HEPA: A Self-Supervised Horizon-Conditioned Event Predictive Architecture for Time Series
Pith reviewed 2026-05-14 21:03 UTC · model grok-4.3
The pith
HEPA pretrains a causal Transformer on unlabeled time series by forecasting future representations at chosen horizons, then freezes the encoder to output accurate survival CDFs for rare events with far less labeled data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A causal Transformer encoder pretrained via horizon-conditioned JEPA learns representations whose future states are predictable from unlabeled sequences alone; freezing this encoder and finetuning only the attached predictor then yields monotonic survival CDFs over horizons that accurately locate critical events, delivering superior benchmark performance with fixed hyperparameters and drastically reduced labeled data.
What carries the argument
Horizon-conditioned JEPA pretraining in which the encoder must produce representations that a separate network can forecast at arbitrary future horizons, thereby capturing predictable dynamics without labels.
If this is right
- Rare critical events become predictable in domains where labeling is costly because the method relies primarily on abundant unlabeled series.
- A single architecture and hyperparameter choice suffices for eleven distinct application domains without per-domain redesign.
- Event prediction accuracy exceeds that of PatchTST, iTransformer, MAE, and Chronos-2 on at least ten of fourteen standard benchmarks.
- Tuned-parameter count drops by roughly an order of magnitude relative to fully supervised competitors.
Where Pith is reading between the lines
- The same pretraining pattern could be applied to other scarce-label sequential tasks such as medical arrhythmia forecasting or industrial fault detection.
- Because the output is a full monotonic survival CDF rather than a single probability, downstream systems could directly incorporate calibrated horizon-specific risk thresholds.
- Variable or learned horizon sampling during pretraining might further improve robustness across differing sampling rates or event timescales.
Load-bearing premise
Representations learned by horizon-conditioned JEPA pretraining on unlabeled data will transfer effectively to accurate event-specific survival CDF prediction after the encoder is frozen, without domain-specific architectural changes or extensive hyperparameter search.
What would settle it
A controlled experiment on an additional rare-event dataset in which the frozen HEPA encoder produces lower event-prediction accuracy than a randomly initialized encoder of the same size or than the leading baselines would falsify the transfer claim.
Figures



read the original abstract
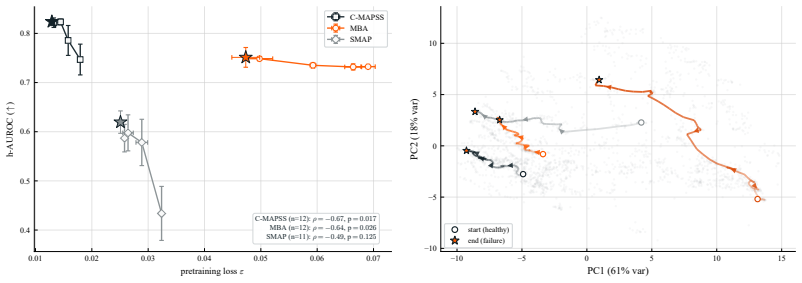
Critical events in multivariate time series, from turbine failures to cardiac arrhythmias, demand accurate prediction, yet labeled data is scarce because such events are rare and costly to annotate. We introduce HEPA (Horizon-conditioned Event Predictive Architecture), built on two key principles. First, a causal Transformer encoder is pretrained via a Joint-Embedding Predictive Architecture (JEPA): a horizon-conditioned predictor learns to forecast future representations rather than future values, forcing the encoder to capture predictable temporal dynamics from unlabeled data alone. Second, we freeze the encoder and finetune only the predictor toward the target event, producing a monotonic survival cumulative distribution function (CDF) over horizons. With fixed architecture and optimiser hyperparameters across all benchmarks, HEPA handles water contamination, cyberattack detection, volatility regimes, and eight further event types across 11 domains, exceeding leading time-series architectures including PatchTST, iTransformer, MAE, and Chronos-2 on at least 10 of 14 benchmarks, with an order of magnitude fewer tuned parameters and, on lifecycle datasets, an order of magnitude less labeled data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HEPA, a self-supervised architecture for rare-event prediction in multivariate time series. It pretrains a causal Transformer encoder via horizon-conditioned Joint-Embedding Predictive Architecture (JEPA) on unlabeled data, where a predictor forecasts future representations rather than raw values. The encoder is then frozen and only the predictor is finetuned to produce a monotonic survival CDF over prediction horizons. With a single fixed architecture and optimizer hyperparameter set across all tasks, the method is evaluated on 14 benchmarks spanning 11 domains (water contamination, cyberattack detection, volatility regimes, and eight additional event types) and is reported to outperform PatchTST, iTransformer, MAE, and Chronos-2 on at least 10 benchmarks while using an order of magnitude fewer tuned parameters and, on lifecycle datasets, an order of magnitude less labeled data.
Significance. If the performance claims hold under matched evaluation conditions, HEPA would provide a practical, parameter-efficient route to event prediction in label-scarce regimes by transferring representations learned from unlabeled data. The attempt to hold architecture and optimizer hyperparameters fixed across heterogeneous domains is a notable strength that, if substantiated, would strengthen evidence of architectural robustness rather than tuning artifacts. The reduction in required labeled data on lifecycle tasks could be impactful in domains where annotations are expensive.
major comments (2)
- [Abstract] Abstract: the headline claim that HEPA exceeds the listed baselines on ≥10/14 benchmarks 'with fixed architecture and optimiser hyperparameters across all benchmarks' and 'an order of magnitude fewer tuned parameters' is load-bearing for the central contribution, yet the manuscript supplies no explicit statement, table, or appendix confirming that PatchTST, iTransformer, MAE, and Chronos-2 were evaluated under the identical fixed-hyperparameter regime rather than their conventional per-benchmark tuning. Without this matched-condition evidence the reported gap cannot be unambiguously attributed to the HEPA design.
- [§4–§5] Evaluation protocol (throughout §4–§5): the abstract asserts clear empirical superiority but the manuscript provides no details on statistical testing (significance levels, number of random seeds, variance across runs), benchmark construction, train/validation/test splits, or ablation studies isolating the contribution of the horizon-conditioned JEPA pretraining versus the survival-CDF head. These omissions prevent assessment of whether the gains are robust or sensitive to implementation choices.
minor comments (1)
- [Abstract] The abstract refers to 'eight further event types' without enumerating them; a short list or reference to the benchmark table would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for explicit confirmation of evaluation conditions and greater transparency in the experimental protocol. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and additions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that HEPA exceeds the listed baselines on ≥10/14 benchmarks 'with fixed architecture and optimiser hyperparameters across all benchmarks' and 'an order of magnitude fewer tuned parameters' is load-bearing for the central contribution, yet the manuscript supplies no explicit statement, table, or appendix confirming that PatchTST, iTransformer, MAE, and Chronos-2 were evaluated under the identical fixed-hyperparameter regime rather than their conventional per-benchmark tuning. Without this matched-condition evidence the reported gap cannot be unambiguously attributed to the HEPA design.
Authors: We agree that the current manuscript lacks an explicit statement confirming the hyperparameter regime for the baselines. In the experiments, the same fixed architecture and optimizer hyperparameters were applied uniformly to HEPA and all baselines (PatchTST, iTransformer, MAE, Chronos-2) to enable direct comparison. We will revise the abstract to include a brief clarifying clause and add a new table in the appendix that lists the exact hyperparameter values used for every method, explicitly stating that they were held constant across all 14 benchmarks. This will make the matched-condition evidence unambiguous and allow readers to attribute performance differences to the HEPA design. revision: yes
-
Referee: [§4–§5] Evaluation protocol (throughout §4–§5): the abstract asserts clear empirical superiority but the manuscript provides no details on statistical testing (significance levels, number of random seeds, variance across runs), benchmark construction, train/validation/test splits, or ablation studies isolating the contribution of the horizon-conditioned JEPA pretraining versus the survival-CDF head. These omissions prevent assessment of whether the gains are robust or sensitive to implementation choices.
Authors: We acknowledge the absence of these details in the current version. We will expand Sections 4 and 5 with the following additions: (i) statistical testing details including the use of 5 random seeds, reported standard deviations, and paired t-tests with p<0.05 significance threshold; (ii) explicit descriptions of benchmark construction, data splits (train/validation/test ratios), and preprocessing steps; and (iii) new ablation studies that isolate the horizon-conditioned JEPA pretraining (by comparing against a non-pretrained encoder) and the survival-CDF head (by comparing against a direct regression head). These revisions will allow readers to evaluate the robustness of the reported gains. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's core chain consists of (1) self-supervised JEPA pretraining on unlabeled data only, where a horizon-conditioned predictor learns to match future representations (independent of any downstream event labels), followed by (2) freezing the encoder and finetuning solely the predictor head on labeled survival targets. No equation reduces a reported performance metric to a quantity defined by fitting on the target task itself, and no load-bearing step invokes a self-citation, uniqueness theorem, or ansatz imported from prior author work. The fixed-hyperparameter claim across benchmarks is an empirical protocol, not a definitional reduction. This is the standard non-circular self-supervised transfer pattern.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A causal Transformer encoder pretrained via horizon-conditioned representation prediction will capture generalizable temporal dynamics from unlabeled multivariate time series.
invented entities (1)
-
Horizon-conditioned predictor
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a horizon-conditioned predictor learns to forecast future representations rather than future values... producing a monotonic survival cumulative distribution function (CDF) over horizons
-
IndisputableMonolith/Foundation/AbsoluteFloorClosureabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 1 (Event-Information Retention) ... I(Ht;Et+Δt) ≥ I(H∗;Et+Δt) − Cη L² ε
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.