Posterior-First Neural PDE Simulation: Inferring Hidden Problem State from a Single Field
Pith reviewed 2026-05-07 17:48 UTC · model grok-4.3
The pith
Inferring a posterior over hidden problem states from a single field improves neural PDE rollout accuracy by avoiding deterministic collapse.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that posterior-first neural PDE simulation—recovering the posterior over the minimal task-sufficient problem state from one observed field before conditioning prediction—prevents the ambiguity barrier incurred by deterministic field-to-future collapse and produces lower rollout error whenever the true posterior is non-Dirac.
What carries the argument
The posterior over the minimal task-sufficient problem state, which encodes residual ambiguity and lets Bayes-optimal downstream values factor through it.
If this is right
- Deterministic predictors incur an ambiguity barrier whose magnitude equals the expected divergence from the true posterior.
- Proper scoring rules on refinement labels suffice to learn the posterior without supervision on the hidden state itself.
- Posterior-conditioned rollouts reduce normalized error from 0.175 to 0.132 on metadata-hidden PDEBench tasks.
- Synthetic exact-ambiguity tests show point-versus-posterior gaps match the size of the predicted barrier.
Where Pith is reading between the lines
- The separation of posterior inference from prediction could extend to other partial-observation forecasting problems such as video or climate sequences.
- If the minimal state is low-dimensional, the approach might lower the amount of training data needed for reliable long-horizon simulation.
- Sampling multiple futures from the recovered posterior could improve robustness when the simulator is used inside control or optimization loops.
Load-bearing premise
A minimal task-sufficient problem state exists whose posterior can be recovered accurately from a single field using only proper scoring rules and no extra supervision.
What would settle it
A synthetic PDE experiment in which the single observed field is statistically independent of the hidden parameters, so that the inferred posterior stays uniform and rollout error shows no improvement over direct prediction.
Figures
read the original abstract
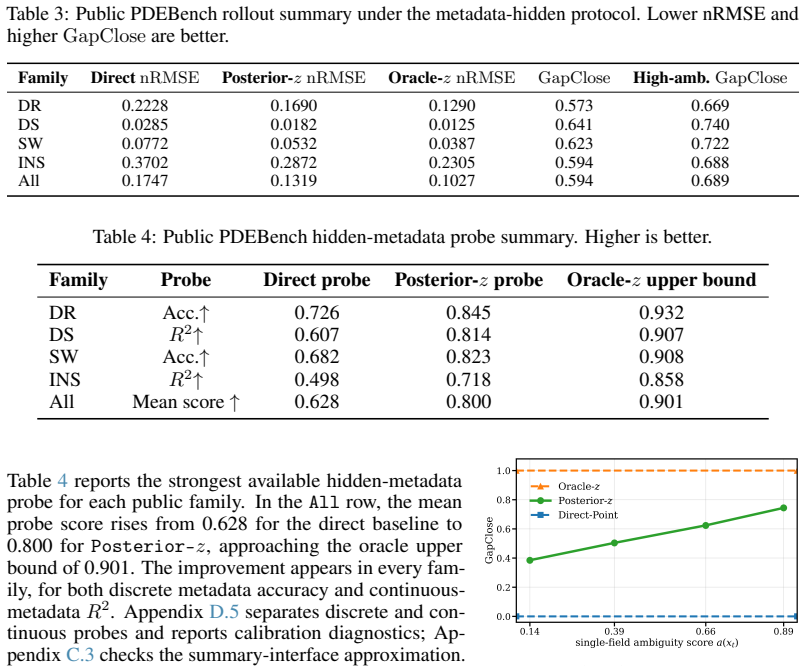
Neural PDE simulators often receive only a single observed field at deployment. In this setting, a field-to-future predictor can collapse distinct latent problem states into the same deterministic interface, losing the ambiguity needed for reliable rollout and downstream decisions. We propose posterior-first neural PDE simulation: first infer a posterior over the minimal task-sufficient problem state, then condition prediction on that posterior. The resulting theory connects the object, the learning target, and the failure mode: Bayes downstream values factor through this posterior, refinement labels make it learnable by proper scoring rules, and deterministic collapse incurs an ambiguity barrier whenever the true posterior is non-Dirac. Synthetic exact-ambiguity experiments show that point-versus-posterior gaps track the predicted barrier. On metadata-hidden PDEBench tasks, posterior recovery reduces pooled rollout nRMSE from 0.175 to 0.132, closing 59.4% of the direct-to-oracle gap. These results suggest that single-observation neural PDE simulation should be posterior-first rather than monolithic field-to-future prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes posterior-first neural PDE simulation for scenarios where only a single observed field is available at deployment. It argues that direct field-to-future predictors suffer from deterministic collapse, losing ambiguity. Instead, the approach infers a posterior over the minimal task-sufficient problem state from the single field using proper scoring rules trained on refinement labels, then conditions the neural simulator on samples from this posterior. Theoretical analysis shows that Bayes downstream values factor through this posterior, and deterministic predictors incur an ambiguity barrier when the true posterior is non-Dirac. Experiments include synthetic tests confirming the barrier and PDEBench tasks where the method reduces pooled rollout nRMSE from 0.175 to 0.132, closing 59.4% of the direct-to-oracle gap.
Significance. If the results hold, this work offers a significant conceptual shift in neural PDE simulation by emphasizing posterior inference over hidden states to mitigate ambiguity in single-observation settings. The linkage between the theoretical framework (Bayes factorization and proper scoring rules) and empirical validation on both controlled synthetic cases and real PDEBench benchmarks strengthens the contribution. Explicit credit is due for the reproducible synthetic experiments that directly test the predicted ambiguity barrier and for quantifying the practical improvement in terms of gap closure to an oracle.
major comments (2)
- [§3] §3: The factorization of Bayes downstream values through the posterior and the claim that refinement labels make the posterior learnable via proper scoring rules are load-bearing for the posterior-first justification, but the manuscript provides no derivation details, proof sketch, or specific scoring rule implementation to support these connections.
- [PDEBench results (likely §5)] PDEBench results (likely §5): The reported reduction in pooled rollout nRMSE from 0.175 to 0.132 (closing 59.4% of the direct-to-oracle gap) is a central empirical claim, but it lacks error bars, standard deviations across runs, or details on the number of independent trials and seeds, preventing assessment of statistical reliability.
minor comments (2)
- [Abstract and Introduction] The term 'refinement labels' is used without an immediate definition or forward reference in the abstract and introduction, which may confuse readers new to the concept.
- [§2] Notation for the posterior distribution and the 'minimal task-sufficient problem state' could be introduced with a clear equation or diagram early in the paper to improve readability.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of the conceptual contribution and for the detailed major comments. We address each point below and will revise the manuscript accordingly to strengthen the theoretical exposition and empirical reporting.
read point-by-point responses
-
Referee: [§3] §3: The factorization of Bayes downstream values through the posterior and the claim that refinement labels make the posterior learnable via proper scoring rules are load-bearing for the posterior-first justification, but the manuscript provides no derivation details, proof sketch, or specific scoring rule implementation to support these connections.
Authors: We agree that the connections in §3 are central and that the current manuscript presents them at a high level without a full derivation. The factorization follows from applying the law of total expectation to the downstream value function, showing that it depends on the hidden state only through the posterior over the minimal task-sufficient state. Learnability with refinement labels follows because those labels are drawn from the true posterior, so a strictly proper scoring rule (such as the logarithmic score, implemented via cross-entropy) yields a consistent estimator of the posterior. We will add an explicit proof sketch and the precise scoring-rule implementation to the revised §3. revision: yes
-
Referee: PDEBench results (likely §5): The reported reduction in pooled rollout nRMSE from 0.175 to 0.132 (closing 59.4% of the direct-to-oracle gap) is a central empirical claim, but it lacks error bars, standard deviations across runs, or details on the number of independent trials and seeds, preventing assessment of statistical reliability.
Authors: The referee correctly notes that the PDEBench results are presented as single aggregated values without variability measures. The manuscript reports results from one training run per method on the pooled test set. In the revision we will rerun the PDEBench experiments with at least five independent random seeds, report the mean and standard deviation of the nRMSE values, and include error bars on the key figures. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper's central claims rest on a theoretical factorization of Bayes downstream risk through an inferred posterior over a minimal task-sufficient state, with learnability via proper scoring rules on refinement labels and an ambiguity barrier for deterministic collapse. These elements are introduced as independent theoretical connections rather than reductions to fitted inputs, self-citations, or ansatzes. The synthetic experiments directly test the predicted barrier, and PDEBench results quantify empirical gap closure without evidence of self-referential definitions or load-bearing prior work by the same authors. No equations or derivations in the abstract or described content reduce by construction to the reported outcomes.
Axiom & Free-Parameter Ledger
invented entities (1)
-
minimal task-sufficient problem state
no independent evidence
Reference graph
Works this paper leans on
-
[1]
B., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A
Li, Z., Kovachki, N. B., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A. M., and Anandkumar, A. (2021). Fourier Neural Operator for Parametric Partial Differential Equations. InInternational Conference on Learning Representations
work page 2021
-
[2]
Lu, L., Jin, P., Pang, G., Zhang, Z., and Karniadakis, G. E. (2021). Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators.Nature Machine Intelligence, 3, 218–229
work page 2021
-
[3]
Lippe, P., Veeling, B., Perdikaris, P., Turner, R., and Brandstetter, J. (2023). PDE-Refiner: Achieving Accurate Long Rollouts with Neural PDE Solvers.Advances in Neural Information Processing Systems, 36, 67398–67433
work page 2023
-
[7]
Zhou, H., et al. (2025). Unisolver: PDE-Conditional Transformers Towards Universal Neural PDE Solvers. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 79061–79088
work page 2025
-
[8]
Liu, Y ., Zhang, Z., and Schaeffer, H. (2024). PROSE: Predicting Multiple Operators and Symbolic Expressions using multimodal transformers.Neural Networks, 180, 106707
work page 2024
-
[9]
Yang, L., et al. (2023). In-context operator learning with data prompts for differential equation problems. Proceedings of the National Academy of Sciences, 120(39), e2310142120
work page 2023
-
[10]
Morel, R., Han, J., and Oyallon, E. (2025). DISCO: learning to DISCover an evolution Operator for multi-physics-agnostic prediction. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 44750–44774
work page 2025
-
[11]
Serrano, L., et al. (2025). Zebra: In-Context Generative Pretraining for Solving Parametric PDEs. In Proceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 53940–53988
work page 2025
-
[12]
Williams, J. P., Zahn, O., and Kutz, J. N. (2024). Sensing with shallow recurrent decoder networks. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 480(2298), 20240054
work page 2024
-
[13]
Raissi, M., Yazdani, A., and Karniadakis, G. E. (2020). Hidden fluid mechanics: Learning velocity and pressure fields from flow visualizations.Science, 367(6481), 1026–1030
work page 2020
-
[14]
Raissi, M., Perdikaris, P., and Karniadakis, G. E. (2019). Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational Physics, 378, 686–707
work page 2019
-
[15]
Raissi, M. (2018). Deep Hidden Physics Models: Deep Learning of Nonlinear Partial Differential Equations. Journal of Machine Learning Research, 19(25), 1–24
work page 2018
-
[16]
Buitrago Ruiz, R., Marwah, T., Gu, A., and Risteski, A. (2025). On the Benefits of Memory for Modeling Time-Dependent PDEs. InInternational Conference on Learning Representations
work page 2025
-
[17]
Magnani, E., Krämer, N., Eschenhagen, R., Rosasco, L., and Hennig, P. (2025). Approximate Bayesian Neural Operators: Uncertainty Quantification for Parametric PDEs.Transactions on Machine Learning Research
work page 2025
-
[18]
Kaltenbach, S., Perdikaris, P., and Koutsourelakis, P.-S. (2023). Semi-supervised invertible neural operators for Bayesian inverse problems.Computational Mechanics, 72(3), 451–470
work page 2023
-
[19]
Takamoto, M., Praditia, T., Leiteritz, R., MacKinlay, D., Alesiani, F., Pflüger, D., and Niepert, M. (2022). PDEBench: An Extensive Benchmark for Scientific Machine Learning. In36th Conference on Neural Information Processing Systems (NeurIPS 2022) Track on Datasets and Benchmarks. 10
work page 2022
-
[20]
Gray, P. and Scott, S. K. (1984). Autocatalytic reactions in the isothermal, continuous stirred tank reactor: Oscillations and instabilities in the system A+ 2B→3B , B→C .Chemical Engineering Science, 39(6), 1087–1097
work page 1984
-
[21]
Pearson, J. E. (1993). Complex patterns in a simple system.Science, 261(5118), 189–192
work page 1993
-
[22]
Ronneberger, O., Fischer, P., and Brox, T. (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation. InMedical Image Computing and Computer-Assisted Intervention, volume 9351 ofLecture Notes in Computer Science, pages 234–241. Springer
work page 2015
-
[23]
Shi, X., Chen, Z., Wang, H., Yeung, D.-Y ., Wong, W.-K., and Woo, W.-C. (2015). Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. InAdvances in Neural Information Processing Systems, 28, 802–810
work page 2015
-
[24]
Vaswani, A., et al. (2017). Attention Is All You Need. InAdvances in Neural Information Processing Systems, 30
work page 2017
-
[25]
Cranmer, K., Brehmer, J., and Louppe, G. (2020). The frontier of simulation-based inference.Proceedings of the National Academy of Sciences, 117(48), 30055–30062
work page 2020
-
[26]
Radev, S. T., Mertens, U. K., V oss, A., Ardizzone, L., and Köthe, U. (2022). BayesFlow: Learning Complex Stochastic Models With Invertible Neural Networks.IEEE Transactions on Neural Networks and Learning Systems, 33(4), 1452–1466
work page 2022
-
[27]
Tejero-Cantero, A., Boelts, J., Deistler, M., Lueckmann, J.-M., Durkan, C., Gonçalves, P. J., Greenberg, D. S., and Macke, J. H. (2020). sbi: A toolkit for simulation-based inference.Journal of Open Source Software, 5(52), 2505
work page 2020
-
[28]
Lehmann, E. L. and Casella, G. (1998).Theory of Point Estimation. Springer, New York, 2nd edition
work page 1998
-
[29]
Lakshminarayanan, B., Pritzel, A., and Blundell, C. (2017). Simple and Scalable Predictive Uncertainty Estimation Using Deep Ensembles. InAdvances in Neural Information Processing Systems, 30
work page 2017
-
[30]
Seq.” denotes released trajectories; “seg
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., and Dean, J. (2017). Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. InInternational Conference on Learning Representations. 11 Contents of Appendices A Posterior Problem-State Formulation: Detailed Derivations . . . . . . . . . . . . . . . . . . . . ...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.