Compositional Sparsity as an Inductive Bias for Neural Architecture Design
Pith reviewed 2026-06-30 20:52 UTC · model grok-4.3
The pith
Mapping sparse dependency graphs into fixed neural wirings produces models that learn high-dimensional functions with far fewer parameters than dense networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Target functions decompose into constituents supported on low-dimensional variable subsets. Sparse dependency structures extracted by constrained information maximisation in information filtering networks capture this compositional sparsity. Mapping the inferred topology into fixed-wiring sparse neural graphs via homological neural networks produces architectures that recover the underlying structure on synthetic tasks, remain stable as dimensionality increases, and match or outperform dense baselines on real data while using far fewer parameters, showing lower variance and reduced sensitivity to hyperparameters.
What carries the argument
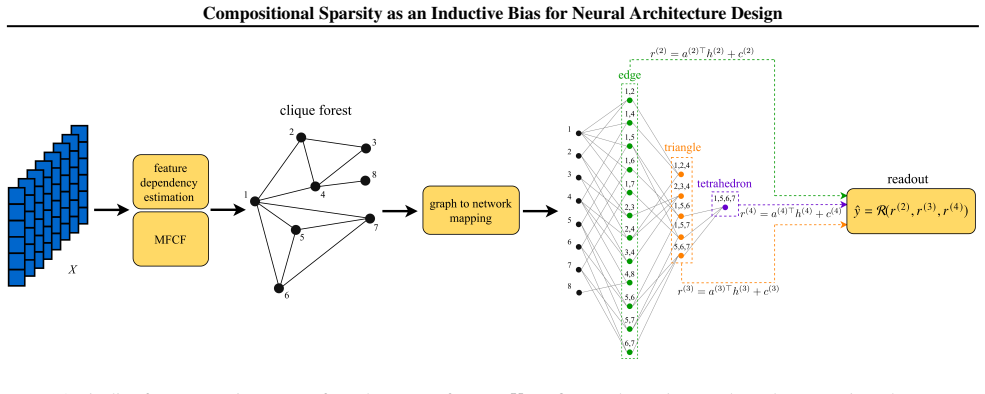
Homological mapping that converts sparse dependency graphs from information filtering networks into fixed-wiring sparse neural architectures.
If this is right
- HNNs are orders of magnitude sparser than standard DNNs.
- HNNs recover the underlying compositional structure on synthetic tasks with known sparse hierarchies.
- HNNs remain stable in regimes where dense alternatives degrade as dimensionality increases.
- HNNs match or outperform dense baselines on real-world datasets while using far fewer parameters and exhibiting lower variance.
Where Pith is reading between the lines
- Replacing information filtering networks with other sparsity-extraction methods could test whether the performance gains depend on that specific extraction step.
- The fixed wiring derived from data dependencies could make the learned models more interpretable by aligning architecture directly with the function's compositional hierarchy.
- The observed stability at high dimensions suggests the approach may scale to problems where dense networks become impractical due to parameter growth.
- Applying the same pipeline to sequential or graph-structured data could reveal whether compositional sparsity appears in those settings as well.
Load-bearing premise
The sparse dependency structures extracted by constrained information maximisation accurately capture the compositional sparsity of the target functions so that the homological mapping produces useful fixed-wiring graphs.
What would settle it
A high-dimensional task whose true compositional structure is known in advance but where networks built from the information-filtered graphs fail to learn while dense networks succeed.
Figures
read the original abstract
Identifying the structural priors that enable Deep Neural Networks (DNNs) to overcome the curse of dimensionality is a fundamental challenge in machine learning theory. Existing literature suggests that effective high-dimensional learning is driven by compositional sparsity, where target functions decompose into constituents supported on low-dimensional variable subsets. To investigate this hypothesis, we combine Information Filtering Networks (IFNs), which extract sparse dependency structures via constrained information maximisation, with Homological Neural Networks (HNNs), which map the inferred topology into fixed-wiring sparse neural graphs. We formalise the design principles underlying this construction and present an interpretable pipeline in which abstraction emerges through hierarchical composition. HNNs are orders of magnitude sparser than standard DNNs and require only minimal hyperparameter tuning. On synthetic tasks with known sparse hierarchies, HNNs recover the underlying compositional structure and remain stable in regimes where dense alternatives degrade as dimensionality increases. Across a broad suite of real-world datasets, HNNs consistently match or outperform dense baselines while using far fewer parameters, exhibiting lower variance and showing reduced sensitivity to hyperparameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes combining Information Filtering Networks (IFNs), which extract sparse dependency structures via constrained information maximisation, with Homological Neural Networks (HNNs) that map the inferred topology into fixed-wiring sparse neural graphs. The central claim is that this pipeline realises compositional sparsity as an inductive bias for neural architecture design, yielding networks that are orders of magnitude sparser than standard DNNs, recover known sparse hierarchies on synthetic tasks, remain stable as dimensionality grows, and match or outperform dense baselines on real-world datasets while using far fewer parameters, exhibiting lower variance, and showing reduced hyperparameter sensitivity.
Significance. If the empirical claims hold with supporting quantitative evidence and the IFN step is shown to recover true compositional structure rather than spurious sparsity, the work would supply a data-driven, interpretable route to embedding compositional sparsity as an inductive bias. This could help explain how DNNs overcome the curse of dimensionality and reduce reliance on extensive hyperparameter search.
major comments (2)
- [Abstract] Abstract: the abstract states that HNNs recover the underlying compositional structure on synthetic tasks with known hierarchies and outperform dense baselines on real-world data, yet supplies no quantitative recovery metrics (e.g., precision/recall on recovered variable subsets or graph-edit distance to ground-truth hierarchies), no error bars, no dataset descriptions, and no ablation controls that replace the IFN step with a generic sparsity method. These omissions are load-bearing for the claim that the constrained information maximisation in IFNs accurately captures the true low-dimensional compositional supports.
- [Abstract] Abstract: no statement is given of the precise constraints imposed during information maximisation in the IFN step, nor of the homological mapping procedure that converts the extracted dependency graph into the fixed-wiring HNN topology. Without these details it is impossible to verify whether the resulting graphs encode the compositional sparsity of the target functions rather than any sparse graph.
minor comments (1)
- [Abstract] The abstract introduces 'homological mapping' and 'abstraction emerges through hierarchical composition' without a brief definition or pointer to the relevant section, which reduces immediate clarity for readers outside the subfield.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the abstract accordingly in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract states that HNNs recover the underlying compositional structure on synthetic tasks with known hierarchies and outperform dense baselines on real-world data, yet supplies no quantitative recovery metrics (e.g., precision/recall on recovered variable subsets or graph-edit distance to ground-truth hierarchies), no error bars, no dataset descriptions, and no ablation controls that replace the IFN step with a generic sparsity method. These omissions are load-bearing for the claim that the constrained information maximisation in IFNs accurately captures the true low-dimensional compositional supports.
Authors: We agree the abstract is too high-level on this point. The manuscript body reports recovery of known hierarchies on synthetic tasks via performance metrics and visualizations, plus comparisons on real datasets. In revision we will update the abstract to report key quantitative recovery metrics (precision/recall on variable subsets), error bars from repeated runs, dataset names, and reference to ablations against generic sparsity baselines. This directly addresses the concern that the IFN step captures true compositional supports rather than arbitrary sparsity. revision: yes
-
Referee: [Abstract] Abstract: no statement is given of the precise constraints imposed during information maximisation in the IFN step, nor of the homological mapping procedure that converts the extracted dependency graph into the fixed-wiring HNN topology. Without these details it is impossible to verify whether the resulting graphs encode the compositional sparsity of the target functions rather than any sparse graph.
Authors: The abstract is a concise summary; the precise IFN constraints (constrained information maximisation) and the homological mapping from dependency graph to fixed-wiring HNN are defined in the methods. We will revise the abstract to include brief statements of these elements so that the encoding of compositional sparsity is verifiable from the abstract itself. revision: yes
Circularity Check
No circularity: empirical pipeline with independent evaluation steps
full rationale
The paper presents a two-stage pipeline (IFN for extracting sparse dependency graphs via constrained information maximisation, followed by homological mapping to HNN fixed-wiring graphs) and evaluates it empirically on synthetic tasks with known hierarchies and on real-world datasets. No equations, definitions, or self-citations in the abstract reduce the reported recovery or performance gains to the construction of the graphs themselves. The central claim that the extracted structures capture compositional sparsity is treated as a testable hypothesis whose validity is assessed by external metrics (stability, parameter count, accuracy), not by re-deriving the same fitted quantities. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- sparsity constraint parameters in IFN
axioms (1)
- domain assumption Target functions decompose into constituents supported on low-dimensional variable subsets (compositional sparsity)
Reference graph
Works this paper leans on
-
[1]
Aste, T. Information filtering networks: Theoretical founda- tions, generative algorithms, and real-world applications. Journal of Physics: Complexity, 2025a. Also available as arXiv:2505.03812. Aste, T.Probabilistic Data-Driven Modeling. Cambridge University Press, 2025b. Aste, T., Di Matteo, T., and Hyde, S. T. Complex networks on hyperbolic surfaces.Ph...
-
[2]
Ba, J. L., Kiros, J. R., and Hinton, G. E. Layer normalization. arXiv preprint arXiv:1607.06450,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Beneventano, P., Pinto, A., and Poggio, T. How neural networks learn the support is an implicit regularization effect of SGD.arXiv preprint arXiv:2406.11110,
-
[4]
and Aste, T
Briola, A. and Aste, T. Topological feature selection. In Topological, Algebraic and Geometric Learning Work- shops 2023, pp. 534–556. PMLR,
2023
-
[5]
Homo- logical convolutional neural networks.arXiv preprint arXiv:2308.13816,
Briola, A., Wang, Y ., Bartolucci, S., and Aste, T. Homo- logical convolutional neural networks.arXiv preprint arXiv:2308.13816,
-
[6]
Ebli, S., Defferrard, M., and Spreemann, G
Also available as arXiv:2507.02550. Ebli, S., Defferrard, M., and Spreemann, G. Simplicial neural networks. InAdvances in Neural Information Processing Systems, volume 33, pp. 9360–9371,
-
[7]
F., Feurer, M., and Bischl, B
Fischer, S. F., Feurer, M., and Bischl, B. OpenML-CTR23: A curated tabular regression benchmarking suite. InAu- toML Conference 2023 Workshop,
2023
-
[8]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., and Dean, J. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Granger causal- ity detection with kolmogorov-arnold networks.arXiv preprint arXiv:2412.15373,
Lin, H., Ren, M., Barucca, P., and Aste, T. Granger causal- ity detection with kolmogorov-arnold networks.arXiv preprint arXiv:2412.15373,
-
[10]
arXiv preprint arXiv:2410.18164 , year=
Ma, J., Thomas, V ., Hosseinzadeh, R., Kamkari, H., Labach, A., Cresswell, J. C., Golestan, K., Yu, G., V olkovs, M., and Caterini, A. L. TabDPT: Scaling tabular foundation models.arXiv preprint arXiv:2410.18164,
-
[11]
Deep Learning: A Critical Appraisal
Marcus, G. Deep learning: A critical appraisal.arXiv preprint arXiv:1801.00631,
work page internal anchor Pith review Pith/arXiv arXiv
- [12]
- [13]
-
[14]
The impact of depth on compositional generalization in transformer language models
Petty, J., Steenkiste, S., Dasgupta, I., Sha, F., Garrette, D., and Linzen, T. The impact of depth on compositional generalization in transformer language models. InPro- ceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 7239–7252,
2024
-
[15]
Analyzing the Structure of Attention in a Transformer Language Model
Vig, J. and Belinkov, Y . Analyzing the structure of atten- tion in a transformer language model.arXiv preprint arXiv:1906.04284,
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[16]
Homological neural networks: A sparse architecture for multivariate complex- ity
Wang, Y ., Briola, A., and Aste, T. Homological neural networks: A sparse architecture for multivariate complex- ity. InTopological, Algebraic and Geometric Learning Workshops 2023, pp. 228–241. PMLR, 2023a. Wang, Y ., Briola, A., and Aste, T. Topological portfolio selection and optimization. InProceedings of the Fourth ACM International Conference on AI ...
-
[17]
Learning under Concept Drift: an Overview
Zliobait˙e, I. Learning under concept drift: An overview. Technical Report arXiv:1010.4784, arXiv,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Tree-based baselines follow the same fixed configurations used in the synthetic experiments
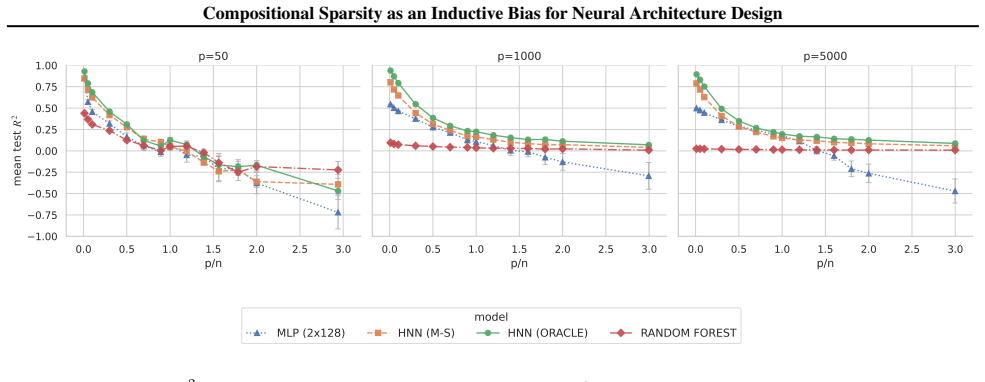
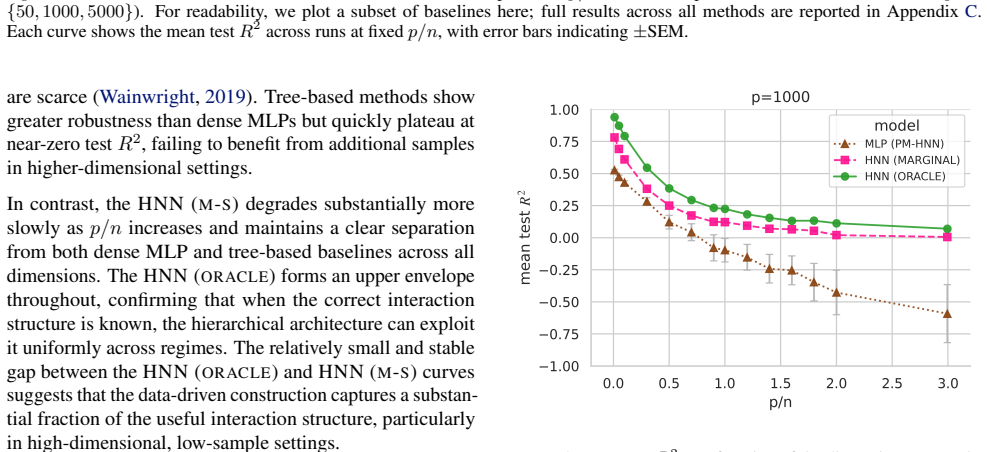
All MLPs share the same optimiser, stopping criteria, and activation functions as HNNs. Tree-based baselines follow the same fixed configurations used in the synthetic experiments. C. Additional Synthetic Results Table 3 reports aggregated test R2 rankings across the full sweep of synthetic configurations, spanning feature dimensions p∈[50,5000] and dimen...
1988
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.