Recognition: unknown
Constraining Host-Level Abuse in Self-Hosted Computer-Use Agents via TEE-Backed Isolation
Pith reviewed 2026-05-08 09:02 UTC · model grok-4.3
The pith
Self-hosted computer-use agents can block unsafe host operations before execution by routing risk decisions through a TEE-backed trusted plane.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
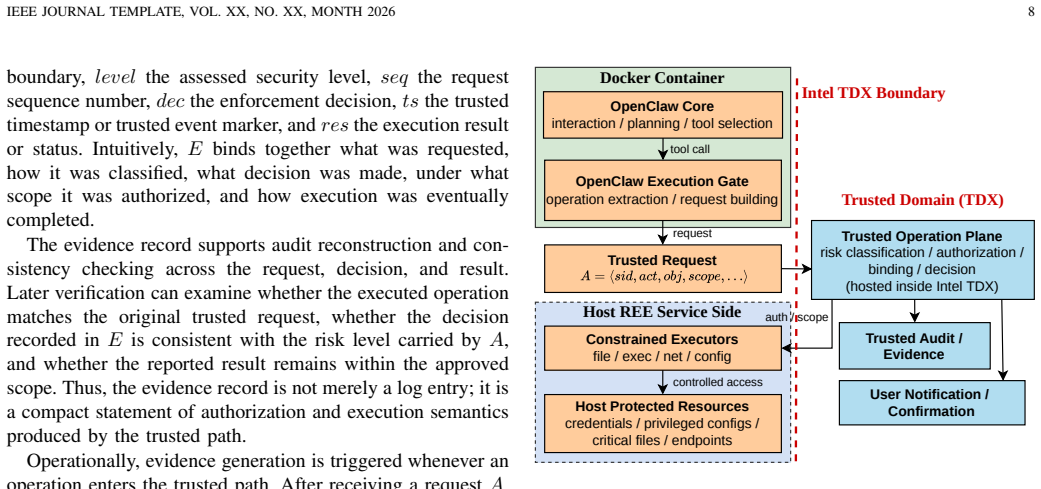
The paper establishes an architecture that keeps routine agent functionality on the constrained REE path while protecting classification, authorization, binding, evidence generation, and selected execution controls inside a TEE-backed trusted operation plane. Remote terminal-side components verify TEE-audited commands before any constrained local execution occurs. This allows the system to intercept unsafe or policy-disallowed operations, leave permitted workloads unchanged, and produce verifiable records of decisions.
What carries the argument
The TEE-backed trusted operation plane, which isolates security-critical classification, authorization, and evidence tasks from the host so that risk judgments cannot be subverted along the normal control path.
If this is right
- Unsafe or policy-disallowed operations are intercepted and prevented before any host-side effect occurs.
- Ordinary functionality for allowed workloads continues with no change to the agent's normal execution path.
- Auditable evidence of classification decisions and command bindings can be generated for later inspection.
- Overhead scales with the fraction of operations that require TEE involvement.
Where Pith is reading between the lines
- The same separation of risk decisions from execution could be applied to other agents that receive natural-language instructions and touch local resources.
- Remote verification of TEE records might support centralized policy enforcement across multiple independent agents.
- Hardware-protected classification reduces the need for ever-growing lists of ad-hoc blocking rules.
Load-bearing premise
The trusted execution environment will correctly classify operations and enforce authorization decisions without being subverted by the host or by flaws in the risk model itself.
What would settle it
An experiment in which an unsafe operation reaches execution despite the TEE checks, or a legitimate operation is blocked because the trusted plane misclassified its risk.
Figures


read the original abstract
Self-hosted computer-use agents (SHCUAs), such as OpenClaw, combine natural-language interaction with direct access to host-side resources, including browsers, files, scripts, system commands, and external communication channels. While useful for automating real tasks, this capability also creates a host-level abuse surface: a legitimately deployed agent may be steered toward unsafe operations through malicious messages, indirect prompt injection, unsafe skills, or tampering along the host-side control path. We argue that such risks cannot be addressed by ad hoc blocking rules alone, because the security criticality of an operation depends jointly on its action type, target object, execution context, and potential effect. This paper presents an operation-centric model for risk-based confinement of SHCUA operations. The proposed design keeps ordinary functionality on the constrained REE path, while protecting security-critical classification, authorization, binding, evidence generation, and selected execution-control decisions inside a cloud-native TEE-backed trusted operation plane. We instantiate the architecture on OpenClaw using Intel TDX as the primary trusted backend, with remote terminal-side trusted components verifying TDX-audited commands before constrained local execution. The evaluation shows that the design can block unsafe or policy-disallowed operations before execution, preserve ordinary functionality for allowed workloads, and provide auditable evidence with deployment-dependent overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an operation-centric risk model for confining self-hosted computer-use agents (SHCUAs) such as OpenClaw. It places security-critical functions—risk classification, authorization, binding, evidence generation, and selected execution controls—inside a cloud-native TEE-backed trusted operation plane (instantiated with Intel TDX), while keeping ordinary functionality on the constrained REE path. Remote terminal-side components verify TDX-audited commands before local execution. The abstract states that evaluation demonstrates blocking of unsafe or policy-disallowed operations, preservation of allowed functionality, and provision of auditable evidence at deployment-dependent overhead.
Significance. If the central claims hold, the work would offer a concrete hardware-assisted mechanism for mitigating host-level abuse in agentic systems that combine natural-language control with direct resource access, a timely contribution given the rapid deployment of tools like OpenClaw. The separation of the trusted operation plane from the host is a principled use of TEE properties and could generalize beyond the specific instantiation.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: the claim that 'the evaluation shows that the design can block unsafe or policy-disallowed operations before execution' is presented without any description of test cases, adversarial scenarios (e.g., indirect prompt injection, skill tampering, novel operation sequences), classification accuracy metrics, or error analysis. This is load-bearing for the confinement guarantee because the architecture relies on correct joint action/target/context/effect classification inside the TEE.
- [Architecture / Trusted Operation Plane] Architecture description of the trusted operation plane: no specification is given of the classification rules, decision procedure, or risk model used to label operations as safe/unsafe. Without this, it is impossible to assess whether the TEE merely enforces an arbitrary policy reliably or actually prevents abuse; the paper itself argues that ad-hoc rules are insufficient, yet provides no evidence that the model inside the TEE is robust.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly indicated the scale of the evaluation (number of workloads, types of disallowed operations tested) and the measured overhead range rather than stating only that overhead is 'deployment-dependent'.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas where the manuscript can be strengthened to better substantiate its claims. We respond to each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the claim that 'the evaluation shows that the design can block unsafe or policy-disallowed operations before execution' is presented without any description of test cases, adversarial scenarios (e.g., indirect prompt injection, skill tampering, novel operation sequences), classification accuracy metrics, or error analysis. This is load-bearing for the confinement guarantee because the architecture relies on correct joint action/target/context/effect classification inside the TEE.
Authors: We agree that the current Evaluation section provides only high-level aggregate results and lacks the detailed experimental description needed to support the abstract's claims. The manuscript does not currently include the requested breakdown of test cases, adversarial scenarios, metrics, or error analysis. In the revised manuscript we will expand the Evaluation section with a full description of the test suite (including indirect prompt injection, skill tampering, and novel operation sequences), classification accuracy metrics, false-positive/negative rates, and error analysis. These additions will directly address the load-bearing nature of the joint classification guarantee. revision: yes
-
Referee: [Architecture / Trusted Operation Plane] Architecture description of the trusted operation plane: no specification is given of the classification rules, decision procedure, or risk model used to label operations as safe/unsafe. Without this, it is impossible to assess whether the TEE merely enforces an arbitrary policy reliably or actually prevents abuse; the paper itself argues that ad-hoc rules are insufficient, yet provides no evidence that the model inside the TEE is robust.
Authors: The manuscript defines an operation-centric risk model in which criticality is assessed jointly from action type, target object, execution context, and potential effect, explicitly contrasting this with ad-hoc rules. However, the current draft does not provide an explicit specification of the classification rules or decision procedure. We will revise the Architecture section to include a formal description of the risk model, pseudocode for the decision procedure, and concrete examples of how the four factors are combined to label operations. This will clarify that the TEE enforces a structured, non-arbitrary policy and will allow readers to evaluate its robustness properties from the design. revision: yes
Circularity Check
No circularity: architectural proposal relies on external TEE properties
full rationale
The paper presents a system design and architecture for TEE-backed isolation of security-critical operations in SHCUAs. It contains no equations, no fitted parameters, no predictions derived from data, and no self-citations or uniqueness theorems that bear the load of the central claims. The argument that ad-hoc rules are insufficient and that TEE placement protects classification/authorization is justified by reference to standard TEE isolation guarantees (e.g., Intel TDX) rather than by any reduction to the paper's own inputs or definitions. The design is self-contained as a proposal against external benchmarks of TEE behavior.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A TEE such as Intel TDX provides isolation sufficient to protect classification, authorization, and evidence-generation decisions from the host REE path.
- domain assumption Security risk of an operation can be correctly determined from its action type, target object, execution context, and potential effects.
Reference graph
Works this paper leans on
-
[1]
(2026, Feb.) Openclaw vulnerability: Website-to-local agent takeover
The Oasis Research Team. (2026, Feb.) Openclaw vulnerability: Website-to-local agent takeover. [Online]. Available: https://www.oasis. security/blog/openclaw-vulnerability IEEE JOURNAL TEMPLATE, VOL. XX, NO. XX, MONTH 2026 16
2026
-
[2]
(2026, Jan.) Openclaw/clawdbot has 1-click RCE via authentication token exfiltration from gatewayurl
GitHub Advisory Database. (2026, Jan.) Openclaw/clawdbot has 1-click RCE via authentication token exfiltration from gatewayurl. [Online]. Available: https://github.com/advisories/GHSA-g8p2-7wf7-98mq
2026
-
[3]
K. Breen. (2026, Mar.) Openclaw: Hunting season is open. Immersive. [Online]. Available: https://www.immersivelabs.com/resources/c7-blog/ openclaw-hunting-season-is-open
2026
-
[4]
P. Arntz. (2026, Mar.) Beware of fake openclaw installers, even if bing points you to github. Malwarebytes. [On- line]. Available: https://www.malwarebytes.com/blog/news/2026/03/ beware-of-fake-openclaw-installers-even-if-bing-points-you-to-github
2026
-
[5]
OP-TEE (Open Portable Trusted Ex- ecution Environment),
The Linux Kernel Documentation, “OP-TEE (Open Portable Trusted Ex- ecution Environment),” https://docs.kernel.org/tee/op-tee.html, accessed 2026
2026
-
[6]
OP-TEE Documentation,
OP-TEE Project, “OP-TEE Documentation,” https://optee.readthedocs. io/, accessed 2026
2026
-
[7]
Keystone: An Open Framework for Architecting Trusted Execution Environments,
D. Lee, D. Kohlbrenner, S. Shinde, K. Asanovi ´c, and D. Song, “Keystone: An Open Framework for Architecting Trusted Execution Environments,” inProceedings of the Fifteenth European Conference on Computer Systems, ser. EuroSys ’20. ACM, 2020
2020
-
[8]
Keystone Enclave Documentation,
Keystone Enclave Project, “Keystone Enclave Documentation,” https: //docs.keystone-enclave.org/, accessed 2026
2026
-
[9]
Enclave Application Cache for RISC-V Keystone,
T. Umezawa, A. Saiki, and K. Kimura, “Enclave Application Cache for RISC-V Keystone,” inProceedings of the 2025 Workshop on System Software for Trusted Execution, 2025
2025
-
[10]
(2026) Openclaw - personal AI assistant
OpenClaw. (2026) Openclaw - personal AI assistant. GitHub repository. [Online]. Available: https://github.com/openclaw/openclaw
2026
-
[11]
Camels can use computers too: System-level security for computer use agents,
H. Foerster, T. Blanchard, K. Nikoli ´c, I. Shumailov, C. Zhang, R. Mullins, N. Papernot, F. Tram `er, and Y . Zhao, “Camels can use computers too: System-level security for computer use agents,” Jan
-
[12]
[Online]. Available: https://arxiv.org/abs/2601.09923
-
[13]
Your Agent, Their Asset: A Real-World Safety Analysis of OpenClaw
Z. Wang, H. Tu, L. Zhang, H. Chen, J. Wu, X. Liu, Z. Yuan, T. Pang, M. Q. Shieh, F. Liu, Z. Zheng, H. Yao, Y . Zhou, and C. Xie, “Your agent, their asset: A real-world safety analysis of openclaw,” Apr. 2026. [Online]. Available: https://arxiv.org/abs/2604.04759
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
A systematic security evaluation of openclaw and its variants,
Y . Wang, H. Gao, Z. Niu, Z. Liu, W. Zhang, X. Wang, and S. Lian, “A systematic security evaluation of openclaw and its variants,” Apr
-
[15]
A Systematic Security Evaluation of OpenClaw and Its Variants
[Online]. Available: https://arxiv.org/abs/2604.03131
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
VPI-Bench: Visual prompt injection attacks for computer-use agents,
T. Cao, B. Lim, Y . Liu, Y . Sui, Y . Li, S. Deng, L. Lu, N. Oo, S. Yan, and B. Hooi, “VPI-Bench: Visual prompt injection attacks for computer-use agents,” Jun. 2025. [Online]. Available: https://arxiv.org/abs/2506.02456
-
[17]
What Did It Actually Do?: Understanding risk awareness and traceability for computer-use agents,
Z. Peng and M. Li, “What Did It Actually Do?: Understanding risk awareness and traceability for computer-use agents,” Mar. 2026. [Online]. Available: https://arxiv.org/abs/2603.28551
-
[18]
Don’t let the claw grip your hand: A security analysis and defense framework for openclaw,
Z. Shan, J. Xin, Y . Zhang, and M. Xu, “Don’t let the claw grip your hand: A security analysis and defense framework for openclaw,” Mar
-
[19]
[Online]. Available: https://arxiv.org/abs/2603.10387
-
[20]
Z. Ying, X. Yang, S. Wu, Y . Song, Y . Qu, H. Li, T. Li, J. Wang, A. Liu, and X. Liu, “Uncovering security threats and architecting defenses in autonomous agents: A case study of openclaw,” Mar. 2026. [Online]. Available: https://arxiv.org/abs/2603.12644
-
[21]
ClawLess: A Security Model of AI Agents
H. Lu, N. Liu, S. Wang, and F. Zhang, “Clawless: A security model of AI agents,” Apr. 2026. [Online]. Available: https://arxiv.org/abs/2604.06284
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents
Q. Zhan, Z. Liang, Z. Ying, and D. Kang, “Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents,” Mar. 2024. [Online]. Available: https://arxiv.org/abs/2403.02691
work page internal anchor Pith review arXiv 2024
-
[23]
AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents
E. Debenedetti, J. Zhang, M. Balunovi ´c, L. Beurer-Kellner, M. Fischer, and F. Tram`er, “Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents,” Jun. 2024. [Online]. Available: https://arxiv.org/abs/2406.13352
work page internal anchor Pith review arXiv 2024
-
[24]
Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents
H. Zhang, J. Huang, K. Mei, Y . Yao, Z. Wang, C. Zhan, H. Wang, and Y . Zhang, “Agent security bench (ASB): Formalizing and benchmarking attacks and defenses in LLM-based agents,” Oct. 2024. [Online]. Available: https://arxiv.org/abs/2410.02644
work page internal anchor Pith review arXiv 2024
-
[25]
Os-harm: A benchmark for measuring safety of computer use agents
T. Kuntz, A. Duzan, H. Zhao, F. Croce, J. Z. Kolter, N. Flammarion, and M. Andriushchenko, “OS-Harm: A benchmark for measuring safety of computer use agents,” Jun. 2025. [Online]. Available: https://arxiv.org/abs/2506.14866
-
[26]
Wasp: Benchmarking web agent security against prompt injection attacks,
I. Evtimov, A. Zharmagambetov, A. Grattafiori, C. Guo, and K. Chaudhuri, “W ASP: Benchmarking web agent security against prompt injection attacks,” Apr. 2025. [Online]. Available: https: //arxiv.org/abs/2504.18575
-
[27]
AgentHazard: A Benchmark for Evaluating Harmful Behavior in Computer-Use Agents
Y . Feng, Y . Ding, Y . Tan, X. Ma, Y . Li, Y . Wu, Y . Gao, K. Zhai, and Y . Guo, “Agenthazard: A benchmark for evaluating harmful behavior in computer-use agents,” Apr. 2026. [Online]. Available: https://arxiv.org/abs/2604.02947
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
ClawSafety: "Safe" LLMs, Unsafe Agents
B. Wei, Y . Zhang, J. Pan, K. Mei, X. Wang, J. Hamm, Z. Zhu, and Y . Ge, “Clawsafety: “Safe” LLMs, Unsafe Agents,” Apr. 2026. [Online]. Available: https://arxiv.org/abs/2604.01438
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
W. Luo, Q. Zhang, T. Lu, X. Liu, B. Hu, H.-C. Chiu, S. Ma, Y . Zhang, X. Xiao, Y . Cao, Z. Xiang, and C. Xiao, “Code agent can be an end-to- end system hacker: Benchmarking real-world threats of computer-use agent,” Oct. 2025. [Online]. Available: https://arxiv.org/abs/2510.06607
-
[30]
ICON: Indirect prompt injection defense for agents based on inference-time correction,
C. Wang, F. Zhang, J. Zhang, Z. Zhang, Y . Wang, L. Huang, J. Gao, Z. Chen, and W. Y . B. Lim, “ICON: Indirect prompt injection defense for agents based on inference-time correction,” Feb. 2026. [Online]. Available: https://arxiv.org/abs/2602.20708
-
[31]
Simple prompt injection attacks can leak personal data observed by llm agents during task execution
M. Alizadeh, Z. Samei, D. Stetsenko, and F. Gilardi, “Simple prompt injection attacks can leak personal data observed by LLM agents during task execution,” Jun. 2025. [Online]. Available: https://arxiv.org/abs/2506.01055
-
[32]
P. Wang, X. Li, C. Xiang, J. Zhang, Y . Li, L. Zhang, X. Wang, and Y . Tian, “The landscape of prompt injection threats in LLM agents: From taxonomy to analysis,” Feb. 2026. [Online]. Available: https://arxiv.org/abs/2602.10453
-
[33]
Memory poisoning attack and defense on memory based LLM-agents,
B. D. Sunil, I. Sinha, P. Maheshwari, S. Todmal, S. Mallik, and S. Mishra, “Memory poisoning attack and defense on memory based LLM-agents,” Jan. 2026. [Online]. Available: https://arxiv.org/abs/2601. 05504
2026
-
[34]
AgentSpec: Customizable Runtime Enforcement for Safe and Reliable LLM Agents
H. Wang, C. M. Poskitt, and J. Sun, “Agentspec: Customizable runtime enforcement for safe and reliable LLM agents,” Mar. 2025. [Online]. Available: https://arxiv.org/abs/2503.18666
work page internal anchor Pith review arXiv 2025
-
[35]
Formal Policy Enforcement for Real-World Agentic Systems
N. Palumbo, S. Choudhary, J. Choi, P. Chalasani, and S. Jha, “Policy compiler for secure agentic systems,” Feb. 2026. [Online]. Available: https://arxiv.org/abs/2602.16708
work page internal anchor Pith review arXiv 2026
-
[36]
MI9 – agent intelligence protocol: Runtime governance for agentic AI systems,
C. L. Wang, T. Singhal, A. Kelkar, and J. Tuo, “MI9: An integrated runtime governance framework for agentic AI,” Aug. 2025. [Online]. Available: https://arxiv.org/abs/2508.03858
-
[37]
C. Koch, “From governance norms to enforceable controls: A layered translation method for runtime guardrails in agentic AI,” Apr. 2026. [Online]. Available: https://arxiv.org/abs/2604.05229
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
M. Kaptein, V .-J. Khan, and A. Podstavnychy, “Runtime governance for AI agents: Policies on paths,” Mar. 2026. [Online]. Available: https://arxiv.org/abs/2603.16586
- [39]
-
[40]
Progent: Securing AI Agents with Privilege Control
T. Shi, J. He, Z. Wang, H. Li, L. Wu, W. Guo, and D. Song, “Progent: Programmable privilege control for LLM agents,” Apr. 2025. [Online]. Available: https://arxiv.org/abs/2504.11703
work page internal anchor Pith review arXiv 2025
-
[41]
Pro2guard: Proactive runtime enforcement of llm agent safety via probabilistic model checking,
H. Wang, C. M. Poskitt, J. Wei, and J. Sun, “Probguard: Probabilistic runtime monitoring for LLM agent safety,” Aug. 2025. [Online]. Available: https://arxiv.org/abs/2508.00500
-
[42]
Agent Behavioral Contracts: Formal Specification and Runtime Enforcement,
V . P. Bhardwaj, “Agent behavioral contracts: Formal specification and runtime enforcement for reliable autonomous AI agents,” Feb. 2026. [Online]. Available: https://arxiv.org/abs/2602.22302
-
[43]
Evaluating Privilege Usage of Agents with Real-World Tools
Q. Zhang, L. Fu, L. Lian, G. Go, Y . Wang, C. Zhou, Y . Jiang, and G. Pu, “Evaluating privilege usage of agents with real-world tools,” Mar. 2026. [Online]. Available: https://arxiv.org/abs/2603.28166
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
SafeClaw-R: Towards safe and secure multi-agent personal assistants,
H. Wang, Z. Xiao, Y . Zhang, C. M. Poskitt, and J. Sun, “Safeclaw-r: Towards safe and secure multi-agent personal assistants,” Mar. 2026. [Online]. Available: https://arxiv.org/abs/2603.28807
-
[45]
Security Considerations for Artificial Intelligence Agents
N. Li, K. Zhang, K. Polley, and J. Ma, “Security considerations for artificial intelligence agents,” Mar. 2026. [Online]. Available: https://arxiv.org/abs/2603.12230
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
Preventing privilege escala- tion,
N. Provos, M. Friedl, and P. Honeyman, “Preventing privilege escala- tion,” inProceedings of the 12th USENIX Security Symposium, 2003, pp. 231–242. [Online]. Available: https://www.usenix.org/conference/ 12th-usenix-security-symposium/preventing-privilege-escalation
2003
-
[47]
Enforceable security policies,
F. B. Schneider, “Enforceable security policies,”ACM Transactions on Information and System Security, vol. 3, no. 1, pp. 30–50, 2000. [Online]. Available: https://dl.acm.org/doi/10.1145/353323.353382
-
[48]
SC-11: Trusted Path,
National Institute of Standards and Technology, “SC-11: Trusted Path,” 2020, nIST SP 800-53 Rev. 5. [Online]. Available: https: //csrc.nist.gov/pubs/sp/800/53/r5/upd1/final
2020
-
[49]
J. A. Vaughan, L. Jia, K. Mazurak, and S. Zdancewic, “Evidence- based audit,” inProceedings of the 21st IEEE Computer Security Foundations Symposium (CSF), 2008, pp. 177–191. [Online]. Available: https://doi.org/10.1109/CSF.2008.24
-
[50]
M. Christodorescu, E. Fernandes, A. Hooda, S. Jha, J. Rehberger, K. Chaudhuri, X. Fu, K. Shams, G. Amir, J. Choi, S. Choudhary, N. Palumbo, A. Labunets, and N. V . Pandya, “Systems security IEEE JOURNAL TEMPLATE, VOL. XX, NO. XX, MONTH 2026 17 foundations for agentic computing,” Dec. 2025. [Online]. Available: https://arxiv.org/abs/2512.01295
-
[51]
Ai agents under threat: A survey of key security challenges and future pathways,
Z. Deng, Y . Guo, C. Han, W. Ma, J. Xiong, S. Wen, and Y . Xiang, “AI agents under threat: A survey of key security challenges and future pathways,” Jun. 2024. [Online]. Available: https://arxiv.org/abs/2406.02630
-
[52]
Agentvigil: Generic black-box red-teaming for indirect prompt injection against LLM agents,
Z. Wang, V . Siu, Z. Ye, T. Shi, Y . Nie, X. Zhao, C. Wang, W. Guo, and D. Song, “Agentvigil: Generic black-box red-teaming for indirect prompt injection against LLM agents,” May 2025. [Online]. Available: https://arxiv.org/abs/2505.05849
-
[53]
Available: https://arxiv.org/abs/2407.12784
Z. Chen, Z. Xiang, C. Xiao, D. Song, and B. Li, “Agentpoison: Red-teaming LLM agents via poisoning memory or knowledge bases,” Jul. 2024. [Online]. Available: https://arxiv.org/abs/2407.12784
-
[54]
Poison once, exploit forever: Environment-injected memory poisoning attacks on web agents,
W. Zou, M. Dong, M. R. Calvo, S. Chang, J. Guo, D. Lee, X. Niu, X. Ma, Y . Qi, and J. Jiang, “Poison once, exploit forever: Environment-injected memory poisoning attacks on web agents,” Apr
-
[55]
Poison Once, Exploit Forever: Environment-Injected Memory Poisoning Attacks on Web Agents
[Online]. Available: https://arxiv.org/abs/2604.02623
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
N. Maloyan and D. Namiot, “Prompt injection attacks on agentic coding assistants: A systematic analysis of vulnerabilities in skills, tools, and protocol ecosystems,” Jan. 2026. [Online]. Available: https://arxiv.org/abs/2601.17548 Di Lu(Member, IEEE) received the B.S., M.S., and Ph.D. degrees in computer science and technology from Xidian University, Chi...
-
[57]
His research interests include trusted com- puting, confidential computing, system and network security
Now he is a full Professor in the School of Computer Science and Technology at Xidian Uni- versity. His research interests include trusted com- puting, confidential computing, system and network security. Bo Zhangreceived the BS degree from Nanyang In- stitute of Technology, China, in 2025. He is currently pursuing an MS degree in the School of Computer S...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.