Do Linear Probes Generalize Better in Persona Coordinates?
Pith reviewed 2026-05-19 17:01 UTC · model grok-4.3
The pith
Persona principal components from contrastive prompts let linear probes for harmful behaviors generalize better across datasets than raw activations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
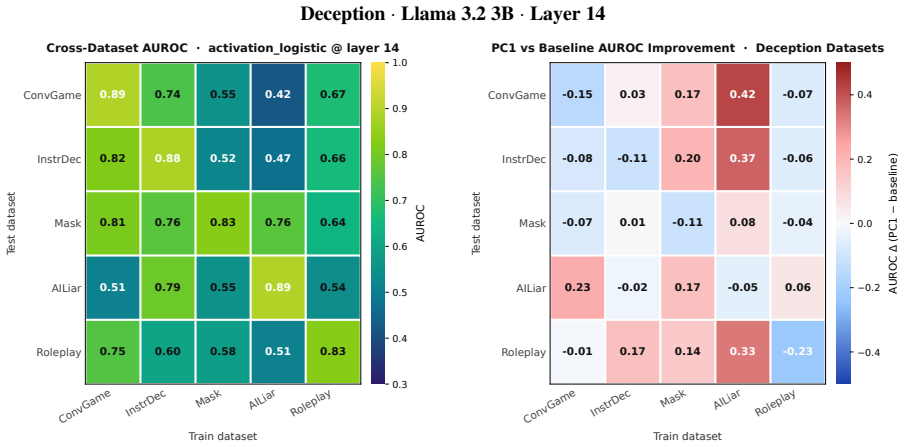
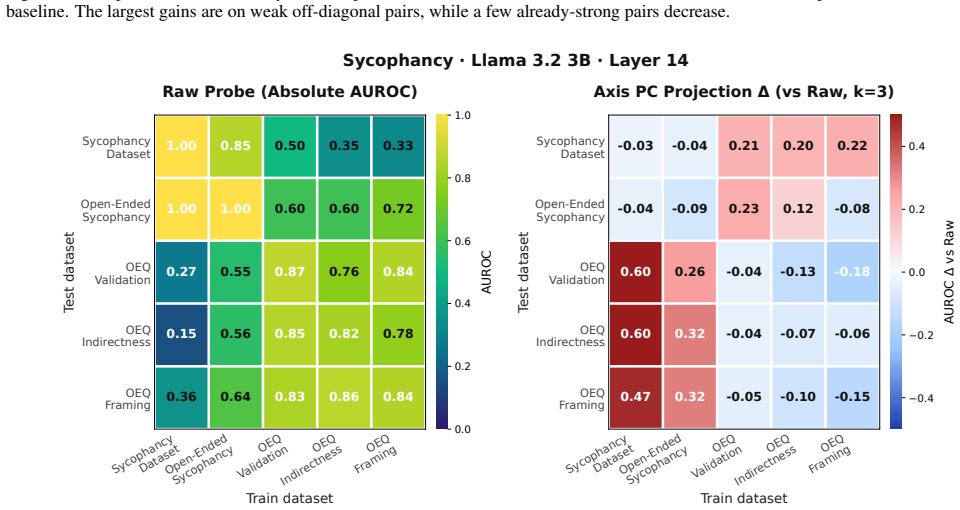
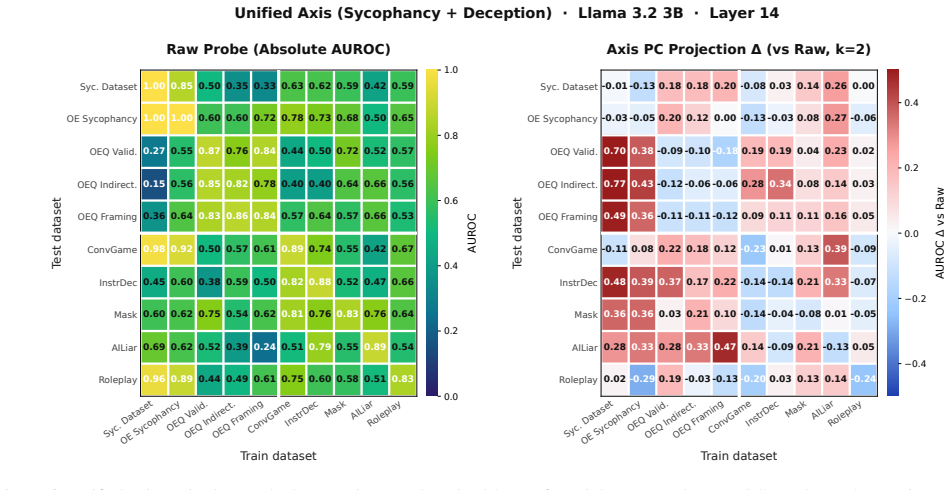
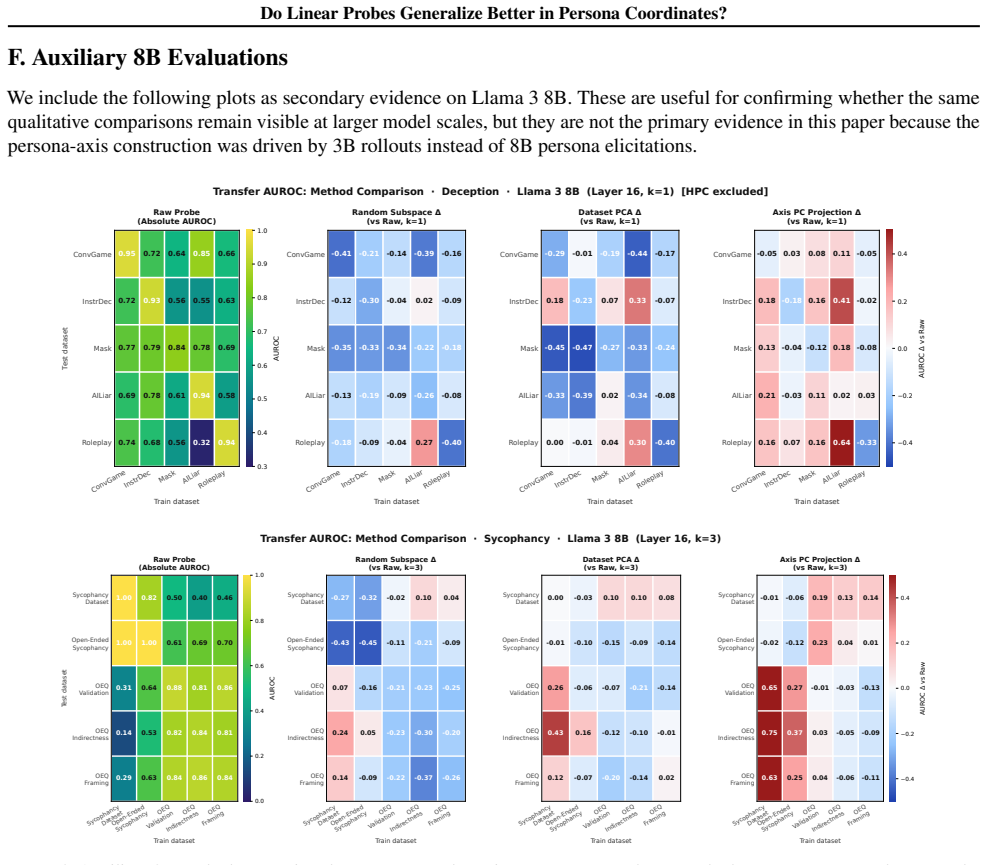
We construct persona axes for deception and sycophancy by using contrastive persona prompts to collect activation vectors, then apply unsupervised PCA to obtain first principal components that cleanly separate harmful and harmless personas. Probes trained on the persona-PC projections generalize better than probes trained on raw activations across ten evaluation datasets. A unified axis that combines multiple harmful and harmless behaviors further improves generalization across both behaviors and datasets, showing that persona vectors supply a useful inductive bias for transferable behavior probes.
What carries the argument
Persona principal component: the leading direction extracted by unsupervised PCA from activation vectors gathered via contrastive harmful-versus-harmless persona prompts, which isolates features relevant to harmful behavior.
If this is right
- Persona-derived directions transfer non-trivially to new evaluation datasets.
- Probes trained on persona-PC projections generalize better than those trained on raw activations.
- A unified axis spanning multiple harmful and harmless behaviors improves performance across behaviors and datasets.
- Persona vectors act as an inductive bias that supports more transferable internal monitors for model behavior.
Where Pith is reading between the lines
- If the result holds, safety monitoring systems could rely on a small set of precomputed axes instead of retraining probes for every new deployment scenario.
- The approach suggests harmful behaviors occupy consistent low-dimensional structures in activation space that unsupervised persona contrasts can locate.
- Similar persona-based axes might be tested on other alignment-relevant behaviors such as power-seeking or goal misgeneralization.
- Stability of these axes across model families or scales remains an open empirical question.
Load-bearing premise
The first principal component obtained by unsupervised PCA on persona-specific activation vectors cleanly isolates robust harmful-behavior features while excluding spurious correlations that break under distribution shift.
What would settle it
A new dataset with distribution shift on which probes trained on persona-PC projections show no improvement or worse performance than probes on raw activations would falsify the generalization claim.
Figures





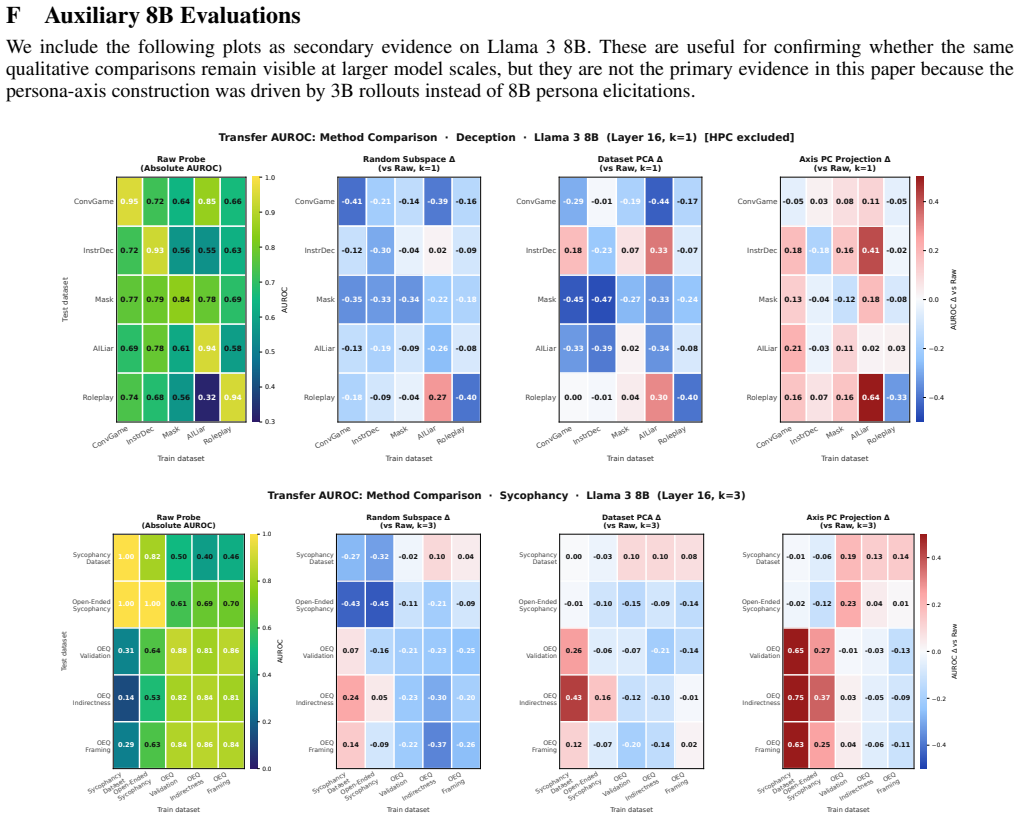

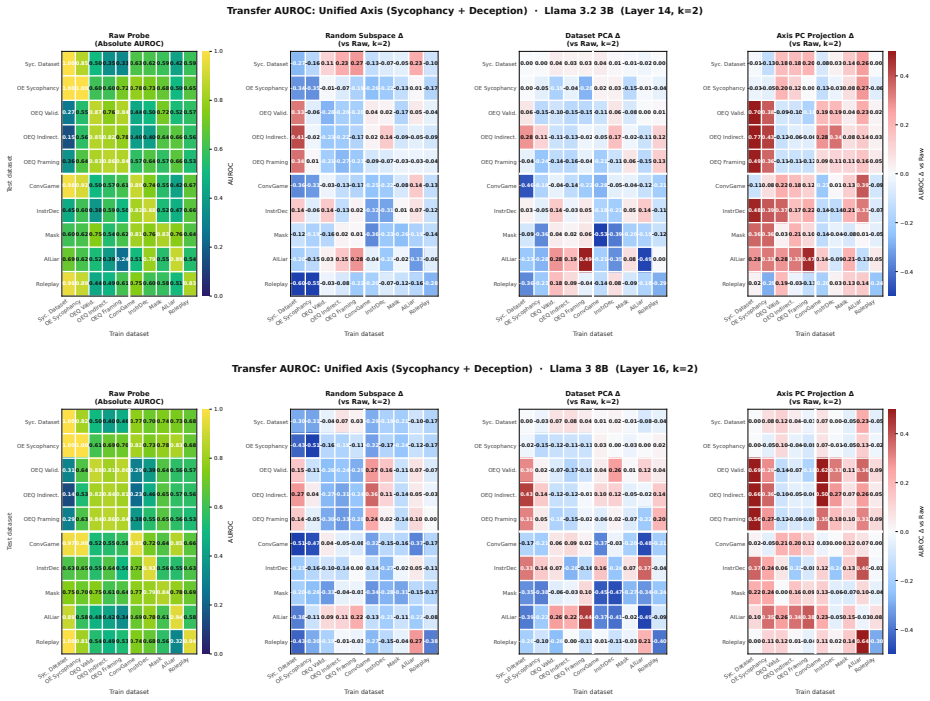

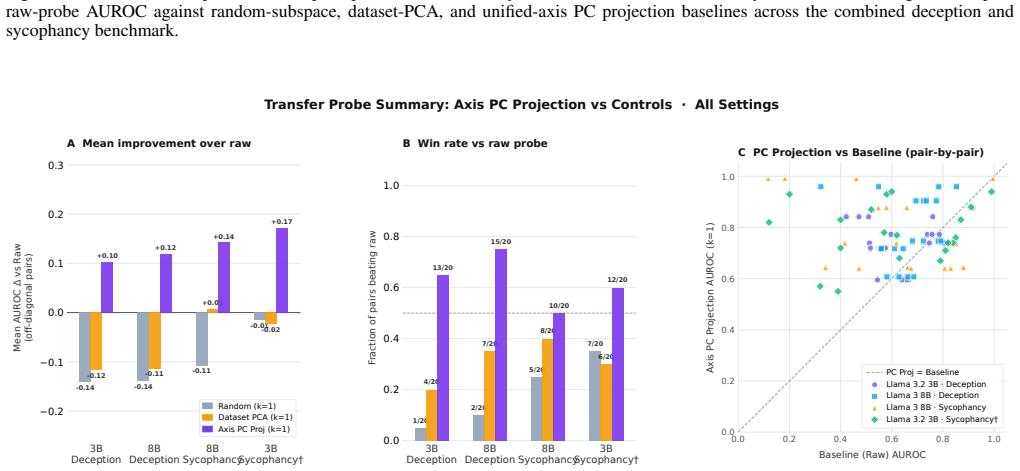
read the original abstract
It is becoming increasingly necessary to have monitors check for harmful behaviors during language model interactions, but text-only monitoring has not been sufficient. This is because models sometimes exhibit strategic deception and sandbagging, changing their behavior during evaluation. This motivates the use of white-box monitors like linear probes, which can read the model internals directly. Currently, such probes can fail under distribution shift, limiting their usefulness in real settings. We study whether there exists a low-dimensional subspace of the model internals that captures harmful behaviors more robustly, while leaving out spuriously correlative features. Inspired by the Assistant Axis and Persona Selection Model, we construct persona axes for deception and sycophancy using contrastive persona prompts. The first principal components, obtained by unsupervised PCA of the persona-specific vectors, cleanly separate harmful and harmless personas. Across 10 evaluation datasets, we show that persona-derived directions transfer non-trivially and probes trained on persona-PC projections generalize better than probes trained on raw activations. We also find that a unified axis consisting of multiple harmful and harmless behaviors improves generalization across behaviors and datasets. Overall, persona vectors provide a useful inductive bias for building more transferable behavior probes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that constructing persona axes for deception and sycophancy via contrastive persona prompts, followed by unsupervised PCA on the resulting activation vectors, yields first principal components that cleanly separate harmful and harmless behaviors. Linear probes trained on these 1D persona-PC projections generalize better than probes on raw high-dimensional activations across 10 evaluation datasets, and a unified multi-behavior axis further improves transfer.
Significance. If the central results hold after addressing controls, the work demonstrates that low-dimensional subspaces derived from persona contrasts can supply a useful inductive bias for more robust white-box monitors of harmful LLM behaviors under distribution shift. Credit is due for the multi-dataset evaluation (10 held-out sets) and the exploration of a unified axis combining multiple behaviors; these elements strengthen the case for practical applicability in scalable oversight.
major comments (2)
- [§4] §4 (results on generalization): The headline comparison of probes on 1D persona-PC projections versus full-dimensional raw activations does not include controls that hold dimensionality fixed (e.g., random 1D projections, PCA on neutral activations, or top-k PCs of the same persona vectors). This is load-bearing for the claim that persona coordinates provide a useful inductive bias, because any OOD accuracy gain could arise from implicit regularization of the 1D projection rather than isolation of robust harmful-behavior features.
- [§3.2] §3.2 (methods and data): The description of dataset splits, sample sizes per dataset, number of random seeds or runs, and statistical tests (e.g., confidence intervals or significance for the reported transfer improvements) is insufficient. Without these details it is impossible to determine whether the positive results across the 10 datasets are driven by post-hoc choices or dataset-specific effects.
minor comments (2)
- [Abstract] Abstract: The 10 evaluation datasets are referenced but not enumerated; adding a short list would improve immediate context for readers.
- [§3.1] Notation: The distinction between 'persona-PC projections' and the raw activation vectors could be clarified with an explicit equation or diagram showing the projection step.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The suggestions to strengthen controls and methodological transparency are well-taken and will improve the clarity and robustness of our claims. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [§4] §4 (results on generalization): The headline comparison of probes on 1D persona-PC projections versus full-dimensional raw activations does not include controls that hold dimensionality fixed (e.g., random 1D projections, PCA on neutral activations, or top-k PCs of the same persona vectors). This is load-bearing for the claim that persona coordinates provide a useful inductive bias, because any OOD accuracy gain could arise from implicit regularization of the 1D projection rather than isolation of robust harmful-behavior features.
Authors: We agree that dimensionality-matched controls are necessary to isolate whether the observed generalization gains stem from the specific features captured by persona contrasts rather than from the regularization effect of projecting to 1D. In the revised manuscript we will add three controls: (1) random 1D projections of the raw activations, (2) the first principal component obtained from PCA on activations collected from neutral (non-persona) prompts, and (3) the top-k principal components of the persona vectors themselves. These additions will be reported alongside the existing results in §4 so that readers can directly compare the persona-derived direction against both random and non-specific low-dimensional baselines. revision: yes
-
Referee: [§3.2] §3.2 (methods and data): The description of dataset splits, sample sizes per dataset, number of random seeds or runs, and statistical tests (e.g., confidence intervals or significance for the reported transfer improvements) is insufficient. Without these details it is impossible to determine whether the positive results across the 10 datasets are driven by post-hoc choices or dataset-specific effects.
Authors: We acknowledge that §3.2 currently omits several experimental details required for reproducibility and statistical assessment. In the revision we will expand this section to specify: the precise train/test splits and sample sizes for each of the 10 evaluation datasets; the number of random seeds used (we will average over five independent seeds and report standard deviations); and confidence intervals or standard errors for all reported accuracy differences. We will also state that dataset selection was performed prior to any probing experiments and that no post-hoc filtering of results occurred. revision: yes
Circularity Check
No significant circularity; empirical generalization tested on held-out data
full rationale
The paper constructs persona axes from contrastive prompts, applies unsupervised PCA to extract the first principal component of persona-specific activation vectors, and evaluates linear probes trained on the resulting 1D projections against probes on raw activations across 10 held-out datasets. The central claim of improved out-of-distribution generalization is an empirical measurement on external data and does not reduce to the construction by definition or via self-citation chains. No load-bearing steps equate predictions to fitted inputs or rename known results.
Axiom & Free-Parameter Ledger
free parameters (2)
- choice of contrastive persona prompts
- selection of model layers for activation extraction
axioms (1)
- domain assumption The first principal component of persona-specific activation differences isolates robust harmful-behavior features rather than dataset-specific artifacts.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We then run PCA on the centered persona vectors at each layer... PCk(z(ℓ)) = ⟨z(ℓ), u(ℓ)k⟩... probes trained on the projections onto persona PCs generalize better across datasets than probes trained on the raw activations.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The first principal components... cleanly separate harmful and harmless personas.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Stress Testing Deliberative Alignment for Anti-Scheming Training , url =
Schoen, Bronson and Nitishinskaya, Evgenia and Balesni, Mikita and Højmark, Axel and Hofstätter, Felix and Scheurer, Jérémy and Meinke, Alexander and Wolfe, Jason and Weij, Teun van der and Lloyd, Alex and Goldowsky-Dill, Nicholas and Fan, Angela and Matveiakin, Andrei and Shah, Rusheb and Williams, Marcus and Glaese, Amelia and Barak, Boaz and Zaremba, W...
-
[2]
Jiang, Albert Q. and Sablayrolles, Alexandre and Roux, Antoine and Mensch, Arthur and Savary, Blanche and Bamford, Chris and Chaplot, Devendra Singh and Casas, Diego de las and Hanna, Emma Bou and Bressand, Florian and Lengyel, Gianna and Bour, Guillaume and Lample, Guillaume and Lavaud, Lélio Renard and Saulnier, Lucile and Lachaux, Marie-Anne and Stock,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.04088 2024
-
[3]
Jiang, Albert Q. and Sablayrolles, Alexandre and Mensch, Arthur and Bamford, Chris and Chaplot, Devendra Singh and Casas, Diego de las and Bressand, Florian and Lengyel, Gianna and Lample, Guillaume and Saulnier, Lucile and Lavaud, Lélio Renard and Lachaux, Marie-Anne and Stock, Pierre and Scao, Teven Le and Lavril, Thibaut and Wang, Thomas and Lacroix, T...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06825 2023
-
[4]
2025 , eprinttype =. doi:10.48550/arXiv.2412.19437 , abstract =. 2412.19437 [cs] , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.19437 2025
-
[5]
Qwen and Yang, An and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Li, Chengyuan and Liu, Dayiheng and Huang, Fei and Wei, Haoran and Lin, Huan and Yang, Jian and Tu, Jianhong and Zhang, Jianwei and Yang, Jianxin and Yang, Jiaxi and Zhou, Jingren and Lin, Junyang and Dang, Kai and Lu, Keming and Bao, Keqin and Yang, Ke...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2025
-
[6]
Llama 3.2: Revolutionizing Edge AI and Vision (Connect 2024) , author =
work page 2024
-
[7]
Ministral-8B-Instruct-2410 Model Card , author =. 2024 , month = oct, url =
work page 2024
-
[8]
2025 , month = aug # " 13", url =
GPT-5 System Card , author =. 2025 , month = aug # " 13", url =
work page 2025
-
[9]
Hierarchical Neural Story Generation
Fan, Angela and Lewis, Mike and Dauphin, Yann , month = may, year =. Hierarchical. doi:10.48550/arXiv.1805.04833 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1805.04833
-
[10]
Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models,
Jiang, Liwei and Rao, Kavel and Han, Seungju and Ettinger, Allyson and Brahman, Faeze and Kumar, Sachin and Mireshghallah, Niloofar and Lu, Ximing and Sap, Maarten and Choi, Yejin and Dziri, Nouha , month = jun, year =. doi:10.48550/arXiv.2406.18510 , abstract =
-
[11]
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
Li, Nathaniel and Pan, Alexander and Gopal, Anjali and Yue, Summer and Berrios, Daniel and Gatti, Alice and Li, Justin D. and Dombrowski, Ann-Kathrin and Goel, Shashwat and Phan, Long and Mukobi, Gabriel and Helm-Burger, Nathan and Lababidi, Rassin and Justen, Lennart and Liu, Andrew B. and Chen, Michael and Barrass, Isabelle and Zhang, Oliver and Zhu, Xi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.03218
-
[12]
and Duvenaud, David , urldate =
Benton, Joe and Wagner, Misha and Christiansen, Eric and Anil, Cem and Perez, Ethan and Srivastav, Jai and Durmus, Esin and Ganguli, Deep and Kravec, Shauna and Shlegeris, Buck and Kaplan, Jared and Karnofsky, Holden and Hubinger, Evan and Grosse, Roger and Bowman, Samuel R. and Duvenaud, David , urldate =. Sabotage Evaluations for Frontier Models , url =...
-
[13]
What makes a convincing argument?
Habernal, Ivan and Gurevych, Iryna , year =. What makes a convincing argument?. Proceedings of the 2016
work page 2016
-
[15]
Kirch, Nathalie and Weisser, Constantin and Field, Severin and Yannakoudakis, Helen and Casper, Stephen , month = may, year =. What. doi:10.48550/arXiv.2411.03343 , abstract =
-
[16]
Jailbroken: How Does LLM Safety Training Fail?
Wei, Alexander and Haghtalab, Nika and Steinhardt, Jacob , month = jul, year =. Jailbroken:. doi:10.48550/arXiv.2307.02483 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.02483
-
[17]
Enhancing Chat Language Models by Scaling High-quality Instructional Conversations
Ding, Ning and Chen, Yulin and Xu, Bokai and Qin, Yujia and Zheng, Zhi and Hu, Shengding and Liu, Zhiyuan and Sun, Maosong and Zhou, Bowen , month = may, year =. Enhancing. doi:10.48550/arXiv.2305.14233 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.14233
-
[18]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Bai, Yuntao and Jones, Andy and Ndousse, Kamal and Askell, Amanda and Chen, Anna and DasSarma, Nova and Drain, Dawn and Fort, Stanislav and Ganguli, Deep and Henighan, Tom and Joseph, Nicholas and Kadavath, Saurav and Kernion, Jackson and Conerly, Tom and El-Showk, Sheer and Elhage, Nelson and Hatfield-Dodds, Zac and Hernandez, Danny and Hume, Tristan and...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2204.05862
-
[19]
Sharma, Mrinank and Tong, Meg and Mu, Jesse and Wei, Jerry and Kruthoff, Jorrit and Goodfriend, Scott and Ong, Euan and Peng, Alwin and Agarwal, Raj and Anil, Cem and Askell, Amanda and Bailey, Nathan and Benton, Joe and Bluemke, Emma and Bowman, Samuel R. and Christiansen, Eric and Cunningham, Hoagy and Dau, Andy and Gopal, Anjali and Gilson, Rob and Gra...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.18837
-
[20]
Bloom, Joseph and Taylor, Jordan and Kissane, Connor and Black, Sid and merizian and alexdzm and jacoba and Millwood, Ben and Cooney, Alan , month = jul, year =. White
-
[21]
Sharkey, Lee and Chughtai, Bilal and Batson, Joshua and Lindsey, Jack and Wu, Jeff and Bushnaq, Lucius and Goldowsky-Dill, Nicholas and Heimersheim, Stefan and Ortega, Alejandro and Bloom, Joseph and Biderman, Stella and Garriga-Alonso, Adria and Conmy, Arthur and Nanda, Neel and Rumbelow, Jessica and Wattenberg, Martin and Schoots, Nandi and Miller, Jose...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.16496
-
[22]
Language models learn to mislead humans via rlhf
Wen, Jiaxin and Zhong, Ruiqi and Khan, Akbir and Perez, Ethan and Steinhardt, Jacob and Huang, Minlie and Bowman, Samuel R. and He, He and Feng, Shi , month = dec, year =. Language. doi:10.48550/arXiv.2409.12822 , abstract =
-
[23]
Propositional interpretability in artificial intelligence
Chalmers, David J. , month = jan, year =. Propositional. doi:10.48550/arXiv.2501.15740 , abstract =
-
[24]
doi:10.48550/arXiv.2502.14744 , abstract =
Jiang, Yilei and Gao, Xinyan and Peng, Tianshuo and Tan, Yingshui and Zhu, Xiaoyong and Zheng, Bo and Yue, Xiangyu , month = jun, year =. doi:10.48550/arXiv.2502.14744 , abstract =
-
[25]
Parrack, Avi and Attubato, Carlo Leonardo and Heimersheim, Stefan , month = aug, year =. Benchmarking. doi:10.48550/arXiv.2507.12691 , abstract =
-
[26]
McKenzie, Alex and Pawar, Urja and Blandfort, Phil and Bankes, William and Krueger, David and Lubana, Ekdeep Singh and Krasheninnikov, Dmitrii , month = jun, year =. Detecting. doi:10.48550/arXiv.2506.10805 , abstract =
-
[27]
Investigating task-specific prompts and sparse autoencoders for activation monitoring , url =
Tillman, Henk and Mossing, Dan , month = apr, year =. Investigating task-specific prompts and sparse autoencoders for activation monitoring , url =. doi:10.48550/arXiv.2504.20271 , abstract =
-
[28]
Chan, Yik Siu and Yong, Zheng-Xin and Bach, Stephen H. , month = jul, year =. Can. doi:10.48550/arXiv.2507.12428 , abstract =
-
[29]
Nguyen, Jord and Hoang, Khiem and Attubato, Carlo Leonardo and Hofstätter, Felix , month = jul, year =. Probing and. doi:10.48550/arXiv.2507.01786 , abstract =
-
[30]
Feng, Jiahai and Russell, Stuart and Steinhardt, Jacob , month = dec, year =. Monitoring. doi:10.48550/arXiv.2406.19501 , abstract =
-
[32]
Simple probes can catch sleeper agents , url =
MacDiarmid, Monte and Maxwell, Timothy and Schiefer, Nicholas and Mu, Jesse and Kaplan, Jared and Duvenaud, David and Bowman, Sam and Tamkin, Alex and Perez, Ethan and Sharma, Mrinank and Denison, Carson and Hubinger, Evan , month = apr, year =. Simple probes can catch sleeper agents , url =
-
[33]
What makes a convincing argument?
Habernal, Ivan and Gurevych, Iryna , editor =. What makes a convincing argument?. Proceedings of the 2016. 2016 , pages =. doi:10.18653/v1/D16-1129 , urldate =
-
[34]
Measuring Massive Multitask Language Understanding
Hendrycks, Dan and Burns, Collin and Basart, Steven and Zou, Andy and Mazeika, Mantas and Song, Dawn and Steinhardt, Jacob , month = jan, year =. Measuring. doi:10.48550/arXiv.2009.03300 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2009.03300 2009
-
[35]
Representation Engineering: A Top-Down Approach to AI Transparency
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and Goel, Shashwat and Li, Nathaniel and Byun, Michael J. and Wang, Zifan and Mallen, Alex and Basart, Steven and Koyejo, Sanmi and Song, Dawn and Fredrikson, Matt and Kolter, J. ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.01405
-
[36]
Zhang, Jason and Viteri, Scott , month = mar, year =. Uncovering. doi:10.48550/arXiv.2409.14026 , abstract =
-
[37]
Abdelnabi, Sahar and Salem, Ahmed , month = may, year =. Linear. doi:10.48550/arXiv.2505.14617 , abstract =
-
[38]
Gu, Tianle and Huang, Kexin and Wang, Zongqi and Wang, Yixu and Li, Jie and Yao, Yuanqi and Yao, Yang and Yang, Yujiu and Teng, Yan and Wang, Yingchun , month = jun, year =. Probing the. doi:10.48550/arXiv.2506.16078 , abstract =
-
[39]
Towards Understanding Sycophancy in Language Models
Sharma, Mrinank and Tong, Meg and Korbak, Tomasz and Duvenaud, David and Askell, Amanda and Bowman, Samuel R. and Cheng, Newton and Durmus, Esin and Hatfield-Dodds, Zac and Johnston, Scott R. and Kravec, Shauna and Maxwell, Timothy and McCandlish, Sam and Ndousse, Kamal and Rausch, Oliver and Schiefer, Nicholas and Yan, Da and Zhang, Miranda and Perez, Et...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.13548
-
[40]
and Ward, Francis Rhys , month = feb, year =
Weij, Teun van der and Hofstätter, Felix and Jaffe, Ollie and Brown, Samuel F. and Ward, Francis Rhys , month = feb, year =. doi:10.48550/arXiv.2406.07358 , abstract =
-
[41]
Barkur, Sudarshan Kamath and Schacht, Sigurd and Scholl, Johannes , month = jan, year =. Deception in. doi:10.48550/arXiv.2501.16513 , abstract =
-
[42]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mazeika, Mantas and Phan, Long and Yin, Xuwang and Zou, Andy and Wang, Zifan and Mu, Norman and Sakhaee, Elham and Li, Nathaniel and Basart, Steven and Li, Bo and Forsyth, David and Hendrycks, Dan , month = feb, year =. doi:10.48550/arXiv.2402.04249 , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.04249
-
[43]
Lu, Christina and Gallagher, Jack and Michala, Jonathan and Fish, Kyle and Lindsey, Jack , month = jan, year =. The
-
[44]
Ying, Zhuofan Josh and Ravfogel, Shauli and Kriegeskorte, Nikolaus and Hase, Peter , month = feb, year =. The
-
[45]
Shafran, Or and Ronen, Shaked and Fahn, Omri and Ravfogel, Shauli and Geiger, Atticus and Geva, Mor , month = feb, year =. From
-
[46]
Bar-Shalom, Guy and Frasca, Fabrizio and Galron, Yaniv and Ziser, Yftah and Maron, Haggai , month = sep, year =. Beyond
-
[47]
The persona selection model , url =
- [48]
-
[49]
Understanding intermediate layers using linear classifier probes , author=. 2018 , eprint=
work page 2018
-
[50]
Constitutional Classifiers++: Efficient Production-Grade Defenses against Universal Jailbreaks , author=. 2026 , eprint=
work page 2026
-
[51]
Designing and Interpreting Probes with Control Tasks , author=. 2019 , eprint=
work page 2019
-
[52]
Emotion concepts and their function in a large language model , url =
-
[53]
Dong, Yurui and Jin, Luozhijie and Yang, Yao and Lu, Bingjie and Yang, Jiaxi and Liu, Zhi , month = feb, year =. Controllable
- [54]
-
[55]
Findings of the Association for Computational Linguistics: EMNLP 2022 , address =
Language Models as Agent Models , author =. Findings of the Association for Computational Linguistics: EMNLP 2022 , address =. 2022 , url =
work page 2022
-
[56]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , address =
Personas as a Way to Model Truthfulness in Language Models , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , address =. 2024 , url =
work page 2024
-
[57]
The Persona Selection Model: Why AI Assistants might Behave like Humans , url =
Marks, Samuel and Lindsey, Jack and Olah, Christopher , month = feb, year =. The Persona Selection Model: Why AI Assistants might Behave like Humans , url =
-
[58]
Proceedings of the 41st International Conference on Machine Learning , series =
The Linear Representation Hypothesis and the Geometry of Large Language Models , author =. Proceedings of the 41st International Conference on Machine Learning , series =. 2024 , url =
work page 2024
-
[59]
Findings of the Association for Computational Linguistics: EMNLP 2023 , publisher =
The Internal State of an LLM Knows When It's Lying , author =. Findings of the Association for Computational Linguistics: EMNLP 2023 , publisher =. 2023 , url =
work page 2023
-
[60]
The Eleventh International Conference on Learning Representations , year =
Discovering Latent Knowledge in Language Models Without Supervision , author =. The Eleventh International Conference on Learning Representations , year =
-
[61]
De- tecting strategic deception using linear probes.arXiv preprint arXiv:2502.03407, 2025
Goldowsky-Dill, Nicholas and Chughtai, Bilal and Heimersheim, Stefan and Hobbhahn, Marius , month = feb, year =. Detecting Strategic Deception Using Linear Probes , url =. doi:10.48550/arXiv.2502.03407 , publisher =
-
[62]
Building Better Deception Probes Using Targeted Instruction Pairs , url =
Natarajan, Vikram and Jain, Devina and Arora, Shivam and Golechha, Satvik and Bloom, Joseph , month = feb, year =. Building Better Deception Probes Using Targeted Instruction Pairs , url =. doi:10.48550/arXiv.2602.01425 , publisher =
-
[63]
The Twelfth International Conference on Learning Representations , year =
Towards Understanding Sycophancy in Language Models , author =. The Twelfth International Conference on Learning Representations , year =
-
[64]
Large Language Models can Strategically Deceive their Users when Put Under Pressure , url =
Scheurer, J. Large Language Models can Strategically Deceive their Users when Put Under Pressure , url =. 2024 , note =. doi:10.48550/arXiv.2311.07590 , publisher =
-
[65]
Emergent Misalignment: Narrow Finetuning Can Produce Broadly Misaligned
Betley, Jan and Tan, Daniel and Warncke, Niels and Sztyber-Betley, Anna and Bao, Xuchan and Soto, Mart. Emergent Misalignment: Narrow Finetuning Can Produce Broadly Misaligned. 2025 , eprint =
work page 2025
-
[66]
Pacchiardi, Lorenzo and Chan, Alex J. and Mindermann, S. How to Catch an. 2023 , eprint =
work page 2023
- [67]
-
[68]
Liars' Bench: Evaluating Lie Detectors for Language Models , author =. 2025 , eprint =
work page 2025
- [69]
- [70]
-
[71]
Steering Llama 2 via Contrastive Activation Addition , url =
Steering Llama 2 via Contrastive Activation Addition , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , address =. doi:10.18653/v1/2024.acl-long.828 , url =
-
[72]
ELEPHANT: Measuring and understanding social sycophancy in LLMs
Cheng, Myra and Yu, Sunny and Lee, Cinoo and Khadpe, Pranav and Ibrahim, Lujain and Jurafsky, Dan , year =. 2505.13995 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
The Impact of Off-Policy Training Data on Probe Generalisation , author=. 2026 , eprint=
work page 2026
-
[74]
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets , author =. 2023 , eprint =
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.