Reward-Decomposed Reinforcement Learning for Immersive Video Role-Playing
Pith reviewed 2026-05-08 17:35 UTC · model grok-4.3
The pith
EBM-RL decomposes rewards to ground video role-playing in visual scenes and character traits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
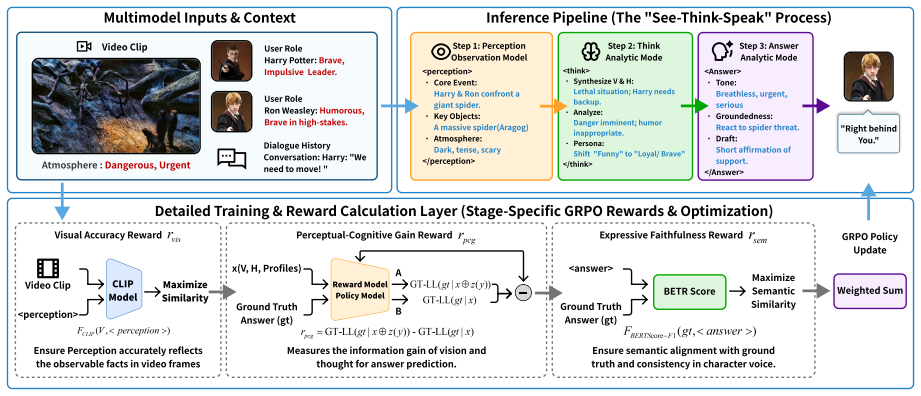
EBM-RL is a decoupled GRPO-based framework that separates observation in perception, reasoning in think, and utterance in answer. It uses four rewards including CLIP scene-text alignment for ambiance, perceptual-cognitive to increase likelihood of reference responses, answer accuracy for faithfulness, and dense format for structured output. This leads to better visual-atmosphere consistency and character authenticity compared to baselines.
What carries the argument
The decoupled structure of perception, think, and answer stages combined with the four complementary reward signals in the EBM-RL framework.
If this is right
- Outperforms text-only role-playing baselines and larger vision-language models on the immersive role-playing benchmark.
- Delivers simultaneous gains in visual-atmosphere consistency and character authenticity.
- Shows strong zero-shot generalization to out-of-domain VideoQA benchmarks without additional fine-tuning.
- Comes with an open-source dataset release for video-grounded role-playing dialogue.
Where Pith is reading between the lines
- The stage separation could be applied to other dialogue systems to improve multimodal consistency.
- Reward decomposition might allow smaller models to achieve performance close to larger ones in grounded tasks.
- Future work could test if these rewards transfer to real-time VR applications or different video domains.
Load-bearing premise
The assumption that the four specific rewards together encourage human-like sensory grounding and immersive responses without causing biases or overfitting to the benchmark data.
What would settle it
Testing EBM-RL on a newly collected immersive role-playing video dataset with unseen characters and scenes, where it does not show improvements over baselines, would falsify the performance claims.
Figures


read the original abstract
Text-based role-playing models can imitate character styles, but often fail to capture scene atmosphere and evolving tension, which are crucial for immersive applications such as VR games and interactive narratives. We study video-grounded role-playing dialogue and introduce EBM-RL (Eye--Brain--Mouth Reinforcement Learning), a decoupled GRPO-based framework that separates observation (<perception>), reasoning (<think>), and utterance generation (<answer>). This design mimics the human See-Think-Speak process, enabling the model to ground dialogue in visual perception before reasoning and response generation. To optimize this See-Think-Speak process, EBM-RL integrates complementary rewards for scene--text alignment, perceptual--cognitive utility, answer faithfulness, and format consistency. Extensive experiments show that EBM-RL substantially outperforms text-only role-playing baselines and larger-scale vision-language models on our immersive role-playing benchmark, improving both visual-atmosphere consistency and character authenticity. Moreover, EBM-RL demonstrates strong zero-shot transfer to out-of-domain VideoQA benchmarks without additional fine-tuning. We also release an open-source dataset for video-grounded role-playing dialogue.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EBM-RL, a decoupled GRPO-based reinforcement learning framework for video-grounded role-playing dialogue. It explicitly separates the process into [perception], [think], and [answer] stages and integrates four rewards: CLIP-based scene-text alignment, a perceptual-cognitive reward that boosts the likelihood of reference responses given perception and think outputs, answer accuracy, and a dense format reward. The central claims are substantial outperformance over text-only baselines and larger vision-language models on a custom immersive role-playing benchmark (with gains in visual-atmosphere consistency and character authenticity), plus zero-shot generalization to VideoQA tasks without further fine-tuning, accompanied by the release of an open-source dataset.
Significance. If the empirical results are robust, the decoupled structure and reward decomposition could provide a useful template for building more grounded multimodal agents in immersive applications such as VR narratives. The dataset release is a clear positive contribution that supports reproducibility and follow-on research.
major comments (1)
- The perceptual-cognitive reward is defined to encourage [perception] and [think] processes that increase the likelihood of the reference response (as stated in the abstract and method description). This directly ties the intermediate reasoning steps to benchmark-specific reference answers, creating a plausible pathway for the policy to optimize reference-matching patterns rather than emergent video-derived atmosphere or tension. Because this reward is load-bearing for the claims of human-like sensory grounding, simultaneous gains in visual-atmosphere consistency and character authenticity, and the zero-shot VideoQA transfer, the manuscript should include ablations that isolate its contribution and additional metrics that do not rely on reference likelihood to substantiate the central generalization claims.
minor comments (1)
- The abstract asserts 'substantial outperformance' and 'simultaneous gains' without naming the specific metrics, baselines, or statistical tests; adding these details would improve immediate readability while the full experimental section supplies the supporting evidence.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The concern about the perceptual-cognitive reward potentially encouraging reference-matching is a substantive point that merits additional analysis. We address it directly below and commit to revisions that strengthen the empirical grounding of our claims.
read point-by-point responses
-
Referee: The perceptual-cognitive reward is defined to encourage [perception] and [think] processes that increase the likelihood of the reference response (as stated in the abstract and method description). This directly ties the intermediate reasoning steps to benchmark-specific reference answers, creating a plausible pathway for the policy to optimize reference-matching patterns rather than emergent video-derived atmosphere or tension. Because this reward is load-bearing for the claims of human-like sensory grounding, simultaneous gains in visual-atmosphere consistency and character authenticity, and the zero-shot VideoQA transfer, the manuscript should include ablations that isolate its contribution and additional metrics that do not rely on reference likelihood to substantiate the central generalization claims.
Authors: We acknowledge that the perceptual-cognitive reward, by construction, increases the likelihood of reference responses given the [perception] and [think] outputs. This design choice could in principle allow the policy to exploit reference patterns rather than purely video-derived cues. However, the reward is applied only after the CLIP-based scene-text alignment reward has already enforced visual grounding in the perception stage, and it is further constrained by the separate answer accuracy reward that evaluates faithfulness to the input video. To isolate its effect, we will add an ablation in the revised manuscript that removes only the perceptual-cognitive reward while retaining the CLIP alignment, answer accuracy, and format rewards. We will report the resulting changes in visual-atmosphere consistency, character authenticity, and zero-shot VideoQA performance. In addition, we will introduce reference-independent metrics, including automated scene-description accuracy using an off-the-shelf vision model and targeted human ratings of visual grounding, to provide supporting evidence for the generalization claims. revision: yes
Circularity Check
No circularity: empirical method with externally defined rewards and benchmark evaluation.
full rationale
The paper introduces EBM-RL as a decoupled RL framework with four explicitly defined rewards (CLIP alignment, perceptual-cognitive using reference likelihood, accuracy, format) and evaluates it empirically on a new benchmark plus zero-shot transfer. No derivation chain, mathematical prediction, or first-principles result is claimed that reduces to its inputs by construction. Rewards rely on external components (CLIP, reference responses) rather than being fitted or renamed from the target metrics. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided text to justify core choices. The outperformance claims rest on experimental results, not on any self-referential reduction.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.