Recognition: no theorem link
LLM Jaggedness Unlocks Scientific Creativity
Pith reviewed 2026-05-12 04:03 UTC · model grok-4.3
The pith
Uneven capabilities across LLMs allow model combinations to generate more scientific ideas than any single model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLMs exhibit jaggedness in scientific creativity, with uneven performance across models, prompts, and scientific domains. By using inference-time compute, knowledge pooling, and brainstorming to build meta-model ensembles, these combinations outperform any individual model in generating unique and coherent scientific ideas, as measured by the total number of valid responses on SciAidanBench.
What carries the argument
The SciAidanBench benchmark, which counts the number of unique and coherent ideas generated for scientific questions, combined with ensemble construction methods using inference-time mechanisms to pool and brainstorm across models.
If this is right
- Model ensembles can cover a wider range of scientific subfields than any single model.
- Inference-time techniques like brainstorming allow leveraging complementary strengths without retraining.
- Jaggedness means that scaling a single model may not improve all areas equally, favoring diversity in model use.
- Scientific creativity benefits from diversity in capability profiles across providers.
Where Pith is reading between the lines
- This approach could be extended to other creative tasks beyond science, like engineering design or hypothesis formulation.
- It implies that future AI development might benefit from maintaining diversity in models rather than converging on uniform capabilities.
- Practitioners could use automated judgment to scale idea generation without always needing human review.
- The uneven profiles suggest training data diversity is key to unlocking ensemble gains.
Load-bearing premise
That counting unique coherent responses accurately measures scientific creativity and that judgments of validity have no systematic biases.
What would settle it
If a new experiment shows that a single advanced model generates as many or more valid ideas as the ensembles on a held-out set of scientific questions, or if the ensembles show no improvement over the best individual.
Figures





read the original abstract
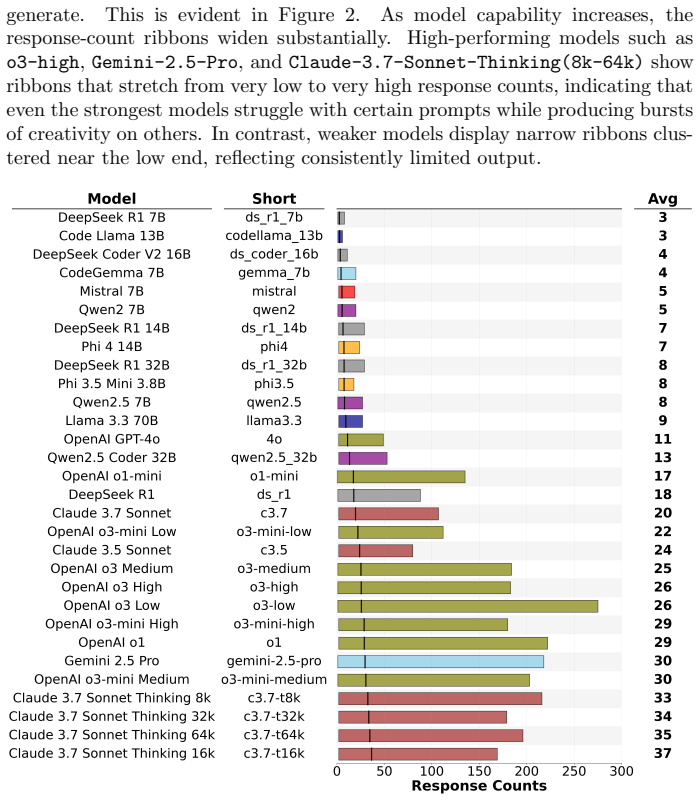
As artificial intelligence advances, models are not improving uniformly. Instead, progress unfolds in a jagged fashion, with capabilities growing unevenly across tasks, domains, and model scales. In this work, we examine this dynamic jaggedness through the lens of scientific idea generation. We introduce SciAidanBench, a benchmark of open-ended scientific questions designed to measure the scientific creativity of large language models (LLMs). Given a scientific question, models are asked to generate as many unique and coherent ideas as possible, with the total number of valid responses serving as a proxy for creative potential. Evaluating 19 base models across 8 providers (30 total variants including reasoning versions), we find that jaggedness manifests both across models and within models. First, in a cross-task comparison between general and scientific creativity, improvements in general creativity do not translate uniformly to scientific creativity, revealing divergent capability profiles across models. Second, at the prompt level, stronger models do not improve uniformly; instead, they exhibit high variability, with bursts of creativity on some questions and limited performance on others. Third, at the domain level, individual models display uneven strengths across scientific subfields, reflecting fragmented internal capability profiles. Finally, we show that this jaggedness can be harnessed. We explore mechanisms of inference-time compute, knowledge pooling, and brainstorming to combine models effectively and construct meta-model ensembles that outperform any single model. Our results position jaggedness not as a limitation, but as a resource, a structural feature of AI progress that, when understood and leveraged, can amplify LLM-driven scientific creativity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SciAidanBench, a benchmark of open-ended scientific questions on which LLMs are prompted to generate as many unique and coherent ideas as possible; the count of valid responses serves as the proxy for creative potential. It evaluates 19 base models (30 variants) and documents jaggedness in scientific creativity across general vs. scientific tasks, within-model prompt variability, and domain-level strengths. It then shows that inference-time compute, knowledge pooling, and brainstorming can be used to build meta-model ensembles that outperform any individual model on this metric.
Significance. If the count-based proxy for creativity is shown to align with expert-assessed novelty or downstream scientific value, the work would demonstrate that capability jaggedness is a usable resource rather than a flaw, offering concrete mechanisms to improve LLM-driven ideation beyond single-model scaling. The scale of the evaluation (19 models, multiple ensemble strategies) provides a useful empirical map of current model profiles.
major comments (2)
- [Abstract / SciAidanBench definition and evaluation protocol] The definition of creative potential as the total number of unique coherent responses (Abstract and SciAidanBench section) is load-bearing for all claims yet lacks any reported correlation to external anchors such as domain-expert ratings of novelty/feasibility, citation potential, or downstream experimental utility. Without such validation, both the jaggedness patterns and the ensemble gains remain difficult to interpret as evidence of amplified scientific creativity.
- [Ensemble mechanisms and results] The ensemble results (final section on meta-model construction) do not appear to control for total sample count or inference budget; reported gains could arise simply from the union of more independent generations rather than from complementary use of jagged capability profiles. A matched-budget ablation (e.g., single model with equivalent total generations) is needed to isolate the claimed benefit of combining models.
minor comments (2)
- [Abstract and Methods] The abstract states that 19 models were evaluated but provides no details on validity criteria for 'unique' and 'coherent,' whether judgments were automated or human, or inter-rater agreement statistics; these should be reported explicitly in the methods.
- [Results figures/tables] Figure or table captions for cross-model and cross-domain comparisons should include error bars or statistical tests for the reported variability to allow readers to assess the robustness of the jaggedness observations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on SciAidanBench and the ensemble results. The comments identify two substantive issues with our evaluation protocol and controls. We address each below and commit to targeted revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract / SciAidanBench definition and evaluation protocol] The definition of creative potential as the total number of unique coherent responses (Abstract and SciAidanBench section) is load-bearing for all claims yet lacks any reported correlation to external anchors such as domain-expert ratings of novelty/feasibility, citation potential, or downstream experimental utility. Without such validation, both the jaggedness patterns and the ensemble gains remain difficult to interpret as evidence of amplified scientific creativity.
Authors: We agree that the count-based proxy is central and that external validation would improve interpretability. The original manuscript presents the metric explicitly as a proxy and does not claim direct alignment with expert novelty ratings. In revision we will (1) add a dedicated paragraph in the SciAidanBench section justifying the proxy via prior computational-creativity literature, (2) include additional qualitative examples of high- and low-scoring outputs so readers can assess coherence and uniqueness directly, and (3) insert an explicit limitations statement noting the absence of expert correlation studies. These changes clarify the scope of our claims while remaining within the resource constraints of the current work. revision: partial
-
Referee: [Ensemble mechanisms and results] The ensemble results (final section on meta-model construction) do not appear to control for total sample count or inference budget; reported gains could arise simply from the union of more independent generations rather than from complementary use of jagged capability profiles. A matched-budget ablation (e.g., single model with equivalent total generations) is needed to isolate the claimed benefit of combining models.
Authors: The concern about confounding total generation volume with model complementarity is well-taken. Our reported ensembles combined a fixed set of models but did not include an explicit matched-budget comparison against single models given the same total number of generations. We will add this ablation to the revised manuscript: for each ensemble we will run the strongest single model with an equivalent total generation budget and report the resulting idea counts. This will allow readers to distinguish volume effects from the benefit of pooling across jagged capability profiles. revision: yes
Circularity Check
No significant circularity; empirical benchmark results are self-contained.
full rationale
The paper defines a proxy metric (count of unique coherent responses on SciAidanBench) for creative potential, uses it to quantify jaggedness across models/tasks/domains via direct evaluation of 19+ models, and reports that meta-ensembles yield higher counts on the same benchmark. This is a standard empirical workflow with no equations, no parameter fitting that is then relabeled as prediction, and no load-bearing self-citations or imported uniqueness theorems. The derivation chain consists of experimental measurements and comparisons rather than any definitional loop or reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Fabrizio Dell’Acqua, Edward McFowland III, Ethan R Mollick, Hila Lifshitz-Assaf, Katherine Kellogg, Saran Rajendran, Lisa Krayer, Fran¸ cois Candelon, and Karim R Lakhani. Navigating the jagged technological fron- tier: Field experimental evidence of the effects of ai on knowledge worker productivity and quality.Harvard Business School Technology & Opera-...
work page 2023
-
[2]
Inverse scaling: When bigger isn’t better.arXiv [cs.CL], June 2023
Ian R McKenzie, Alexander Lyzhov, Michael Pieler, Alicia Parrish, Aaron Mueller, Ameya Prabhu, Euan McLean, Aaron Kirtland, Alexis Ross, Alisa Liu, Andrew Gritsevskiy, Daniel Wurgaft, Derik Kauffman, Gabriel Rec- chia, Jiacheng Liu, Joe Cavanagh, Max Weiss, Sicong Huang, The Floating Droid, Tom Tseng, Tomasz Korbak, Xudong Shen, Yuhui Zhang, Zheng- ping Z...
work page 2023
-
[3]
Inverse scaling in test-time compute.arXiv [cs.AI], July 2025
Aryo Pradipta Gema, Alexander H¨ agele, Runjin Chen, Andy Arditi, Jacob Goldman-Wetzler, Kit Fraser-Taliente, Henry Sleight, Linda Petrini, Julian Michael, Beatrice Alex, Pasquale Minervini, Yanda Chen, Joe Benton, and Ethan Perez. Inverse scaling in test-time compute.arXiv [cs.AI], July 2025. 16
work page 2025
-
[4]
Parshin Shojaee, Iman Mirzadeh, Keivan Alizadeh, Maxwell Horton, Samy Bengio, and Mehrdad Farajtabar. The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity.arXiv [cs.AI], July 2025
work page 2025
-
[5]
Jiayi Zhang, Simon Yu, Derek Chong, Anthony Sicilia, Michael R Tomz, Christopher D Manning, and Weiyan Shi. Verbalized sampling: How to mitigate mode collapse and unlock LLM diversity.arXiv [cs.CL], October 2025
work page 2025
-
[6]
AidanBench: Evaluating novel idea generation on open-ended questions
Aidan McLaughlin, James Campbell, and Anuja Uppuluri. AidanBench: Evaluating novel idea generation on open-ended questions
-
[7]
Sciaidanbench: Evaluating llm scientific creativity
Shray Mathur, Noah van der Vleuten, J Anibal Boscoboinik, Esther Tsai, and Kevin Yager. Sciaidanbench: Evaluating llm scientific creativity. In New York Scientific Data Summit 2025: Powering the Future of Science with Artificial Intelligence, pages 25–28. SIAM, 2025
work page 2025
-
[8]
The AI scientist: Towards fully automated open-ended scientific discovery.arXiv [cs.AI], August 2024
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The AI scientist: Towards fully automated open-ended scientific discovery.arXiv [cs.AI], August 2024
work page 2024
-
[9]
ResearchTown: Simulator of human research community.arXiv [cs.CL], December 2024
Haofei Yu, Zhaochen Hong, Zirui Cheng, Kunlun Zhu, Keyang Xuan, Jinwei Yao, Tao Feng, and Jiaxuan You. ResearchTown: Simulator of human research community.arXiv [cs.CL], December 2024
work page 2024
-
[10]
Biqing Qi, Kaiyan Zhang, Kai Tian, Haoxiang Li, Zhang-Ren Chen, Sihang Zeng, Ermo Hua, Hu Jinfang, and Bowen Zhou. Large language models as biomedical hypothesis generators: A comprehensive evaluation.arXiv [cs.CL], July 2024
work page 2024
-
[11]
Towards a unified framework for reference retrieval and related work generation
Zhengliang Shi, Shen Gao, Zhen Zhang, Xiuying Chen, Zhumin Chen, Pengjie Ren, and Zhaochun Ren. Towards a unified framework for reference retrieval and related work generation. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 5785–5799, 2023
work page 2023
-
[12]
Chime: Llm-assisted hierarchical organization of scientific studies for literature review support
Chao-Chun Hsu, Erin Bransom, Jenna Sparks, Bailey Kuehl, Chenhao Tan, David Wadden, Lucy Lu Wang, and Aakanksha Naik. Chime: Llm-assisted hierarchical organization of scientific studies for literature review support. arXiv preprint arXiv:2407.16148, 2024
-
[13]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. Autogen: Enabling next-gen llm applications via multi-agent conversation framework. arXiv preprint arXiv:2308.08155, 3(4), 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Crispr-gpt: An llm agent for automated design of gene-editing experiments
Kaixuan Huang, Yuanhao Qu, Henry Cousins, William A Johnson, Di Yin, Mihir Shah, Denny Zhou, Russ Altman, Mengdi Wang, and Le Cong. Crispr-gpt: An llm agent for automated design of gene-editing experiments. arXiv preprint arXiv:2404.18021, 2024. 17
-
[15]
Shray Mathur, Noah van der Vleuten, Kevin G Yager, and Esther HR Tsai. Vision: a modular ai assistant for natural human-instrument interaction at scientific user facilities.Machine Learning: Science and Technology, 6(2): 025051, 2025
work page 2025
-
[16]
John Joon Young Chung, Vishakh Padmakumar, Melissa Roemmele, Yuqian Sun, and Max Kreminski. Modifying large language model post- training for diverse creative writing.arXiv preprint arXiv:2503.17126, 2025
-
[17]
arXiv preprint arXiv:2310.11667 , year=
Xuhui Zhou, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Yu, Zhengyang Qi, Louis-Philippe Morency, Yonatan Bisk, Daniel Fried, Gra- ham Neubig, et al. Sotopia: Interactive evaluation for social intelligence in language agents.arXiv preprint arXiv:2310.11667, 2023
-
[18]
Haw-Shiuan Chang, Nanyun Peng, Mohit Bansal, Anil Ramakrishna, and Tagyoung Chung. Real sampling: Boosting factuality and diversity of open- ended generation by extrapolating the entropy of an infinitely large lm. Transactions of the Association for Computational Linguistics, 13:760–783, 2025
work page 2025
-
[19]
Minh Nhat Nguyen, Andrew Baker, Clement Neo, Allen Roush, Andreas Kirsch, and Ravid Shwartz-Ziv. Turning up the heat: Min-p sampling for creative and coherent llm outputs.arXiv preprint arXiv:2407.01082, 2024
-
[20]
Haoyang Su, Renqi Chen, Shixiang Tang, Zhenfei Yin, Xinzhe Zheng, Jinzhe Li, Biqing Qi, Qi Wu, Hui Li, Wanli Ouyang, Philip Torr, Bowen Zhou, and Nanqing Dong. Many heads are better than one: Improved sci- entific idea generation by a LLM-based multi-agent system.arXiv [cs.AI], October 2024
work page 2024
-
[21]
Marissa Radensky, Simra Shahid, Raymond Fok, Pao Siangliulue, Tom Hope, and Daniel S Weld. Scideator: Human-LLM scientific idea generation grounded in research-paper facet recombination.arXiv [cs.HC], September 2024
work page 2024
-
[22]
Jinheon Baek, Sujay Kumar Jauhar, Silviu Cucerzan, and Sung Ju Hwang. ResearchAgent: Iterative research idea generation over scientific literature with large language models.arXiv [cs.CL], April 2024
work page 2024
-
[23]
Emergent Abilities of Large Language Models
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Met- zler, et al. Emergent abilities of large language models.arXiv preprint arXiv:2206.07682, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027, 2020. 18
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[25]
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Jour- nal of Machine Learning Research, 23(120):1–39, 2022
work page 2022
-
[26]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730– 27744, 2022
work page 2022
-
[27]
Lu Hong and Scott E Page. Groups of diverse problem solvers can outper- form groups of high-ability problem solvers.Proceedings of the National Academy of Sciences, 101(46):16385–16389, 2004
work page 2004
-
[28]
Improving factuality and reasoning in language models through multiagent debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. InForty-first international conference on machine learning, 2024
work page 2024
-
[29]
Encouraging divergent think- ing in large language models through multi-agent debate
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. Encouraging divergent think- ing in large language models through multi-agent debate. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 17889–17904, 2024
work page 2024
-
[30]
Generative monoculture in large language models.arXiv preprint arXiv:2407.02209, 2024
Fan Wu, Emily Black, and Varun Chandrasekaran. Generative monoculture in large language models.arXiv preprint arXiv:2407.02209, 2024
-
[31]
Addressing llm diversity by infusing random concepts.arXiv preprint arXiv:2601.18053, 2026
Pulin Agrawal and Prasoon Goyal. Addressing llm diversity by infusing random concepts.arXiv preprint arXiv:2601.18053, 2026
-
[32]
Multilingual prompting for improving llm generation diversity
Qihan Wang, Shidong Pan, Tal Linzen, and Emily Black. Multilingual prompting for improving llm generation diversity. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 6378–6400, 2025. 19 Supplementary Information for LLM Jaggedness Unlocks Scientific Creativity Shray Mathur, J. Anibal Boscoboinik, Esther H. R....
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.