Recognition: 2 theorem links
· Lean TheoremDAP: Doppler-aware Point Network for Heterogeneous mmWave Action Recognition
Pith reviewed 2026-05-12 02:29 UTC · model grok-4.3
The pith
DAP-Net aligns mmWave radar point clouds across devices by treating Doppler patterns as invariant anchors and adding text-based semantic guidance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Leveraging action-consistent spatio-temporal Doppler patterns as anchors, the Dual-space Doppler Reparameterization (D2R) module performs sample-adaptive geometric densification and Doppler-guided feature recalibration, while the Text Alignment Module (TAM) provides stable semantic anchors via a pretrained textual space, enabling DAP-Net to learn source-invariant action semantics and achieve state-of-the-art accuracy with strong cross-source robustness on heterogeneous mmWave settings.
What carries the argument
Dual-space Doppler Reparameterization (D2R) module that uses spatio-temporal Doppler patterns for sample-adaptive geometric densification and feature recalibration, paired with the Text Alignment Module (TAM) that supplies semantic guidance from a pretrained textual space.
If this is right
- Point-cloud sparsity in mmWave data can be mitigated by reparameterizing geometry around Doppler signatures rather than raw spatial coordinates alone.
- Cross-modal alignment with pretrained text embeddings supplies semantic regularization that improves robustness when visual or radar features shift between sources.
- A single trained model can generalize across radar sources without requiring source-specific fine-tuning or large new labeled sets for each device.
- Standardized multi-source datasets like UniMM-HAR become necessary benchmarks for measuring real deployment robustness instead of single-device accuracy.
Where Pith is reading between the lines
- The same Doppler-anchor idea could transfer to other velocity-sensitive sensors such as lidar or acoustic arrays where motion signatures are more stable than raw spatial patterns.
- If text alignment proves reliable, the approach might support few-shot or zero-shot recognition of previously unseen action classes by relying on language descriptions rather than radar examples.
- Future data collection efforts should prioritize recording the same actions across multiple hardware variants early, because single-source scaling appears less effective for generalization.
Load-bearing premise
Spatio-temporal Doppler patterns remain consistent enough for the same human action no matter which radar device or frequency band records the data.
What would settle it
Collect a fresh set of action recordings with a fourth mmWave radar configuration whose frequency band and hardware lie outside the three used in UniMM-HAR; if accuracy on this held-out source drops sharply below the reported cross-source numbers, the invariance claim does not hold.
Figures









read the original abstract
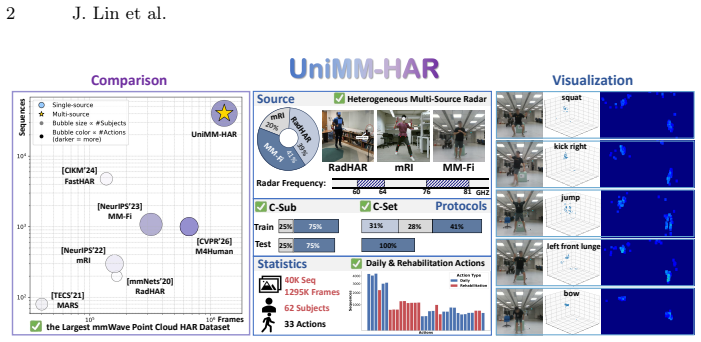
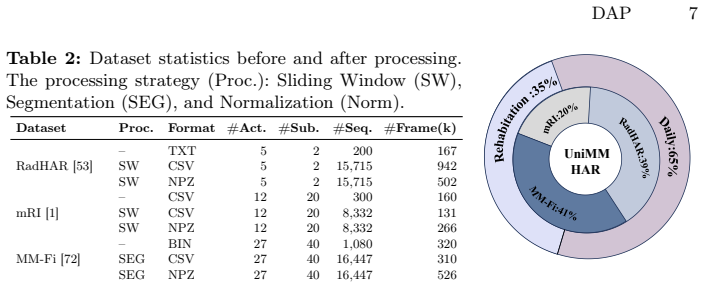
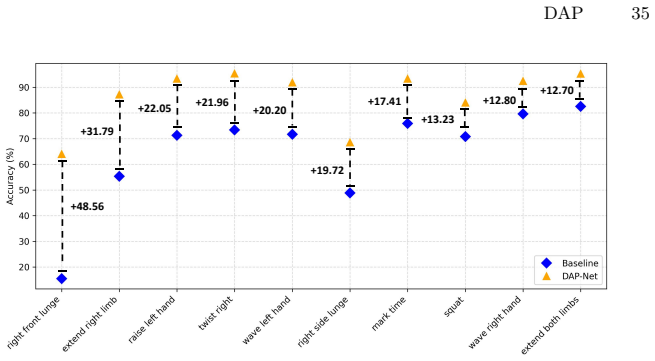
Millimeter-wave (mmWave) radar provides privacy-preserving sensing and is valuable for human action recognition (HAR). Existing mmWave point cloud datasets are limited in scale and mostly collected under homogeneous single-source settings, preventing current methods from handling real-world distribution shifts caused by heterogeneous radar sources, such as different devices and frequency bands. To address this, we introduce UniMM-HAR, the largest and first mmWave point cloud HAR dataset for heterogeneous multi-source scenarios, standardizing three distinct radar configurations to realistically evaluate cross-source generalization. We further propose the Doppler-aware Point Cloud Network (DAP-Net) to tackle heterogeneity challenges. DAP-Net enhances intra-modal representations and performs cross-modal alignment to learn source-invariant action semantics. Leveraging action-consistent spatio-temporal Doppler patterns as anchors, the Dual-space Doppler Reparameterization (D2R) module performs sample-adaptive geometric densification and Doppler-guided feature recalibration, while the Text Alignment Module (TAM) provides stable semantic anchors via a pretrained textual space. Experiments show that DAP-Net significantly outperforms existing methods under heterogeneous radar settings, achieving state-of-the-art accuracy and strong cross-source robustness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UniMM-HAR, the largest mmWave point cloud HAR dataset standardized across three heterogeneous radar configurations (different devices and frequency bands) to study cross-source distribution shifts, and proposes DAP-Net consisting of a Dual-space Doppler Reparameterization (D2R) module that uses action-consistent spatio-temporal Doppler patterns for sample-adaptive geometric densification and feature recalibration plus a Text Alignment Module (TAM) that leverages pretrained textual embeddings for semantic guidance, claiming that this yields state-of-the-art accuracy and strong cross-source robustness over existing methods.
Significance. If the empirical claims hold, the work would be significant for privacy-preserving mmWave sensing: the new multi-source dataset fills a clear gap left by prior homogeneous collections, and the architectural use of Doppler anchors plus textual semantics offers a concrete route to source-invariant representations. The dataset release itself would be a lasting contribution regardless of the precise performance numbers.
major comments (2)
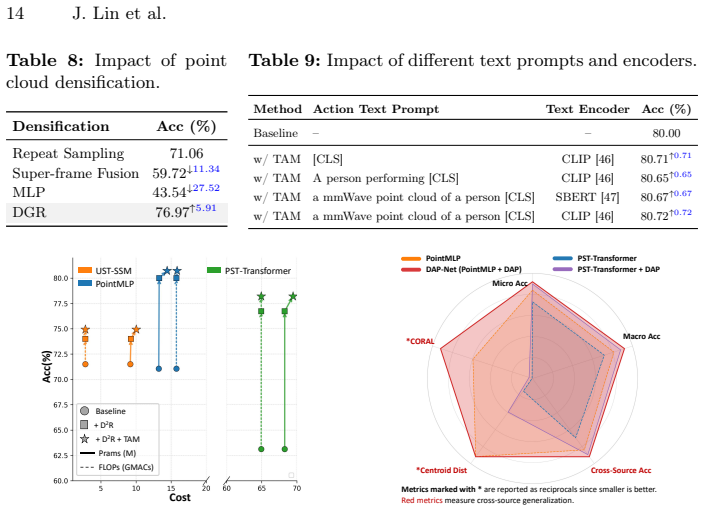
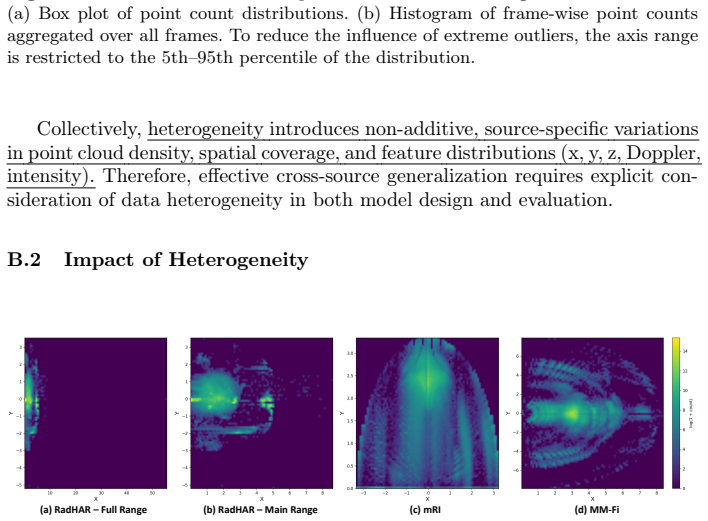
- [Section 3.2 (D2R module description)] The central cross-source robustness claim rests on the D2R module's premise that spatio-temporal Doppler patterns remain sufficiently action-consistent across the three radar configurations despite differences in velocity resolution, aliasing, and noise. No quantitative verification of this invariance (e.g., inter-source Doppler similarity scores, ablation on pattern distortion, or failure-case analysis) appears in the method or experiments sections; without it the sample-adaptive reparameterization risks becoming source-dependent rather than invariant.
- [Experiments section, Table 2] Table 2 (or equivalent results table) reports overall accuracy gains but does not include per-source breakdowns, statistical significance tests, or error bars for the cross-source splits; this makes it difficult to assess whether the claimed robustness is uniform or driven by a subset of easier source pairs.
minor comments (2)
- [Abstract] The abstract asserts SOTA performance without any numerical values or baseline names; moving one or two headline numbers into the abstract would improve readability.
- [Section 3.2] Notation for the Doppler reparameterization (e.g., the exact form of the sample-adaptive scaling in Eq. (X)) should be cross-referenced explicitly when first introduced in the text.
Simulated Author's Rebuttal
We sincerely thank the referee for the constructive and insightful comments, which help us strengthen the presentation of our cross-source robustness claims. We address each major comment point by point below and will incorporate the suggested additions in the revised manuscript.
read point-by-point responses
-
Referee: [Section 3.2 (D2R module description)] The central cross-source robustness claim rests on the D2R module's premise that spatio-temporal Doppler patterns remain sufficiently action-consistent across the three radar configurations despite differences in velocity resolution, aliasing, and noise. No quantitative verification of this invariance (e.g., inter-source Doppler similarity scores, ablation on pattern distortion, or failure-case analysis) appears in the method or experiments sections; without it the sample-adaptive reparameterization risks becoming source-dependent rather than invariant.
Authors: We appreciate the referee's emphasis on this foundational assumption. The D2R module design in Section 3.2 is grounded in the physical property that Doppler velocity signatures for a given action remain largely consistent in their spatio-temporal structure across radar configurations, even as absolute velocity resolution and aliasing vary; this is why we use them as anchors for sample-adaptive densification and recalibration. However, we agree that the current manuscript lacks explicit quantitative verification of this invariance. In the revised version, we will add: (i) inter-source cosine similarity scores on normalized Doppler features for identical action classes, (ii) an ablation quantifying performance sensitivity to controlled Doppler pattern distortion, and (iii) a brief failure-case analysis highlighting source pairs where invariance is weakest. These additions will empirically substantiate the premise without altering the method itself. revision: yes
-
Referee: [Experiments section, Table 2] Table 2 (or equivalent results table) reports overall accuracy gains but does not include per-source breakdowns, statistical significance tests, or error bars for the cross-source splits; this makes it difficult to assess whether the claimed robustness is uniform or driven by a subset of easier source pairs.
Authors: We concur that the current Table 2 aggregates results in a manner that obscures per-pair variability. To enable a more rigorous evaluation of uniformity, the revised manuscript will expand the experimental results with a detailed per-source-pair accuracy table for all cross-source protocols. We will also report standard deviations as error bars from multiple independent runs (different random seeds) and include paired statistical significance tests (e.g., t-tests with p-values) against the strongest baselines. This will demonstrate whether gains are consistent across all source combinations or concentrated in particular pairs. revision: yes
Circularity Check
No circularity in architectural proposal or empirical claims
full rationale
The paper introduces UniMM-HAR dataset and DAP-Net architecture (with D2R module using Doppler patterns as anchors and TAM for textual alignment) as an empirical solution for heterogeneous mmWave HAR. No equations, derivations, or parameter-fitting steps are described that reduce any claimed prediction or result to the inputs by construction. Performance claims rest on experimental comparisons rather than self-referential math or load-bearing self-citations. The assumption of action-consistent Doppler patterns is a modeling premise, not a circular reduction, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An, S., Li, Y., Ogras, U.: mri: Multi-modal 3d human pose estimation dataset using mmwave, rgb-d, and inertial sensors. NeurIPS35, 27414–27426 (2022)
work page 2022
-
[2]
ACM Transactions on Embedded Computing Systems20(5s), 1–22 (2021)
An, S., Ogras, U.Y.: Mars: mmwave-based assistive rehabilitation system for smart healthcare. ACM Transactions on Embedded Computing Systems20(5s), 1–22 (2021)
work page 2021
- [3]
-
[4]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Bengio, Y., Léonard, N., Courville, A.: Estimating or propagating gradi- ents through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[5]
IEEE Transactions on Radar Systems2, 484–497 (2024)
Biswas, S., Manavi Alam, A., Gurbuz, A.C.: Hrspecnet: A deep learning-based high-resolution radar micro-doppler signature reconstruction for improved har clas- sification. IEEE Transactions on Radar Systems2, 484–497 (2024)
work page 2024
-
[6]
IEEE TPAMI 45(3), 3522–3538 (2022)
Bruce, X., Liu, Y., Zhang, X., Zhong, S.h., Chan, K.C.: Mmnet: A model-based multimodal network for human action recognition in rgb-d videos. IEEE TPAMI 45(3), 3522–3538 (2022)
work page 2022
- [7]
- [8]
- [9]
-
[10]
Courbariaux,M.,Hubara,I.,Soudry,D.,El-Yaniv,R.,Bengio,Y.:Binarizedneural networks: Training deep neural networks with weights and activations constrained to+ 1 or-1. arXiv preprint arXiv:1602.02830 (2016)
-
[11]
Cui, H., Zhong, S., Wu, J., Shen, Z., Dahnoun, N., Zhao, Y.: Milipoint: A point cloud dataset for mmwave radar. NeurIPS36, 62713–62726 (2023)
work page 2023
-
[12]
Applied Sciences14(16), 7253 (2024)
Dang, X., Fan, K., Li, F., Tang, Y., Gao, Y., Wang, Y.: Multi-person action recog- nition based on millimeter-wave radar point cloud. Applied Sciences14(16), 7253 (2024)
work page 2024
- [13]
- [14]
- [15]
-
[16]
IEEE TPAMI45(2), 2181–2192 (2022)
Fan, H., Yang, Y., Kankanhalli, M.: Point spatio-temporal transformer networks for point cloud video modeling. IEEE TPAMI45(2), 2181–2192 (2022)
work page 2022
-
[17]
Fan, J., Zhou, Y., Yang, Y., Cui, X., Zhang, J., Xie, L., Yang, J., Lu, C.X., Ding, F.: M4human: A large-scale multimodal mmwave radar benchmark for human mesh reconstruction. arXiv preprint arXiv:2512.12378 (2025)
- [18]
-
[19]
IEEE Sensors Letters3(12), 1–4 (2019) 16 J
Fhager, L.O., Heunisch, S., Dahlberg, H., Evertsson, A., Wernersson, L.E.: Pulsed millimeter wave radar for hand gesture sensing and classification. IEEE Sensors Letters3(12), 1–4 (2019) 16 J. Lin et al
work page 2019
-
[20]
In: Youth Academic Annual Conference of Chinese Association of Automation
Gao, G., Liu, Q., Wang, W., Yu, Z., Liu, X.: Human activity recognition based on 4d millimeter-wave radar. In: Youth Academic Annual Conference of Chinese Association of Automation. pp. 1822–1828. IEEE (2025)
work page 2025
-
[21]
arXiv preprint arXiv:2405.01882 (2024)
Gu, Z., He, X., Fang, G., Xu, C., Xia, F., Jia, W.: Millimeter wave radar- based human activity recognition for healthcare monitoring robot. arXiv preprint arXiv:2405.01882 (2024)
- [22]
- [23]
-
[24]
NeurIPS36, 58064– 58074 (2023)
Hor, S., Yang, S., Choi, J., Arbabian, A.: Mvdoppler: Unleashing the power of multi-view doppler for micromotion-based gait classification. NeurIPS36, 58064– 58074 (2023)
work page 2023
- [25]
- [26]
- [27]
- [28]
- [29]
-
[30]
Liu, J., Wang, X., Wang, C., Gao, Y., Liu, M.: Temporal decoupling graph convo- lutional network for skeleton-based gesture recognition. IEEE TMM26, 811–823 (2024)
work page 2024
- [31]
-
[32]
Liu, M., Liu, H., Chen, C.: Enhanced skeleton visualization for view invariant human action recognition. PR68, 346–362 (2017)
work page 2017
-
[33]
IEEE TPAMI48(3), 3726–3743 (2026)
Liu, M., Liu, J., Jiang, Y., He, B.: Heatmap pooling network for action recognition from rgb videos. IEEE TPAMI48(3), 3726–3743 (2026)
work page 2026
- [34]
-
[35]
Liu, Y., Wang, F., Wang, N., Zhang, Z.X.: Echoes beyond points: Unleashing the power of raw radar data in multi-modality fusion. NeurIPS36, 53964–53982 (2023)
work page 2023
-
[36]
IEEE Transactions on Mobile Computing23(5), 5479–5493 (2023)
Luo,F.,Khan,S.,Li,A.,Huang,Y.,Wu,K.:Edgeactnet:Edgeintelligence-enabled human activity recognition using radar point cloud. IEEE Transactions on Mobile Computing23(5), 5479–5493 (2023)
work page 2023
-
[37]
arXiv preprint arXiv:2202.07123 , year=
Ma, X., Qin, C., You, H., Ran, H., Fu, Y.: Rethinking network design and lo- cal geometry in point cloud: A simple residual mlp framework. arXiv preprint arXiv:2202.07123 (2022)
- [38]
- [39]
-
[40]
Palipana, S., Salami, D., Leiva, L.A., Sigg, S.: Pantomime: Mid-air gesture recog- nition with sparse millimeter-wave radar point clouds. IMWUT5(1), 1–27 (2021)
work page 2021
- [41]
-
[42]
Neural Networks108, 533–543 (2018)
Phan, A.V., Le Nguyen, M., Nguyen, Y.L.H., Bui, L.T.: Dgcnn: A convolutional neural network over large-scale labeled graphs. Neural Networks108, 533–543 (2018)
work page 2018
- [43]
- [44]
-
[45]
Qi, C.R., Yi, L., Su, H., Guibas, L.J.: Pointnet++: Deep hierarchical feature learn- ing on point sets in a metric space. NeurIPS30(2017)
work page 2017
- [46]
- [47]
-
[48]
IEEE Transactions on Mobile Computing22(8), 4946–4960 (2022)
Salami, D., Hasibi, R., Palipana, S., Popovski, P., Michoel, T., Sigg, S.: Tesla- rapture: A lightweight gesture recognition system from mmwave radar sparse point clouds. IEEE Transactions on Mobile Computing22(8), 4946–4960 (2022)
work page 2022
-
[49]
IEEE Transactions on Neu- ral Networks and Learning Systems34(11), 8418–8429 (2022)
Sengupta, A., Cao, S.: mmpose-nlp: A natural language processing approach to precise skeletal pose estimation using mmwave radars. IEEE Transactions on Neu- ral Networks and Learning Systems34(11), 8418–8429 (2022)
work page 2022
-
[50]
Seo, H.I., Bae, J.W., Seo, D.H.: Radar-based human activity recognition using adaptive range selection and deep neural network. IEEE Sensors Journal pp. 1–1 (2026)
work page 2026
- [52]
-
[53]
In: Pro- ceedings of the 3rd ACM Workshop on Millimeter-wave Networks and Sensing Systems
Singh, A.D., Sandha, S.S., Garcia, L., Srivastava, M.: Radhar: Human activity recognition from point clouds generated through a millimeter-wave radar. In: Pro- ceedings of the 3rd ACM Workshop on Millimeter-wave Networks and Sensing Systems. pp. 51–56 (2019)
work page 2019
-
[54]
Tan, T.H., Tian, J.H., Sharma, A.K., Liu, S.H., Huang, Y.F.: Human activity recognition based on deep learning and micro-doppler radar data. Sensors24(8) (2024)
work page 2024
-
[55]
Texas Instruments: IWR1443BOOST single-chip 77- and 79-ghz mmwave sensor evaluation module.https://www.ti.com/tool/IWR1443BOOST(2014), accessed: 2020-09-29
work page 2014
-
[56]
Texas Instruments: IWR6843 single-chip 60-ghz mmwave radar sensor.https: //www.ti.com/product/IWR6843(2019), accessed: 2020-09-29
work page 2019
- [57]
- [58]
-
[59]
In: International Conference on AI in Healthcare
Tunau, M., Zakka, V.G., Dai, Z.: Enhanced sparse point cloud data processing for privacy-aware human action recognition. In: International Conference on AI in Healthcare. pp. 142–155. Springer (2025)
work page 2025
- [60]
- [61]
-
[62]
Wang, S., Cao, D., Liu, R., Jiang, W., Yao, T., Lu, C.X.: Human parsing with joint learning for dynamic mmwave radar point cloud. IMWUT7(1), 1–22 (2023)
work page 2023
-
[63]
Wang, Y., Liu, H., Cui, K., Zhou, A., Li, W., Ma, H.: m-activity: Accurate and real-time human activity recognition via millimeter wave radar. In: ICASSP. pp. 8298–8302. IEEE (2021)
work page 2021
-
[64]
arXiv preprint arXiv:2503.02300 (2025)
Wu, R., Li, Z., Wang, J., Xu, X., Zheng, Z., Huang, K., Lu, G.: Diffusion-based mmwave radar point cloud enhancement driven by range images. arXiv preprint arXiv:2503.02300 (2025)
-
[65]
IEEE Transactions on Radar Systems4, 261–272 (2025)
Wu, Y., Fioranelli, F., Gao, C.: Radmamba: Efficient human activity recognition through a radar-based micro-doppler-oriented mamba state-space model. IEEE Transactions on Radar Systems4, 261–272 (2025)
work page 2025
-
[66]
IEEE Transactions on Mobile Computing 23(12), 10734–10751 (2024)
Xia, S., Chu, L., Pei, L., Yang, J., Yu, W., Qiu, R.C.: Timestamp-supervised wearable-based activity segmentation and recognition with contrastive learning and order-preserving optimal transport. IEEE Transactions on Mobile Computing 23(12), 10734–10751 (2024)
work page 2024
- [67]
-
[68]
Xu, R., Wang, X., Wang, T., Chen, Y., Pang, J., Lin, D.: Pointllm: Empowering largelanguagemodelstounderstandpointclouds.In:ECCV.pp.131–147.Springer (2024)
work page 2024
-
[69]
Xue, H., Ju, Y., Miao, C., Wang, Y., Wang, S., Zhang, A., Su, L.: mmmesh: Towards 3d real-time dynamic human mesh construction using millimeter-wave. In: MobiSys. pp. 269–282 (2021)
work page 2021
-
[70]
arXiv preprint arXiv:2511.08910 (2025)
Yan, J., Xu, C., Liu, D.: Og-pcl: Efficient sparse point cloud processing for human activity recognition. arXiv preprint arXiv:2511.08910 (2025)
- [71]
-
[72]
Yang, J., Huang, H., Zhou, Y., Chen, X., Xu, Y., Yuan, S., Zou, H., Lu, C.X., Xie, L.: Mm-fi: Multi-modal non-intrusive 4d human dataset for versatile wireless sensing. NeurIPS36, 18756–18768 (2023)
work page 2023
-
[73]
IEEE Systems Journal16(2), 3036–3047 (2022)
Yu, C., Xu, Z., Yan, K., Chien, Y.R., Fang, S.H., Wu, H.C.: Noninvasive human activity recognition using millimeter-wave radar. IEEE Systems Journal16(2), 3036–3047 (2022)
work page 2022
-
[74]
In: 2020 IEEE 91st Vehicular Technology Conference
Yu, J.T., Yen, L., Tseng, P.H.: mmwave radar-based hand gesture recognition using range-angle image. In: 2020 IEEE 91st Vehicular Technology Conference. pp. 1–5 (2020)
work page 2020
-
[75]
In: International Conference on Computer and Communications
Zeng, X., Shi, Y., Zhou, A.: Multi-har: Human activity recognition in multi-person scenes based on mmwave sensing. In: International Conference on Computer and Communications. pp. 1789–1793. IEEE (2022)
work page 2022
- [76]
-
[77]
IEEE Sensors Letters3(2), 1–4 (2018)
Zhang, R., Cao, S.: Real-time human motion behavior detection via cnn using mmwave radar. IEEE Sensors Letters3(2), 1–4 (2018)
work page 2018
-
[78]
Zhao, M., Tian, Y., Zhao, H., Alsheikh, M.A., Li, T., Hristov, R., Kabelac, Z., Katabi,D.,Torralba,A.:Rf-based3dskeletons.In:SIGCOMM.pp.267–281(2018)
work page 2018
-
[79]
IEEE Internet of Things Journal10(12), 10236–10249 (2023)
Zhao, P., Lu, C.X., Wang, B., Trigoni, N., Markham, A.: Cubelearn: End-to-end learning for human motion recognition from raw mmwave radar signals. IEEE Internet of Things Journal10(12), 10236–10249 (2023)
work page 2023
-
[80]
IEEE TPAMI45(4), 4396–4415 (2022)
Zhou, K., Liu, Z., Qiao, Y., Xiang, T., Loy, C.C.: Domain generalization: A survey. IEEE TPAMI45(4), 4396–4415 (2022)
work page 2022
-
[81]
Zhou, R., Li, S., Zhang, H., Liu, C., Sun, J.: mmmulti: Multi-person action recog- nition based on multi-task learning using millimeter waves. IMWUT9(2), 1–25 (2025) 20 J. Lin et al. Supplementary Material In this supplementary material, we provide a comprehensive overview of the UniMM-HAR dataset, an analysis of its heterogeneous multi-source characteris...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.