UniPCB: A Generation-Assisted Detection Framework for PCB Defect Inspection
Pith reviewed 2026-05-12 00:46 UTC · model grok-4.3
The pith
A joint generation-detection framework for PCBs uses multi-modal synthesis to augment scarce defect data and reach 98.0 percent mAP@0.5.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
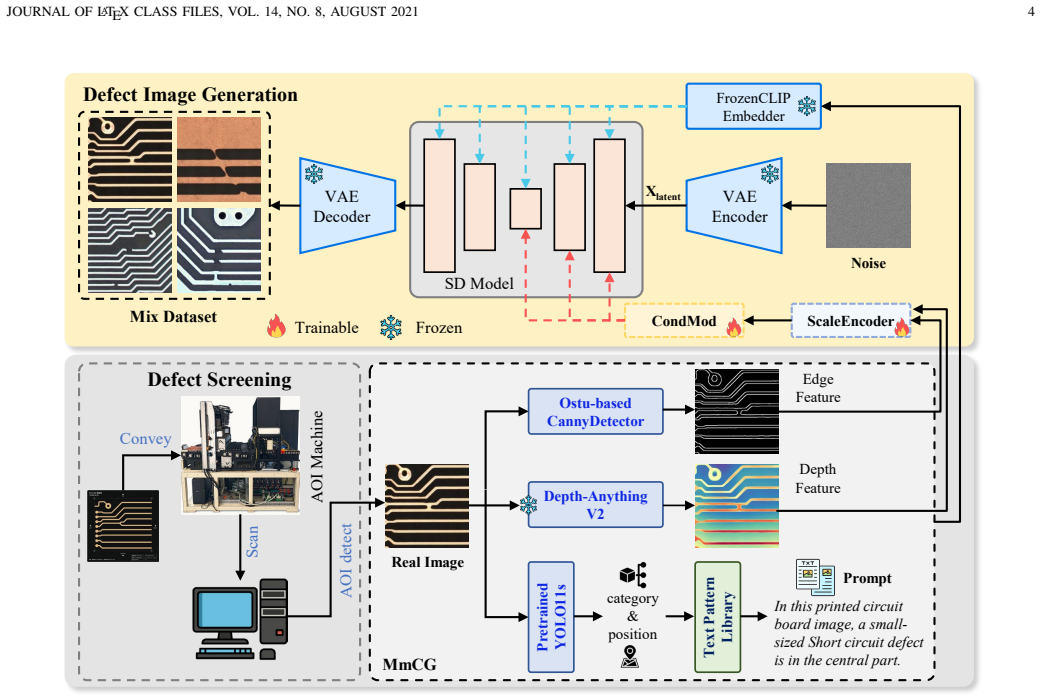
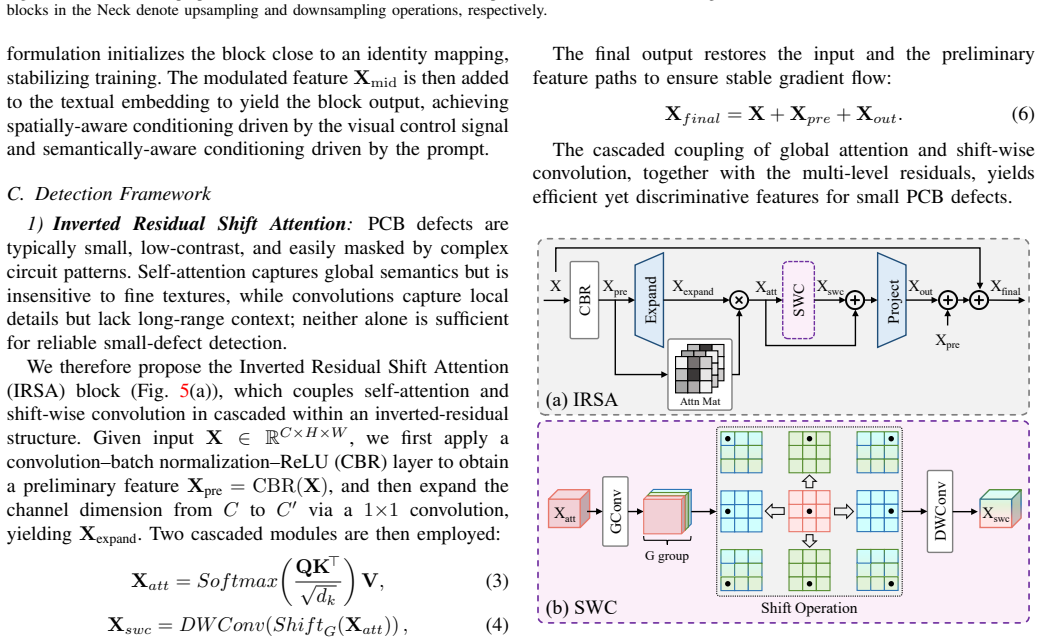
The authors establish that a generation-assisted detection framework, with a Multi-modal Condition Generator feeding a ScaleEncoder and FiLM-style Condition Modulation for synthesis, plus an Inverted Residual Shift Attention and Cross-level Complementary Fusion Block for detection, jointly overcomes data scarcity and representation limits, delivering mAP@0.5 of 98.0 percent and mAP@0.5:0.95 of 61.8 percent on DsPCBSD+ while the generator reaches FID 129.61 and SSIM 0.619.
What carries the argument
The Multi-modal Condition Generator with ScaleEncoder and Condition Modulation that synthesizes aligned defects from parallel edge-depth-text inputs, paired with the detector's Inverted Residual Shift Attention and Cross-level Complementary Fusion Block that fuses global context and local texture via shift convolution and pixel-level gates.
If this is right
- Synthesized defects directly enrich the scarce IIoT training set, so gains in generation quality translate into higher detection mAP.
- The multi-modal conditioning enables structurally aligned samples that help the detector handle complex circuit backgrounds better than single-condition methods.
- The joint pipeline outperforms all compared detection and generation baselines on the DsPCBSD+ benchmark.
- The IIoT pipeline supports real-time inspection by addressing both data volume and feature extraction challenges in one system.
Where Pith is reading between the lines
- The same multi-modal conditioning strategy could be tested on other industrial inspection tasks where defect samples are rare, such as weld or fabric defect detection.
- Ablating the generation branch would show whether the attention and fusion blocks alone deliver part of the accuracy gain even without extra data.
- If domain shift between generated and real defects proves larger than reported, the framework might need additional adaptation steps for new PCB manufacturing lines.
Load-bearing premise
The synthesized defect samples must be realistic enough and distributionally close enough to real IIoT PCB images that adding them to the training set improves detection accuracy on actual data rather than introducing harmful artifacts or shift.
What would settle it
Training the detector on real samples alone versus real samples plus the generated ones and measuring mAP on a held-out set of real PCB defects; if the augmented version shows no gain or a drop, the core benefit of generation assistance is refuted.
Figures










read the original abstract
In the Industrial Internet of Things (IIoT), enabling intelligent, real-time Printed Circuit Board (PCB) defect inspection is critical for ensuring product reliability. However, existing IIoT-based visual inspection systems face two compounding challenges: scarce and imbalanced defect samples that limit model training, and insufficient feature representation under complex circuit backgrounds. Existing generation methods rely on single-modality conditions with coarse structural control, while detection methods improve architectures without addressing the data bottleneck. To resolve both challenges jointly, we propose a generation-assisted PCB defect inspection framework that integrates controlled defect synthesis with task-specific defect detection within an IIoT-enabled pipeline. On the generation side, a Multi-modal Condition Generator extracts complementary edge, depth, and text conditions in parallel. A ScaleEncoder then embeds these conditions into the diffusion U-Net at four resolutions, and a Condition Modulation applies FiLM-style spatially-adaptive modulation at each scale, enabling structurally aligned and defect-aware sample synthesis to augment the scarce IIoT dataset. On the detection side, an Inverted Residual Shift Attention couples self-attention with shift-wise convolution to jointly capture global context and local texture, and a Cross-level Complementary Fusion Block generates pixel-level gates for selective cross-level feature fusion. The synthesized samples directly enrich the detection training set, so that improvements in generation compound with improvements in detection. Extensive experiments on DsPCBSD+ demonstrate that UniPCB achieves mAP@0.5 of 98.0% and mAP@0.5:0.95 of 61.8% on defect detection, surpassing all compared methods, while the generation branch attains an FID of 129.61 and SSIM of 0.619, outperforming existing conditional generation approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UniPCB, a generation-assisted framework for PCB defect inspection that integrates a Multi-modal Condition Generator (using parallel edge, depth, and text conditions fed via ScaleEncoder and Condition Modulation into a diffusion U-Net) for synthesizing defect samples to augment scarce IIoT data, with a detection network employing Inverted Residual Shift Attention and Cross-level Complementary Fusion for improved feature representation. On the DsPCBSD+ dataset, it reports mAP@0.5 of 98.0% and mAP@0.5:0.95 of 61.8% for detection (surpassing compared methods) alongside generation metrics of FID 129.61 and SSIM 0.619 (outperforming existing conditional generators), claiming that synthesized samples directly enrich training and compound with architectural improvements.
Significance. If the central claim holds, the work offers a practical pipeline for addressing data imbalance in industrial PCB inspection by jointly optimizing synthesis and detection, which could improve real-world IIoT reliability. The explicit reporting of both generation quality metrics and end-task mAP provides a basis for comparison, and the multi-modal conditioning approach is a concrete technical contribution. However, the lack of isolating experiments limits attribution of gains.
major comments (3)
- [Abstract / Experiments] Abstract and experiments section: The headline claim that 'the synthesized samples directly enrich the detection training set, so that improvements in generation compound with improvements in detection' is load-bearing for the generation-assisted framing, yet no ablation is described that trains the detection branch (Inverted Residual Shift Attention + Cross-level Complementary Fusion) on real DsPCBSD+ data only versus real + generated samples. Without this, the mAP@0.5 of 98.0% and mAP@0.5:0.95 of 61.8% cannot be attributed to the Multi-modal Condition Generator rather than the detection modules alone.
- [Abstract] Abstract: The reported mAP and generation metrics are presented without error bars, statistical significance tests (e.g., paired t-tests across runs), details on train/validation/test splits, or full baseline re-implementation protocols. This makes it impossible to assess whether the gains over compared methods are robust or sensitive to implementation choices.
- [Abstract / Methods] Generation branch description: The Multi-modal Condition Generator is said to produce 'structurally aligned and defect-aware' samples, but the abstract provides no quantitative measure of distributional alignment (e.g., feature-space distance to real defects) or qualitative failure cases, leaving the weakest assumption—that the FID 129.61 / SSIM 0.619 outputs avoid harmful domain shift—unverified.
minor comments (2)
- [Abstract] The abstract uses 'DsPCBSD+' without defining the dataset or citing its source; this should be clarified with a reference or brief description in the main text.
- [Methods] Notation for the ScaleEncoder and Condition Modulation (FiLM-style) is introduced without equations; adding a short mathematical formulation would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of experimental validation and reporting that we will address to strengthen the paper. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract / Experiments] The headline claim that 'the synthesized samples directly enrich the detection training set, so that improvements in generation compound with improvements in detection' is load-bearing for the generation-assisted framing, yet no ablation is described that trains the detection branch (Inverted Residual Shift Attention + Cross-level Complementary Fusion) on real DsPCBSD+ data only versus real + generated samples. Without this, the mAP@0.5 of 98.0% and mAP@0.5:0.95 of 61.8% cannot be attributed to the Multi-modal Condition Generator rather than the detection modules alone.
Authors: We agree that an explicit ablation isolating the contribution of the synthesized samples is necessary to substantiate the generation-assisted claim. In the revised manuscript, we will add this ablation: training the full detection network (Inverted Residual Shift Attention + Cross-level Complementary Fusion) on real DsPCBSD+ data only, and comparing it directly to training on the combined real + generated set under identical hyperparameters and splits. This will quantify the mAP gains attributable to the Multi-modal Condition Generator. revision: yes
-
Referee: [Abstract] The reported mAP and generation metrics are presented without error bars, statistical significance tests (e.g., paired t-tests across runs), details on train/validation/test splits, or full baseline re-implementation protocols. This makes it impossible to assess whether the gains over compared methods are robust or sensitive to implementation choices.
Authors: We will revise the experiments section to report mean mAP values with standard deviations across multiple independent runs (e.g., 5 seeds), include paired t-tests or equivalent significance tests against baselines, explicitly state the train/validation/test split ratios and sampling strategy on DsPCBSD+, and provide complete re-implementation details (hyperparameters, data augmentation, and training schedules) for all compared methods to enable robust assessment of the gains. revision: yes
-
Referee: [Abstract / Methods] Generation branch description: The Multi-modal Condition Generator is said to produce 'structurally aligned and defect-aware' samples, but the abstract provides no quantitative measure of distributional alignment (e.g., feature-space distance to real defects) or qualitative failure cases, leaving the weakest assumption—that the FID 129.61 / SSIM 0.619 outputs avoid harmful domain shift—unverified.
Authors: FID and SSIM are established metrics for generation fidelity and structural similarity. To further verify distributional alignment and absence of harmful domain shift, the revised version will add quantitative analysis (e.g., average feature-space L2 distances using embeddings from a pre-trained ResNet on real vs. generated defect patches) and a dedicated qualitative section showing representative success cases alongside any observed failure modes (e.g., over-generated artifacts or misalignment). revision: yes
Circularity Check
No significant circularity; empirical framework with external validation
full rationale
The paper presents an architectural framework (Multi-modal Condition Generator with ScaleEncoder and Condition Modulation; Inverted Residual Shift Attention and Cross-level Complementary Fusion) whose performance claims rest on empirical metrics (mAP@0.5 98.0%, mAP@0.5:0.95 61.8%, FID 129.61, SSIM 0.619) measured on the external DsPCBSD+ dataset. No equations, derivations, or first-principles results are described that reduce by construction to fitted inputs, self-citations, or renamed patterns. The generation-assisted claim is presented as an empirical outcome rather than a tautological restatement of training objectives, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multi-modal conditions (edge, depth, text) can be extracted in parallel and embedded to produce structurally aligned defect images
- domain assumption Coupling self-attention with shift-wise convolution and cross-level gating improves feature representation under complex circuit backgrounds
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Multi-modal Condition Generator extracts complementary edge, depth, and text conditions... ScaleEncoder embeds these conditions into the diffusion U-Net at four resolutions, and a Condition Modulation applies FiLM-style spatially-adaptive modulation
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and embed_strictMono unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Inverted Residual Shift Attention couples self-attention with shift-wise convolution... Cross-level Complementary Fusion Block generates pixel-level gates
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.