Psychologically Potent, Computationally Invisible: LLMs Generate Social-Comparison-Eliciting Posts They Fail to Detect
Pith reviewed 2026-05-09 19:07 UTC · model grok-4.3
The pith
LLMs generate social-comparison triggers but fail to detect them with prompts
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
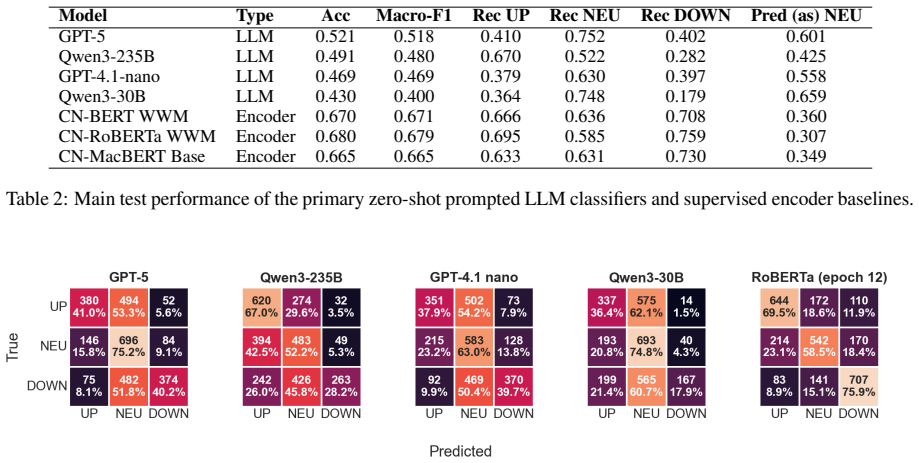
The central claim is that LLMs display a generation-detection mismatch for social comparison: they can create Xiaohongshu-style posts that measurably alter perceived standing and affect, but prompted classifiers fail to identify the triggers reliably, with stable error patterns such as over-neutralization and skew. The XHS-SCoRE benchmark establishes that the underlying signal is textually learnable yet not robustly accessible to prompt-based classification.
What carries the argument
The XHS-SCoRE benchmark, which collects first-person reader judgments labeling posts as upward, downward, or neutral social comparison elicitors, functions as the diagnostic tool to expose the mismatch between fluent generation and fragile prompt-based detection.
If this is right
- AI content generators may produce posts that influence self-perception without built-in ability to flag the mechanism.
- Prompt engineering alone proves insufficient for reliable detection of subtle relational signals in social media text.
- Supervised training on reader-labeled data succeeds where prompting fails, pointing to hybrid detection needs.
- Generated posts can change comparison-related affect even when the model cannot recognize the eliciting features.
Where Pith is reading between the lines
- Content moderation systems relying on prompt-based LLM self-assessment may miss social comparison triggers in generated material.
- Training on reader-grounded labels could help models handle other psychologically subtle cues beyond sentiment.
- The mismatch raises questions about whether generation and detection of social signals require fundamentally different model access methods.
Load-bearing premise
That first-person reader labels on Xiaohongshu posts accurately capture the stable psychological experience of social comparison rather than artifacts from the platform or labeling process.
What would settle it
A controlled test in which prompted LLMs classify XHS-SCoRE posts with accuracy matching or exceeding supervised in-domain baselines, or in which LLM-generated posts produce no measurable shift in readers' perceived standing or affect.
Figures
read the original abstract
We introduce Xiaohongshu Social Comparison Reader Elicitation (XHS-SCoRE), a reader-grounded benchmark for detecting whether text-only Xiaohongshu (RedNote) posts elicit Upward, Downward, or Neutral/no clear social comparison from a first-person reader perspective. The task targets a socially meaningful relational, behaviorally real signal not reducible to sentiment. Across prompted LLM classifiers and supervised Chinese encoders, we find a consistent generation--detection mismatch: the signal is textually learnable in-domain, but not robustly accessible to prompt-based classification. Prompted LLM classifiers show stable failures, especially neutralization of comparison-eliciting posts and model-specific directional skew. A controlled pilot shows that LLM-generated Xiaohongshu-style posts can shift perceived standing and comparison-related affect even when prompt-based detection of the same construct remains fragile. XHS-SCoRE contributes a benchmark for reader-grounded comparison detection and a diagnostic framework for studying when socially meaningful relational cues remain only partially visible to prompt-based inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the XHS-SCoRE benchmark consisting of Xiaohongshu (RedNote) posts labeled by first-person readers for eliciting upward, downward, or neutral social comparison. It reports that supervised Chinese encoder models learn the in-domain signal while prompted LLMs exhibit consistent failure modes (e.g., neutralization and directional skew) and cannot reliably detect it, despite a pilot showing that LLM-generated posts can still shift perceived standing and comparison-related affect.
Significance. If the reader labels validly index the intended psychological construct rather than platform artifacts, the work demonstrates a clear dissociation between LLMs' generative fluency and their prompt-based access to subtle relational signals. It supplies a new reader-grounded benchmark and diagnostic framework for studying partial visibility of psychologically meaningful cues, with credit due for the empirical mismatch finding and the controlled pilot design.
major comments (2)
- [Benchmark construction] Benchmark construction section: no inter-rater reliability, label distribution, test-retest stability, or correlation with established instruments (e.g., INCOM) is reported for the first-person XHS-SCoRE annotations. This is load-bearing because the central generation-detection mismatch claim and the supervised-model success both presuppose that the labels capture stable psychological social-comparison elicitation rather than annotation artifacts or Xiaohongshu stylistic regularities.
- [Pilot study] Pilot study section: the abstract and summary provide no details on sample size, statistical tests, confound controls, or how affect shifts were measured. Without these, the claim that LLM-generated posts shift comparison-related affect cannot be evaluated and remains preliminary, weakening the contrast with detection fragility.
minor comments (2)
- [Abstract] Abstract: the phrase 'stable, interpretable failure modes' is used without a concrete example (e.g., neutralization rate or skew direction); adding one would improve immediate clarity.
- [Terminology] Terminology: ensure 'UPWARD', 'DOWNWARD', and 'NEUTRAL' are defined once and used consistently in all tables and figures.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below, clarifying our methodological choices and indicating where revisions will be made to improve transparency.
read point-by-point responses
-
Referee: Benchmark construction section: no inter-rater reliability, label distribution, test-retest stability, or correlation with established instruments (e.g., INCOM) is reported for the first-person XHS-SCoRE annotations. This is load-bearing because the central generation-detection mismatch claim and the supervised-model success both presuppose that the labels capture stable psychological social-comparison elicitation rather than annotation artifacts or Xiaohongshu stylistic regularities.
Authors: We agree that greater transparency on the annotation process is warranted. In the revised manuscript we will report the full label distribution across UPWARD, DOWNWARD, and NEUTRAL categories. Inter-rater reliability statistics are not reported because the design intentionally collects first-person reader annotations; each label reflects an individual reader's subjective experience of comparison elicitation rather than an objective property of the post. Traditional IRR metrics are therefore not the appropriate validation criterion, and we will add an explicit discussion of this reader-grounded rationale in the limitations section. Test-retest stability and correlations with instruments such as INCOM were not collected in the present study; we will state this limitation clearly and identify it as a valuable direction for future validation. The fact that supervised Chinese encoders achieve strong in-domain performance nevertheless indicates that the labels encode a learnable signal that goes beyond platform-specific stylistic regularities. revision: partial
-
Referee: Pilot study section: the abstract and summary provide no details on sample size, statistical tests, confound controls, or how affect shifts were measured. Without these, the claim that LLM-generated posts shift comparison-related affect cannot be evaluated and remains preliminary, weakening the contrast with detection fragility.
Authors: We appreciate the referee highlighting the need for fuller reporting. Although the full manuscript contains the pilot details, the abstract and summary sections are indeed too terse. In the revision we will expand both the abstract and the dedicated pilot-study subsection to specify the sample size (N=50), the pre-post measurement of perceived standing and comparison-related affect, the use of paired statistical tests, and the confound controls (post length, topic category, and presentation order). These additions will allow readers to evaluate the pilot results directly and will strengthen the reported dissociation between generative capability and prompt-based detection. revision: yes
Circularity Check
No circularity: empirical benchmark and evaluation are externally grounded
full rationale
The paper constructs XHS-SCoRE from independent first-person reader annotations on Xiaohongshu posts and then reports direct empirical comparisons between prompted LLM classifiers and supervised Chinese encoder baselines. No equations or parameters are fitted and then relabeled as predictions; no self-citations supply load-bearing uniqueness theorems or ansatzes; the central mismatch claim is an observed performance gap on the externally labeled data rather than a definitional or self-referential reduction. The derivation chain consists of standard benchmark creation followed by standard model evaluation and remains self-contained against external reader judgments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Social comparison is a distinct relational signal separable from sentiment and reliably reportable by readers in first-person terms.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.