Steer-to-Detect: Probing Hidden Representations for Detection of LLM-Generated Texts
Pith reviewed 2026-06-30 21:51 UTC · model grok-4.3
The pith
A learned steering vector injected into a frozen LLM's hidden states produces representations with better separation between human and machine text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Steer-to-Detect learns a steering vector from labeled examples and adds it to the hidden states of a frozen observer LLM, yielding representations in which human-written and LLM-generated texts exhibit improved class separability. A hypothesis test is then performed on the steered representations, and the procedure is accompanied by finite-sample high-probability guarantees on both Type I and Type II error rates.
What carries the argument
The steering vector, learned from data and added to the hidden states of an unchanged observer LLM to increase separability before hypothesis testing.
If this is right
- The hypothesis test on steered representations admits finite-sample high-probability bounds on Type I and Type II errors.
- Detection performance remains strong when test data are drawn from distributions different from the training data.
- The method continues to work under adversarial perturbations applied to the input text.
- The two-stage separation of learning the vector and performing the test allows the observer model to stay frozen throughout.
Where Pith is reading between the lines
- The same steering construction could be tried on tasks that distinguish outputs from different model families rather than human versus machine.
- If a low-dimensional direction consistently separates the two classes across many models, detectors might be updated by recomputing only the vector instead of retraining everything.
- One could measure whether the learned vector remains effective when the observer LLM is replaced by a model from a different scale or architecture family.
Load-bearing premise
A steering vector can be learned from data that meaningfully increases separability in the hidden representations of an unchanged observer LLM and that this increase transfers cleanly to the hypothesis test without introducing new biases.
What would settle it
If the steered hidden states on a held-out test set show no measurable reduction in class overlap relative to the unsteered states, or if the observed error rates exceed the stated finite-sample bounds.
Figures

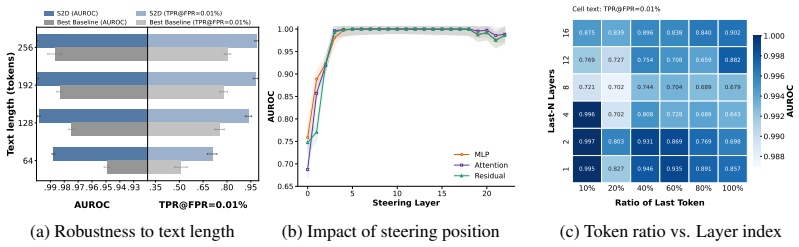
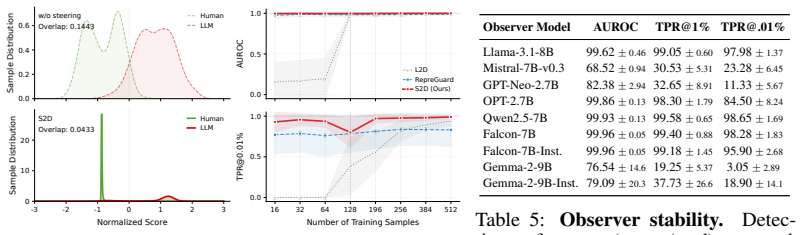


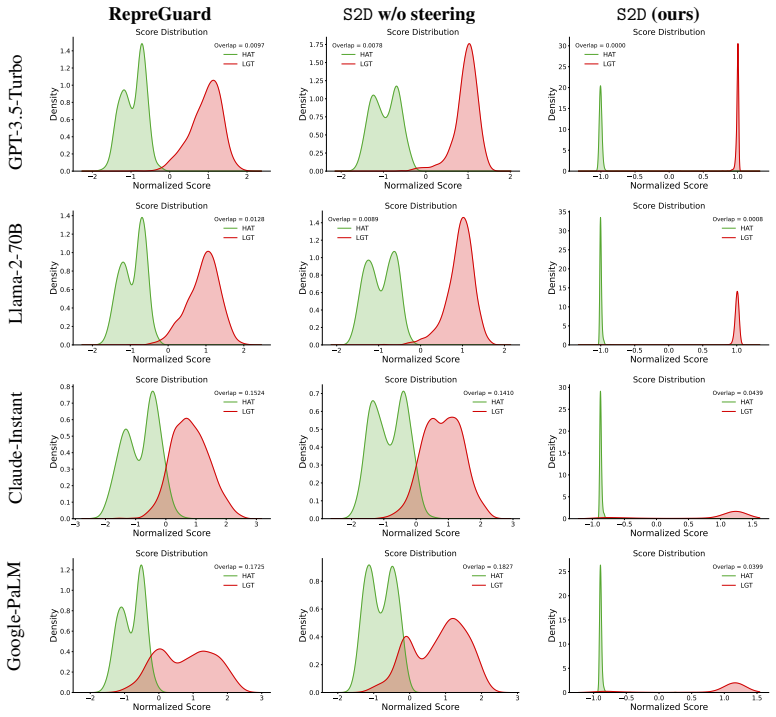

read the original abstract
The rapid advancement of large language models (LLMs) has made machine-generated text increasingly difficult to distinguish from human-written text. While recent studies explore leveraging internal representations of language models to uncover deeper detection signals, these raw features often exhibit substantial overlap between classes, limiting their discriminative power. To address this challenge, we propose Steer-to-Detect (\texttt{S2D}), a two-stage framework for detecting LLM-generated text. In the first stage, \texttt{S2D} learns a steering vector that is injected into the hidden states of a frozen observer LLM, producing representations with improved class separability. In the second stage, detection is performed via a hypothesis testing procedure based on the steered representations. We establish finite-sample, high-probability guarantees for Type I and Type II errors, providing a theoretical characterization of the procedure. Empirically, \texttt{S2D} achieves strong and consistent performance across a range of settings, including out-of-distribution scenarios and adversarial perturbations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Steer-to-Detect (S2D), a two-stage framework for detecting LLM-generated text. Stage 1 learns a steering vector that is injected into the hidden states of a frozen observer LLM to produce representations with improved class separability. Stage 2 performs detection via hypothesis testing on the steered representations and establishes finite-sample, high-probability guarantees on Type I and Type II errors. The work also reports strong empirical performance across in-distribution, out-of-distribution, and adversarial settings.
Significance. If the finite-sample guarantees can be shown to hold after properly accounting for the data-dependent steering vector, the work would supply a theoretically grounded method for enhancing separability in internal LLM representations without retraining the observer model. The combination of a learnable steering mechanism with explicit error bounds is a potentially useful contribution to the detection literature.
major comments (1)
- [Abstract] Abstract (and any theoretical section deriving the bounds): the finite-sample high-probability guarantees on Type I/II errors are stated for the steered representations, yet the steering vector is learned from finite data in stage 1. The provided description gives no indication that the analysis incorporates a union bound, concentration inequality, or strict train/test separation to control the dependence between the learned vector and the subsequent test statistic. If the proof treats the vector as fixed (oracle), the claimed guarantees do not automatically extend to the two-stage procedure.
minor comments (1)
- The abstract refers to 'out-of-distribution scenarios and adversarial perturbations' without naming the concrete datasets, perturbation methods, or evaluation metrics; these details are needed to assess the strength of the empirical claims.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying this subtlety in the theoretical analysis of the two-stage procedure. We address the point directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract (and any theoretical section deriving the bounds): the finite-sample high-probability guarantees on Type I/II errors are stated for the steered representations, yet the steering vector is learned from finite data in stage 1. The provided description gives no indication that the analysis incorporates a union bound, concentration inequality, or strict train/test separation to control the dependence between the learned vector and the subsequent test statistic. If the proof treats the vector as fixed (oracle), the claimed guarantees do not automatically extend to the two-stage procedure.
Authors: We agree that the stated finite-sample bounds are derived under the assumption that the steering vector is fixed once learned. The current theoretical section does not apply a union bound over the learning stage or provide an explicit concentration argument that would make the guarantees unconditional on the data used to obtain the vector. The manuscript therefore presents conditional guarantees given the learned vector rather than fully accounting for the dependence introduced by Stage 1. We will revise the abstract and the theoretical section to make this conditioning explicit, to clarify the role of the held-out test set used for detection, and to add a short discussion of the additional technical steps (e.g., a union bound or data-splitting argument) that would be required to obtain unconditional high-probability statements. These clarifications will be incorporated in the next version. revision: yes
Circularity Check
No circularity; two-stage procedure and guarantees are presented as independent
full rationale
The abstract describes a two-stage framework in which a steering vector is learned from data and injected into a frozen observer LLM, followed by a separate hypothesis-testing stage on the resulting representations. Finite-sample high-probability guarantees for Type I and Type II errors are stated as a theoretical characterization of the procedure. No equations, definitions, or self-citations are quoted that would reduce the guarantees to the learned vector by construction, treat a fitted quantity as a prediction, or rely on load-bearing self-citation chains. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- steering vector
axioms (1)
- domain assumption Hidden representations of an observer LLM contain class-separable signals for generated versus human text that can be enhanced by a linear steering vector.
Reference graph
Works this paper leans on
-
[1]
(A) I am not A lawyer, but...: engaging legal experts towards responsible LLM policies for legal advice
Inyoung Cheong, King Xia, KJ Kevin Feng, Quan Ze Chen, and Amy X Zhang. (A) I am not A lawyer, but...: engaging legal experts towards responsible LLM policies for legal advice. In Proceedings of the 2024 ACM conference on fairness, accountability, and transparency, pages 2454–2469, 2024
2024
-
[2]
FinLlama: LLM- based financial sentiment analysis for algorithmic trading
Giorgos Iacovides, Thanos Konstantinidis, Mingxue Xu, and Danilo Mandic. FinLlama: LLM- based financial sentiment analysis for algorithmic trading. InProceedings of the 5th ACM International Conference on AI in Finance, pages 134–141, 2024
2024
-
[3]
Delving into LLM-assisted writing in biomedical publications through excess vocabulary.Science Advances, 11(27):eadt3813, 2025
Dmitry Kobak, Rita González-Márquez, Em˝oke-Ágnes Horvát, and Jan Lause. Delving into LLM-assisted writing in biomedical publications through excess vocabulary.Science Advances, 11(27):eadt3813, 2025
2025
-
[4]
LLM-friendly knowledge representation for customer support
Hanchen Su, Wei Luo, Yashar Mehdad, Wei Han, Elaine Liu, Wayne Zhang, Mia Zhao, and Joy Zhang. LLM-friendly knowledge representation for customer support. InProceedings of the 31st International Conference on Computational Linguistics: Industry Track, pages 496–504, 2025
2025
-
[5]
A review of LLM agent applications in finance and banking
Devesh Batra, Conor Hamill, John Hartley, Ramin Okhrati, Dale Seddon, Harvey Miller, Raad Khraishi, and Greig Cowan. A review of LLM agent applications in finance and banking. Available at SSRN 5381584, 2025
2025
-
[6]
Do language models plagiarize? In Proceedings of the ACM Web Conference 2023, pages 3637–3647, 2023
Jooyoung Lee, Thai Le, Jinghui Chen, and Dongwon Lee. Do language models plagiarize? In Proceedings of the ACM Web Conference 2023, pages 3637–3647, 2023
2023
-
[7]
Evaluation of LLM vulnerabilities to being misused for personalized disinformation generation
Aneta Zugecova, Dominik Macko, Ivan Srba, Robert Moro, Jakub Kopál, Katarína Marcinˇci- nová, and Matúš Mesarˇcík. Evaluation of LLM vulnerabilities to being misused for personalized disinformation generation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 780–797, 2025
2025
-
[8]
Instructions as backdoors: Backdoor vulnerabilities of instruction tuning for large language models
Jiashu Xu, Mingyu Ma, Fei Wang, Chaowei Xiao, and Muhao Chen. Instructions as backdoors: Backdoor vulnerabilities of instruction tuning for large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 3111–3126, 2024
2024
-
[9]
Adversarial prompt and fine-tuning attacks threaten medical large language models.Nature Communications, 16(1):9011, 2025
Yifan Yang, Qiao Jin, Furong Huang, and Zhiyong Lu. Adversarial prompt and fine-tuning attacks threaten medical large language models.Nature Communications, 16(1):9011, 2025
2025
-
[10]
DetectGPT: Zero-shot machine-generated text detection using probability curvature
Eric Mitchell, Yoonho Lee, Alexander Khazatsky, Christopher D Manning, and Chelsea Finn. DetectGPT: Zero-shot machine-generated text detection using probability curvature. InInterna- tional conference on machine learning, pages 24950–24962. PMLR, 2023
2023
-
[11]
A watermark for large language models
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. A watermark for large language models. InInternational Conference on Machine Learning, pages 17061–17084. PMLR, 2023
2023
-
[12]
A statistical framework of watermarks for large language models: Pivot, detection efficiency and optimal rules.The Annals of Statistics, 53(1):322–351, 2025
Xiang Li, Feng Ruan, Huiyuan Wang, Qi Long, and Weijie J Su. A statistical framework of watermarks for large language models: Pivot, detection efficiency and optimal rules.The Annals of Statistics, 53(1):322–351, 2025
2025
-
[13]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to AI transparency.arXiv preprint arXiv:2310.01405, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Hadas Orgad, Michael Toker, Zorik Gekhman, Roi Reichart, Idan Szpektor, Hadas Kotek, and Yonatan Belinkov. LLMs know more than they show: On the intrinsic representation of LLM hallucinations.arXiv preprint arXiv:2410.02707, 2024
-
[15]
Inference- time intervention: Eliciting truthful answers from a language model.Advances in Neural Information Processing Systems, 36:41451–41530, 2023
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference- time intervention: Eliciting truthful answers from a language model.Advances in Neural Information Processing Systems, 36:41451–41530, 2023. 10
2023
-
[16]
Layer by Layer: Uncovering Hidden Representations in Language Models
Oscar Skean, Md Rifat Arefin, Dan Zhao, Niket Patel, Jalal Naghiyev, Yann LeCun, and Ravid Shwartz-Ziv. Layer by layer: Uncovering hidden representations in language models.arXiv preprint arXiv:2502.02013, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Steer LLM Latents for Hallucination Detection
Seongheon Park, Xuefeng Du, Min-Hsuan Yeh, Haobo Wang, and Yixuan Li. Steer LLM Latents for Hallucination Detection. InInternational Conference on Machine Learning, pages 47971–47990. PMLR, 2025
2025
-
[18]
Zero-shot detection of LLM-generated text via text reorder
Jingtao Sun and Zhanglong Lv. Zero-shot detection of LLM-generated text via text reorder. Neurocomputing, 631:129829, 2025
2025
-
[19]
DetectLLM: Leveraging log rank information for zero-shot detection of machine-generated text
Jinyan Su, Terry Zhuo, Di Wang, and Preslav Nakov. DetectLLM: Leveraging log rank information for zero-shot detection of machine-generated text. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 12395–12412, 2023
2023
-
[20]
Fast-DetectGPT: Efficient Zero-Shot Detection of Machine-Generated Text via Conditional Probability Curvature
Guangsheng Bao, Yanbin Zhao, Zhiyang Teng, Linyi Yang, and Yue Zhang. Fast-DetectGPT: Efficient Zero-Shot Detection of Machine-Generated Text via Conditional Probability Curvature. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[21]
Abhimanyu Hans, Avi Schwarzschild, Valeriia Cherepanova, Hamid Kazemi, Aniruddha Saha, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Spotting LLMs with binoculars: Zero-shot detection of machine-generated text.arXiv preprint arXiv:2401.12070, 2024
-
[22]
Raidar: generative AI detection via rewriting.arXiv preprint arXiv:2401.12970, 2024
Chengzhi Mao, Carl V ondrick, Hao Wang, and Junfeng Yang. Raidar: generative AI detection via rewriting.arXiv preprint arXiv:2401.12970, 2024
-
[23]
Hongyi Zhou, Jin Zhu, Erhan Xu, Kai Ye, Ying Yang, and Chengchun Shi. Learn-to-Distance: Distance Learning for Detecting LLM-Generated Text.arXiv preprint arXiv:2601.21895, 2026
-
[24]
Magret: Machine-generated text detection with rewritten texts
Yifei Huang, Jiuxin Cao, Hanyu Luo, Xin Guan, and Bo Liu. Magret: Machine-generated text detection with rewritten texts. InProceedings of the 31st International Conference on Computational Linguistics, pages 8336–8346, 2025
2025
-
[25]
Release Strategies and the Social Impacts of Language Models
Irene Solaiman, Miles Brundage, Jack Clark, Amanda Askell, Ariel Herbert-V oss, Jeff Wu, Alec Radford, Gretchen Krueger, Jong Wook Kim, Sarah Kreps, et al. Release strategies and the social impacts of language models.arXiv preprint arXiv:1908.09203, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[26]
Automatic detection of generated text is easiest when humans are fooled
Daphne Ippolito, Daniel Duckworth, Chris Callison-Burch, and Douglas Eck. Automatic detection of generated text is easiest when humans are fooled. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 1808–1822, 2020
2020
-
[27]
ChatGPT or human? Detect and explain
Sandra Mitrovi´c, Davide Andreoletti, and Omran Ayoub. ChatGPT or human? Detect and explain. Explaining decisions of machine learning model for detecting short ChatGPT-generated text.arXiv preprint arXiv:2301.13852, 2023
-
[28]
Hongyi Zhou, Jin Zhu, Pingfan Su, Kai Ye, Ying Yang, Shakeel AOB Gavioli-Akilagun, and Chengchun Shi. AdaDetectGPT: Adaptive detection of LLM-generated text with statistical guarantees.arXiv preprint arXiv:2510.01268, 2025
-
[29]
Watermarking for large language models: A survey.Mathematics, 13(9):1420, 2025
Zhiguang Yang, Gejian Zhao, and Hanzhou Wu. Watermarking for large language models: A survey.Mathematics, 13(9):1420, 2025
2025
-
[30]
Building intelligence identification system via large language model watermarking: a survey and beyond.Artificial Intelligence Review, 58(8):249, 2025
Xuhong Wang, Haoyu Jiang, Yi Yu, Jingru Yu, Yilun Lin, Ping Yi, Yingchun Wang, Yu Qiao, Li Li, and Fei-Yue Wang. Building intelligence identification system via large language model watermarking: a survey and beyond.Artificial Intelligence Review, 58(8):249, 2025
2025
-
[31]
Securing large language models: A survey of watermarking and fingerprinting techniques.ACM Computing Surveys, 58(7):1–35, 2026
Peigen Ye, Huali Ren, Zhengdao Li, Anli Yan, Hongyang Yan, Shaowei Wang, and Jin Li. Securing large language models: A survey of watermarking and fingerprinting techniques.ACM Computing Surveys, 58(7):1–35, 2026
2026
-
[32]
Text fluoroscopy: Detecting LLM-generated text through intrinsic features
Xiao Yu, Kejiang Chen, Qi Yang, Weiming Zhang, and Nenghai Yu. Text fluoroscopy: Detecting LLM-generated text through intrinsic features. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 15838–15846, 2024. 11
2024
-
[33]
Repreguard: Detecting LLM-generated text by revealing hidden representation patterns.Transactions of the Association for Computational Linguistics, 13:1812–1831, 2025
Xin Chen, Junchao Wu, Shu Yang, Runzhe Zhan, Zeyu Wu, Ziyang Luo, Di Wang, Min Yang, Lidia S Chao, and Derek F Wong. Repreguard: Detecting LLM-generated text by revealing hidden representation patterns.Transactions of the Association for Computational Linguistics, 13:1812–1831, 2025
2025
-
[34]
Analyzing individual neurons in pre-trained language models
Nadir Durrani, Hassan Sajjad, Fahim Dalvi, and Yonatan Belinkov. Analyzing individual neurons in pre-trained language models. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4865–4880, 2020
2020
-
[35]
Anna Hedström, Salim I Amoukou, Tom Bewley, Saumitra Mishra, and Manuela Veloso. To steer or not to steer? mechanistic error reduction with abstention for language models.arXiv preprint arXiv:2510.13290, 2025
-
[36]
Neurons in large language models: Dead, n-gram, positional
Elena V oita, Javier Ferrando, and Christoforos Nalmpantis. Neurons in large language models: Dead, n-gram, positional. InFindings of the Association for Computational Linguistics: ACL 2024, pages 1288–1301, 2024
2024
-
[37]
Patchscopes: a unifying framework for inspecting hidden representations of language models
Asma Ghandeharioun, Avi Caciularu, Adam Pearce, Lucas Dixon, and Mor Geva. Patchscopes: a unifying framework for inspecting hidden representations of language models. InProceedings of the 41st International Conference on Machine Learning, pages 15466–15490, 2024
2024
-
[38]
LayerNavigator: Finding promising intervention layers for efficient activation steering in large language models
Hao Sun, Huailiang Peng, Qiong Dai, Xu Bai, and Yanan Cao. LayerNavigator: Finding promising intervention layers for efficient activation steering in large language models. In Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id= wj4lM45xQR
2025
-
[39]
Activation Steering with a Feedback Controller
Dung V Nguyen, Hieu M Vu, Nhi Y Pham, Lei Zhang, and Tan M Nguyen. Activation steering with a feedback controller.arXiv preprint arXiv:2510.04309, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Spotlight your instructions: Instruction- following with dynamic attention steering
Praveen Venkateswaran and Danish Contractor. Spotlight your instructions: Instruction- following with dynamic attention steering. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3752–3770, 2026
2026
-
[41]
Toward universal steering and monitoring of AI models.Science, 391(6787):787–792, 2026
Daniel Beaglehole, Adityanarayanan Radhakrishnan, Enric Boix-Adsera, and Mikhail Belkin. Toward universal steering and monitoring of AI models.Science, 391(6787):787–792, 2026
2026
-
[42]
Parmida Davarmanesh, Ashia Wilson, and Adityanarayanan Radhakrishnan. Efficient and accurate steering of large language models through attention-guided feature learning.arXiv preprint arXiv:2602.00333, 2026
-
[43]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering.arXiv preprint arXiv:2308.10248, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
A unified understanding and evaluation of steering methods.arXiv preprint arXiv:2502.02716, 2025
Shawn Im and Sharon Li. A unified understanding and evaluation of steering methods.arXiv preprint arXiv:2502.02716, 2025
-
[45]
Steering llama 2 via contrastive activation addition
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Turner. Steering llama 2 via contrastive activation addition. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15504–15522, 2024
2024
-
[46]
SHARP: Steering hallucination in LVLMs via representation engineering
Junfei Wu, Yue Ding, Guofan Liu, Tianze Xia, Ziyue Huang, Dianbo Sui, Qiang Liu, Shu Wu, Liang Wang, and Tieniu Tan. SHARP: Steering hallucination in LVLMs via representation engineering. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 14357–14372, 2025
2025
-
[47]
Leheng Sheng, Changshuo Shen, Weixiang Zhao, Junfeng Fang, Xiaohao Liu, Zhenkai Liang, Xiang Wang, An Zhang, and Tat-Seng Chua. Alphasteer: Learning refusal steering with principled null-space constraint.arXiv preprint arXiv:2506.07022, 2025. 12
-
[48]
Xinchi Qiu, Lei Yu, Yuchen Zhang, Aobo Yang, Narine Kokhlikyan, Nicola Cancedda, Diego Garcia-Olano, et al. Hallucination reduction with casal: Contrastive activation steering for amortized learning.arXiv preprint arXiv:2510.02324, 2025
-
[49]
Steering evaluation-aware language models to act like they are deployed
Tim Tian Hua, Andrew Qin, Samuel Marks, and Neel Nanda. Steering evaluation-aware language models to act like they are deployed.arXiv preprint arXiv:2510.20487, 2025
-
[50]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Pico: Contrastive label disambiguation for partial label learning
Haobo Wang, Ruixuan Xiao, Yixuan Li, Lei Feng, Gang Niu, Gang Chen, and Junbo Zhao. Pico: Contrastive label disambiguation for partial label learning. InInternational conference on learning representations, 2021
2021
-
[54]
Springer, 2005
Erich Leo Lehmann and Joseph P Romano.Testing statistical hypotheses. Springer, 2005
2005
-
[55]
Youden index and optimal cut-point estimated from observations affected by a lower limit of detection
Marcus D Ruopp, Neil J Perkins, Brian W Whitcomb, and Enrique F Schisterman. Youden index and optimal cut-point estimated from observations affected by a lower limit of detection. Biometrical Journal: Journal of Mathematical Methods in Biosciences, 50(3):419–430, 2008
2008
-
[56]
Joint confidence region estimation for area under roc curve and youden index.Statistics in medicine, 33(6):985–1000, 2014
Jingjing Yin and Lili Tian. Joint confidence region estimation for area under roc curve and youden index.Statistics in medicine, 33(6):985–1000, 2014
2014
-
[57]
Classification accuracy and cut point selection.Statistics in medicine, 31(23): 2676–2686, 2012
Xinhua Liu. Classification accuracy and cut point selection.Statistics in medicine, 31(23): 2676–2686, 2012
2012
-
[58]
Minjia Mao, Dongjun Wei, Xiao Fang, and Michael Chau. A General Method for Detecting Information Generated by Large Language Models.arXiv preprint arXiv:2506.21589, 2025
-
[59]
Detecting LLM-Generated Text with Performance Guarantees.arXiv preprint arXiv:2601.06586, 2026
Hongyi Zhou, Jin Zhu, Ying Yang, and Chengchun Shi. Detecting LLM-Generated Text with Performance Guarantees.arXiv preprint arXiv:2601.06586, 2026
-
[60]
Shengchao Liu, Xiaoming Liu, Chengzhengxu Li, Zhaohan Zhang, Guoxin Ma, Yu Lan, and Shuai Xiao. MGT-Prism: Enhancing Domain Generalization for Machine-Generated Text Detection via Spectral Alignment.arXiv preprint arXiv:2508.13768, 2025
-
[61]
DetectRL: Benchmarking LLM-generated text detection in real-world scenarios.Advances in Neural Information Processing Systems, 37:100369–100401, 2024
Junchao Wu, Runzhe Zhan, Derek Wong, Shu Yang, Xinyi Yang, Yulin Yuan, and Lidia Chao. DetectRL: Benchmarking LLM-generated text detection in real-world scenarios.Advances in Neural Information Processing Systems, 37:100369–100401, 2024
2024
-
[62]
Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization
Shashi Narayan, Shay B Cohen, and Mirella Lapata. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 1797–1807, 2018
2018
-
[63]
Hierarchical neural story generation
Angela Fan, Mike Lewis, and Yann Dauphin. Hierarchical neural story generation. InProceed- ings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 889–898, 2018
2018
-
[64]
Character-level convolutional networks for text classification.Advances in Neural Information Processing Systems, 28, 2015
Xiang Zhang, Junbo Zhao, and Yann LeCun. Character-level convolutional networks for text classification.Advances in Neural Information Processing Systems, 28, 2015
2015
-
[65]
Introducing ChatGPT
OpenAI. Introducing ChatGPT. https://openai.com/index/chatgpt/, 2023. OpenAI Blog
2023
-
[66]
Releasing claude instant 1.2, 2023
Anthropic. Releasing claude instant 1.2, 2023. URL https://www.anthropic.com/news/ releasingclaude-instant-1-2. Anthropic Blog. 13
2023
-
[67]
Rohan Anil, Andrew M Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, et al. Palm 2 technical report. arXiv preprint arXiv:2305.10403, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[68]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open Foundation and Fine-Tuned Chat Models.arXiv preprint arXiv:2307.09288, 2023. URL https://arxiv.org/abs/2307.09288
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[69]
GLTR: Statistical detection and visualization of generated text
Sebastian Gehrmann, Hendrik Strobelt, and Alexander M Rush. GLTR: Statistical detection and visualization of generated text. InProceedings of the 57th annual meeting of the association for computational linguistics: system demonstrations, pages 111–116, 2019
2019
-
[70]
Imitate before detect: Aligning machine stylistic preference for machine-revised text detection
Jiaqi Chen, Xiaoye Zhu, Tianyang Liu, Ying Chen, Chen Xinhui, Yiwen Yuan, Chak Tou Leong, Zuchao Li, Long Tang, Lei Zhang, et al. Imitate before detect: Aligning machine stylistic preference for machine-revised text detection. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 23559–23567, 2025
2025
-
[71]
Watermarking of large language models
Scott Aaronson and H Kirchner. Watermarking of large language models. InLarge language models and transformers workshop at Simons Institute for the Theory of Computing, volume 2023, 2023
2023
-
[72]
Scalable watermarking for identifying large language model outputs.Nature, 634(8035):818–823, 2024
Sumanth Dathathri, Abigail See, Sumedh Ghaisas, Po-Sen Huang, Rob McAdam, Johannes Welbl, Vandana Bachani, Alex Kaskasoli, Robert Stanforth, Tatiana Matejovicova, et al. Scalable watermarking for identifying large language model outputs.Nature, 634(8035):818–823, 2024
2024
-
[73]
Index for rating diagnostic tests.Cancer, 3(1):32–35, 1950
William J Youden. Index for rating diagnostic tests.Cancer, 3(1):32–35, 1950
1950
-
[74]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[75]
The tight constant in the Dvoretzky-Kiefer-Wolfowitz inequality.The Annals of Probability, pages 1269–1283, 1990
Pascal Massart. The tight constant in the Dvoretzky-Kiefer-Wolfowitz inequality.The Annals of Probability, pages 1269–1283, 1990
1990
-
[76]
Measuring mass concentrations and estimating density contour clusters-an excess mass approach.The annals of Statistics, pages 855–881, 1995
Wolfgang Polonik. Measuring mass concentrations and estimating density contour clusters-an excess mass approach.The annals of Statistics, pages 855–881, 1995
1995
-
[77]
Smooth discrimination analysis.The Annals of Statistics, 27(6):1808–1829, 1999
Enno Mammen and Alexandre B Tsybakov. Smooth discrimination analysis.The Annals of Statistics, 27(6):1808–1829, 1999
1999
-
[78]
A plug-in approach to neyman-pearson classification.Journal of Machine Learning Research, 14(1):3011–3040, 2013
Xin Tong. A plug-in approach to neyman-pearson classification.Journal of Machine Learning Research, 14(1):3011–3040, 2013
2013
-
[79]
On tail probabilities for martingales.the Annals of Probability, pages 100–118, 1975
David A Freedman. On tail probabilities for martingales.the Annals of Probability, pages 100–118, 1975. 14 A Algorithm Algorithm 1:Overall training pipeline forS2D Input: Frozen observer model fθ, training set Strain, null calibration set Scal (human-written text only); steering layer ℓs; vMF concentration parameter κ; EMA coefficient ρ; learning rate η; ...
1975
-
[80]
Substituting the vMF likelihood and the uniform prior gives p(yi |f θ,v(xi)) = Cd(κ) exp κµ⊤ yi fθ,v(xi) · 1 2P c∈{0,1} Cd(κ) exp (κµ⊤c fθ,v(xi))· 1 2
By Bayes’ theorem, p(yi |f θ,v(xi)) = p(fθ,v(xi)|y i)p(yi)P c∈{0,1} p(fθ,v(xi)|y i =c)p(y i =c) . Substituting the vMF likelihood and the uniform prior gives p(yi |f θ,v(xi)) = Cd(κ) exp κµ⊤ yi fθ,v(xi) · 1 2P c∈{0,1} Cd(κ) exp (κµ⊤c fθ,v(xi))· 1 2 . 15 Since Cd(κ) and the prior 1 2 are identical across classes, they cancel out, yielding the softmax form ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.