ReVision: Scaling Computer-Use Agents via Temporal Visual Redundancy Reduction
Pith reviewed 2026-05-14 20:52 UTC · model grok-4.3
The pith
ReVision removes redundant visual patches from agent history screenshots to cut token usage by 46 percent while raising success rates by 3 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
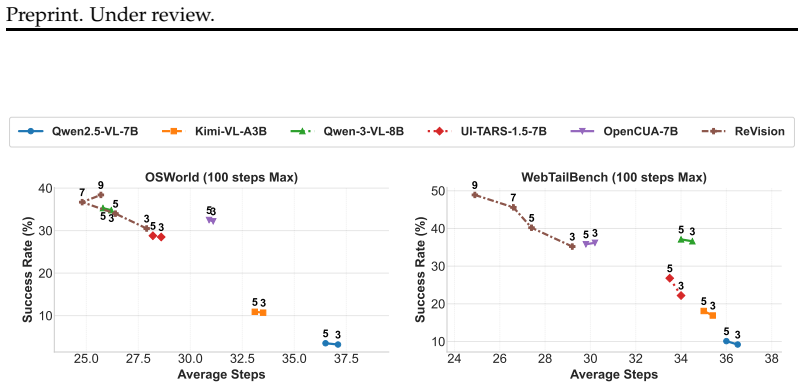
ReVision trains multimodal language models on trajectories where redundant visual patches are removed using a learned patch selector that compares patch representations across consecutive screenshots while preserving spatial structure required by the model. Across OSWorld, WebTailBench, and AgentNetBench, when processing trajectories with 5 history screenshots using Qwen2.5-VL-7B, ReVision reduces token usage by approximately 46% on average while improving success rate by 3% over the no drop baseline. This establishes a clear efficiency gain, enabling agents to process longer trajectories with fewer tokens. With this improved efficiency, performance continues to improve as more past visual-0
What carries the argument
a learned patch selector that compares patch representations across consecutive screenshots to drop redundant patches while preserving spatial structure
If this is right
- Agents can process longer trajectories without exceeding fixed token budgets.
- Performance improves steadily with added visual history once temporal redundancy is removed.
- The observed saturation with history in prior work stems from token inefficiency rather than lack of useful past information.
- The approach applies across OSWorld, WebTailBench, and AgentNetBench.
Where Pith is reading between the lines
- Similar patch-level redundancy reduction could extend to video-based agents in robotics or navigation.
- The method might combine with other compression techniques to scale context even further.
- Adaptive selection that also considers task relevance could yield larger gains than temporal comparison alone.
Load-bearing premise
The learned patch selector accurately identifies and removes only redundant patches without discarding task-critical visual information required for correct agent actions.
What would settle it
An experiment in which agents using the selected patches fail on tasks that succeed with the full set of patches, or in which adding more history after reduction produces no further performance gains.
Figures







read the original abstract
Computer-use agents (CUAs) rely on visual observations of graphical user interfaces, where each screenshot is encoded into a large number of visual tokens. As interaction trajectories grow, the token cost increases rapidly, limiting the amount of history that can be incorporated under fixed context and compute budgets. This has resulted in no or very limited improvement in the performance when using history unlike other domains. We address this inefficiency by introducing ReVision, which is used to train multimodal language models on trajectories where redundant visual patches are removed using a learned patch selector that compares patch representations across consecutive screenshots while preserving spatial structure required by the model. Across three benchmarks, OSWorld, WebTailBench, and AgentNetBench, when processing trajectories with 5 history screenshots using Qwen2.5-VL-7B, ReVision reduces token usage by 46% on average while improving success rate by 3% over the no drop baseline. This establishes a clear efficiency gain, enabling agents to process longer trajectories with fewer tokens. With this improved efficiency, we revisit the role of history in CUAs and find that performance continues to improve as more past observations are incorporated when redundancy is removed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReVision, a method that trains multimodal LLMs for computer-use agents by removing temporally redundant visual patches from sequences of history screenshots via a learned patch selector. The selector compares patch representations across consecutive frames while preserving spatial structure. On OSWorld, WebTailBench, and AgentNetBench, using Qwen2.5-VL-7B with 5 history screenshots, it reports ~46% average token reduction and a 3% success-rate improvement over a no-drop baseline. The work further claims that, once redundancy is removed, agent performance continues to scale with additional history observations, implying that prior saturation effects stem from token inefficiency rather than limited utility of past visual information.
Significance. If the empirical claims hold under closer scrutiny, the result directly addresses a core scaling bottleneck for visual history in computer-use agents, where token counts grow linearly with trajectory length. Demonstrating both substantial efficiency gains and a modest performance lift on three distinct benchmarks would support the broader hypothesis that history saturation is an artifact of representation rather than an inherent limit, potentially enabling longer-horizon agents within fixed context budgets.
major comments (3)
- [§4] §4 (Experiments): The headline 46% token reduction and 3% success lift are reported as aggregate figures without accompanying per-benchmark breakdowns, standard deviations across runs, or statistical significance tests (e.g., paired t-tests or bootstrap confidence intervals). This makes it impossible to determine whether the observed lift exceeds run-to-run variance or is driven by a subset of trajectories.
- [§3.2] §3.2 (Learned Patch Selector): The training objective and loss used to optimize the patch selector are not specified. Without an explicit term that penalizes removal of low-redundancy but high-action-value patches (e.g., transient UI state changes), it remains unclear whether the selector truly preserves task-critical information or merely reduces tokens in a manner correlated with the training distribution.
- [§4.3] §4.3 (Ablation and Analysis): No oracle ablation or per-trajectory inspection is provided that forces removal of ground-truth critical patches (identified via action relevance) and measures the resulting drop in success rate. Such a control is necessary to substantiate the claim that the selector removes only redundant content rather than discarding necessary visual signals.
minor comments (3)
- [Abstract] The abstract states concrete benchmark gains but does not cite the exact prior works that observed “no or very limited improvement” when adding history; adding 1–2 references would strengthen the motivation.
- [§3] Notation for the patch selector (e.g., how spatial structure is preserved after dropping) is introduced without an accompanying equation or diagram in the main text; a small illustrative figure would improve clarity.
- [Tables] Table captions should explicitly list the number of trajectories and random seeds used for each reported metric.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on our manuscript. We address each of the major concerns below and will revise the paper to incorporate the suggested improvements where appropriate.
read point-by-point responses
-
Referee: §4 (Experiments): The headline 46% token reduction and 3% success lift are reported as aggregate figures without accompanying per-benchmark breakdowns, standard deviations across runs, or statistical significance tests (e.g., paired t-tests or bootstrap confidence intervals). This makes it impossible to determine whether the observed lift exceeds run-to-run variance or is driven by a subset of trajectories.
Authors: We agree that disaggregated results and statistical analysis would improve clarity. In the revised manuscript, we will add per-benchmark tables showing token reduction and success rates, include standard deviations from multiple experimental runs, and report p-values from paired t-tests or bootstrap confidence intervals to demonstrate that the improvements are statistically significant. revision: yes
-
Referee: §3.2 (Learned Patch Selector): The training objective and loss used to optimize the patch selector are not specified. Without an explicit term that penalizes removal of low-redundancy but high-action-value patches (e.g., transient UI state changes), it remains unclear whether the selector truly preserves task-critical information or merely reduces tokens in a manner correlated with the training distribution.
Authors: The patch selector is trained using a composite loss consisting of a temporal redundancy term (measuring similarity between patch embeddings across consecutive frames) and a task-specific term that encourages preservation of patches relevant to the agent's action prediction. This is achieved by backpropagating through the agent's success on the trajectories. We will explicitly detail this objective and the loss formulation in the revised §3.2. The end-to-end training with agent performance serves as the mechanism to avoid discarding high-value patches, as removing them would directly reduce success rates during training. revision: yes
-
Referee: §4.3 (Ablation and Analysis): No oracle ablation or per-trajectory inspection is provided that forces removal of ground-truth critical patches (identified via action relevance) and measures the resulting drop in success rate. Such a control is necessary to substantiate the claim that the selector removes only redundant content rather than discarding necessary visual signals.
Authors: We recognize the value of an oracle ablation study. However, constructing ground-truth critical patches would require additional human annotation or a separate model for action relevance, which was not feasible within the scope of this work. Our current evidence for preserving critical information includes the observed 3% success rate improvement over the no-drop baseline and the continued performance scaling with longer histories, which would be unlikely if essential visual signals were being removed. We will expand §4.3 with qualitative analysis of selected vs. dropped patches and discuss this limitation. revision: partial
Circularity Check
No significant circularity; empirical results on held-out benchmarks
full rationale
The paper introduces ReVision as a trained patch selector that removes redundant visual patches from screenshot trajectories while preserving spatial structure, then reports direct empirical measurements: ~46% average token reduction and +3% success rate on 5-history trajectories using Qwen2.5-VL-7B across OSWorld, WebTailBench, and AgentNetBench. These outcomes are obtained by training the selector and evaluating success rates on held-out benchmark trajectories; no equations reduce a claimed prediction to a fitted parameter by construction, no load-bearing self-citation chain justifies the core claim, and no ansatz or uniqueness theorem is smuggled in. The central efficiency gain is therefore a measured quantity rather than a tautological re-expression of the training objective.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal language models can learn to selectively attend to or drop visual patches based on cross-frame similarity comparisons.
invented entities (1)
-
learned patch selector
no independent evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.