Random test functions, H⁻¹ norm equivalence, and stochastic variational physics-informed neural networks
Pith reviewed 2026-05-07 14:49 UTC · model grok-4.3
The pith
The H^{-1} norm of any functional is equivalent to its expected squared evaluation against a random test function whose distribution depends only on the domain.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that the H^{-1} norm of any functional is equivalent to its expected squared evaluation against a random test function whose distribution depends only on the domain. Realisations of this random test function have negative Sobolev regularity for d greater than or equal to 2, yet this roughness does not prevent averaging over the distribution from exactly recovering the correct weak topology, independently of the differential operator. This equivalence introduces stochastically weak solutions, which coincide with classical weak solutions, and motivates stochastic variational physics-informed neural networks trained by minimising an empirical approximation of the stocha
What carries the argument
A domain-dependent probability distribution over test functions such that the expected value of the squared pairing with any functional recovers the H^{-1} norm and the associated weak topology.
Load-bearing premise
There exists a distribution over random test functions, depending only on the domain, for which the expected squared evaluation exactly equals the H^{-1} norm of the functional for any functional.
What would settle it
A concrete counterexample consisting of a domain, a specific functional, and its H^{-1} norm that does not match the computed expectation over samples from the proposed random test function distribution.
Figures









read the original abstract
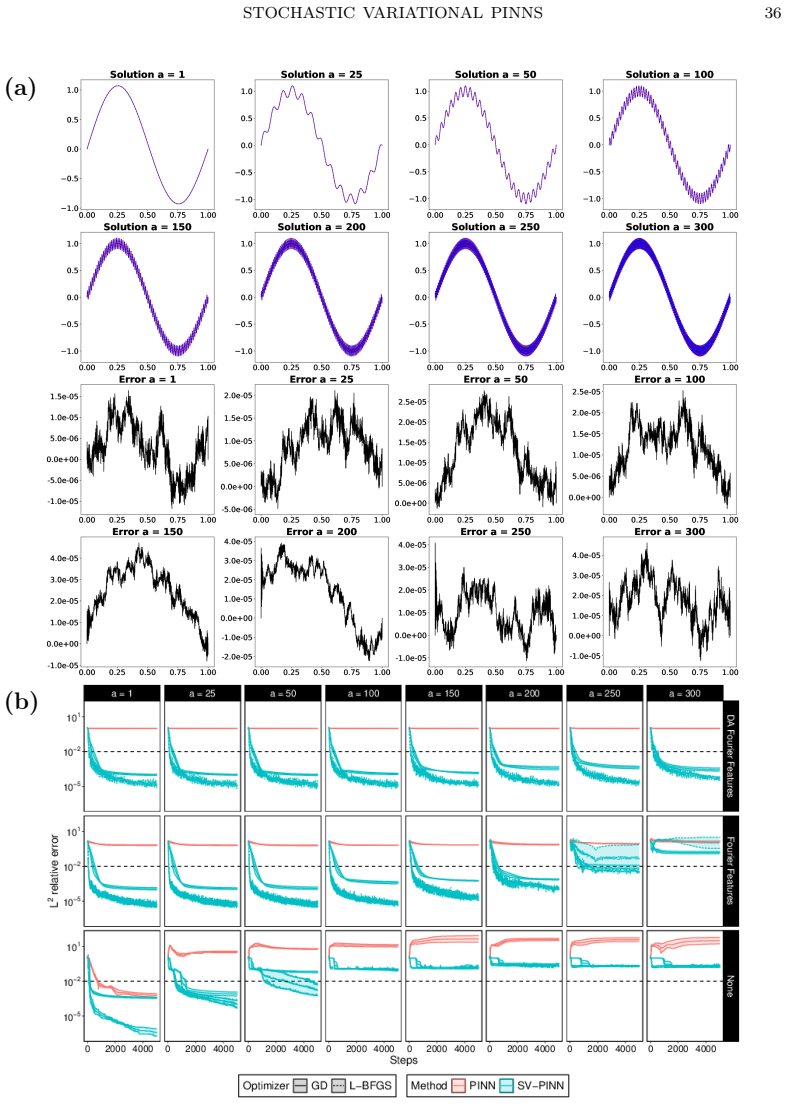
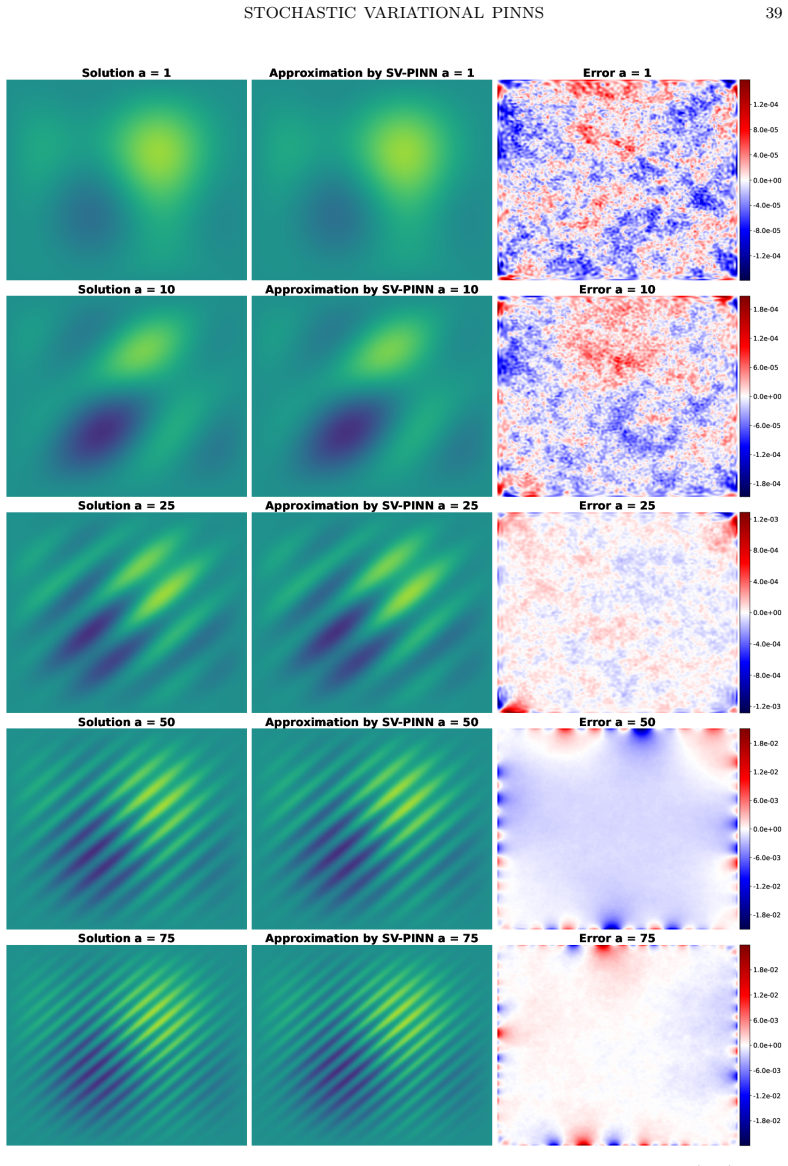
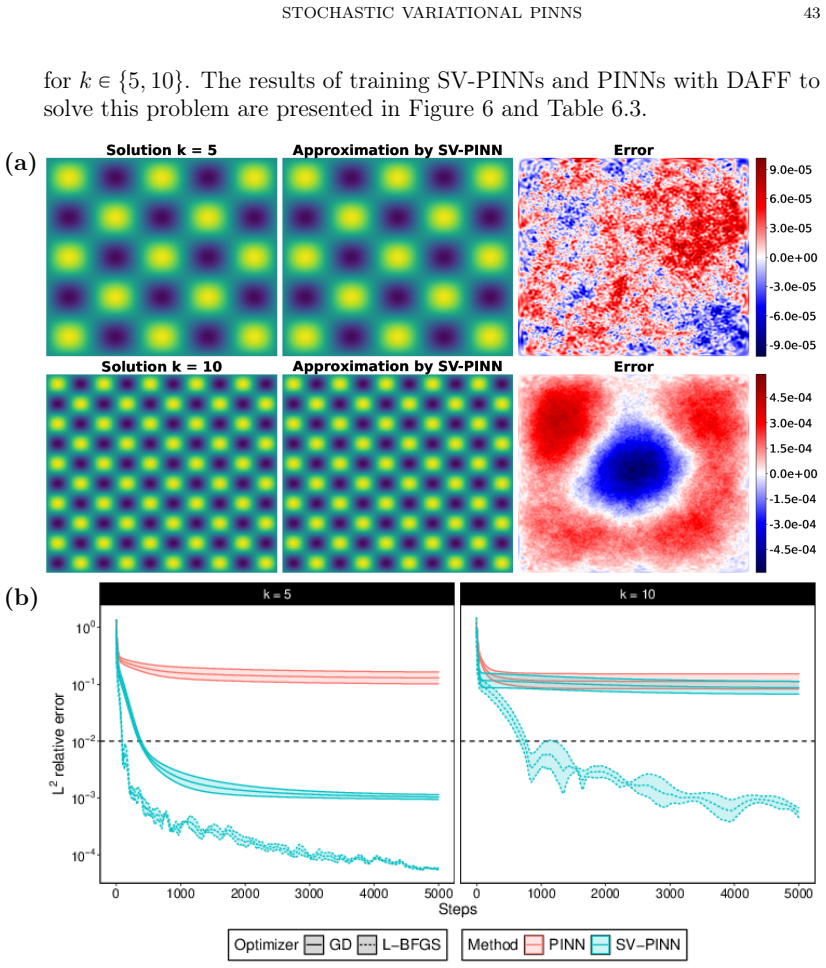
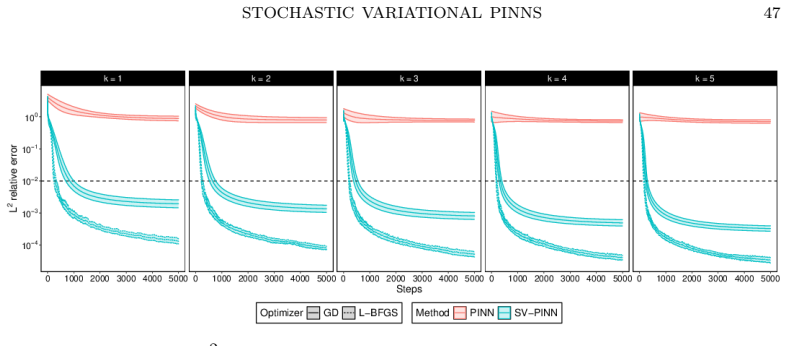
The dual norm characterisation of weak solutions of second-order linear elliptic partial differential equations is mathematically natural but computationally intractable: evaluating the $H^{-1}$ norm of the residual requires a supremum over an infinite-dimensional test space. We prove that the $H^{-1}$ norm of any functional is equivalent to its expected squared evaluation against a random test function whose probability distribution depends only on the domain. Crucially, realisations of this random test function have negative Sobolev regularity for $d \geq 2$, yet this roughness is not an obstacle: averaging over the distribution exactly recovers the correct weak topology, independently of the differential operator, and no supremum evaluation is necessary. This equivalence introduces the notion of stochastically weak solutions, which coincide with classical weak solutions, and motivates stochastic variational physics-informed neural networks (SV-PINNs): neural networks trained by minimising an empirical approximation of the stochastic norm of the PDE residual. Although instantiated here with neural networks, the underlying principle is independent of the trial space and suggests a broader paradigm for numerical methods based on stochastic rather than deterministic test spaces. The framework extends naturally to higher-order elliptic, parabolic and hyperbolic equations and to abstract operator equations on Hilbert spaces. As a proof of concept, we present numerical experiments on eight challenging second-order linear elliptic problems spanning high-frequency and multi-scale solutions, indefinite operators, variable coefficients, and non-standard domains, in which SV-PINNs consistently and significantly outperform standard PINNs, recovering solutions to within one percent relative error in hundreds of L-BFGS steps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proves that the H^{-1} norm of any functional is equivalent to the square root of its expected squared pairing against a random test function whose law depends only on the domain. This equivalence is independent of the differential operator, yields stochastically weak solutions that coincide with classical weak solutions, and motivates SV-PINNs: neural networks trained by minimizing an empirical Monte-Carlo approximation to the stochastic residual norm. The framework is illustrated on eight second-order linear elliptic problems (high-frequency, multi-scale, indefinite, variable-coefficient, non-standard domains) where SV-PINNs recover solutions to within 1% relative error in a few hundred L-BFGS iterations and consistently outperform standard PINNs.
Significance. If the equivalence is rigorously established, the work supplies a computationally tractable, operator-independent surrogate for the dual norm that removes the need to solve auxiliary supremum problems. This is a genuine advance for variational PINNs and related mesh-free methods. The numerical evidence on a deliberately diverse test suite, together with the claim that negative Sobolev regularity of the random fields does not obstruct recovery of the H^{-1} topology, strengthens the practical case. The extension sketched to higher-order, parabolic, hyperbolic and abstract Hilbert-space problems further increases potential impact.
minor comments (2)
- [Abstract] Abstract: the statement that solutions are recovered “to within one percent relative error” should specify the norm (L^2, H^1, etc.) in which the error is measured and indicate whether the figure is an average or worst-case value over the eight test problems.
- [Numerical experiments] Implementation details for sampling the random test functions (discretization of the covariance operator, number of Monte-Carlo samples per loss evaluation, and handling of the negative-order regularity for d ≥ 2) are only sketched; a short algorithmic box or pseudocode would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive and encouraging report, which accurately summarizes the main theoretical result on the H^{-1} equivalence and its use in SV-PINNs, as well as the numerical experiments on diverse elliptic problems. We appreciate the assessment of significance and the recommendation for minor revision.
Circularity Check
No significant circularity
full rationale
The paper's central result is a functional-analytic existence proof: there exists a random test function distribution (depending only on the domain) such that the expected squared duality pairing recovers the H^{-1} norm exactly. This is achieved by taking the covariance operator of the random field to be the inverse Riesz map of the H^1_0 inner product, which is a standard, operator-independent construction on the domain. The equivalence therefore holds by the definition of covariance and the Riesz representation theorem, but this constitutes a valid mathematical demonstration rather than a self-referential loop or a fitted quantity renamed as a prediction. No load-bearing step in the derivation reduces to its own inputs by construction; the subsequent SV-PINN training procedure follows from the established equivalence without circularity. The argument is self-contained against external functional-analytic benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard properties of Sobolev spaces H^1 and its dual H^{-1} for second-order elliptic operators
- ad hoc to paper Existence of a random test-function distribution depending only on the domain such that expectation of squared evaluations recovers the H^{-1} norm independently of the operator
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.