality-specific feature sets, fusion strategy, training procedures, hyperparameter selection, exact sample sizes per split, or statistical significance testing (including confidence intervals or p-values for the reported differences). These omissions prevent independent verification of the claimed superiority and stability of appraisal dimensions.
Authors: We acknowledge that the current manuscript lacks sufficient methodological detail for full reproducibility and verification. In the revision, the Methods and Results sections will be substantially expanded to describe: the specific model architectures (including multimodal fusion approaches), modality-specific feature extraction (e.g., audio, video, and any physiological features), training procedures, hyperparameter selection methods, exact participant and sample sizes per corpus and split, and statistical significance testing with confidence intervals and p-values for key comparisons. This will allow independent assessment of the reported performance differences. revision: yes
-
Referee: [Corpus Description] Corpus and Annotation subsections: The manuscript does not provide a side-by-side comparison of annotation guidelines, rater training, task instructions, or rater demographics between the two corpora. Any systematic differences in labeling context or quality could artifactually favor appraisal dimensions in the cross-corpus tests; explicit confirmation of matched protocols is therefore necessary to support the robustness interpretation.
Authors: We will add a dedicated comparative subsection (or table) in the Corpus Description to explicitly contrast the annotation guidelines, rater training protocols, task instructions, and rater demographics between the young-adult and THERADIA-WoZ corpora. This will include confirmation that both used aligned protocols for the same categorical labels and appraisal dimensions, with comparable rater training and instructions. The addition will directly support our claim that the generalization differences arise from the representational properties rather than annotation artifacts. revision: yes
Circularity Check
No circularity: empirical results grounded in independent corpora and held-out evaluation
full rationale
The paper reports an empirical ML study that trains separate models to predict appraisal dimensions versus categorical labels on two independently collected age-specific corpora. Evaluation uses standard within-corpus, cross-corpus, and mixed-corpus splits on held-out data; performance differences are measured directly on these external test sets rather than being redefined from fitted parameters. No equations, self-definitional loops, or load-bearing self-citations appear in the derivation of the central claim. The comparison protocol supplies independent grounding, so the reported superiority of appraisal dimensions in cross-age generalization does not reduce to a construction or renaming of the inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Appraisal dimensions drawn from psychological theory provide a more stable and generalizable representation of affect than categorical emotion labels
- domain assumption Multimodal signals can be fused via deep learning to predict continuous affect ratings
Reference graph
Works this paper leans on
-
[1]
Artificial intelligence in healthcare,
K.-H. Yu, A. L. Beam, and I. S. Kohane, “Artificial intelligence in healthcare,”Nature biomedical engineering, vol. 2, no. 10, pp. 719–731, 2018
work page 2018
-
[2]
Can social interaction constitute social cognition?
H. De Jaegher, E. Di Paolo, and S. Gallagher, “Can social interaction constitute social cognition?”Trends in Cognitive Sciences, vol. 14, no. 10, pp. 441–447, Oct. 2010
work page 2010
-
[3]
N. T. Hill, L. Mowszowski, S. L. Naismithet al., “Computerized cognitive training in older adults with mild cognitive impairment or dementia: a systematic review and meta-analysis,”American Journal of Psychiatry, vol. 174, no. 4, pp. 329–340, 2017
work page 2017
-
[4]
A. Lampit, H. Hallock, and M. Valenzuela, “Computerized cognitive training in cognitively healthy older adults: a systematic review and meta-analysis of effect modifiers,”PLoS medicine, vol. 11, no. 11, p. e1001756, 2014
work page 2014
-
[5]
Automatic emotion recognition in clinical scenario: A systematic review of methods,
L. Pepa, L. Spalazzi, M. Capecciet al., “Automatic emotion recognition in clinical scenario: A systematic review of methods,”IEEE Transactions on Affective Computing, vol. 14, no. 2, pp. 1675–1695, 2023
work page 2023
-
[6]
Theradia woz: An ecological corpus for appraisal-based affect research in healthcare,
H. Fournier, S. Alisamir, S. Azzakhnini, I. Zsoldos, E. Trân, G. Bailly, F. Elisei, B. Bouchot, B. Varini, P. Constantet al., “Theradia woz: An ecological corpus for appraisal-based affect research in healthcare,” IEEE Transactions on Affective Computing, 2025
work page 2025
-
[7]
S. Basharpoor, E. Seif, and S. Daneshvar, “Computerized executive functions training: The efficacy on reading performance of children with dyslexia,”Dyslexia, vol. 30, no. 2, p. e1762, 2024
work page 2024
-
[8]
Deep learning-based facial expression recognition for the elderly: A systematic review,
F. X. Gaya-Morey, J. M. Buades-Rubio, P. Palanque, R. Lacuesta, and C. Manresa-Yee, “Deep learning-based facial expression recognition for the elderly: A systematic review,”arXiv preprint arXiv:2502.02618, 2025
-
[9]
Facial age affects emotional expression decoding,
M. Fölster, U. Hess, and K. Werheid, “Facial age affects emotional expression decoding,”Frontiers in psychology, vol. 5, p. 30, 2014
work page 2014
-
[10]
Changes in computer-analyzed facial expressions with age,
H. Ko, K. Kim, M. Bae, M.-G. Seo, G. Nam, S. Park, S. Park, J. Ihm, and J.-Y . Lee, “Changes in computer-analyzed facial expressions with age,”Sensors, vol. 21, no. 14, p. 4858, 2021
work page 2021
-
[11]
A computational study on aging effect for facial ex- pression recognition,
E. SÖNMEZ, “A computational study on aging effect for facial ex- pression recognition,”Turkish Journal of Electrical Engineering and Computer Sciences, vol. 27, no. 4, pp. 2430–2443, 2019
work page 2019
-
[12]
A review study: The effect of face aging at estimating age and face recognition,
R. R. Atallah, A. Kamsin, and M. A. Ismail, “A review study: The effect of face aging at estimating age and face recognition,” inJournal of Physics: Conference Series, vol. 1339, no. 1. IOP Publishing, 2019, p. 012006. 11
work page 2019
-
[13]
Expression recognition across age,
S. R. Jannat and S. Canavan, “Expression recognition across age,” in2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021). IEEE, 2021, pp. 1–5
work page 2021
-
[14]
Facial emotion recog- nition analysis based on age-biased data,
H. Park, Y . Shin, K. Song, C. Yun, and D. Jang, “Facial emotion recog- nition analysis based on age-biased data,”Applied Sciences, vol. 12, no. 16, p. 7992, 2022
work page 2022
-
[15]
Changes in vocal emotion recognition across the life span
M. Amorim, A. Anikin, A. J. Mendes, C. F. Lima, S. A. Kotz, and A. P. Pinheiro, “Changes in vocal emotion recognition across the life span.” Emotion, vol. 21, no. 2, p. 315, 2021
work page 2021
-
[16]
Y . Lin, F. Xu, X. Ye, H. Zhang, H. Ding, and Y . Zhang, “Age and sex differences in emotion perception are influenced by emotional category and communication channel.”Psychology and aging, 2024
work page 2024
-
[17]
Age differences in vocal emotion perception: on the role of speaker age and listener sex,
A. Sen, D. Isaacowitz, and A. Schirmer, “Age differences in vocal emotion perception: on the role of speaker age and listener sex,” Cognition and Emotion, vol. 32, no. 6, pp. 1189–1204, 2018
work page 2018
-
[18]
Understanding the expression of loneliness on twitter across age groups and genders,
A. Andy, G. Sherman, and S. C. Guntuku, “Understanding the expression of loneliness on twitter across age groups and genders,”Plos one, vol. 17, no. 9, p. e0273636, 2022
work page 2022
-
[19]
Solving the emotion paradox: Categorization and the experience of emotion,
L. F. Barrett, “Solving the emotion paradox: Categorization and the experience of emotion,”Personality and social psychology review, vol. 10, no. 1, pp. 20–46, 2006
work page 2006
-
[20]
A circumplex model of emotions,
J. Russel, “A circumplex model of emotions,”Journal of Personality and Social Psychology, vol. 39, pp. 1161–1178, 1980
work page 1980
-
[21]
H. Fournier and O. Koenig, “Combined effects of intrinsic and goal rel- evances on attention and action tendency during the emotional episode.” Emotion, vol. 23, no. 2, pp. 425–436, 2023
work page 2023
-
[22]
——, “Emotional attention: Time course and effects of agonistic and antagonistic overlay of intrinsic and goal relevances.”Emotion, vol. 24, no. 4, p. 923, 2024
work page 2024
-
[23]
The world of emotions is not two-dimensional,
J. R. Fontaine, K. R. Scherer, E. B. Roeschet al., “The world of emotions is not two-dimensional,”Psychological science, vol. 18, no. 12, pp. 1050–1057, 2007
work page 2007
-
[24]
Sander,Models of emotion: The affective neuroscience approach
D. Sander,Models of emotion: The affective neuroscience approach. Cambridge University Press, 2013, pp. 4–54
work page 2013
-
[25]
A systems approach to appraisal mechanisms in emotion,
D. Sander, D. Grandjean, and K. R. Scherer, “A systems approach to appraisal mechanisms in emotion,”Neural networks, vol. 18, no. 4, pp. 317–352, 2005
work page 2005
-
[26]
Dynamic facial expression of emotion and observer inference,
K. R. Scherer, H. Ellgring, A. Dieckmannet al., “Dynamic facial expression of emotion and observer inference,”Frontiers in psychology, vol. 10, p. 508, 2019
work page 2019
-
[27]
I. Zsoldos, E. Trân, H. Fournieret al., “The value of a virtual assistant to improve engagement in computerized cognitive training at home: An exploratory study,”JMIR Rehabilitation and Assistive Technologies, vol. 11, p. e48129, 2024
work page 2024
- [28]
-
[29]
Associations between cognitive appraisals and emotions: A meta-analytic review
G. C. Yeo and D. C. Ong, “Associations between cognitive appraisals and emotions: A meta-analytic review.”Psychological Bulletin, 2024
work page 2024
-
[30]
S. Davis and P. Mermelstein, “Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences,” IEEE transactions on acoustics, speech, and signal processing, vol. 28, no. 4, pp. 357–366, 1980
work page 1980
-
[31]
Term-weighting approaches in automatic text retrieval,
G. Salton and C. Buckley, “Term-weighting approaches in automatic text retrieval,”Information processing & management, vol. 24, no. 5, pp. 513–523, 1988
work page 1988
-
[32]
Manual of the facial action coding system (facs),
P. Ekman and W. V . Friesen, “Manual of the facial action coding system (facs),”Trans. ed. Vol. Consulting Psychologists Press, Palo Alto, vol. 3, 1978
work page 1978
-
[33]
wav2vec 2.0: A frame- work for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A frame- work for self-supervised learning of speech representations,”Advances in Neural Information Processing Systems, vol. 33, pp. 12 449–12 460, 2020
work page 2020
-
[34]
BERT: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Leeet al., “BERT: Pre-training of deep bidirectional transformers for language understanding,” inProceedings of the 2019 Conference of the North American Chapter of the Asso- ciation for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computational Linguistics, 2019, pp. ...
work page 2019
-
[35]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 8748–8763
work page 2021
-
[36]
Prediction of asynchronous dimensional emotion ratings from audiovisual and physiological data,
F. Ringeval, F. Eyben, E. Kroupi, A. Yuce, J.-P. Thiran, T. Ebrahimi, D. Lalanne, and B. Schuller, “Prediction of asynchronous dimensional emotion ratings from audiovisual and physiological data,”Pattern Recognition Letters, vol. 66, pp. 22–30, 2015
work page 2015
-
[37]
L. Stappen, L. Schumann, B. Sertolliet al., “Muse-toolbox: The mul- timodal sentiment analysis continuous annotation fusion and discrete class transformation toolbox,” inProceedings of the 2nd Workshop on multimodal sentiment analysis challenge, 2021, pp. 75–82
work page 2021
-
[38]
F. Weninger, F. Ringeval, E. Marchiet al., “Discriminatively Trained Re- current Neural Networks for Continuous Dimensional Emotion Recog- nition from Audio,” inProceedings of the 25th International Joint Conference on Artificial Intelligence (IJCAI 2016). New York City (NY), USA: IJCAI/AAAI, July 2016, pp. 2196–2202
work page 2016
-
[39]
Chapter 25 - tools in the trunk,
J. K. Kruschke, “Chapter 25 - tools in the trunk,” inDoing Bayesian Data Analysis (Second Edition), 2nd ed., J. K. Kruschke, Ed. Boston: Academic Press, 2015, pp. 721–736. [Online]. Available: https: //www.sciencedirect.com/science/article/pii/B9780124058880000258
work page 2015
-
[40]
R. E. Kass and A. E. Raftery, “Bayes factors,”Journal of the american statistical association, vol. 90, no. 430, pp. 773–795, 1995
work page 1995
-
[41]
Bayesian estimation supersedes the t test
J. K. Kruschke, “Bayesian estimation supersedes the t test.”Journal of Experimental Psychology: General, vol. 142, no. 2, p. 573, 2013
work page 2013
-
[42]
Cohen,Statistical power analysis for the behavioral sciences
J. Cohen,Statistical power analysis for the behavioral sciences. rout- ledge, 2013
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.