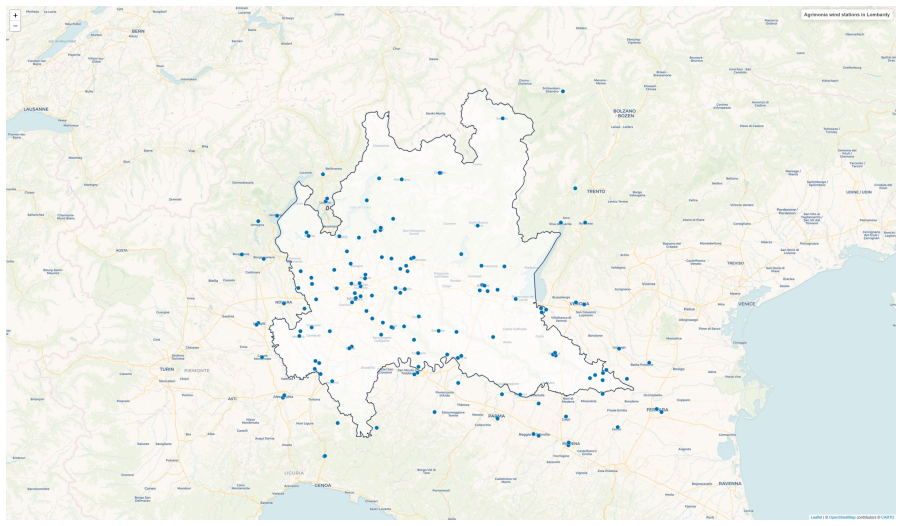
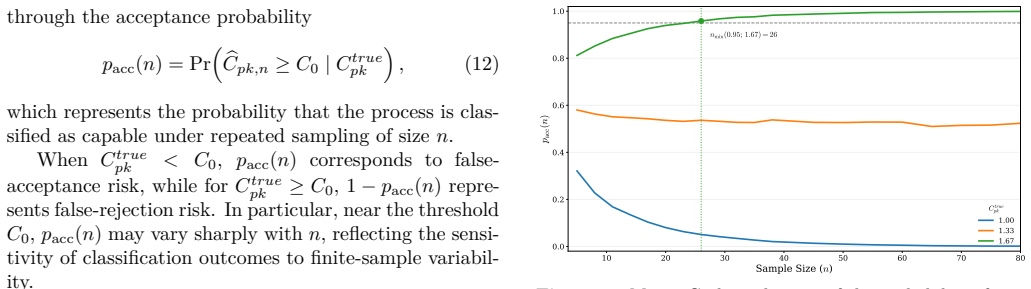
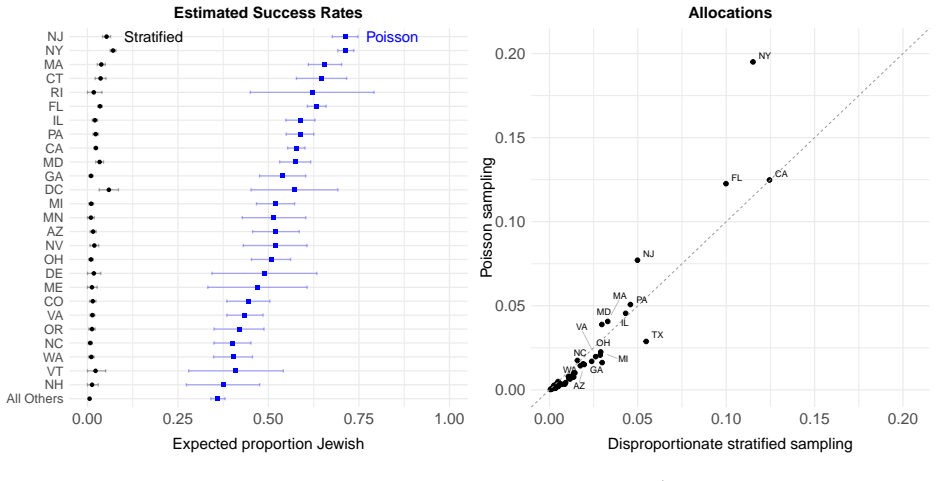
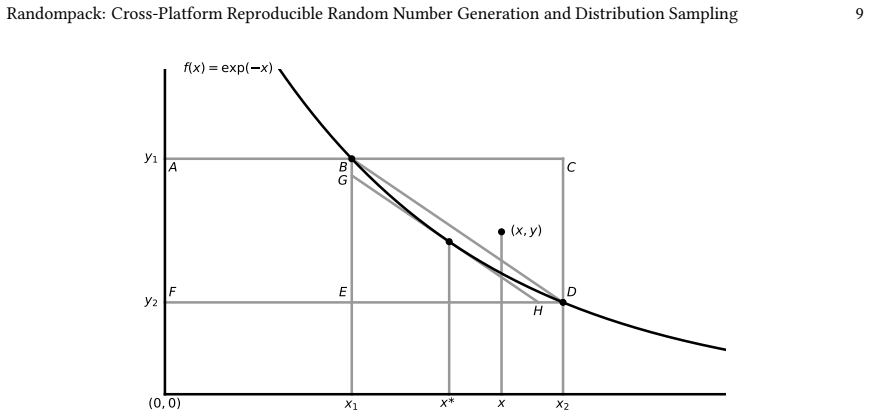
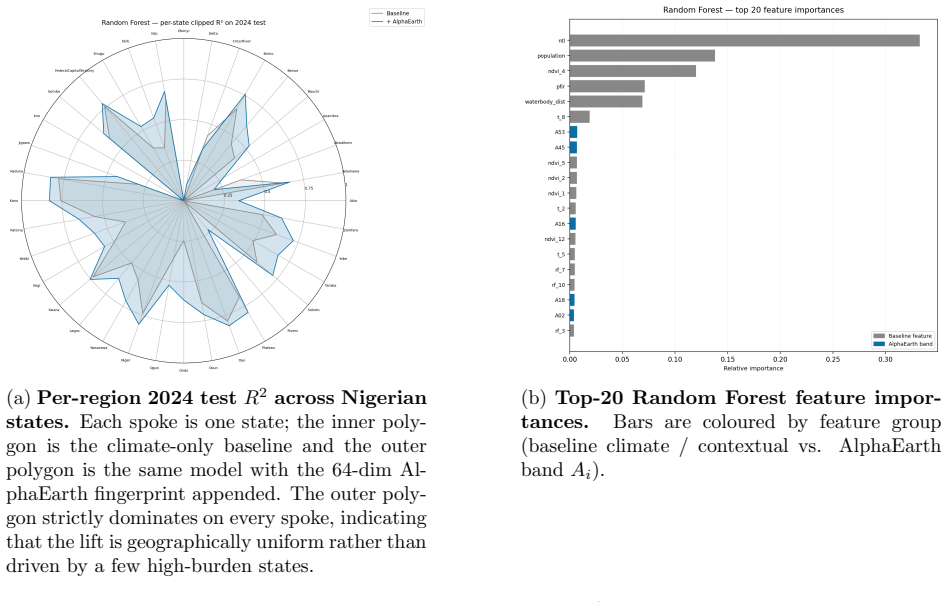
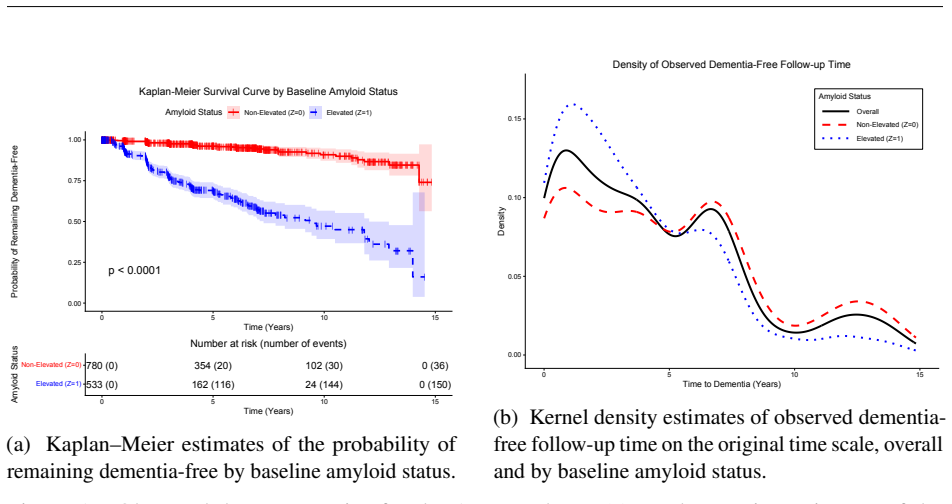
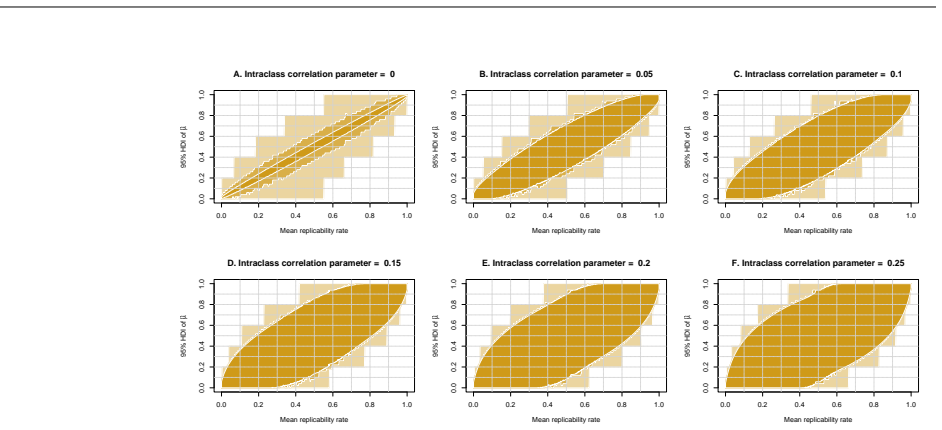
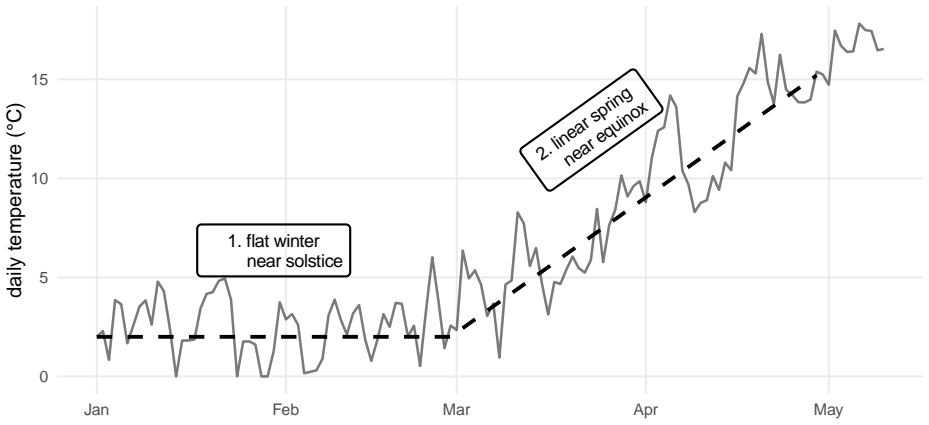
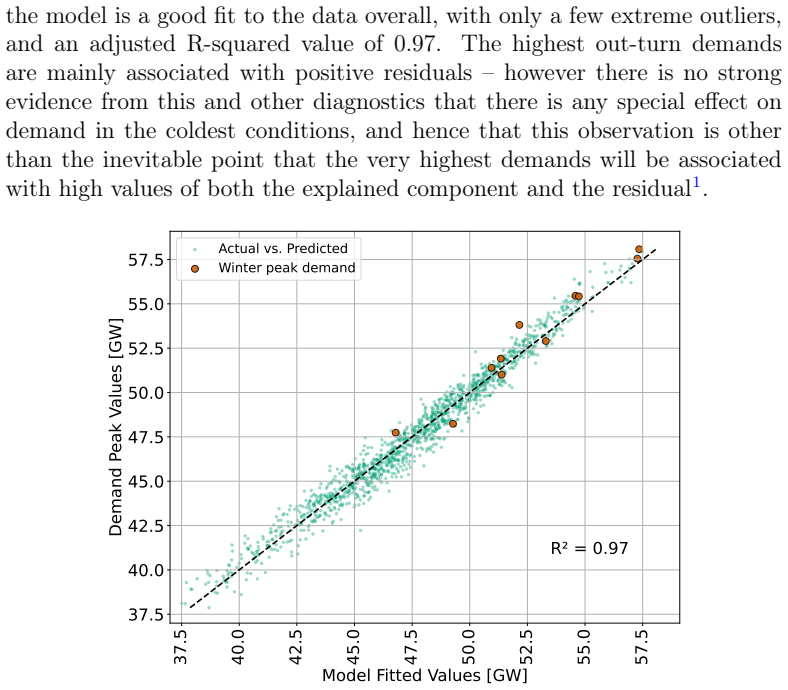
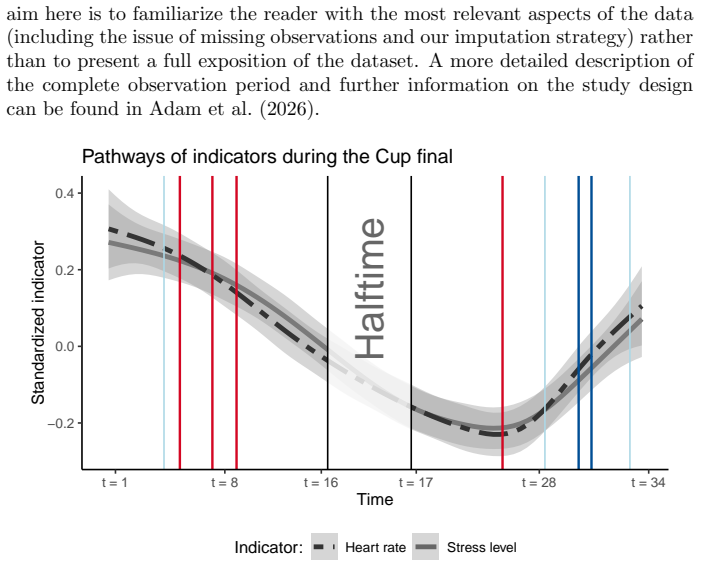
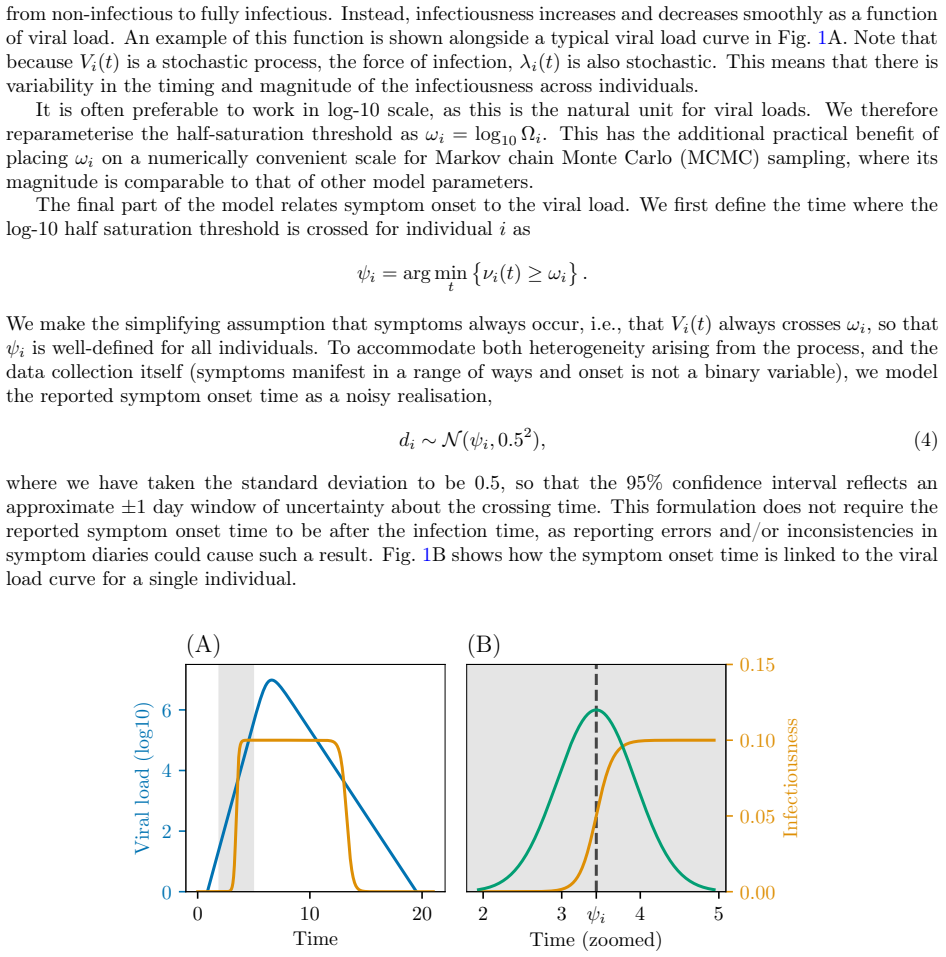
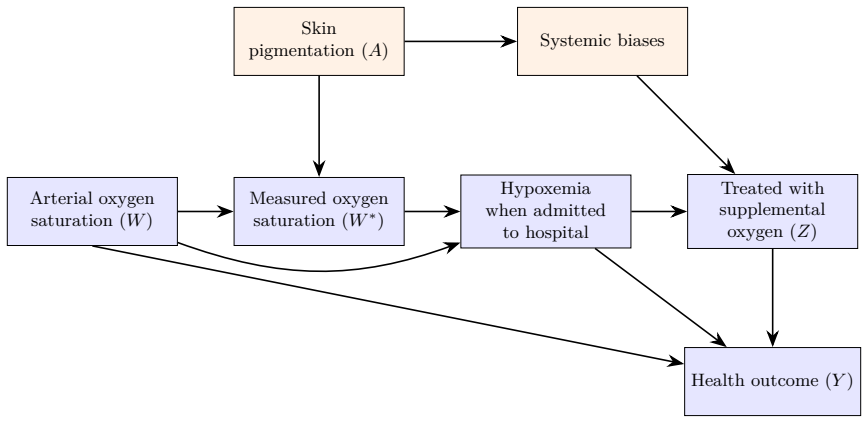
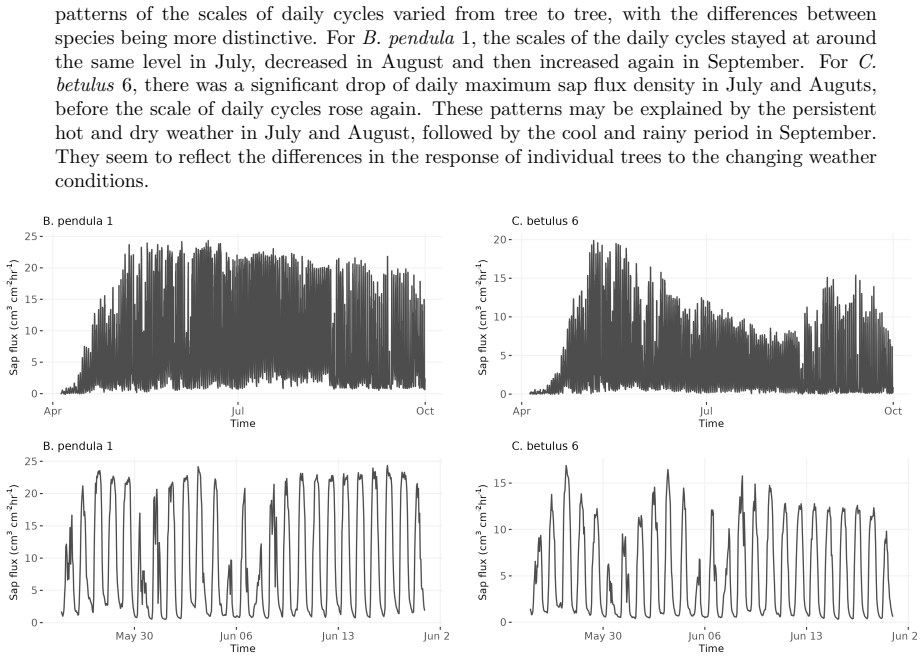
0
Ensemble models forecast daily tree water use from weather data
An ensemble prediction method for forecasting sap flux density and water-use in temperate trees
Additive model ensemble tested across nine species and three seasons enables irrigation planning under climate stress.
 full image
full image
abstract click to expand
Efficient irrigation management is crucial to agriculture, forestry and horticulture, especially under climate change. Developments in novel sensors and Internet of Things technology provide an opportunity to carry out real-time monitoring of tree sap flux density, which, when coupled with advanced modelling techniques, enables online prediction of tree water-use suitable for irrigation planning. This manuscript proposes one such pipeline that integrates tree sap flow sensors, weather station sensors, and statistical models to predict tree daily water-use. In particular, an ensemble prediction approach based on additive models has been developed, using weather data as the main predictors of sap flux density. The method simultaneously considers the non-linear relationships and interactions between sap flux density and its environmental drivers, as well as the variability among individual trees over different growing seasons. Using field data collected on nine species of trees over the 2022, 2023 and 2024 growing seasons, this manuscript demonstrates the ability of the proposed ensemble prediction method in producing reliable daily water-use forecasts. The challenge of predicting tree water-use under climate stress, such as heatwaves, and the impact of tree sizes on prediction have also been discussed. Despite the complexity of the problem, the proposed method provides a general framework which can be used in a variety of settings, from commercial tree growers to conversation work. The model can be integrated into an online monitoring platform, assisting real-time decision making on irrigation management.