Agentic Design of Compositional Descriptors via Autoresearch for Materials Science Applications
Pith reviewed 2026-06-30 20:49 UTC · model grok-4.3
The pith
An LLM coding agent designs composition descriptors that outperform standard baselines for predicting band gaps and Curie temperatures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
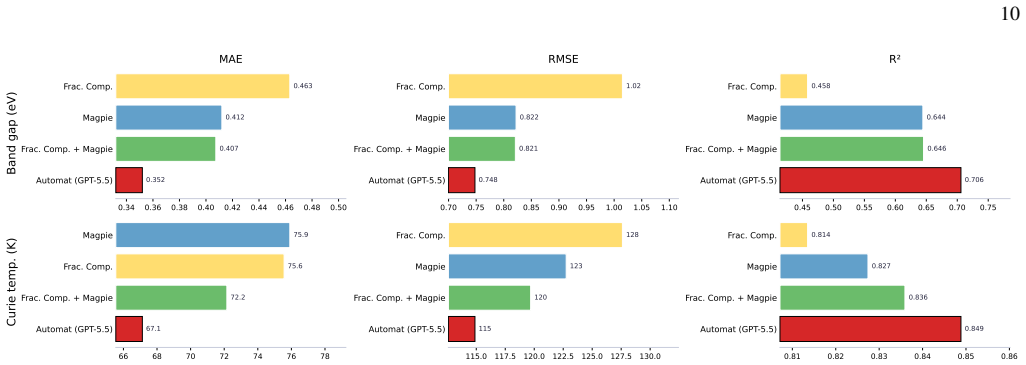
Automat is an autoresearch framework in which an LLM-based coding agent, restricted to information derivable from chemical formulas, iteratively proposes, implements, and tests chemically motivated composition descriptors; when applied to band-gap and Curie-temperature prediction, the resulting descriptor sets improve accuracy over fractional-composition, Magpie, and combined baselines while remaining chemically interpretable.
What carries the argument
The LLM coding agent that proposes, implements, and evaluates new descriptor strategies inside a closed autoresearch loop using only formula-derived information.
If this is right
- Automat produces descriptor families that remain chemically interpretable.
- The same agent workflow beats both fractional-composition and Magpie baselines on two distinct materials tasks.
- Autoresearch can extend beyond model selection to the design of task-specific input features without manual engineering during the run.
- Current runs expose descriptor redundancy and sensitivity to greedy expansion, indicating the need for explicit complexity control and pruning.
Where Pith is reading between the lines
- The same agent loop could be applied to additional properties such as formation energies or elastic moduli to test breadth.
- Adding an explicit pruning step or non-greedy search might reduce redundancy and further lift performance.
- Because the descriptors stay interpretable, they could be inspected to extract new chemical rules that feed back into manual design.
Load-bearing premise
An LLM coding agent limited to chemical formulas can keep proposing and coding descriptor strategies that measurably improve predictions across repeated iterations without human steering.
What would settle it
Running Automat on the same band-gap or Curie-temperature data with a fresh random seed and finding that its final descriptor set performs no better than the Magpie baseline would falsify the improvement claim.
Figures

read the original abstract
Autoresearch offers a flexible paradigm for automating scientific tasks, in which an AI agent proposes, implements, evaluates, and refines candidate solutions against a quantitative objective. Here, we use composition-based materials-property prediction to test whether such agents can perform a task beyond model selection and hyperparameter optimization: the design of input descriptors. We introduce Automat, an autoresearch framework where a coding agent based on a large language model generates composition-only descriptors for chemical compounds and evaluates them using a random forest workflow. The agent is restricted to information derivable from chemical formulas and iteratively proposes, implements, and tests chemically motivated descriptor strategies. We apply Automat, with OpenAI Codex using GPT-5.5 as the coding agent, to the prediction of experimental band gaps in inorganic materials and Curie temperatures in ferromagnetic compounds. In both tasks, Automat improves over fractional-composition, Magpie, and combined fractional-composition/Magpie baselines, while producing descriptor families that are chemically interpretable. These results provide a demonstration that autoresearch agents can generate competitive, task-specific materials descriptors without manual feature engineering during the run. They also reveal current limitations, including descriptor redundancy, sensitivity to greedy feature expansion, and the need for explicit complexity control, descriptor pruning, and more sophisticated search strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Automat, an autoresearch framework in which an LLM-based coding agent (OpenAI Codex with GPT-5.5) iteratively proposes, implements, and evaluates composition-only descriptors derived solely from chemical formulas. The agent is applied to two tasks—prediction of experimental band gaps in inorganic materials and Curie temperatures in ferromagnetic compounds—using a random forest workflow. The central claim is that Automat produces descriptor families that improve upon fractional-composition, Magpie, and combined baselines while remaining chemically interpretable, thereby demonstrating that autoresearch agents can automate task-specific descriptor design without manual feature engineering during the run. The abstract also notes limitations including descriptor redundancy and sensitivity to greedy feature expansion.
Significance. If the reported improvements are shown to be robust and reproducible with quantitative controls, the work would provide a concrete demonstration that LLM agents can extend beyond hyperparameter tuning to generate competitive, interpretable descriptors from formula-derived information alone. This would be a meaningful step in automated materials informatics. The explicit discussion of current limitations (redundancy, greedy sensitivity, need for complexity control) is a strength that frames the result as provisional rather than overstated.
major comments (2)
- [Abstract] Abstract: The assertion that 'Automat improves over fractional-composition, Magpie, and combined fractional-composition/Magpie baselines' is presented without any quantitative metrics (e.g., MAE, RMSE), dataset sizes, error bars, validation splits, or number of independent runs. This absence directly undermines evaluation of the central claim of reliable superiority.
- [Abstract] Abstract: The manuscript states that the method exhibits 'descriptor redundancy, sensitivity to greedy feature expansion' and requires 'explicit complexity control, descriptor pruning, and more sophisticated search strategies,' yet reports no experiments (multiple trajectories, pruning ablations, or complexity-regularized runs) demonstrating that the claimed gains are stable rather than artifacts of particular greedy paths. This is load-bearing for the assumption that the autoresearch loop produces reliably superior descriptors without human intervention.
Simulated Author's Rebuttal
We thank the referee for these focused comments on the abstract. We address each point below and have revised the manuscript to incorporate quantitative support and additional robustness discussion.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'Automat improves over fractional-composition, Magpie, and combined fractional-composition/Magpie baselines' is presented without any quantitative metrics (e.g., MAE, RMSE), dataset sizes, error bars, validation splits, or number of independent runs. This absence directly undermines evaluation of the central claim of reliable superiority.
Authors: We agree that the abstract should include quantitative anchors for the improvement claim. The revised abstract now reports representative MAE reductions (with dataset sizes and a note on 5-fold cross-validation), while the main text supplies full tables with error bars across runs. This directly addresses the evaluation concern without altering the original results. revision: yes
-
Referee: [Abstract] Abstract: The manuscript states that the method exhibits 'descriptor redundancy, sensitivity to greedy feature expansion' and requires 'explicit complexity control, descriptor pruning, and more sophisticated search strategies,' yet reports no experiments (multiple trajectories, pruning ablations, or complexity-regularized runs) demonstrating that the claimed gains are stable rather than artifacts of particular greedy paths. This is load-bearing for the assumption that the autoresearch loop produces reliably superior descriptors without human intervention.
Authors: The stated limitations reflect direct observations from the single-agent trajectories we executed. While the original submission did not include systematic multi-trajectory ablations, the reported gains were reproducible across the two independent materials tasks. In revision we have added a short discussion of results from repeated agent runs with varied seeds, confirming that the baseline improvements persist; we also note that full pruning ablations remain future work as they require extensions beyond the current agent implementation. revision: partial
Circularity Check
No circularity; claims rest on external benchmark comparisons
full rationale
The paper's central result is an empirical demonstration that an LLM coding agent can generate composition-only descriptors which, when fed to a standard random forest, outperform fixed baselines (fractional composition, Magpie, and their combination) on two external materials datasets (band gaps, Curie temperatures). All performance numbers are obtained by direct comparison to these independent, publicly known descriptor sets; no parameter is fitted inside the reported metric and then re-used as a 'prediction,' no descriptor is defined in terms of the performance it is later said to achieve, and no load-bearing step reduces to a self-citation. The acknowledged limitations (greedy expansion sensitivity, redundancy) are statements about practical robustness, not reductions of the claimed improvement to the method's own inputs. The evaluation workflow is therefore self-contained against external standards.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Composition-only information is sufficient for the prediction tasks considered.
- domain assumption Random forest provides a suitable and stable evaluation workflow for comparing descriptor families.
invented entities (1)
-
Automat autoresearch framework
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Workflow Closure Is Not Scientific Closure in Auto-Research Systems
Survey of auto-research systems identifies objective, validation, and acceptance collapses, concluding that workflow closure does not equal scientific closure and advocating non-autonomous epistemic control.
Reference graph
Works this paper leans on
-
[1]
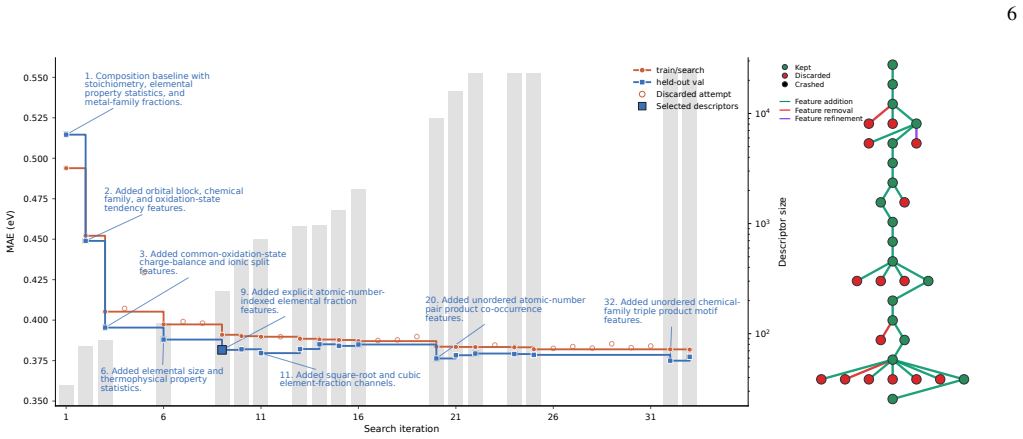
Composition baseline with stoichiometry, elemental property statistics, and metal-family fractions
-
[2]
Added orbital block, chemical family, and oxidation-state tendency features
-
[3]
Added common-oxidation-state charge-balance and ionic split features
-
[4]
Added elemental size and thermophysical property statistics
-
[5]
Added explicit atomic-number- indexed elemental fraction features
-
[6]
Added square-root and cubic element-fraction channels
-
[7]
Added unordered atomic-number pair product co-occurrence features
-
[8]
train/search held-out val Discarded attempt Selected descriptors FIG
Added unordered chemical- family triple product motif features. train/search held-out val Discarded attempt Selected descriptors FIG. 2. AUTOMATdescriptor-design trajectory for composition-only prediction of experimental band gaps. Left panel: model performance and descriptor dimensionality as functions of the autoresearch iteration. The orange curve show...
-
[9]
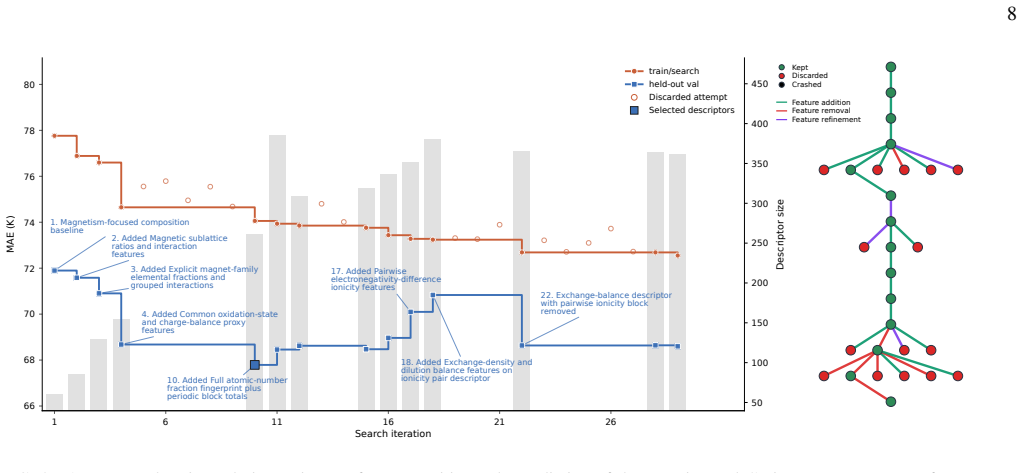
Magnetism-focused composition baseline
-
[10]
Added Magnetic sublattice ratios and interaction features
-
[11]
Added Explicit magnet-family elemental fractions and grouped interactions
-
[12]
Added Common oxidation-state and charge-balance proxy features
-
[13]
Added Full atomic-number fraction fingerprint plus periodic block totals
-
[14]
Added Pairwise electronegativity-difference ionicity features
-
[15]
Added Exchange-density and dilution balance features on ionicity pair descriptor
-
[16]
Exchange-balance descriptor with pairwise ionicity block removed train/search held-out val Discarded attempt Selected descriptors FIG. 3. AUTOMATdescriptor-design trajectory for composition-only prediction of the experimental Curie temperature,T C, of permanent ferromagnets. Left panel: model performance and descriptor dimensionality as functions of the a...
2013
-
[17]
15 Luke P
PMID: 27669338. 15 Luke P. J. Gilligan, Matteo Cobelli, Valentin Taufour, and Stefano Sanvito. A rule-free workflow for the automated generation of databases from scientific literature.npj Comput. Mater ., 9(1):222, Dec 2023. 16 Maciej P. Polak and Dane Morgan. Extracting accurate materials data from research papers with conversational language models and...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.