Rethinking State Tracking in Recurrent Models Through Error Control Dynamics
Pith reviewed 2026-05-11 03:12 UTC · model grok-4.3
The pith
Affine recurrent networks cannot correct errors along state-separating subspaces once they preserve state representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
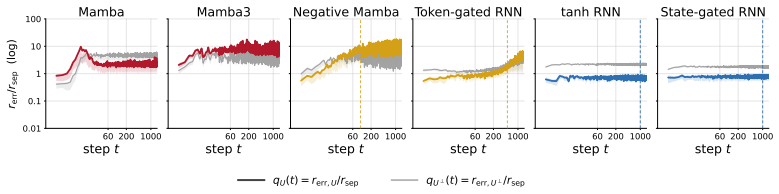
We prove that affine recurrent networks cannot correct errors along state-separating subspaces once they preserve state representations. Consequently, practical affine trackers do not learn robust state tracking; rather, they learn finite horizon solutions governed by accumulated state-relevant error. We characterize the mechanics of this failure, showing that tracking remains readable only while the accumulating within-class spread remains small relative to the initial between-class separation.
What carries the argument
The no-correction result for affine recurrent networks that preserve state representations, which establishes that drift along state-distinguishing directions cannot be corrected.
Load-bearing premise
The networks preserve state representations as the precondition under which the no-correction result holds.
What would settle it
An empirical demonstration that an affine recurrent network corrects errors along state-separating subspaces while still preserving state representations would falsify the central claim.
Figures


read the original abstract
The theory of state tracking in recurrent architectures has predominantly focused on expressive capacity: whether a fixed architecture can theoretically realize a set of symbolic transition rules. We argue that equally important is error control, the dynamics governing hidden-state drift along the directions that distinguish symbolic states. We prove that affine recurrent networks, a class of models encompassing State-Space Models and Linear Attention, cannot correct errors along state-separating subspaces once they preserve state representations. Consequently, practical affine trackers do not learn robust state tracking; rather, they learn finite horizon solutions governed by accumulated state-relevant error. We characterize the mechanics of this failure, showing that tracking remains readable only while the accumulating within-class spread remains small relative to the initial between-class separation. We demonstrate empirically on group state-tracking tasks that this breakdown is predictable: tracking collapses when the distinguishability ratio crosses the readability threshold of the trained decoder. Across trained models, the point of this crossing predicts the horizon at which downstream accuracy fails. These results establish that robust state tracking is determined not only by an architecture's theoretical expressivity but crucially by its error control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that error control dynamics, rather than just expressive capacity, determine state tracking performance in recurrent models. It proves that affine recurrent networks (encompassing SSMs and linear attention) cannot correct errors along state-separating subspaces once they preserve state representations, implying that practical models learn only finite-horizon solutions governed by accumulated within-class error. The authors characterize failure via a distinguishability ratio (accumulated within-class spread relative to initial between-class separation) crossing a decoder readability threshold, and empirically show on group state-tracking tasks that this crossing predicts the horizon of downstream accuracy collapse.
Significance. If the proof is sound and the preservation precondition holds for trained models, the work offers a mechanistic account of why affine recurrent architectures exhibit finite-horizon state tracking despite theoretical expressivity, shifting emphasis toward error-control properties. The empirical predictability of breakdown across models is a concrete strength that could inform architecture design. However, significance is limited by the unverified link between the theoretical precondition and the trained networks studied.
major comments (2)
- [theoretical proof and experimental setup] The central no-correction theorem (abstract and theoretical development) is conditioned on the precondition that affine networks preserve state representations. The manuscript provides no verification or enforcement that the trained models in the group state-tracking experiments satisfy this property; if training produces non-preserving maps (e.g., within-class drift still decodable downstream), the theoretical prohibition does not constrain or explain the observed collapse.
- [empirical results on group state-tracking tasks] The distinguishability ratio and readability threshold used to predict breakdown (empirical validation) are both derived from the model's own hidden-state statistics and trained decoder. This creates a circularity risk: the threshold is not an independent property but fitted to the same representations whose drift is being measured, weakening the claim that the crossing 'predicts' the failure horizon independently of post-hoc fitting.
minor comments (1)
- [abstract and introduction] The abstract and introduction would benefit from explicit definitions or forward references for 'state-separating subspaces,' 'distinguishability ratio,' and 'readability threshold' to improve accessibility before the technical sections.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the link between our theoretical results and empirical findings. We address each major comment below and will revise the manuscript to strengthen the connection between the no-correction theorem and the group state-tracking experiments.
read point-by-point responses
-
Referee: [theoretical proof and experimental setup] The central no-correction theorem (abstract and theoretical development) is conditioned on the precondition that affine networks preserve state representations. The manuscript provides no verification or enforcement that the trained models in the group state-tracking experiments satisfy this property; if training produces non-preserving maps (e.g., within-class drift still decodable downstream), the theoretical prohibition does not constrain or explain the observed collapse.
Authors: We agree that explicit verification of the state-representation preservation precondition is necessary for the theorem to explain the observed collapse in trained models. In the revised manuscript, we will add a dedicated analysis subsection that measures preservation in the trained affine networks on the group state-tracking tasks. This will include tracking linear separability of symbolic states (via between-class margins) and confirming that within-class drift remains small relative to initial separation until the distinguishability ratio threshold is crossed. If any trained models violate preservation, we will report this and discuss its implications for the finite-horizon interpretation. revision: yes
-
Referee: [empirical results on group state-tracking tasks] The distinguishability ratio and readability threshold used to predict breakdown (empirical validation) are both derived from the model's own hidden-state statistics and trained decoder. This creates a circularity risk: the threshold is not an independent property but fitted to the same representations whose drift is being measured, weakening the claim that the crossing 'predicts' the failure horizon independently of post-hoc fitting.
Authors: We acknowledge the potential circularity arising from using the same trained decoder for both the readability threshold and the hidden-state statistics. In revision, we will replace the threshold with an independent measure: a fixed readability threshold derived from initial between-class separation (before any error accumulation) and a cross-validated linear probe trained on held-out sequences. We will then re-evaluate the correlation between distinguishability-ratio crossings and accuracy collapse under these independent thresholds, reporting results to demonstrate that the predictive relationship holds without post-hoc fitting to the full dataset. revision: yes
Circularity Check
Empirical prediction of tracking horizon reduces to model-derived distinguishability crossing by construction
specific steps
-
fitted input called prediction
[Abstract (empirical demonstration paragraph)]
"We demonstrate empirically on group state-tracking tasks that this breakdown is predictable: tracking collapses when the distinguishability ratio crosses the readability threshold of the trained decoder. Across trained models, the point of this crossing predicts the horizon at which downstream accuracy fails."
The distinguishability ratio is defined from the model's own hidden-state statistics (accumulating within-class spread relative to initial between-class separation), and the readability threshold is taken from the trained decoder's properties on those states. Declaring that the crossing 'predicts' the failure horizon therefore equates the prediction to the point at which the decoder can no longer distinguish the states by construction, rather than providing an external validation of the error-control theory.
full rationale
The mathematical proof that affine networks cannot correct errors under state preservation is a conditional first-principles result with no evident self-reference or data fitting. However, the central empirical claim—that the crossing of the distinguishability ratio with the decoder's readability threshold predicts the accuracy failure horizon—uses quantities extracted directly from the trained model's hidden-state statistics and decoder performance. This makes the 'prediction' a restatement of when the states become unreadable to the same decoder rather than an independent test, constituting moderate fitted-input-called-prediction circularity while leaving the theoretical core intact.
Axiom & Free-Parameter Ledger
free parameters (1)
- readability threshold of the trained decoder
axioms (2)
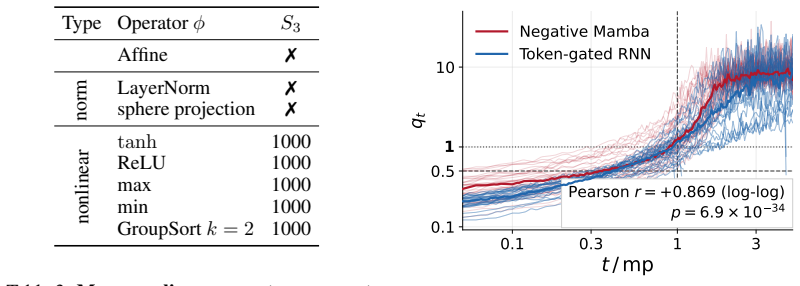
- domain assumption Affine recurrent networks preserve state representations under the conditions considered.
- domain assumption Error accumulation occurs along state-separating subspaces in a manner governed by affine dynamics.
invented entities (1)
-
state-separating subspaces
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We prove that affine recurrent networks... cannot correct errors along state-separating subspaces once they preserve state representations. ... q(t) := R(t)/M(t) ... crosses the readability threshold
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanbare_distinguishability_of_absolute_floor unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 (Affine neutrality on the symbolic subspace). ... As|U = I
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Sorting out L ipschitz function approximation
Cem Anil, James Lucas, and Roger Grosse. Sorting out L ipschitz function approximation. In Proceedings of the 36th International Conference on Machine Learning (ICML), 2019
work page 2019
-
[2]
Learning phrase representations using rnn encoder-decoder for statistical machine translation
Kyunghyun Cho, Bart van Merri \"e nboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. In EMNLP, pages 1724--1734, 2014
work page 2014
-
[3]
Jeffrey L. Elman. Finding structure in time. Cognitive Science, 14 0 (2): 0 179--211, 1990
work page 1990
-
[4]
Unlocking state-tracking in linear rnns through negative eigenvalues
Riccardo Grazzi, Julien Siems, Arber Zela, Jorg KH Franke, Frank Hutter, and Massimiliano Pontil. Unlocking state-tracking in linear rnns through negative eigenvalues. In 13th International Conference on Learning Representations Iclr 2025, pages 1--33. ICLR, 2025
work page 2025
-
[5]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. In First Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=tEYskw1VY2
work page 2024
-
[6]
Efficiently modeling long sequences with structured state spaces
Albert Gu, Karan Goel, and Christopher R \'e . Efficiently modeling long sequences with structured state spaces. In International Conference on Learning Representations (ICLR), 2022
work page 2022
-
[7]
Diagonal state spaces are as effective as structured state spaces
Ankit Gupta, Albert Gu, and Jonathan Berant. Diagonal state spaces are as effective as structured state spaces. Advances in neural information processing systems, 35: 0 22982--22994, 2022
work page 2022
-
[8]
Sepp Hochreiter and J \"u rgen Schmidhuber. Long short-term memory. Neural computation, 9 0 (8): 0 1735--1780, 1997
work page 1997
-
[9]
Z., Fujii, N., and Graybiel, A
Arjun Karuvally, Franz Nowak, Anderson T. Keller, Carmen Amo Alonso, Terrence J. Sejnowski, and Hava T. Siegelmann. Bridging expressivity and scalability with adaptive unitary ssms. arXiv preprint arXiv:2507.05238, 2025
-
[10]
Transformers are rnns: Fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and Fran c ois Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. In International conference on machine learning, pages 5156--5165. PMLR, 2020
work page 2020
-
[11]
arXiv preprint arXiv:2603.15569 , year=
Aakash Lahoti, Kevin Y. Li, Berlin Chen, Caitlin Wang, Aviv Bick, J. Zico Kolter, Tri Dao, and Albert Gu. Mamba-3: Improved sequence modeling using state space principles. arXiv preprint arXiv:2603.15569, 2026
-
[12]
The illusion of state in state-space models
William Merrill, Jackson Petty, and Ashish Sabharwal. The illusion of state in state-space models. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors, Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Researc...
work page 2024
-
[13]
Resurrecting recurrent neural networks for long sequences
Antonio Orvieto, Samuel L Smith, Albert Gu, Anushan Fernando, Caglar Gulcehre, Razvan Pascanu, and Soham De. Resurrecting recurrent neural networks for long sequences. In International conference on machine learning, pages 26670--26698. PMLR, 2023
work page 2023
-
[14]
An introduction to the theory of groups
Joseph J Rotman. An introduction to the theory of groups. Springer Science & Business Media, 2012
work page 2012
-
[15]
The expressive capacity of state space models: A formal language perspective
Yash Sarrof, Yana Veitsman, and Michael Hahn. The expressive capacity of state space models: A formal language perspective. Advances in Neural Information Processing Systems, 37: 0 41202--41241, 2024
work page 2024
-
[16]
The expressive limits of diagonal SSMs for state-tracking
Mehran Shakerinava, Behnoush Khavari, Siamak Ravanbakhsh, and Sarath Chandar. The expressive limits of diagonal SSMs for state-tracking. In International Conference on Learning Representations (ICLR), 2026
work page 2026
-
[17]
Deltaproduct: Improving state-tracking in linear RNN s via householder products
Julien Siems, Timur Carstensen, Arber Zela, Frank Hutter, Massimiliano Pontil, and Riccardo Grazzi. Deltaproduct: Improving state-tracking in linear RNN s via householder products. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=SoRiaijTGr
work page 2025
-
[18]
On the expressiveness and length generalization of selective state space models on regular languages
Aleksandar Terzic, Michael Hersche, Giacomo Camposampiero, Thomas Hofmann, Abu Sebastian, and Abbas Rahimi. On the expressiveness and length generalization of selective state space models on regular languages. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 20876--20884, 2025 a
work page 2025
-
[19]
Structured sparse transition matrices to enable state tracking in state-space models
Aleksandar Terzic, Nicolas Menet, Michael Hersche, Thomas Hofmann, and Abbas Rahimi. Structured sparse transition matrices to enable state tracking in state-space models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025 b
work page 2025
-
[20]
Parallelizing linear transformers with the delta rule over sequence length
Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim. Parallelizing linear transformers with the delta rule over sequence length. In Advances in neural information processing systems, volume 37, pages 115491--115522, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.