TIE: Time Interval Encoding for Video Generation over Events
Pith reviewed 2026-05-12 04:22 UTC · model grok-4.3
The pith
TIE encodes time as intervals rather than points inside diffusion transformers, allowing overlapping events to be represented natively in attention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Within RoPE-compatible bilinear attention, TIE is characterized by Temporal Integrability, which requires an event to aggregate positional evidence over its full duration, and Duration Invariance, which removes the trivial bias toward longer intervals. Under a uniform kernel this characterization yields an efficient closed-form sinc-based solution that preserves the standard attention interface and naturally attenuates boundary noise through interval integration.
What carries the argument
Time Interval Encoding (TIE), a plug-and-play generalization of rotary embeddings obtained from the pair of temporal integrability and duration invariance under a uniform kernel.
If this is right
- Diffusion transformers can now accept prompts that describe concurrent or extended actions without architectural changes.
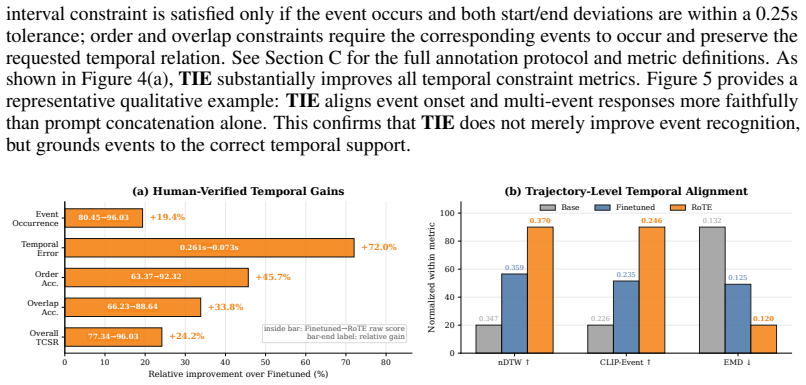
- Temporal boundary error drops from 0.261 s to 0.073 s on the OmniEvents dataset.
- Human-verified temporal constraint satisfaction rises from 77.34 % to 96.03 %.
- Trajectory-level alignment metrics improve while the base model’s visual quality is retained.
- The same attention interface remains unchanged, so TIE can be swapped in as a drop-in replacement.
Where Pith is reading between the lines
- The same interval-first logic could be tested in audio or text generation models that must handle overlapping sound events or narrative timelines.
- Robotics planners that output concurrent actions might benefit from replacing point-wise time encodings with TIE-style intervals.
- An ablation that replaces the uniform kernel with a learned kernel would show whether the closed-form sinc solution is optimal or merely convenient.
Load-bearing premise
The uniform kernel together with the two stated principles is enough to produce a general, artifact-free interval encoding that works across diverse video domains without further tuning.
What would settle it
A controlled evaluation on a held-out set of videos containing many overlapping events in which TIE either fails to raise temporal constraint satisfaction above the point-encoding baseline or introduces measurable drops in visual fidelity.
Figures







read the original abstract
Director-style prompting, robotic action prediction, and interactive video agents demand temporal grounding over concurrent events -- a regime in which 68% of general clips and over 99% of robotics/gameplay clips contain overlapping events, yet existing multi-event generators rest on a single-active-prompt assumption. However, modern video generators, such as Diffusion Transformers (DiT), represent time as discrete points through point-wise positional encodings. This formulation creates a fundamental dimension mismatch: temporally extended intervals and overlapping events are mathematically unrepresentable to the attention mechanism. In this paper, we propose Time Interval Encoding (TIE), a principled, plug-and-play interval-aware generalization of rotary embeddings that elevates time intervals to first-class primitives inside DiT cross-attention. Rather than introducing another heuristic interval embedding, we show that, within RoPE-compatible bilinear attention, TIE is characterized by two basic principles: Temporal Integrability, which requires an event to aggregate positional evidence over its full duration, and Duration Invariance, which removes the trivial bias toward longer intervals. Under a uniform kernel, this characterization yields an efficient closed-form sinc-based solution that preserves the standard attention interface and naturally attenuates boundary noise through interval integration. Empirically, TIE preserves the visual quality of the base DiT model while substantially improving temporal controllability. In our experiments on the OmniEvents dataset, it improves human-verified Temporal Constraint Satisfaction Rate from 77.34% to 96.03% and reduces temporal boundary error from 0.261s to 0.073s, while also improving trajectory-level temporal alignment metrics. The code and dataset are available at https://github.com/MatrixTeam-AI/TIE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Time Interval Encoding (TIE), a plug-and-play generalization of rotary embeddings (RoPE) for Diffusion Transformers (DiT) in video generation. It characterizes TIE via two principles—Temporal Integrability (aggregating positional evidence over an event's full duration) and Duration Invariance (removing bias toward longer intervals)—and derives a closed-form sinc-based encoding under a uniform kernel that integrates into standard bilinear attention while attenuating boundary noise. On the OmniEvents dataset, TIE raises human-verified Temporal Constraint Satisfaction Rate from 77.34% to 96.03%, reduces boundary error from 0.261s to 0.073s, and improves trajectory alignment metrics while preserving base-model visual quality; code and data are released.
Significance. If the central characterization holds, TIE supplies a principled, parameter-free interval primitive for attention-based video models, directly addressing the point-wise time representation mismatch that prevents native handling of overlapping events (common in 68%+ of clips). The open release of code and the OmniEvents dataset is a clear strength for reproducibility. The approach could meaningfully advance controllable generation for robotics, gameplay, and director-style prompting.
major comments (3)
- [§3] §3 (Method): The manuscript states that the two principles plus a uniform kernel yield the closed-form sinc TIE, but provides no comparative derivation or argument showing why the uniform kernel is the minimal or unique choice that satisfies Temporal Integrability and Duration Invariance without introducing domain-specific artifacts; alternatives (e.g., Gaussian or triangular kernels) are not examined.
- [§4] §4 (Experiments): All quantitative results and human evaluations are confined to the OmniEvents dataset; no cross-dataset tests, ablations on varying event densities, motion complexity, or frame rates are reported, leaving the claim of general, artifact-free generalization unsupported.
- [§3.3] §3.3 / Eq. (7)–(9): The claim that interval integration “naturally attenuates boundary noise” is asserted from the sinc form, yet no separate quantitative boundary-noise metric, ablation, or visualization isolates this effect from the overall TCS-rate and boundary-error gains.
minor comments (2)
- [Figures 3–4] Figure 3 and 4 captions should explicitly state the number of samples and the exact human-evaluation protocol (e.g., number of raters, inter-rater agreement) rather than referring only to “visual quality.”
- [Eq. (10)] Notation: the transition from the continuous integral form to the discrete sinc implementation in Eq. (10) would benefit from an explicit discretization step or reference to the sampling rate used.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment point-by-point below with clarifications and commitments to revisions that strengthen the manuscript without misrepresenting the current results.
read point-by-point responses
-
Referee: [§3] §3 (Method): The manuscript states that the two principles plus a uniform kernel yield the closed-form sinc TIE, but provides no comparative derivation or argument showing why the uniform kernel is the minimal or unique choice that satisfies Temporal Integrability and Duration Invariance without introducing domain-specific artifacts; alternatives (e.g., Gaussian or triangular kernels) are not examined.
Authors: The uniform kernel is the minimal choice that yields a parameter-free closed-form solution under the two principles: its constant weight allows direct integration over the interval to produce the sinc function while exactly satisfying Duration Invariance (normalization removes length bias) and Temporal Integrability (full-duration aggregation). Other kernels (Gaussian, triangular) would either require additional hyperparameters or lose the closed-form property, introducing artifacts or breaking RoPE compatibility. We will revise §3 to include an explicit derivation subsection showing this minimality and briefly contrast the uniform case with alternatives, noting that empirical comparison of kernels is reserved for future work given the computational cost of retraining DiT variants. revision: partial
-
Referee: [§4] §4 (Experiments): All quantitative results and human evaluations are confined to the OmniEvents dataset; no cross-dataset tests, ablations on varying event densities, motion complexity, or frame rates are reported, leaving the claim of general, artifact-free generalization unsupported.
Authors: OmniEvents was constructed precisely to isolate the multi-event temporal constraint problem that standard datasets do not emphasize. Because TIE is a plug-and-play replacement for positional encodings inside existing DiT attention, the architecture-level generalization argument holds, yet we agree broader empirical support is desirable. In the revision we will add qualitative results and limited quantitative checks on at least one additional public video dataset (e.g., a subset of WebVid or a robotics clip collection) together with an ablation on event density, to better substantiate the generalization claim. revision: yes
-
Referee: [§3.3] §3.3 / Eq. (7)–(9): The claim that interval integration “naturally attenuates boundary noise” is asserted from the sinc form, yet no separate quantitative boundary-noise metric, ablation, or visualization isolates this effect from the overall TCS-rate and boundary-error gains.
Authors: The reported boundary-error reduction (0.261 s → 0.073 s) and TCS improvement already reflect the net effect of interval integration. The sinc kernel’s low-pass character theoretically suppresses high-frequency boundary discontinuities; we will strengthen the presentation by adding a dedicated figure in §3.3 that visualizes per-boundary attention weights and error histograms with/without TIE, thereby isolating the attenuation mechanism from the aggregate metrics. revision: yes
Circularity Check
No circularity: derivation proceeds from stated principles plus kernel choice to closed-form solution without reduction to inputs.
full rationale
The paper states two principles (Temporal Integrability and Duration Invariance) that characterize TIE inside RoPE-compatible bilinear attention, then shows that a uniform kernel yields a closed-form sinc solution. This is a forward derivation from assumptions to result rather than any self-definition, fitted parameter renamed as prediction, or load-bearing self-citation. No equations or text in the abstract or described chain exhibit the specific reduction required to flag circularity. The uniform kernel is an explicit modeling choice whose consequences are derived, not smuggled in via prior self-work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Temporal Integrability: an event must aggregate positional evidence over its full duration
- domain assumption Duration Invariance: the encoding must remove trivial bias toward longer intervals
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Under a uniform kernel, this characterization yields an efficient closed-form sinc-based solution... Ai,c,r = sinc(θir) [cos(θic) −sin(θic); sin(θic) cos(θic)]
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Temporal Integrability... Duration Invariance... TIE(k, I) = 1/C(μ_I) E_τ∼μ_I [RoPE(k, τ)]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.