Real-Time Group Dynamics with LLM Facilitation: Evidence from a Charity Allocation Task
Pith reviewed 2026-05-15 01:47 UTC · model grok-4.3
The pith
LLM facilitators in group charity tasks shift specific donation shares by up to 5.5 points without raising overall consensus or participation equity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
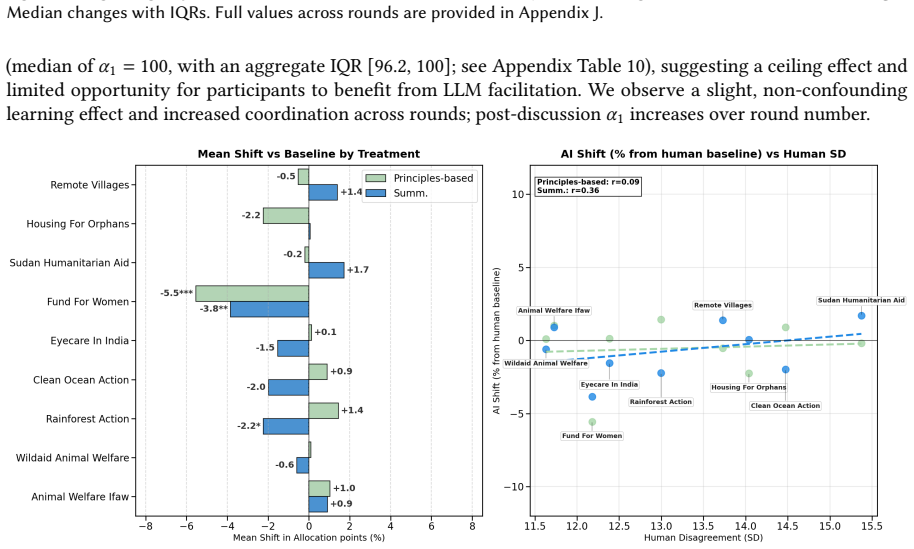
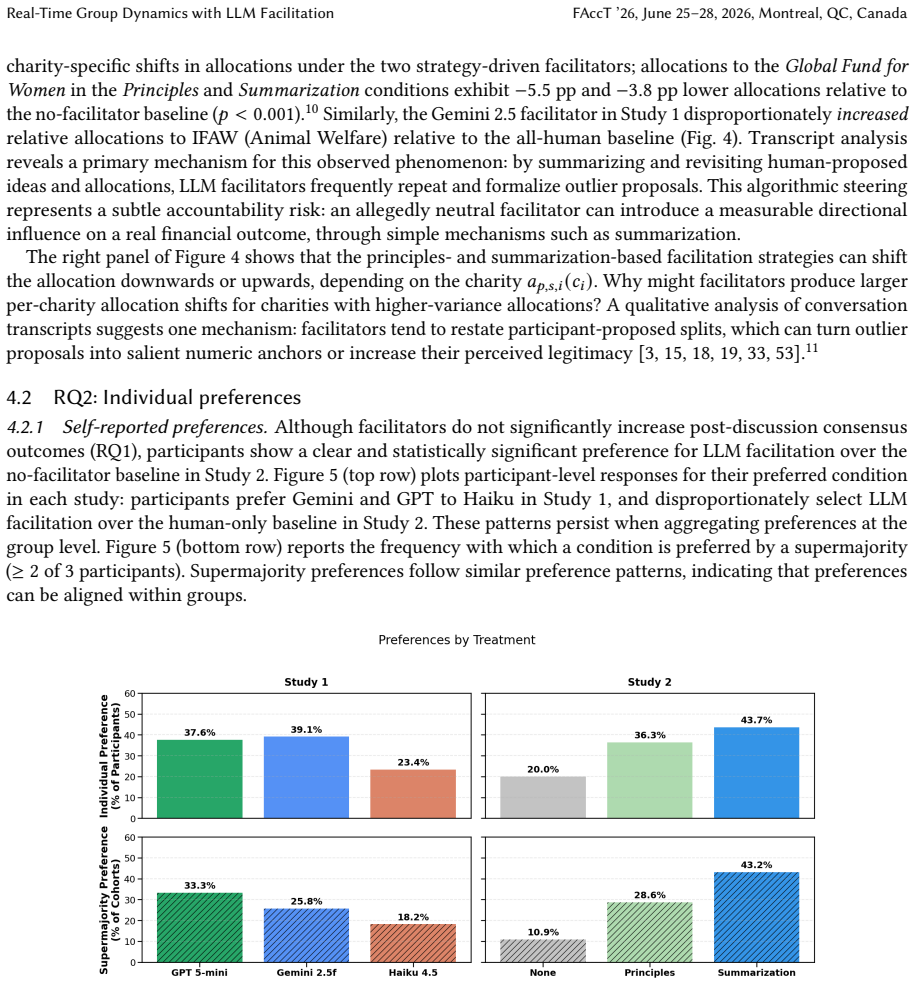
In two studies totaling 879 participants who allocated real donation budgets in groups of three, LLM facilitation across frontier models and strategies produced no significant rise in group consensus compared with no-facilitation baselines. Participants nevertheless preferred facilitated sessions and cited inclusivity as the main reason. Facilitators altered select charity-level shares by as much as 5.5 percentage points, directly affecting payouts, while neither survey responses nor transcript analysis detected improvements in participation equity. Reported trust in the process was higher in the very conditions where steering occurred.
What carries the argument
The incentive-compatible charity allocation task, in which groups divide a fixed budget across charities under text-only chat with or without LLM facilitation, with outcomes tracked through consensus scores, per-charity allocation shifts, survey and transcript equity measures, and post-task preference ratings.
If this is right
- Facilitators can change final charitable payouts even when aggregate agreement metrics remain flat.
- Perceived inclusivity can rise without any corresponding increase in measured participation equity.
- Trust in the deliberation process can increase under conditions where directional influence on outcomes is present.
- Governance evaluation of AI-mediated groups must track collective outcomes, interaction patterns, and subjective perceptions as separate targets.
Where Pith is reading between the lines
- Similar steering could occur in other high-stakes text-based deliberations such as workplace budgeting or community planning.
- Designers might add explicit limits on directional suggestions to reduce unintended allocation shifts while retaining facilitation benefits.
- Testing voice or video interfaces could reveal whether the gap between perceived and actual equity shrinks outside text chat.
Load-bearing premise
The specific charity allocation task with real financial stakes and text-only chat generalizes to other group deliberation settings and the chosen metrics fully capture steering and equity effects.
What would settle it
A replication using a different real-stakes group task, such as ranking policy options, in which LLM facilitation produces neither allocation shifts nor higher preference ratings would falsify the steering and preference findings.
Figures







read the original abstract
As large language models (LLMs) evolve from single-user assistants to active participants in civic and workplace deliberation, evaluating their effects on collective decision making becomes a governance challenge. We present two empirical studies (N=879) of real-time, text-based group deliberation in an incentive-compatible charity allocation task with real financial stakes ($7,200 USD). Groups of three allocate a donation budget under varying LLM facilitation conditions: Study 1 (N=204) compares three frontier models; Study 2 (N=675) compares facilitator strategies against a no-facilitation baseline. Across both studies, LLM facilitation did not significantly improve group consensus in either study, yet participants consistently preferred facilitated discussion. We additionally identify two governance-relevant risks. First, algorithmic steering: facilitators shifted select charity-level allocations by up to 5.5 percentage points -- directly affecting the final charitable payout -- even when aggregate agreement metrics remained unchanged. Second, an illusion of inclusion: participants cited inclusivity as their primary reason for preferring LLM facilitators, yet neither survey nor transcript-based measures of participation equity improved. Notably, participants reported greater trust in the process under the same conditions where facilitators exerted directional influence on outcomes. Together, these findings show that in AI-mediated group deliberation, perceived procedural improvement can coexist with measurable steering and unchanged participation inequality, motivating evaluation practices that treat collective outcomes, interaction dynamics, and participant perceptions as distinct governance targets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents two empirical studies (total N=879) on real-time, text-based group deliberation in an incentive-compatible charity allocation task with real financial stakes ($7,200 USD). Study 1 (N=204) compares three frontier LLMs as facilitators; Study 2 (N=675) compares facilitation strategies to a no-facilitation baseline. Central claims are that LLM facilitation produced no significant improvement in group consensus (per aggregate agreement metrics) yet elicited consistent participant preference for facilitated conditions; two governance risks are identified—algorithmic steering (shifts in select charity allocations up to 5.5 pp without aggregate consensus change) and illusion of inclusion (higher perceived inclusivity without gains in survey or transcript equity measures).
Significance. If the results hold under more detailed scrutiny, the work is significant for HCI and AI governance research. It provides concrete evidence that perceived procedural benefits (preference, trust) can coexist with measurable outcome steering and static participation inequality in LLM-mediated groups. The incentive-compatible design with real stakes strengthens ecological validity for civic and workplace applications, and the distinction between collective outcomes, interaction dynamics, and perceptions offers a useful framework for future evaluation practices.
major comments (3)
- [Results (Study 2)] Results section (Study 2, algorithmic steering paragraph): The claim of shifts up to 5.5 percentage points in specific charity allocations requires explicit statistical tests (e.g., per-charity t-tests or regression coefficients with p-values and confidence intervals) and a precise definition of how 'select' charities were identified; without these, it is unclear whether the shifts are distinguishable from noise given that aggregate agreement metrics showed no change.
- [Methods] Methods section: The operationalization of consensus (e.g., variance, pairwise similarity, or other aggregate metrics) and participation equity (survey items plus transcript coding rules for message volume/turn-taking) must be specified in detail, including inter-rater reliability for transcripts and power analysis for the null consensus result; these metrics are load-bearing for the steering and illusion-of-inclusion conclusions.
- [Discussion] Discussion section: The interpretation that unchanged aggregate metrics plus directional shifts constitute 'steering' rather than a form of consensus change needs justification against alternative granular measures (e.g., semantic alignment of contributions or preference polarization indices); if coarser metrics miss these, the governance-risk framing may require qualification.
minor comments (2)
- [Abstract] Abstract: The total N=879 is the sum of the two studies with no overlap, but a parenthetical note on this would improve immediate clarity.
- [Results] The paper would benefit from reporting effect sizes (e.g., Cohen's d or partial eta-squared) alongside the preference and trust findings to allow readers to assess practical significance.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major point below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Results (Study 2)] Results section (Study 2, algorithmic steering paragraph): The claim of shifts up to 5.5 percentage points in specific charity allocations requires explicit statistical tests (e.g., per-charity t-tests or regression coefficients with p-values and confidence intervals) and a precise definition of how 'select' charities were identified; without these, it is unclear whether the shifts are distinguishable from noise given that aggregate agreement metrics showed no change.
Authors: We agree that additional statistical detail is required for transparency. In the revised manuscript, we will report per-charity independent-samples t-tests (facilitated vs. baseline) with p-values, Cohen's d, and 95% confidence intervals for all allocation differences. 'Select' charities will be defined explicitly as those exhibiting a mean shift of at least 3 percentage points that reaches statistical significance (p < 0.05) in at least one facilitated condition. We will also include the full allocation table for all charities so readers can evaluate the pattern against noise. revision: yes
-
Referee: [Methods] Methods section: The operationalization of consensus (e.g., variance, pairwise similarity, or other aggregate metrics) and participation equity (survey items plus transcript coding rules for message volume/turn-taking) must be specified in detail, including inter-rater reliability for transcripts and power analysis for the null consensus result; these metrics are load-bearing for the steering and illusion-of-inclusion conclusions.
Authors: We will expand the Methods section with precise operational definitions. Consensus is measured by (1) variance of the final allocation proportions across groups and (2) mean pairwise cosine similarity of pre- and post-discussion preference vectors. Participation equity comprises Likert-scale survey items on perceived inclusion/fairness plus transcript coding for message count, total words, and turn-taking Gini coefficient. Two coders will independently code 20% of transcripts; Cohen's kappa will be reported. A post-hoc power analysis for the null consensus results, based on observed effect sizes, will be added to quantify sensitivity to small effects. revision: yes
-
Referee: [Discussion] Discussion section: The interpretation that unchanged aggregate metrics plus directional shifts constitute 'steering' rather than a form of consensus change needs justification against alternative granular measures (e.g., semantic alignment of contributions or preference polarization indices); if coarser metrics miss these, the governance-risk framing may require qualification.
Authors: We maintain that the observed pattern qualifies as steering because directional changes in specific allocations occurred without corresponding gains in aggregate agreement, indicating targeted influence rather than broad convergence. In revision we will add explicit justification contrasting our metrics with polarization indices (showing no increase in preference extremity) and acknowledge that semantic alignment or contribution-level measures could reveal subtler dynamics. The governance-risk language will be qualified to note that our standard allocation metrics may not capture every form of influence, while still highlighting the dissociation between perceived and measured outcomes. revision: partial
Circularity Check
No circularity: purely empirical study with no derivations or self-referential predictions
full rationale
The paper reports two incentive-compatible experiments (N=879) measuring LLM facilitation effects on group consensus, allocation shifts, and perceived inclusivity via surveys and transcripts. No equations, fitted parameters, or first-principles derivations appear; all results rest on direct statistical comparisons of collected data against baselines. No self-citation chains or ansatzes are invoked to justify core claims, so the reported findings on steering and illusion of inclusion are independent of any internal reduction to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions of randomized controlled trials and null-hypothesis significance testing apply to the group allocation task
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.