SplAttN: Bridging 2D and 3D with Gaussian Soft Splatting and Attention for Point Cloud Completion
Pith reviewed 2026-05-22 09:51 UTC · model grok-4.3
The pith
Differentiable Gaussian splatting replaces hard projection to prevent cross-modal entropy collapse and enable real use of visual cues in point cloud completion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
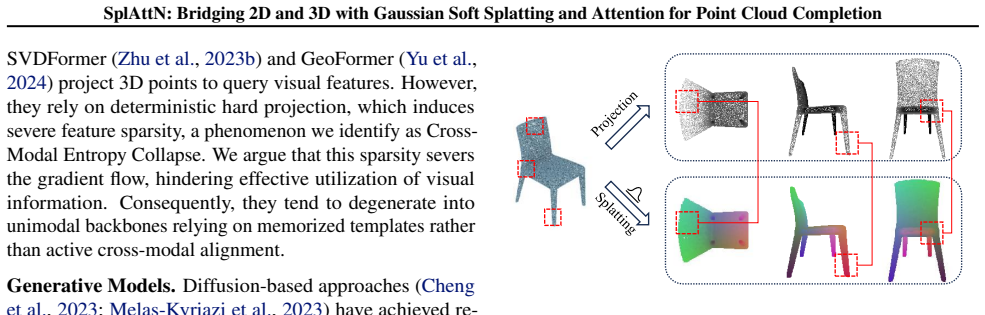
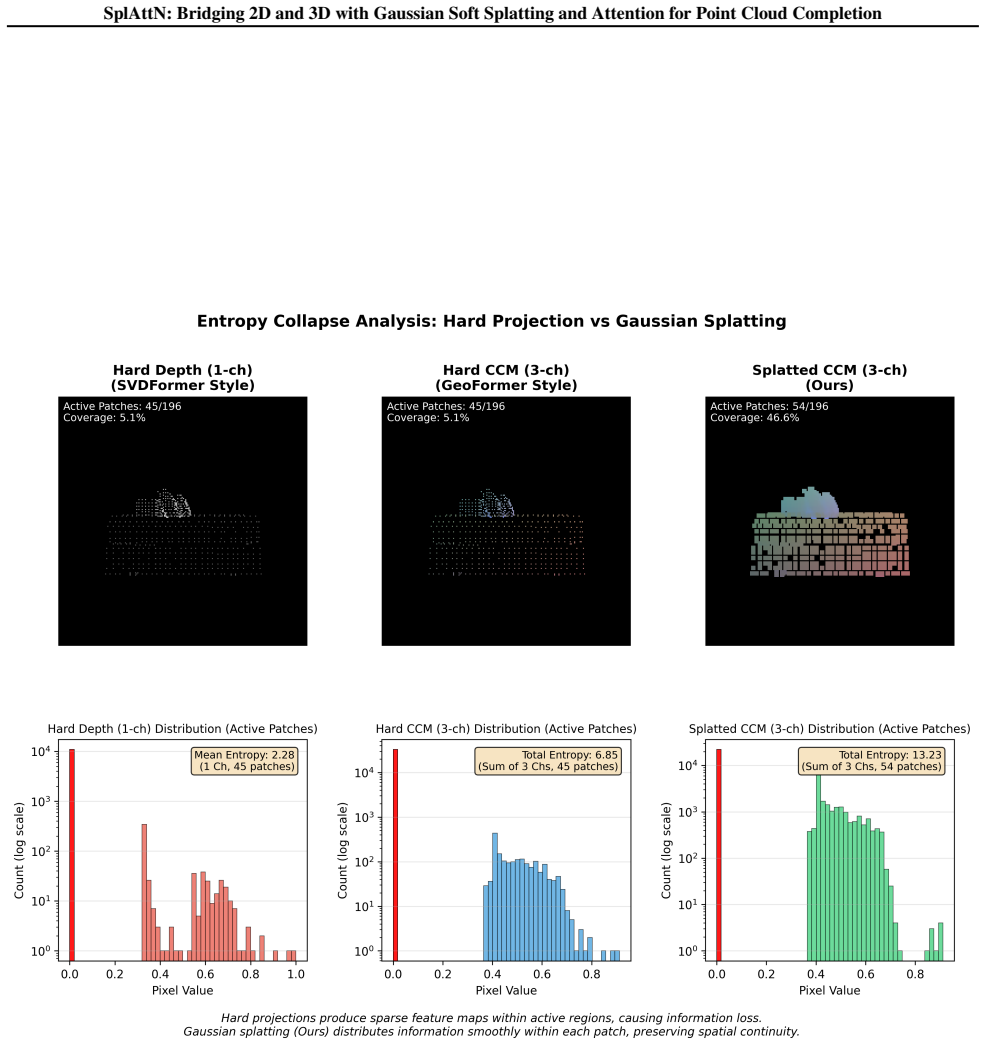
SplAttN identifies Cross-Modal Entropy Collapse as the result of hard projection severing modality connections, then addresses it by reformulating projection as continuous density estimation with differentiable Gaussian splatting, which produces dense support, improves learnability of visual priors, and yields an effective cross-modal connection validated by maintained performance dependence on image cues under counterfactual removal on real-world data.
What carries the argument
Differentiable Gaussian Splatting reformulated as continuous density estimation to produce dense image-plane representations from sparse point clouds, enabling visual prior propagation through the attention and completion pipeline.
If this is right
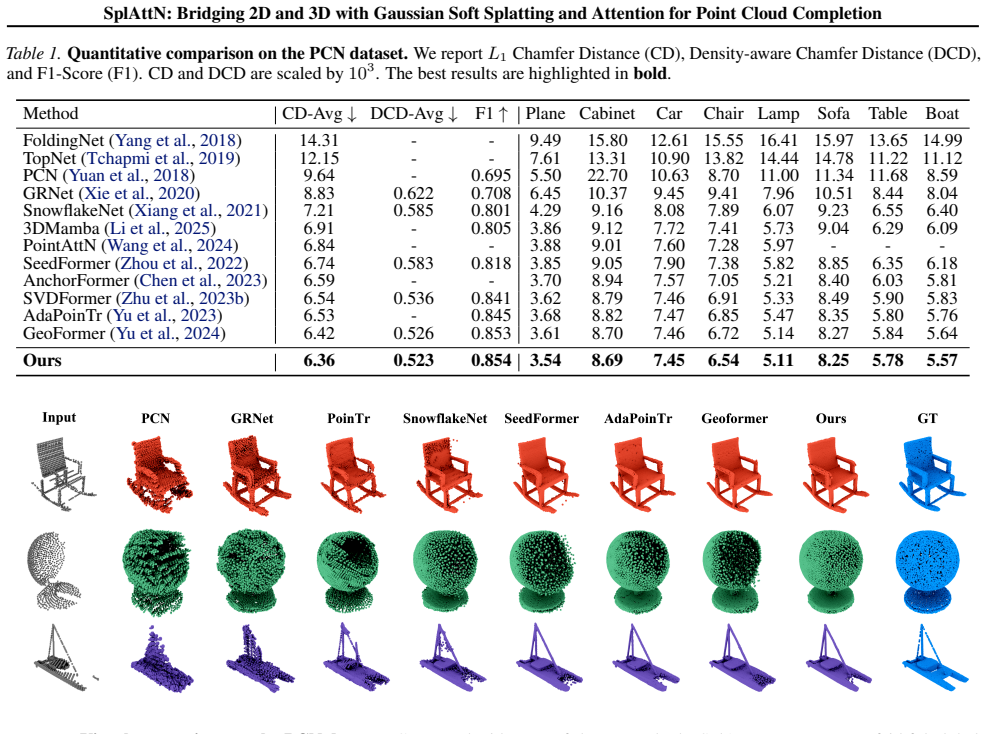
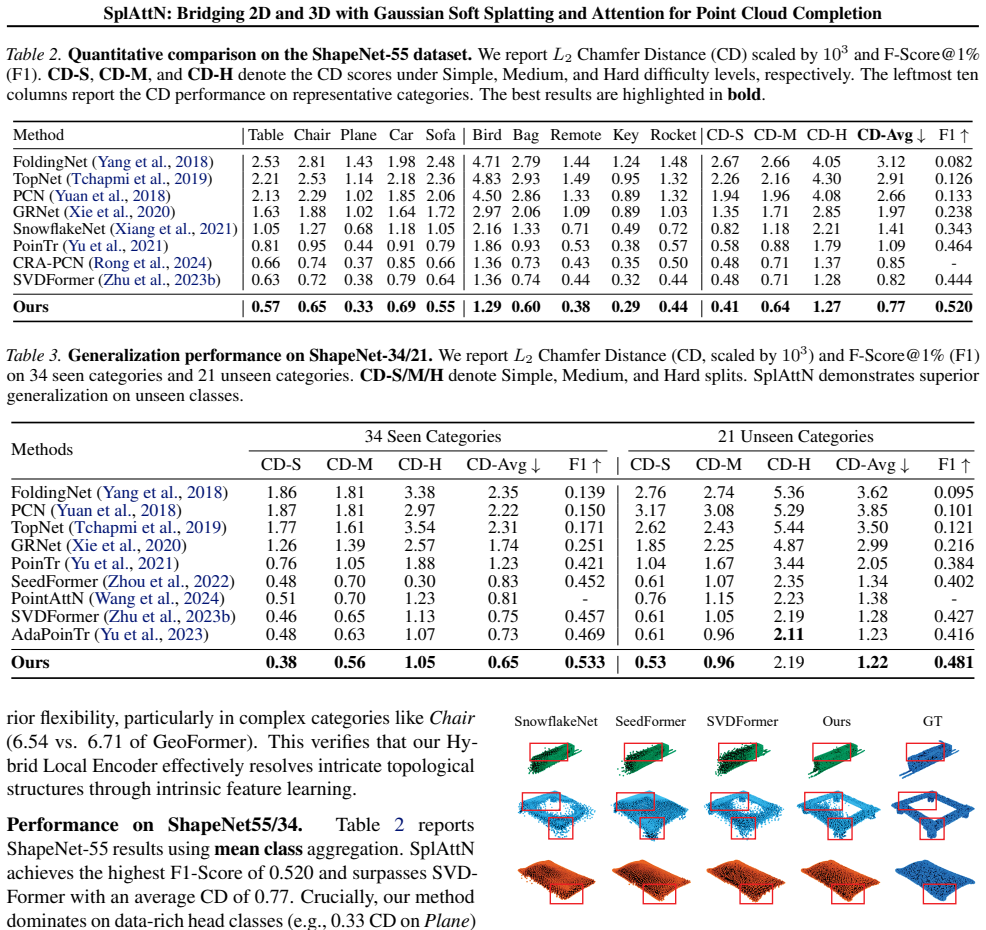
- State-of-the-art completion accuracy on the PCN and ShapeNet-55/34 benchmarks.
- Robust reliance on visual cues shown by counter-factual evaluation on KITTI, where baselines degrade into unimodal retrievers.
- Improved gradient flow and cross-modal connection learnability from the dense continuous representation.
- Avoidance of collapsed sparse support that otherwise hinders visual prior propagation.
Where Pith is reading between the lines
- The same soft-splatting replacement could be tested on other sparse-to-dense fusion tasks such as multi-view 3D reconstruction or sensor fusion for robotics.
- If the dense support already supplies most of the connection benefit, the attention layers might be simplified without loss of performance.
- Real-world deployment in settings with partial image occlusion would likely show larger gains for SplAttN than for hard-projection baselines.
Load-bearing premise
The main barrier to multi-modal benefits is the sparse support and entropy collapse from hard projection, and differentiable Gaussian splatting removes that barrier without introducing new confounding effects in attention or completion.
What would settle it
A controlled test that removes or masks the visual input on KITTI samples and checks whether SplAttN performance drops substantially more than baselines, or an ablation that swaps Gaussian splatting back to hard projection and measures the resulting drop in both accuracy and visual dependence.
Figures












read the original abstract
Although multi-modal learning has advanced point cloud completion, the theoretical mechanisms remain unclear. Recent works attribute success to the connection between modalities, yet we identify that standard hard projection severs this connection: projecting a sparse point cloud onto the image plane yields an extremely sparse support, which hinders visual prior propagation, a failure mode we term Cross-Modal Entropy Collapse. To address this practical limitation, we propose SplAttN, which replaces hard projection with Differentiable Gaussian Splatting to produce a dense, continuous image-plane representation. By reformulating projection as continuous density estimation, SplAttN avoids collapsed sparse support, facilitates gradient flow, and improves cross-modal connection learnability. Extensive experiments show that SplAttN achieves state-of-the-art performance on PCN and ShapeNet-55/34. Crucially, we utilize the real-world KITTI benchmark as a stress test for multi-modal reliance. Counter-factual evaluation reveals that while baselines degenerate into unimodal template retrievers insensitive to visual removal, SplAttN maintains a robust dependency on visual cues, validating that our method establishes an effective cross-modal connection. Code is available at https://github.com/zay002/SplAttN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies Cross-Modal Entropy Collapse as a failure mode arising from hard projection of sparse point clouds onto image planes, which produces extremely sparse support and severs visual prior propagation. SplAttN replaces this with Differentiable Gaussian Splatting to generate dense continuous image-plane representations, combined with an attention pipeline, to improve cross-modal learnability and gradient flow. It reports state-of-the-art results on PCN and ShapeNet-55/34, and uses a counter-factual evaluation on the real-world KITTI benchmark showing that SplAttN retains visual dependency while baselines collapse to unimodal template retrieval.
Significance. If the central claims hold, the work offers a concrete engineering response to a practical barrier in multi-modal point cloud completion by reformulating projection as continuous density estimation. Code availability and the use of KITTI as a stress test for modality reliance are strengths. The significance hinges on whether the observed robustness is causally tied to the splatting change rather than ancillary architectural modifications.
major comments (1)
- [Experiments (KITTI counter-factual)] KITTI counter-factual evaluation: the reported robustness of SplAttN to visual cue removal is presented as evidence of an effective cross-modal connection established by differentiable Gaussian splatting. However, SplAttN also introduces a new attention pipeline over the dense splatted features. Without an ablation that holds the attention module and overall capacity fixed while swapping only hard projection versus Gaussian soft splatting, the causal attribution to the projection reformulation remains under-supported and the stress-test result cannot isolate the claimed mechanism.
minor comments (2)
- [Abstract] The abstract states that SplAttN achieves SOTA on PCN and ShapeNet-55/34 but supplies no quantitative metrics, dataset splits, or baseline comparisons; a brief summary of key numbers would improve readability.
- [Introduction / Method] The term 'Cross-Modal Entropy Collapse' is introduced as a new failure mode; a short formal definition or entropy calculation in the method section would clarify its relation to standard projection sparsity.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful review. The feedback on isolating the contribution of differentiable Gaussian splatting in the KITTI counter-factual evaluation is well-taken, and we address it directly below.
read point-by-point responses
-
Referee: [Experiments (KITTI counter-factual)] KITTI counter-factual evaluation: the reported robustness of SplAttN to visual cue removal is presented as evidence of an effective cross-modal connection established by differentiable Gaussian splatting. However, SplAttN also introduces a new attention pipeline over the dense splatted features. Without an ablation that holds the attention module and overall capacity fixed while swapping only hard projection versus Gaussian soft splatting, the causal attribution to the projection reformulation remains under-supported and the stress-test result cannot isolate the claimed mechanism.
Authors: We agree that a controlled ablation isolating only the projection reformulation—while holding the attention module, overall capacity, and other architectural elements fixed—would provide stronger causal evidence for the role of differentiable Gaussian splatting in the observed robustness on KITTI. The attention pipeline is designed to operate on the dense continuous features produced by splatting, so the components are interdependent by design; however, this does not obviate the need for the requested isolation experiment. In the revised manuscript we will add this specific ablation to the KITTI counter-factual section, directly comparing hard projection versus Gaussian soft splatting under an otherwise identical attention-equipped architecture. This addition will clarify the mechanism and address the referee’s concern about ancillary modifications. revision: yes
Circularity Check
No circularity: empirical engineering response with independent counter-factual validation
full rationale
The paper identifies Cross-Modal Entropy Collapse as a practical failure mode of hard projection and proposes Differentiable Gaussian Splatting plus attention as a direct engineering fix to produce dense continuous representations and better gradient flow. No equations, derivations, or fitted parameters are presented that reduce the claimed cross-modal benefit to a self-referential definition or input by construction. The KITTI counter-factual evaluation (performance drop under visual removal) constitutes independent empirical evidence rather than a statistical tautology or self-citation load-bearing step. The method is self-contained against external benchmarks (PCN, ShapeNet, KITTI) with no uniqueness theorems, ansatzes smuggled via prior self-work, or renaming of known results as new derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Differentiable Gaussian splatting produces a dense continuous image-plane representation from sparse 3D points that facilitates gradient flow
invented entities (1)
-
Cross-Modal Entropy Collapse
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Lwarc(X, Y;λ) =λ·arccosh(1 +L CD(X, Y))
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Psof t(v|Pin) = 1/N sum αp G(v;π(p), σ) ... μ(Ssof t)≥μ(Shard) + ... >0 ... non-vanishing gradients
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
2018 international conference on 3D vision (3DV) , pages=
Pcn: Point completion network , author=. 2018 international conference on 3D vision (3DV) , pages=. 2018 , organization=
work page 2018
-
[2]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Foldingnet: Point cloud auto-encoder via deep grid deformation , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[3]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Topnet: Structural point cloud decoder , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[4]
European conference on computer vision , pages=
Grnet: Gridding residual network for dense point cloud completion , author=. European conference on computer vision , pages=. 2020 , organization=
work page 2020
-
[5]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Pmp-net: Point cloud completion by learning multi-step point moving paths , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[6]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Lake-net: Topology-aware point cloud completion by localizing aligned keypoints , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[7]
Proceedings of the AAAI Conference on artificial intelligence , volume=
Pointattn: You only need attention for point cloud completion , author=. Proceedings of the AAAI Conference on artificial intelligence , volume=
-
[8]
Wang, Xiaogang and , Marcelo H. Ang Jr. and Lee, Gim Hee , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[9]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Cascaded refinement network for point cloud completion , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[10]
Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence , pages=
Multi-modal point cloud completion with interleaved attention enhanced transformer , author=. Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence , pages=
-
[11]
European conference on computer vision , pages=
Detail preserved point cloud completion via separated feature aggregation , author=. European conference on computer vision , pages=. 2020 , organization=
work page 2020
-
[12]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Pointr: Diverse point cloud completion with geometry-aware transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[13]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Snowflakenet: Point cloud completion by snowflake point deconvolution with skip-transformer , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[14]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
PMP-Net++: Point cloud completion by transformer-enhanced multi-step point moving paths , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2022 , publisher=
work page 2022
-
[15]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Pointclip v2: Prompting clip and gpt for powerful 3d open-world learning , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[16]
European conference on computer vision , pages=
Seedformer: Patch seeds based point cloud completion with upsample transformer , author=. European conference on computer vision , pages=. 2022 , organization=
work page 2022
-
[17]
Yu, Xumin and Rao, Yongming and Wang, Ziyi and Lu, Jiwen and Zhou, Jie , title =. IEEE Trans. Pattern Anal. Mach. Intell. , month = dec, pages =. 2023 , issue_date =. doi:10.1109/TPAMI.2023.3309253 , abstract =
-
[18]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Anchorformer: Point cloud completion from discriminative nodes , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[19]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Hyperbolic chamfer distance for point cloud completion , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[20]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Svdformer: Complementing point cloud via self-view augmentation and self-structure dual-generator , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[21]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
SymmCompletion: High-Fidelity and High-Consistency Point Cloud Completion with Symmetry Guidance , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[22]
Forty-second International Conference on Machine Learning , year=
Unpaired Point Cloud Completion via Unbalanced Optimal Transport , author=. Forty-second International Conference on Machine Learning , year=
-
[23]
Advances in Neural Information Processing Systems , volume=
Cross-modal learning for image-guided point cloud shape completion , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Pulsar: Efficient sphere-based neural rendering , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[25]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[26]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Swin transformer: Hierarchical vision transformer using shifted windows , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[27]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Masked autoencoders are scalable vision learners , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[28]
Advances in neural information processing systems , volume=
Pointnet++: Deep hierarchical feature learning on point sets in a metric space , author=. Advances in neural information processing systems , volume=
-
[29]
International conference on machine learning , pages=
Mutual information neural estimation , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[30]
Representation Learning with Contrastive Predictive Coding
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[32]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
DC-PCN: Point Cloud Completion Network with Dual-Codebook Guided Quantization , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[33]
Differentiable surface splatting for point-based geometry processing , year =
Yifan, Wang and Serena, Felice and Wu, Shihao and \". Differentiable surface splatting for point-based geometry processing , year =. ACM Trans. Graph. , month = nov, articleno =. doi:10.1145/3355089.3356513 , abstract =
-
[34]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Softmax splatting for video frame interpolation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[35]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
Geoformer: Learning point cloud completion with tri-plane integrated transformer , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[36]
and Yuille, Alan and Tan, Mingxing , title =
Li, Yingwei and Yu, Adams Wei and Meng, Tianjian and Caine, Ben and Ngiam, Jiquan and Peng, Daiyi and Shen, Junyang and Lu, Yifeng and Zhou, Denny and Le, Quoc V. and Yuille, Alan and Tan, Mingxing , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2022 , pages =
work page 2022
-
[37]
European conference on computer vision , pages=
Tinyvit: Fast pretraining distillation for small vision transformers , author=. European conference on computer vision , pages=. 2022 , organization=
work page 2022
-
[38]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Zhang, Xuancheng and Feng, Yutong and Li, Siqi and Zou, Changqing and Wan, Hai and Zhao, Xibin and Guo, Yandong and Gao, Yue , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2021 , pages =
work page 2021
-
[39]
Li, Yixuan and Ma, Lipeng and Yang, Weidong and Fei, Ben , title =. ACM Trans. Multimedia Comput. Commun. Appl. , month = nov, keywords =. 2025 , publisher =. doi:10.1145/3774887 , abstract =
-
[40]
The international journal of robotics research , volume=
Vision meets robotics: The kitti dataset , author=. The international journal of robotics research , volume=. 2013 , publisher=
work page 2013
-
[41]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Cyclical Learning Rates for Training Neural Networks , author=. 2017 , eprint=
work page 2017
- [43]
-
[44]
Cheng, Yen-Chi and Lee, Hsin-Ying and Tulyakov, Sergey and Schwing, Alexander G. and Gui, Liang-Yan , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2023 , pages =
work page 2023
-
[45]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Melas-Kyriazi, Luke and Rupprecht, Christian and Vedaldi, Andrea , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2023 , pages =
work page 2023
-
[46]
Proceedings of the 29th ACM international conference on multimedia , pages=
Asfm-net: Asymmetrical siamese feature matching network for point completion , author=. Proceedings of the 29th ACM international conference on multimedia , pages=
-
[47]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Cra-pcn: Point cloud completion with intra-and inter-level cross-resolution transformers , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[48]
Computational visual media , volume=
Pct: Point cloud transformer , author=. Computational visual media , volume=. 2021 , publisher=
work page 2021
-
[49]
ACM Transactions on Graphics (tog) , volume=
Dynamic graph cnn for learning on point clouds , author=. ACM Transactions on Graphics (tog) , volume=. 2019 , publisher=
work page 2019
-
[50]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[51]
Intelligence & Robotics , VOLUME =
Dingchen Yang and Bowen Cao and Sanqing Qu and Fan Lu and Shangding Gu and Guang Chen , TITLE =. Intelligence & Robotics , VOLUME =. 2025 , NUMBER =
work page 2025
-
[52]
Intelligence & Robotics , VOLUME =
Zhengyi Lu and Yunhong Liao and Jia Li , TITLE =. Intelligence & Robotics , VOLUME =. 2025 , NUMBER =
work page 2025
-
[53]
Advances in neural information processing systems , volume=
Learning representations by maximizing mutual information across views , author=. Advances in neural information processing systems , volume=
-
[54]
Advances in Neural Information Processing Systems , volume=
Point cloud completion with pretrained text-to-image diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[55]
Advances in Neural Information Processing Systems , volume=
A theory of multimodal learning , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
The Thirteenth International Conference on Learning Representations , year=
SplatFormer: Point Transformer for Robust 3D Gaussian Splatting , author=. The Thirteenth International Conference on Learning Representations , year=
-
[57]
ACM SIGGRAPH 2024 conference papers , pages=
2d gaussian splatting for geometrically accurate radiance fields , author=. ACM SIGGRAPH 2024 conference papers , pages=
work page 2024
-
[58]
Proceedings of the 29th ACM International Conference on Multimedia , pages =
Xia, Yaqi and Xia, Yan and Li, Wei and Song, Rui and Cao, Kailang and Stilla, Uwe , title =. Proceedings of the 29th ACM International Conference on Multimedia , pages =. 2021 , isbn =. doi:10.1145/3474085.3475348 , abstract =
-
[59]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
View-guided point cloud completion , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[60]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Point transformer , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[61]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Variational relational point completion network , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[62]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Proxyformer: Proxy alignment assisted point cloud completion with missing part sensitive transformer , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[63]
European Conference on Computer Vision , pages=
Fbnet: Feedback network for point cloud completion , author=. European Conference on Computer Vision , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.