SaaS-Bench: Can Computer-Use Agents Leverage Real-World SaaS to Solve Professional Workflows?
Pith reviewed 2026-05-20 18:59 UTC · model grok-4.3
The pith
LLM-based computer-using agents complete fewer than 4% of realistic professional SaaS tasks end-to-end.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
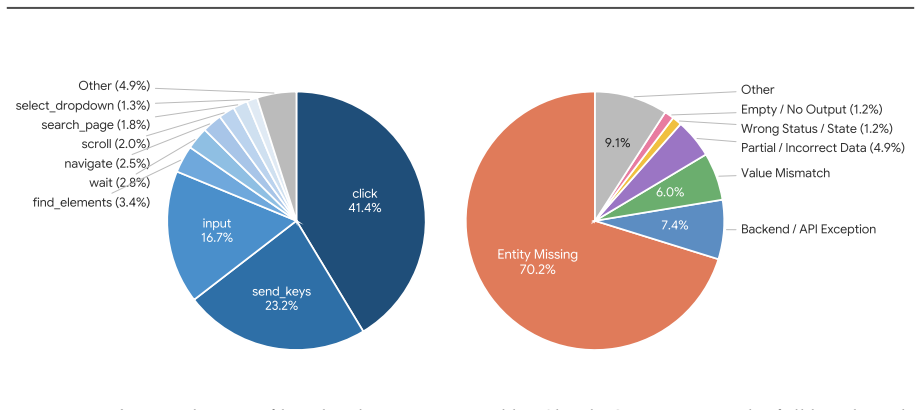
SaaS-Bench is introduced as a benchmark built on 23 deployable SaaS systems across six domains with 106 tasks grounded in realistic scenarios. These tasks involve long-horizon execution in both text and multimodal settings and use weighted verification checkpoints to measure completion and progress. Representative LLM-based agents struggle, with the strongest completing fewer than 4% of tasks end-to-end, revealing limitations in planning, state tracking, cross-application context maintenance, and error recovery.
What carries the argument
SaaS-Bench benchmark with its 106 tasks and weighted verification checkpoints, which evaluates agents on dynamic system states and cross-application coordination in professional SaaS environments.
If this is right
- Current agents lack the ability to maintain context across multiple applications over long periods.
- Error recovery is a critical missing capability for handling real workflows.
- Both planning and state tracking need significant improvement to achieve practical utility.
- The benchmark highlights the need for agents that can handle multimodal inputs effectively in GUI settings.
Where Pith is reading between the lines
- If true, this implies that future agent research should prioritize architectures with explicit memory or state management modules.
- The results could motivate development of hybrid systems that combine LLM reasoning with rule-based automation for SaaS tasks.
- Extending the benchmark to include more domains might reveal domain-specific strengths or weaknesses in agent performance.
Load-bearing premise
The assumption that the selected 106 tasks accurately represent realistic professional workflows and that the weighted checkpoints reliably indicate task success or partial progress.
What would settle it
A new agent design that achieves end-to-end completion on more than 20% of the 106 tasks would challenge the reported limitations of current approaches.
Figures









read the original abstract
Computer-Using Agents (CUAs) are rapidly extending large language models (LLMs) beyond text-based reasoning toward action execution in more complex environments, such as web browsers and graphical user interfaces (GUIs). However, existing web and GUI agent benchmarks often rely on simplified settings, isolated tasks, or short-horizon interactions, making it difficult to assess capabilities of agents in realistic professional workflows. Software-as-a-Service (SaaS) environments are a natural choice for CUA evaluation, as they host a large share of modern digital work and naturally involve dynamic system states, cross-application coordination, domain-specific knowledge, and long-horizon dependencies. To this end, we introduce SaaS-Bench, a benchmark built on 23 deployable SaaS systems across six professional domains, containing 106 tasks grounded in realistic work scenarios. These tasks require long-horizon execution, cover both text-only and multimodal settings, and are evaluated with weighted verification checkpoints that measure strict task completion and partial progress. Experiments show that representative LLM-based agents struggle on SaaS-Bench, with even the strongest model completing fewer than 4% of tasks end-to-end, exposing limitations in planning, state tracking, cross-application context maintenance, and error recovery. Code are available at https://github.com/UniPat-AI/SaaS-Bench for reproduction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SaaS-Bench, a benchmark built on 23 deployable real-world SaaS systems across six professional domains, containing 106 tasks grounded in realistic work scenarios. These tasks emphasize long-horizon execution, dynamic states, cross-application coordination, and both text-only and multimodal interactions. Evaluation uses weighted verification checkpoints to measure strict end-to-end task completion as well as partial progress. Experiments with representative LLM-based computer-use agents report that even the strongest model completes fewer than 4% of tasks end-to-end, highlighting limitations in planning, state tracking, cross-application context maintenance, and error recovery. Code is released for reproduction.
Significance. If the tasks accurately reflect professional workflows and the verification method reliably distinguishes full completion from partial progress, the benchmark would fill a notable gap left by existing simplified web and GUI agent evaluations. The reported sub-4% success rates would then constitute a concrete, falsifiable signal of current agent shortcomings in realistic SaaS settings. The public code release is a clear strength that supports reproducibility and future extensions.
major comments (1)
- [§3] §3 (Benchmark Construction) and the associated verification protocol: the manuscript does not provide quantitative details on how the weighted checkpoints were derived, how weights were assigned to sub-steps, inter-rater agreement for task grounding, or sensitivity analysis for missing critical state transitions. Because the central claim of <4% end-to-end success rests on these checkpoints accurately measuring strict completion rather than benchmark artifacts, this omission is load-bearing and requires explicit documentation or supplementary material.
minor comments (1)
- The abstract contains a minor grammatical issue ('Code are available' should read 'Code is available').
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the single major comment below and commit to revisions that directly respond to the concerns raised about documentation of the verification protocol.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction) and the associated verification protocol: the manuscript does not provide quantitative details on how the weighted checkpoints were derived, how weights were assigned to sub-steps, inter-rater agreement for task grounding, or sensitivity analysis for missing critical state transitions. Because the central claim of <4% end-to-end success rests on these checkpoints accurately measuring strict completion rather than benchmark artifacts, this omission is load-bearing and requires explicit documentation or supplementary material.
Authors: We agree that the current manuscript provides only a high-level description of the weighted verification checkpoints in §3 and that additional quantitative details are required to substantiate the evaluation protocol. In the revised version we will expand §3 with a new subsection that (1) explains the derivation process, including the use of domain-expert review to identify critical state transitions and assign weights proportionally to their impact on task completion; (2) reports the exact weighting scheme and the rationale for each weight value; (3) presents inter-rater agreement statistics (Cohen’s κ) obtained from the three annotators who independently grounded each task and its checkpoints; and (4) includes a sensitivity analysis (moved to the appendix) that perturbs checkpoint weights and omits selected state transitions to show that the reported sub-4 % end-to-end success rate remains stable. These additions will be supported by new tables and will not alter any experimental results. We believe the expanded documentation will eliminate concerns about benchmark artifacts while preserving the paper’s central claims. revision: yes
Circularity Check
No circularity: empirical benchmark results are direct measurements
full rationale
The paper introduces SaaS-Bench as a new collection of 106 tasks on 23 real SaaS systems and reports measured agent success rates (under 4% end-to-end) from direct experiments. No equations, fitted parameters, or derivations are present; the headline percentages are observations on the constructed benchmark rather than quantities forced by self-definition, renamed fits, or self-citation chains. Task design and weighted checkpoints are presented as independent engineering choices grounded in professional scenarios, with no reduction of the reported outcomes back to the inputs by construction. This is a standard empirical benchmark paper whose central claims remain falsifiable against external agent runs and do not rely on any load-bearing self-referential step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SaaS environments naturally involve dynamic system states, cross-application coordination, and long-horizon dependencies suitable for CUA evaluation.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.