Recognition: 2 theorem links
· Lean TheoremEulerian Motion Guidance: Robust Image Animation via Bidirectional Geometric Consistency
Pith reviewed 2026-05-13 06:51 UTC · model grok-4.3
The pith
Adjacent-frame Eulerian motion fields with bidirectional cycle checks guide diffusion-based image animation without drift accumulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
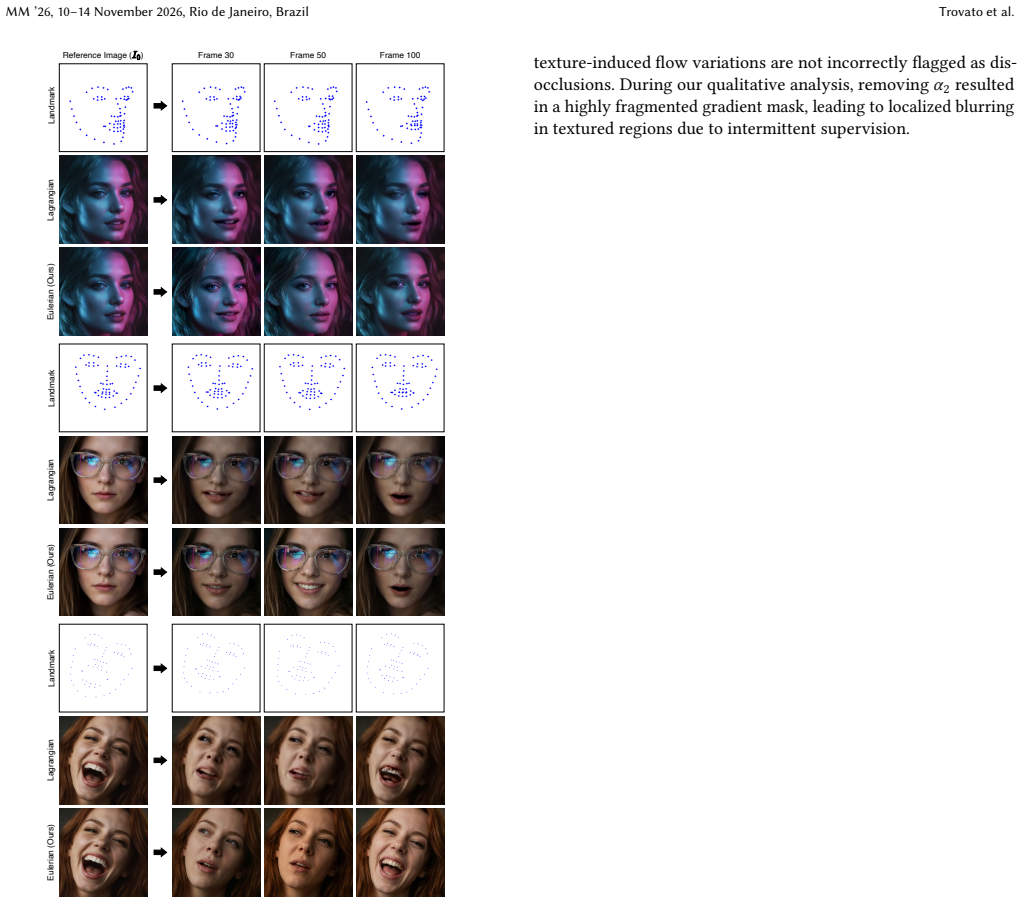
Replacing Lagrangian motion guidance with adjacent-frame Eulerian motion fields, protected by a forward-backward cycle-consistency mask, produces image animations that train in parallel and maintain temporal coherence without learning incorrect warping targets in occluded areas.
What carries the argument
The Bidirectional Geometric Consistency mechanism, which computes a forward-backward cycle check on adjacent-frame motion fields to identify and mask occluded regions before applying the warping objective.
If this is right
- Training becomes parallelizable because each frame receives supervision only from its immediate neighbors.
- Motion error stays bounded since every guidance signal spans only one short hop.
- Occluded pixels are excluded from the loss, so the model does not learn impossible warps.
- Temporal coherence improves and dynamic artifacts drop relative to reference-based methods.
Where Pith is reading between the lines
- The same local-cycle masking could be applied to other flow-supervised video tasks where long-range flow is unreliable.
- Parallel training may make high-resolution animation feasible on shorter compute budgets.
- The approach suggests that many video generation problems can be decomposed into short, verifiable motion steps rather than global trajectory estimation.
Load-bearing premise
The forward-backward cycle check reliably flags all occluded pixels without missing small motions or introducing new warping errors.
What would settle it
Generate animations on sequences with known complex occlusions; if visible drift or ghosting persists in the masked regions at the same rate as in Lagrangian baselines, the claim fails.
Figures









read the original abstract
Recent advancements in image animation have utilized diffusion models to breathe life into static images. However, existing controllable frameworks typically rely on Lagrangian motion guidance, where optical flow is estimated relative to the initial frame. This paper revisits the same optical-flow primitive through a more local supervision design: we use adjacent-frame Eulerian motion fields to guide generation, where the motion signal always describes a short temporal hop. This shift enables parallelized training and provides bounded-error supervision throughout the generation process. To mitigate the drift artifacts common in adjacent frame generation, we introduce a Bidirectional Geometric Consistency mechanism, which computes a forward-backward cycle check to mathematically identify and mask occluded regions, preventing the model from learning incorrect warping objectives. Extensive experiments demonstrate that our approach accelerates training, preserves temporal coherence, and reduces dynamic artifacts compared to reference-based baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Eulerian Motion Guidance for diffusion-based image animation, replacing Lagrangian optical flow (relative to the initial frame) with adjacent-frame Eulerian motion fields. This enables parallelized training and bounded-error supervision. A Bidirectional Geometric Consistency module uses forward-backward cycle checks to identify and mask occluded regions, preventing incorrect warping objectives. Experiments are claimed to show faster training, better temporal coherence, and fewer dynamic artifacts than reference-based baselines.
Significance. If the central claims hold, the work offers a meaningful efficiency gain through local Eulerian supervision and a practical mechanism for occlusion-aware consistency that could reduce drift in long animations. The bounded-error property and parallel training are potentially impactful for scalable controllable video generation if supported by rigorous ablations.
major comments (2)
- Abstract: The abstract states performance gains but supplies no quantitative results, error bars, or ablation details; central claims rest on unverified experimental outcomes visible only in the full paper.
- Bidirectional Geometric Consistency mechanism: The forward-backward cycle check is presented as mathematically identifying and masking occluded regions, but the description does not address robustness to noisy Eulerian flow (e.g., aperture problems or subtle non-rigid motions); this assumption is load-bearing for the bounded-error supervision guarantee and requires explicit validation or failure-case analysis.
minor comments (1)
- Abstract: The distinction between Eulerian and Lagrangian motion guidance would benefit from a one-sentence definition or citation to improve accessibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below and indicate the changes planned for the revised manuscript.
read point-by-point responses
-
Referee: Abstract: The abstract states performance gains but supplies no quantitative results, error bars, or ablation details; central claims rest on unverified experimental outcomes visible only in the full paper.
Authors: We agree that the abstract would be strengthened by quantitative support. In the revision we will add specific metrics (e.g., training speedup, temporal coherence scores) together with error bars from repeated runs so that the central claims are verifiable from the abstract alone. revision: yes
-
Referee: Bidirectional Geometric Consistency mechanism: The forward-backward cycle check is presented as mathematically identifying and masking occluded regions, but the description does not address robustness to noisy Eulerian flow (e.g., aperture problems or subtle non-rigid motions); this assumption is load-bearing for the bounded-error supervision guarantee and requires explicit validation or failure-case analysis.
Authors: The cycle check rests on the exact mathematical identity that holds for non-occluded pixels under perfect flow. We recognize that real-world flow noise (aperture problems, non-rigid motion) can degrade this and that the current text does not provide dedicated robustness analysis. We will add a new subsection with synthetic noise experiments, failure-case visualizations, and quantitative validation of the bounded-error property under realistic flow conditions. revision: yes
Circularity Check
No significant circularity; claims rest on independently introduced mechanisms
full rationale
The provided abstract and description introduce adjacent-frame Eulerian motion fields for parallelized training and bounded-error supervision, plus the Bidirectional Geometric Consistency module with forward-backward cycle check for occlusion masking, as new design choices without any shown equations, fitted parameters, or self-citations that reduce these to prior inputs by construction. No self-definitional loops, renamed known results, or load-bearing self-citations appear. The central claims (parallel training, bounded error, artifact reduction) are presented as consequences of the new supervision design rather than tautological redefinitions. This matches the default expectation for non-circular papers and the reader's assessment of low circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Optical flow estimates between adjacent frames provide bounded-error supervision signals for diffusion-based animation.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 2 (Uniform Bound on Eulerian Supervisory Error)... E[endpoint error] ≤ σ for all t
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Cycle Energy Formulation... E_cycle(x) = ||f_t→t+1(x) + F(f_t+1→t, f_t→t+1)(x)||_2^2
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Omer Bar-Tal, Hila Chefer, Omer Tov, Charles Herrmann, Roni Paiss, Shiran Zada, Ariel Ephrat, Junhwa Hur, Guanghui Liu, Amit Raj, et al. 2024. Lumiere: A space-time diffusion model for video generation. InSIGGRAPH Asia 2024 Conference Papers. 1–11
work page 2024
-
[2]
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, et al. 2023. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Ryan Burgert, Yuancheng Xu, Wenqi Xian, Oliver Pilarski, Pascal Clausen, Ming- ming He, Li Ma, Yitong Deng, Lingxiao Li, Mohsen Mousavi, et al. 2025. Go-with- the-flow: Motion-controllable video diffusion models using real-time warped noise. InProceedings of the Computer Vision and Pattern Recognition Conference. 13–23
work page 2025
-
[4]
Zhiyuan Chen, Jiajiong Cao, Zhiquan Chen, Yuming Li, and Chenguang Ma. 2025. Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 2403–2410
work page 2025
-
[5]
Jiahao Cui, Hui Li, Yun Zhan, Hanlin Shang, Kaihui Cheng, Yuqi Ma, Shan Mu, Hang Zhou, Jingdong Wang, and Siyu Zhu. 2025. Hallo3: Highly dynamic and realistic portrait image animation with video diffusion transformer. InProceedings of the Computer Vision and Pattern Recognition Conference. 21086–21095
work page 2025
-
[6]
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. 2019. Arcface: Additive angular margin loss for deep face recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4690–4699
work page 2019
-
[7]
Wanquan Feng, Tianhao Qi, Jiawei Liu, Mingzhen Sun, Pengqi Tu, Tianxiang Ma, Fei Dai, Songtao Zhao, Siyu Zhou, and Qian He. 2025. I2vcontrol: Disentan- gled and unified video motion synthesis control. InProceedings of the IEEE/CVF International Conference on Computer Vision. 14051–14060
work page 2025
-
[8]
Craig G Fraser. 2005. Leonhard Euler, book on the calculus of variations (1744). InLandmark Writings in Western Mathematics 1640-1940. Elsevier, 168–180
work page 2005
- [9]
-
[10]
Sicheng Gao, Yutang Feng, Linlin Yang, Xuhui Liu, Zichen Zhu, David S Do- ermann, and Baochang Zhang. 2022. MagFormer: Hybrid Video Motion Mag- nification Transformer from Eulerian and Lagrangian Perspectives.. InBMVC. 444
work page 2022
-
[11]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. 2017. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems30 (2017)
work page 2017
-
[12]
Li Hu. 2024. Animate anyone: Consistent and controllable image-to-video syn- thesis for character animation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8153–8163
work page 2024
-
[13]
Longbin Ji, Lei Zhong, Pengfei Wei, and Changjian Li. 2025. PoseTraj: Pose- Aware Trajectory Control in Video Diffusion. InProceedings of the Computer Vision and Pattern Recognition Conference. 22776–22785
work page 2025
- [14]
-
[15]
Wei-Sheng Lai, Jia-Bin Huang, Oliver Wang, Eli Shechtman, Ersin Yumer, and Ming-Hsuan Yang. 2018. Learning blind video temporal consistency. InProceed- ings of the European conference on computer vision (ECCV). 170–185
work page 2018
-
[16]
Yaowei Li, Xintao Wang, Zhaoyang Zhang, Zhouxia Wang, Ziyang Yuan, Liang- bin Xie, Ying Shan, and Yuexian Zou. 2025. Image conductor: Precision control for interactive video synthesis. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 5031–5038
work page 2025
-
[17]
Jingyun Liang, Yuchen Fan, Kai Zhang, Radu Timofte, Luc Van Gool, and Rakesh Ranjan. 2024. Movideo: Motion-aware video generation with diffusion model. In European Conference on Computer Vision. Springer, 56–74
work page 2024
-
[18]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [19]
- [20]
-
[21]
Niranjan D Narvekar and Lina J Karam. 2011. A no-reference image blur metric based on the cumulative probability of blur detection (CPBD).IEEE Transactions on Image Processing20, 9 (2011), 2678–2683
work page 2011
-
[22]
Muyao Niu, Xiaodong Cun, Xintao Wang, Yong Zhang, Ying Shan, and Yinqiang Zheng. 2024. Mofa-video: Controllable image animation via generative motion field adaptions in frozen image-to-video diffusion model. InEuropean Conference on Computer Vision. Springer, 111–128
work page 2024
-
[23]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[24]
In International Conference on Machine Learning (ICML)
Learning transferable visual models from natural language supervision. In International Conference on Machine Learning (ICML). PMLR
-
[25]
Jiapeng Tang, Kai Li, Chengxiang Yin, Liuhao Ge, Fei Jiang, Jiu Xu, Matthias Nießner, Christian Häne, Timur Bagautdinov, Egor Zakharov, et al . 2025. Fac- torPortrait: Controllable Portrait Animation via Disentangled Expression, Pose, and Viewpoint.arXiv preprint arXiv:2512.11645(2025)
-
[26]
Zachary Teed and Jia Deng. 2020. Raft: Recurrent all-pairs field transforms for optical flow. InEuropean conference on computer vision. Springer, 402–419
work page 2020
-
[27]
Carl Vondrick, Hamed Pirsiavash, and Antonio Torralba. 2016. Generating videos with scene dynamics.Advances in neural information processing systems 29 (2016)
work page 2016
-
[28]
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. 2025. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [29]
-
[30]
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. 2024. Motionctrl: A unified and flexible motion controller for video generation. InACM SIGGRAPH 2024 Conference Papers. 1–11
work page 2024
-
[31]
Thaddäus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos. 2025. Video models are zero-shot learners and reasoners.arXiv preprint arXiv:2509.20328(2025)
work page internal anchor Pith review arXiv 2025
- [32]
-
[33]
Zhongcong Xu, Jianfeng Zhang, Jun Hao Liew, Hanshu Yan, Jia-Wei Liu, Chenxu Zhang, Jiashi Feng, and Mike Zheng Shou. 2024. Magicanimate: Temporally consistent human image animation using diffusion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1481–1490
work page 2024
- [34]
-
[35]
Fei Yin, Yong Zhang, Xiaodong Cun, Mingdeng Cao, Yanbo Fan, Xuan Wang, Qingyan Bai, Baoyuan Wu, Jue Wang, and Yujiu Yang. 2022. Styleheat: One- shot high-resolution editable talking face generation via pre-trained stylegan. In European conference on computer vision. Springer, 85–101
work page 2022
- [36]
- [37]
-
[38]
Zhongrui Yu, Martina Megaro-Boldini, Robert W Sumner, and Abdelaziz Djelouah. 2025. Unboxed: Geometrically and Temporally Consistent Video Outpainting. InProceedings of the Computer Vision and Pattern Recognition Con- ference. 7309–7319
work page 2025
-
[39]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang
-
[40]
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. InCVPR
-
[41]
Wenxuan Zhang, Xiaodong Cun, Xuan Wang, Yong Zhang, Xi Shen, Yu Guo, Ying Shan, and Fei Wang. 2023. Sadtalker: Learning realistic 3d motion coefficients for stylized audio-driven single image talking face animation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 8652–8661
work page 2023
-
[42]
Guangcong Zheng, Xianpan Zhou, Xuewei Li, Zhongang Qi, Ying Shan, and Xi Li. 2023. Layoutdiffusion: Controllable diffusion model for layout-to-image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22490–22499. Trovato et al. A Proof of Theorem 1 Theorem 1. (Expected Error Accumulation in Lagrangian Motion F...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.