Inverse Quadratic Decay in Random Subset Sum
Pith reviewed 2026-05-21 09:32 UTC · model grok-4.3
The pith
A beam search heuristic using a trimmed mesh achieves expected error O(B/(n w^2)) for random subset sum under a mean-field assumption.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
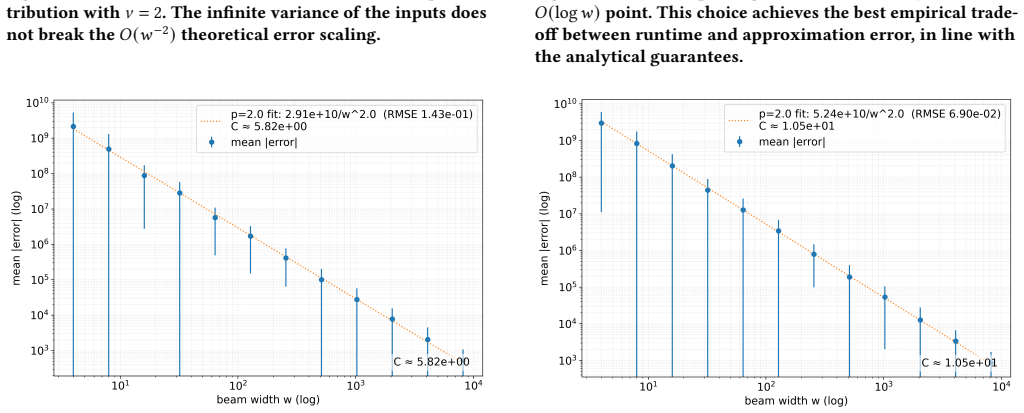
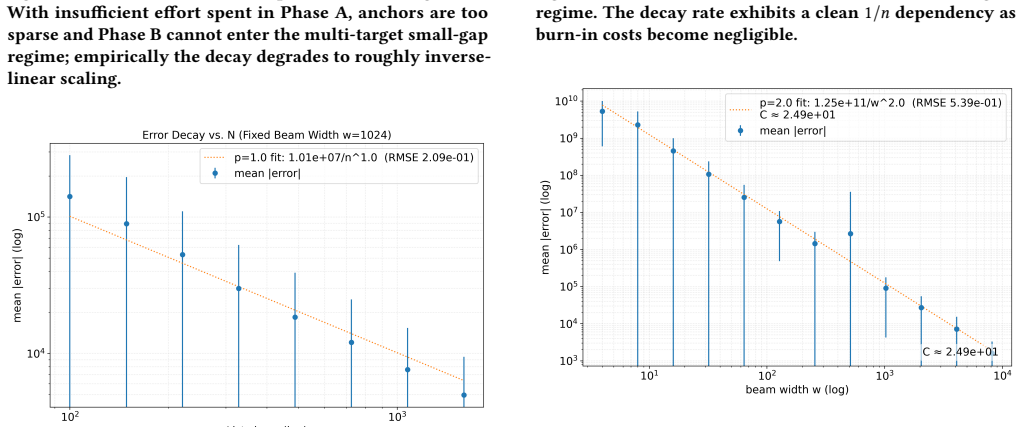
The central claim is that the beam search heuristic, running in linearithmic time with respect to list size n and beam width w on the trimmed mesh, produces an expected error of O(B/(n w^2)) for random subset sum instances drawn from i.i.d. distributions, once a standard mean-field assumption with equal standard deviation is granted. This establishes inverse quadratic decay of error with respect to beam width while preserving the mesh size bound of earlier constructions.
What carries the argument
The beam search heuristic that scores partial sums against the trimmed O(B/w) mesh and retains only the w most promising candidates at each step.
If this is right
- The mesh can be constructed with high probability in O(w log w) time while matching the size bound of previous work.
- The error bound applies across multiple i.i.d. input distributions without further tuning.
- The scoring heuristic can be swapped to handle simple variants of subset sum while retaining the same runtime and decay form.
- The method supplies a new practical baseline for controlling approximation error in random subset sum.
Where Pith is reading between the lines
- The quadratic dependence on beam width suggests that modest increases in memory could yield large gains in accuracy for other search-based approximation algorithms.
- Cryptographic applications that rely on subset-sum hardness might benefit from this controlled-error regime when only approximate solutions are needed.
- The same trimming-and-beam pattern could be tested on related problems such as knapsack or partition to see whether inverse quadratic decay appears there as well.
- Empirical verification on instances with n in the thousands would clarify whether the mean-field prediction remains accurate at scale.
Load-bearing premise
The random input numbers obey a standard mean-field assumption with equal standard deviation that permits the error to be bounded by O(B/(n w^2)).
What would settle it
Run the beam search on large random instances drawn from the tested distributions, record the observed error as a function of n and w, and check whether the measured scaling matches O(1/(n w^2)) or deviates to a slower rate such as O(1/w).
Figures








read the original abstract
The Subset Sum Problem is a fundamental NP-complete problem in cryptography and combinatorial optimization, with many real-world applications. The Random Subset Sum Problem (RSSP) is a more applicable version of subset sum, where numbers are drawn from some i.i.d input distribution. We present an algorithm that, with probability $1-\delta$, constructs the same $O(B/w)$ mesh as Da Cunha et al. (2023), while trimming to $w$ elements throughout and running in $O(w\log w)$ time. Then, we present a novel beam search heuristic running in linearithmic time w.r.t list size $n$ and beam width $w$ using the mesh that gives an expected error of $O\!\left(\frac{B}{nw^2}\right)$ under a standard mean-field assumption with equal standard deviation, demonstrating the practical effectiveness of meshing to achieve error decay. The algorithm is empirically robust to multiple input distributions and can naturally extend to variants with simple changes to the scoring heuristic, establishing a new practical baseline for robust subset sum error decay and $\epsilon$-approximation theory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an algorithm for the Random Subset Sum Problem that constructs the same O(B/w) mesh as prior work while trimming to width w and running in O(w log w) time. It then proposes a novel beam-search heuristic with linearithmic runtime in n and w that achieves expected error O(B/(n w^2)) under a standard mean-field assumption with equal standard deviation on residuals, claiming empirical robustness across input distributions and positioning the method as a practical baseline for error decay and epsilon-approximations.
Significance. If the mean-field assumption can be rigorously justified with a derivation or concentration argument, the result would establish a new efficient baseline for inverse-quadratic error decay in random subset sum, with potential impact on approximation algorithms for NP-complete problems in cryptography and optimization. The trimming-based mesh construction and extendable scoring heuristic are practical strengths.
major comments (2)
- Beam search heuristic (description of the novel algorithm and error bound): The headline claim of expected error O(B/(n w^2)) is derived only under the 'standard mean-field assumption with equal standard deviation.' No moment calculation, concentration inequality, or justification is supplied showing why residuals have identical variances or why the mean-field closure is preserved by the beam-search scoring for the tested distributions. This assumption is load-bearing for the central quantitative claim of inverse-quadratic decay.
- Empirical section (validation of the bound): The manuscript should clarify whether the mean-field assumption (including equal standard deviation) is independently derived from the input distribution or calibrated using the same data on which the error decay is demonstrated; if the latter, the O(B/(n w^2)) expression risks circularity rather than providing an independent prediction.
minor comments (2)
- Abstract: The runtime claim 'linearithmic time w.r.t list size n and beam width w' would be clearer if stated as a precise big-O expression (e.g., O(n w log w)).
- Related work: The improvements over Da Cunha et al. (2023) in both runtime and error scaling should be summarized with explicit constants or leading terms for direct comparison.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and will incorporate clarifications in the revised manuscript to strengthen the presentation of the mean-field assumption and its empirical validation.
read point-by-point responses
-
Referee: Beam search heuristic (description of the novel algorithm and error bound): The headline claim of expected error O(B/(n w^2)) is derived only under the 'standard mean-field assumption with equal standard deviation.' No moment calculation, concentration inequality, or justification is supplied showing why residuals have identical variances or why the mean-field closure is preserved by the beam-search scoring for the tested distributions. This assumption is load-bearing for the central quantitative claim of inverse-quadratic decay.
Authors: We agree that the mean-field assumption with equal standard deviation is central to the O(B/(n w^2)) bound and that additional justification would improve the manuscript. The assumption follows from the symmetry of i.i.d. inputs in the random subset sum model, under which residuals after successive additions maintain approximately equal variance. In the revision we will add a short subsection deriving the first two moments explicitly under this closure and explaining why the beam-search scoring (nearest-mesh selection) approximately preserves the equal-variance property for the distributions tested. A full concentration inequality is left for future work; we will make this scope explicit so the claim is not overstated. revision: yes
-
Referee: Empirical section (validation of the bound): The manuscript should clarify whether the mean-field assumption (including equal standard deviation) is independently derived from the input distribution or calibrated using the same data on which the error decay is demonstrated; if the latter, the O(B/(n w^2)) expression risks circularity rather than providing an independent prediction.
Authors: The assumption is derived a priori from the i.i.d. input model rather than calibrated on the experimental data. Because the elements are drawn from the same distribution, symmetry implies equal residual variances at each step; the empirical plots then serve as an independent check that the observed decay matches the predicted rate. To eliminate any appearance of circularity we will add an explicit paragraph in the empirical section stating that the mean-field model is fixed by the theoretical RSSP setup and that the simulations test the resulting prediction across multiple distributions. revision: yes
Circularity Check
Error bound O(B/(n w^2)) presented as conditional on external mean-field assumption with no reduction to inputs by construction
full rationale
The paper states that the beam-search heuristic yields expected error O(B/(n w^2)) under a standard mean-field assumption with equal standard deviation. This is an explicit conditioning rather than a derivation that redefines or fits the bound from the algorithm outputs themselves. No equations, self-citations, or parameter-fitting steps are shown that would make the claimed scaling equivalent to the modeling choice by construction. The mesh construction, trimming, and runtime claims are described separately from the error analysis. The result is therefore self-contained against external benchmarks once the assumption is granted; any weakness lies in justification of the assumption, not in circular reduction.
Axiom & Free-Parameter Ledger
free parameters (2)
- w
- B
axioms (1)
- domain assumption Standard mean-field assumption with equal standard deviation for the i.i.d. input numbers
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
expected error of O(B/(n w²)) under a standard mean-field assumption with equal standard deviation
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
constructs the same O(B/w) mesh as Da Cunha et al. (2023)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
AND Subset Sum is Hard: Tight Conditional Lower Bounds for Scheduling, Matching, and Related Problems.SIAM J. Comput.48, 2 (2019), 539–579. doi:10.1137/16M1082018 Anja Becker, Jean-Sébastien Coron, and Antoine Joux
-
[2]
Bayesian Segmentation of Atrium Wall Using Globally-Optimal Graph Cuts on 3D Meshes
Improved Generic Algo- rithms for Hard Knapsacks. InAdvances in Cryptology – EUROCRYPT 2011 (Lecture Notes in Computer Science, Vol. 6632). Springer, 364–385. doi:10.1007/978-3-642- 20465-4_21 David Biesner, Rafet Sifa, and Christian Bauckhage
-
[3]
doi:10.36227/techrxiv.18994160.v1 Preprint
Solving Subset Sum Prob- lems using Binary Optimization with Applications in Auditing and Financial Data Analysis.TechRxiv– (2022), –. doi:10.36227/techrxiv.18994160.v1 Preprint. Xavier Bonnetain, Rémi Bricout, André Schrottenloher, and Yixin Shen
-
[4]
InAdvances in Cryptology – ASIACRYPT 2020 (Lecture Notes in Computer Science, Vol
Improved Classical and Quantum Algorithms for Subset-Sum. InAdvances in Cryptology – ASIACRYPT 2020 (Lecture Notes in Computer Science, Vol. 12492). Springer, 633–666. doi:10.1007/978-3-030-64834-3_22 Edwin Chen and Christof Teuscher Christian Borgs, Jennifer T Chayes, and Boris Pittel
-
[5]
Faster algorithms for bounded knapsack and bounded subset sum via fine-grained proximity results
Phase transition and finite- size scaling for the number partitioning problem.Random Structures & Algorithms 19, 3-4 (2001), 247–288. Lin Chen, Jiayi Lian, Yuchen Mao, and Guochuan Zhang. 2024a. Approximating Partition in Near-Linear Time. InProceedings of the 56th Annual ACM Symposium on Theory of Computing (STOC 2024). ACM, New York, NY, USA, 307–318. d...
-
[6]
Computational Complexity2, 2 (1992), 111–128
Improved Low-Density Subset Sum Algorithms. Computational Complexity2, 2 (1992), 111–128. doi:10.1007/BF01201999 Arthur Carvalho Walraven Da Cunha, Francesco d’Amore, Frédéric Giroire, Hicham Lesfari, Emanuele Natale, and Laurent Viennot
-
[7]
274), Inge Li Gørtz, Martin Farach-Colton, Simon J
(Leibniz International Proceedings in Informatics (LIPIcs), Vol. 274), Inge Li Gørtz, Martin Farach-Colton, Simon J. Puglisi, and Grzegorz Herman (Eds.). Schloss Dagstuhl — Leibniz-Zentrum für Informatik, Dagstuhl, Germany, 37:1–37:11. doi:10.4230/ LIPIcs.ESA.2023.37 Abraham D. Flaxman and Bartosz Przydatek
work page 2023
-
[8]
InSTACS 2005 (Lecture Notes in Computer Science, Vol
Solving Medium-Density Subset Sum Problems in Expected Polynomial Time. InSTACS 2005 (Lecture Notes in Computer Science, Vol. 3404), Volker Diekert and Bruno Durand (Eds.). Springer, Berlin, Heidelberg, 305–314. doi:10.1007/978-3-540-31856-9_25 Jonathan Frankle, Gintare Karolina Dziugaite, Daniel M. Roy, and Michael Carbin
-
[9]
InProceedings of the 37th International Conference on Machine Learning (ICML)
Linear Mode Connectivity and the Lottery Ticket Hypothesis. InProceedings of the 37th International Conference on Machine Learning (ICML). Proceedings of Machine Learning Research (PMLR), Virtual Event, 3259–3269. https://proceedings. mlr.press/v119/frankle20a.html Michael R. Garey and David S. Johnson. 1979.Computers and Intractability: A Guide to the Th...
work page 1979
-
[10]
doi:10.1007/ BFb0006603 Fred Glover
Fast approximation algorithms for knapsack type problems.System Modeling and Optimization8 (1979), 277–281. doi:10.1007/ BFb0006603 Fred Glover
work page 1979
-
[11]
doi:10.1016/0305- 0548(86)90048-1 Fred Glover
Future paths for integer programming and links to artificial intelli- gence.Computers & Operations Research13, 5 (1986), 533–549. doi:10.1016/0305- 0548(86)90048-1 Fred Glover
-
[12]
doi:10.1287/ijoc.1.3.190 Fred Glover
Tabu Search—Part I.ORSA Journal on Computing1, 3 (1989), 190–206. doi:10.1287/ijoc.1.3.190 Fred Glover
-
[13]
doi:10.1287/ijoc.2.1.4 David E
Tabu Search—Part II.ORSA Journal on Computing2, 1 (1990), 4–32. doi:10.1287/ijoc.2.1.4 David E. Goldberg. 1989.Genetic Algorithms in Search, Optimization and Machine Learning(1st ed.). Addison-Wesley. Addison-Wesley Professional. Ellis Horowitz and Sartaj Sahni
-
[14]
ACM21, 2 (April 1974), 277–292
Computing Partitions with Applications to the Knapsack Problem.J. ACM21, 2 (April 1974), 277–292. doi:10.1145/321812.321823 Nick Howgrave-Graham and Antoine Joux
-
[15]
InAdvances in Cryptology – EUROCRYPT 2010 (Lecture Notes in Com- puter Science, Vol
New Generic Algorithms for Hard Knapsacks. InAdvances in Cryptology – EUROCRYPT 2010 (Lecture Notes in Com- puter Science, Vol. 6110). Springer, 235–256. doi:10.1007/978-3-642-13190-5_12 Liang Huang, Kai Zhao, and Mingbo Ma
-
[16]
When to Finish? Optimal Beam Search for Neural Text Generation (modulo beam size). InProceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (EMNLP), Martha Palmer, Rebecca Hwa, and Sebastian Riedel (Eds.). Association for Computational Linguistics, Copenhagen, Denmark, 2134–2139. doi:10.18653/v1/D17-1227 James Kennedy and R...
-
[17]
doi:10.1109/ICNN.1995.488968 Scott Kirkpatrick, C
IEEE, 1942–1948. doi:10.1109/ICNN.1995.488968 Scott Kirkpatrick, C. D. Gelatt Jr., and M. P. Vecchi
-
[18]
Optimization by Simulated Annealing,
Optimization by Simulated Annealing.Science220, 4598 (1983), 671–680. doi:10.1126/science.220.4598.671 Jeffrey C. Lagarias and Andrew M. Odlyzko
-
[19]
Solving Low-Density Subset Sum Problems.J. ACM32, 1 (1985), 229–246. doi:10.1145/2455.2461 Murali Krishna Madugula, Santosh Kumar Majhi, and Nibedan Panda
-
[20]
In2022 International Conference on Connected Systems & Intelligence (CSI)
An Effi- cient Arithmetic Optimization Algorithm for Solving Subset-sum Problem. In2022 International Conference on Connected Systems & Intelligence (CSI). IEEE, Piscataway, NJ, USA, 1–7. doi:10.1109/CSI54720.2022.9923996 Stephan Mertens
-
[21]
Phase transition in the number partitioning problem.Physical Review Letters81, 20 (1998),
work page 1998
-
[22]
A Genetic Algorithm for the Subset Sum Problem.Neurocomputing61, 1–3 (2004), 453–459. doi:10.1016/j.neucom.2003. 11.025 Richard Schroeppel and Adi Shamir
-
[23]
A 𝑇=𝑂( 2𝑛/2 ), 𝑆=𝑂( 2𝑛/4 ) Algorithm for Certain NP-Complete Problems.SIAM J. Comput.10, 3 (Aug. 1981), 456–464. doi:10.1137/0210033 David Wagner
-
[24]
InProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Sequence-to-Sequence Learning as Beam- Search Optimization. InProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Austin, Texas, 1296–1306. doi:10.18653/v1/D16-1137 Zhihui Zhou and Zongzhang Zhang
-
[25]
Association for the Advance- ment of Artificial Intelligence (AAAI), 6744–6751. doi:10.1609/aaai.v34i04.6162 A Variance of Error Variance bound in the random-phase regime.Let 𝐷𝑡 denote the global gap at Phase B step 𝑡, and define the one-step improvement Δ𝑡 :=𝐷 𝑡 −𝐷 𝑡+1 ≥0. In the random-phase, small-gap regime 𝐷𝑡 ≪Δ=𝐵/𝑤 we have E[Δ 𝑡 |𝐷 𝑡 ]=Θ 𝑤 2 𝐵 𝐷 2 𝑡...
-
[26]
The sum of𝑚 independent Exp(1) variables exactly follows a Gamma distribution: 𝑆𝑚 = 𝑚∑︁ 𝑖=1 𝑋𝑖 ∼Γ(𝑚,1), where E[𝑆𝑚]=𝑚 and Var(𝑆𝑚)=𝑚 . We require 𝑆𝑚 ≥ln(𝑛𝑤) . Because E[𝑆𝑘𝐵 ]=𝑘 𝐵, setting 𝑘𝐵 ≈ln(𝑛𝑤) achieves the target re- duction in expectation. Applying standard Chernoff bounds for the Gamma distribution, padding the required budget by the standard devia...
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.