FML-bench: A Controlled Study of AI Research Agent Strategies from the Perspective of Search Dynamics
Pith reviewed 2026-06-30 18:58 UTC · model grok-4.3
The pith
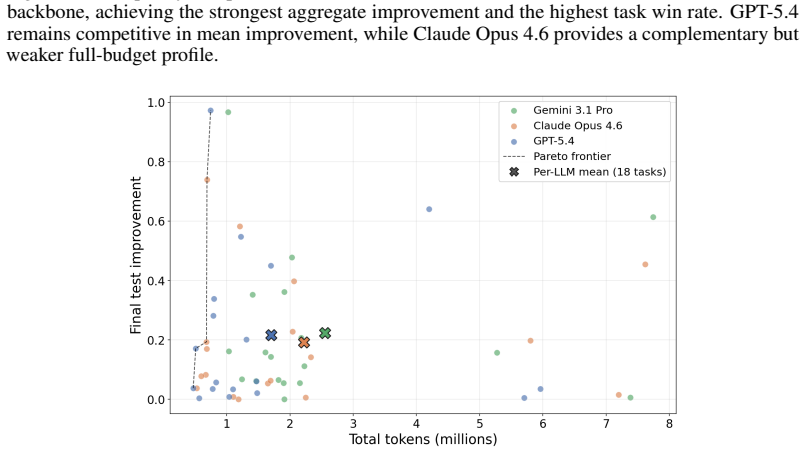
A simple greedy hill-climber nearly matches the best tree-search agent on fundamental ML tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Evaluating six representative agents on FML-Bench shows that strategy complexity alone does not guarantee strong performance: a simple greedy hill-climber nearly matches the best-performing tree-search agent, both well above the remaining agents. This pattern appears tied to improvement opportunity structure, with greedy search more effective on dense opportunities and tree-search or evolutionary strategies more effective on sparse ones. An adaptive agent that switches to broader exploration upon detecting stagnation outperforms the other six, and process-level analysis finds early convergence and directionally focused exploration significantly associated with final performance while solutio
What carries the argument
FML-Bench, a benchmark of 18 fundamental ML research tasks with 12 process-level behavioral metrics that separates agent search strategy from execution infrastructure.
If this is right
- Greedy search tends to be more effective when improvement opportunities are dense.
- Tree-search and evolutionary strategies tend to be more effective when opportunities are sparse.
- Early convergence and directionally focused exploration correlate with higher final performance.
- Solution diversity and total compute cost show no significant link to final performance.
- An adaptive agent that detects stagnation and switches search style outperforms fixed strategies.
Where Pith is reading between the lines
- Agent designers could embed a simple stagnation detector to trigger strategy switches rather than commit to one fixed search topology.
- The benchmark's separation of strategy from infrastructure makes it possible to test whether the same opportunity-structure pattern holds in non-ML scientific domains.
- If the density of improvements can be estimated from early runs, agents might pre-select search style instead of reacting after stagnation occurs.
Load-bearing premise
The 18 tasks and 12 metrics cleanly separate strategy effects from execution infrastructure and represent a typical sample of ML research problems.
What would settle it
Running the six agents plus the adaptive agent on a fresh collection of tasks drawn from the same domains and observing that the performance ordering reverses or that the adaptive agent loses its lead.
Figures








read the original abstract
AI research agents accelerate ML research by automating hypothesis generation, experimentation, and empirical refinement. Existing agent strategies range from greedy hill-climbing to tree search and evolutionary optimization, yet which strategy choices drive performance remains unclear. Answering this question requires a benchmark that separates agent strategy (e.g., search topology) from execution infrastructure (e.g., code editor), so that performance differences are attributable to strategy rather than infrastructure, and that provides process-level metrics beyond final scores to analyze exploration behaviors. Existing benchmarks offer limited support. We propose FML-Bench, a benchmark of 18 fundamental ML research tasks across 10 domains that separates agent strategy from execution infrastructure and defines 12 process-level behavioral metrics. Evaluating six representative agents, we find that: (1) strategy complexity alone does not guarantee strong performance: a simple greedy hill-climber nearly matches the best-performing tree-search agent, both well above the remaining agents; (2) our analysis suggests this pattern relates to improvement opportunity structure: greedy search tends to be more effective when opportunities are dense, while tree-search and evolutionary strategies tend to be more effective when opportunities are sparse; an adaptive agent built on this insight switches to broader exploration upon detecting improvement stagnation and outperforms the other six agents, lending initial support to this observation; and (3) process-level analysis reveals that early convergence and directionally focused exploration are significantly associated with final performance, while solution diversity and compute cost are not. Our benchmark is available at: https://github.com/qrzou/FML-bench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FML-Bench, a benchmark of 18 fundamental ML research tasks across 10 domains that isolates agent search strategy from execution infrastructure and supplies 12 process-level behavioral metrics. Evaluation of six representative agents shows that a simple greedy hill-climber nearly matches the best tree-search agent (both substantially above the rest), which the authors attribute to variation in improvement-opportunity density across tasks. An adaptive agent that switches to broader exploration upon detecting stagnation outperforms the original six, presented as lending support to the density hypothesis. Process-level analysis further links early convergence and directionally focused exploration to higher final performance.
Significance. If the separation of strategy from infrastructure holds and the opportunity-density account is substantiated, the work supplies a useful controlled testbed and concrete design guidance for AI research agents: complexity is not automatically advantageous, and simple adaptive switching can improve results. The open benchmark and process metrics are concrete assets that could support reproducible follow-up studies.
major comments (3)
- [Abstract and adaptive-agent section] Abstract and the section describing the adaptive agent: the policy is constructed by inspecting the six agents' results on the identical 18 tasks, yet its reported outperformance is offered as support for the dense/sparse opportunity-structure explanation. Because the rule was not pre-specified or tested on held-out tasks, the result is consistent with overfitting to the observed improvement statistics rather than an independent confirmation of the mechanism.
- [§3 and §5] §3 (Benchmark and task construction) and §5 (Empirical results): the central claim that performance differences are attributable to strategy rather than infrastructure requires explicit controls, statistical tests for the 'nearly matches' comparison, and evidence that the 18 tasks cleanly separate the two factors. The abstract supplies none of these details, leaving the attribution load-bearing claim under-supported.
- [Process-metrics subsection] Process-metrics analysis (likely §5.3 or associated table): the statements that early convergence and directionally focused exploration are 'significantly associated' with final performance must specify the exact statistical procedure, correction for multiple comparisons, and effect sizes. Without these, the reported associations cannot be evaluated for robustness.
minor comments (2)
- [Methods] The manuscript should clarify in the methods whether any of the 12 process metrics were used in designing the adaptive rule, to allow readers to assess the degree of data leakage.
- [Figures] Figure captions and axis labels for the opportunity-density plots should explicitly define how 'dense' versus 'sparse' is operationalized from the task data.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our results and strengthen the evidential basis for our claims. We respond to each major point below.
read point-by-point responses
-
Referee: [Abstract and adaptive-agent section] Abstract and the section describing the adaptive agent: the policy is constructed by inspecting the six agents' results on the identical 18 tasks, yet its reported outperformance is offered as support for the dense/sparse opportunity-structure explanation. Because the rule was not pre-specified or tested on held-out tasks, the result is consistent with overfitting to the observed improvement statistics rather than an independent confirmation of the mechanism.
Authors: We agree that the adaptive policy was derived post-hoc from the observed performance patterns on the same 18 tasks and therefore cannot be viewed as an independent, pre-registered confirmation. The manuscript already qualifies the result as 'lending initial support'; we will revise the abstract and §5 to state explicitly that the agent is an exploratory construction based on the empirical patterns and to frame the outperformance as suggestive evidence for the opportunity-density account rather than a confirmatory test. A held-out evaluation would require additional tasks, which lies beyond the current benchmark scope. revision: partial
-
Referee: [§3 and §5] §3 (Benchmark and task construction) and §5 (Empirical results): the central claim that performance differences are attributable to strategy rather than infrastructure requires explicit controls, statistical tests for the 'nearly matches' comparison, and evidence that the 18 tasks cleanly separate the two factors. The abstract supplies none of these details, leaving the attribution load-bearing claim under-supported.
Authors: Section 3 describes the standardized execution environment and identical code interface provided to all agents, which is the primary control isolating strategy. We will add (i) a concise statement of this isolation mechanism to the abstract, (ii) a short dedicated paragraph in §3 or §5 reiterating the controls, and (iii) statistical comparisons (paired Wilcoxon signed-rank tests with exact p-values) for the greedy vs. tree-search performance difference. These additions will make the attribution explicit without altering the experimental design. revision: yes
-
Referee: [Process-metrics subsection] Process-metrics analysis (likely §5.3 or associated table): the statements that early convergence and directionally focused exploration are 'significantly associated' with final performance must specify the exact statistical procedure, correction for multiple comparisons, and effect sizes. Without these, the reported associations cannot be evaluated for robustness.
Authors: We will revise the process-metrics subsection to report the precise procedure: Spearman rank correlations between each of the 12 metrics and final performance, with Bonferroni correction across the 12 tests, and accompanying effect sizes (ρ). If the original analysis used a different test, we will recompute and present the corrected results. revision: yes
Circularity Check
No significant circularity: purely empirical benchmark evaluation on fixed tasks.
full rationale
The paper conducts a controlled empirical comparison of six agent strategies plus one adaptive variant on 18 fixed ML research tasks, using 12 process metrics to attribute differences to search topology rather than infrastructure. All reported findings (greedy hill-climber matching tree search, opportunity-density correlation, and adaptive outperformance) are direct measurements or post-hoc constructions evaluated on the identical task set; no equations, derivations, parameter fits presented as independent predictions, or self-citations reduce any claim to its inputs by construction. The adaptive policy is transparently derived from the same data, but this is standard data-driven design in empirical agent studies and does not constitute circularity under the enumerated patterns. The work is therefore self-contained as a benchmark study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Machine bias: There’s software used across the country to predict future criminals
Julia Angwin, Jeff Larson, Surya Mattu, and Lauren Kirchner. Machine bias: There’s software used across the country to predict future criminals. and it’s biased against blacks.ProPublica, May 2016. URL https://www.propublica.org/article/machine-bias-risk-asses sments-in-criminal-sentencing
2016
-
[2]
Martin Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk mini- mization.arXiv preprint arXiv:1907.02893, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[3]
Barry Becker and Ronny Kohavi. Adult. UCI Machine Learning Repository, 1996. DOI: https://doi.org/10.24432/C5XW20
-
[4]
Rachel K. E. Bellamy, Kuntal Dey, Michael Hind, Samuel C. Hoffman, Stephanie Houde, Kalapriya Kannan, Pranay Lohia, Jacquelyn Martino, Sameep Mehta, Aleksandra Mojsilovic, Seema Nagar, Karthikeyan Natesan Ramamurthy, John Richards, Diptikalyan Saha, Prasanna Sattigeri, Moninder Singh, Kush R. Varshney, and Yunfeng Zhang. AI Fairness 360: An extensible too...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Representation learning: A review and new perspectives.IEEE transactions on pattern analysis and machine intelligence, 35(8): 1798–1828, 2013
Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: A review and new perspectives.IEEE transactions on pattern analysis and machine intelligence, 35(8): 1798–1828, 2013
2013
-
[6]
Fairlearn: A toolkit for assessing and improving fairness in ai
Sarah Bird, Miro Dudík, Richard Edgar, Brandon Horn, Roman Lutz, Vanessa Milan, Mehrnoosh Sameki, Hanna Wallach, and Kathleen Walker. Fairlearn: A toolkit for assessing and improving fairness in ai. 2020
2020
-
[7]
Eitan Borgnia, Jonas Geiping, Valeriia Cherepanova, Liam Fowl, Arjun Gupta, Amin Ghiasi, Furong Huang, Micah Goldblum, and Tom Goldstein. Dp-instahide: Provably defusing poi- soning and backdoor attacks with differentially private data augmentations.arXiv preprint arXiv:2103.02079, 2021
-
[8]
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, et al. Mle-bench: Evaluating machine learning agents on machine learning engineering.arXiv preprint arXiv:2410.07095, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Causalml: Python package for causal machine learning, 2020
Huigang Chen, Totte Harinen, Jeong-Yoon Lee, Mike Yung, and Zhenyu Zhao. Causalml: Python package for causal machine learning, 2020
2020
-
[10]
MARS: Modular Agent with Reflective Search for Automated AI Research
Jiefeng Chen, Bhavana Dalvi Mishra, Jaehyun Nam, Rui Meng, Tomas Pfister, and Jinsung Yoon. Mars: Modular agent with reflective search for automated ai research.arXiv preprint arXiv:2602.02660, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Morgan & Claypool Publishers, 2018
Zhiyuan Chen and Bing Liu.Lifelong machine learning. Morgan & Claypool Publishers, 2018
2018
-
[12]
International Conference on Learning Representations (ICLR) , year=
Ziru Chen, Shijie Chen, Yuting Ning, Qianheng Zhang, Boshi Wang, Botao Yu, Yifei Li, Zeyi Liao, Chen Wei, Zitong Lu, et al. Scienceagentbench: Toward rigorous assessment of language agents for data-driven scientific discovery.arXiv preprint arXiv:2410.05080, 2024
-
[13]
solo- learn: A library of self-supervised methods for visual representation learning.Journal of Machine Learning Research, 23(56):1–6, 2022
Victor Guilherme Turrisi Da Costa, Enrico Fini, Moin Nabi, Nicu Sebe, and Elisa Ricci. solo- learn: A library of self-supervised methods for visual representation learning.Journal of Machine Learning Research, 23(56):1–6, 2022
2022
-
[14]
The mnist database of handwritten digit images for machine learning research.IEEE Signal Processing Magazine, 29(6):141–142, 2012
Li Deng. The mnist database of handwritten digit images for machine learning research.IEEE Signal Processing Magazine, 29(6):141–142, 2012
2012
- [15]
-
[16]
In search of lost domain generaliza- tion,
Ishaan Gulrajani and David Lopez-Paz. In search of lost domain generalization.arXiv preprint arXiv:2007.01434, 2020. 10
-
[17]
GraphCodeBERT: Pre-training Code Representations with Data Flow
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, et al. Graphcodebert: Pre-training code representations with data flow.arXiv preprint arXiv:2009.08366, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[18]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020
2020
-
[19]
Bayesian nonparametric modeling for causal inference.Journal of Computa- tional and Graphical Statistics, 20(1):217–240, 2011
Jennifer L Hill. Bayesian nonparametric modeling for causal inference.Journal of Computa- tional and Graphical Statistics, 20(1):217–240, 2011
2011
-
[20]
arXiv preprint arXiv:2310.03302 , doi =
Qian Huang, Jian V ora, Percy Liang, and Jure Leskovec. Mlagentbench: Evaluating language agents on machine learning experimentation.arXiv preprint arXiv:2310.03302, 2023
-
[21]
AIDE: AI-Driven Exploration in the Space of Code
Zhengyao Jiang, Dominik Schmidt, Dhruv Srikanth, Dixing Xu, Ian Kaplan, Deniss Jacenko, and Yuxiang Wu. Aide: Ai-driven exploration in the space of code. 2025. URL https: //arxiv.org/abs/2502.13138
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Liqiang Jing, Zhehui Huang, Xiaoyang Wang, Wenlin Yao, Wenhao Yu, Kaixin Ma, Hongming Zhang, Xinya Du, and Dong Yu. Dsbench: How far are data science agents from becoming data science experts?arXiv preprint arXiv:2409.07703, 2024
-
[24]
autoresearch: Ai agents running research on single-gpu nanochat training automatically.https://github.com/karpathy/autoresearch, 2026
Andrej Karpathy. autoresearch: Ai agents running research on single-gpu nanochat training automatically.https://github.com/karpathy/autoresearch, 2026. GitHub repository
2026
-
[25]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
2009
-
[26]
LAB-Bench: Measuring Capabilities of Language Models for Biology Research
Jon M Laurent, Joseph D Janizek, Michael Ruzo, Michaela M Hinks, Michael J Hammer- ling, Siddharth Narayanan, Manvitha Ponnapati, Andrew D White, and Samuel G Rodriques. Lab-bench: Measuring capabilities of language models for biology research.arXiv preprint arXiv:2407.10362, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Abandoning objectives: Evolution through the search for novelty alone.Evolutionary computation, 19(2):189–223, 2011
Joel Lehman and Kenneth O Stanley. Abandoning objectives: Evolution through the search for novelty alone.Evolutionary computation, 19(2):189–223, 2011
2011
-
[28]
Trustworthy ai: From principles to practices.ACM Computing Surveys, 55(9):1–46, 2023
Bo Li, Peng Qi, Bo Liu, Shuai Di, Jingen Liu, Jiquan Pei, Jinfeng Yi, and Bowen Zhou. Trustworthy ai: From principles to practices.ACM Computing Surveys, 55(9):1–46, 2023
2023
-
[29]
arXiv preprint arXiv:2408.14033 , year=
Ruochen Li, Teerth Patel, Qingyun Wang, and Xinya Du. Mlr-copilot: Autonomous machine learning research based on large language models agents.arXiv preprint arXiv:2408.14033, 2024
-
[30]
Lightly: A python library for self-supervised learning on images
Lightly-AI. Lightly: A python library for self-supervised learning on images. https://gith ub.com/lightly-ai/lightly, 2025
2025
-
[31]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scien- tist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
TOFU: A Task of Fictitious Unlearning for LLMs
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary C Lipton, and J Zico Kolter. Tofu: A task of fictitious unlearning for llms.arXiv preprint arXiv:2401.06121, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Communication-efficient learning of deep networks from decentralized data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. InArtificial intelligence and statistics, pages 1273–1282. Pmlr, 2017
2017
-
[34]
A survey on bias and fairness in machine learning.ACM computing surveys (CSUR), 54(6):1–35, 2021
Ninareh Mehrabi, Fred Morstatter, Nripsuta Saxena, Kristina Lerman, and Aram Galstyan. A survey on bias and fairness in machine learning.ACM computing surveys (CSUR), 54(6):1–35, 2021. 11
2021
-
[35]
Illuminating search spaces by mapping elites
Jean-Baptiste Mouret and Jeff Clune. Illuminating search spaces by mapping elites.arXiv preprint arXiv:1504.04909, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[36]
Sasi Kumar Murakonda and Reza Shokri. Ml privacy meter: Aiding regulatory compliance by quantifying the privacy risks of machine learning.arXiv preprint arXiv:2007.09339, 2020
-
[37]
Maria-Irina Nicolae, Mathieu Sinn, Minh Ngoc Tran, Beat Buesser, Ambrish Rawat, Mar- tin Wistuba, Valentina Zantedeschi, Nathalie Baracaldo, Bryant Chen, Heiko Ludwig, et al. Adversarial robustness toolbox v1. 0.0.arXiv preprint arXiv:1807.01069, 2018
-
[38]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Harshith Padigela, Chintan Shah, and Dinkar Juyal. Ml-dev-bench: Comparative analysis of ai agents on ml development workflows.arXiv preprint arXiv:2502.00964, 2025
-
[40]
The seven tools of causal inference, with reflections on machine learning.Commu- nications of the ACM, 62(3):54–60, 2019
Judea Pearl. The seven tools of causal inference, with reflections on machine learning.Commu- nications of the ACM, 62(3):54–60, 2019
2019
-
[41]
Quality diversity: A new frontier for evolutionary computation.Frontiers in Robotics and AI, 3:40, 2016
Justin K Pugh, Lisa B Soros, and Kenneth O Stanley. Quality diversity: A new frontier for evolutionary computation.Frontiers in Robotics and AI, 3:40, 2016
2016
-
[42]
icarl: Incremental classifier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017
2001
-
[43]
Agent laboratory: Using llm agents as research assistants.Findings of the Association for Computational Linguistics: EMNLP 2025, pages 5977–6043, 2025
Samuel Schmidgall, Yusheng Su, Ze Wang, Ximeng Sun, Jialian Wu, Xiaodong Yu, Jiang Liu, Michael Moor, Zicheng Liu, and Emad Barsoum. Agent laboratory: Using llm agents as research assistants.Findings of the Association for Computational Linguistics: EMNLP 2025, pages 5977–6043, 2025
2025
-
[44]
Openevolve: an open-source evolutionary coding agent
Asankhaya Sharma. Openevolve: an open-source evolutionary coding agent. https://gith ub.com/algorithmicsuperintelligence/openevolve, 2025. GitHub repository
2025
-
[45]
Adapting neural networks for the estimation of treatment effects.Advances in neural information processing systems, 32, 2019
Claudia Shi, David Blei, and Victor Veitch. Adapting neural networks for the estimation of treatment effects.Advances in neural information processing systems, 32, 2019
2019
-
[46]
Easy few-shot learning: ready-to-use code and tutorial notebooks for few-shot image classification.https://github.com/sicara/easy-few-shot-learning, 2024
Sicara. Easy few-shot learning: ready-to-use code and tutorial notebooks for few-shot image classification.https://github.com/sicara/easy-few-shot-learning, 2024
2024
-
[47]
Prototypical networks for few-shot learning
Jake Snell, Kevin Swersky, and Richard Zemel. Prototypical networks for few-shot learning. Advances in neural information processing systems, 30, 2017
2017
-
[48]
Fixmatch: Simplifying semi- supervised learning with consistency and confidence.Advances in neural information processing systems, 33:596–608, 2020
Kihyuk Sohn, David Berthelot, Nicholas Carlini, Zizhao Zhang, Han Zhang, Colin A Raf- fel, Ekin Dogus Cubuk, Alexey Kurakin, and Chun-Liang Li. Fixmatch: Simplifying semi- supervised learning with consistency and confidence.Advances in neural information processing systems, 33:596–608, 2020
2020
-
[49]
arXiv preprint arXiv:2505.18705 , year=
Jiabin Tang, Lianghao Xia, Zhonghang Li, and Chao Huang. Ai-researcher: Autonomous scientific innovation.arXiv preprint arXiv:2505.18705, 2025
-
[50]
Edan Toledo, Karen Hambardzumyan, Martin Josifoski, Rishi Hazra, Nicolas Baldwin, Alexis Audran-Reiss, Michael Kuchnik, Despoina Magka, Minqi Jiang, Alisia Maria Lupidi, et al. Ai research agents for machine learning: Search, exploration, and generalization in mle-bench. arXiv preprint arXiv:2507.02554, 2025
-
[51]
Three types of incremental learning.Nature Machine Intelligence, 4:1185–1197, 2022
Gido M van de Ven, Tinne Tuytelaars, and Andreas S Tolias. Three types of incremental learning.Nature Machine Intelligence, 4:1185–1197, 2022
2022
-
[52]
Vapnik.Statistical Learning Theory
Vladimir N. Vapnik.Statistical Learning Theory. Wiley-Interscience, New York, 1998. 12
1998
-
[53]
Deep hashing network for unsupervised domain adaptation
Hemanth Venkateswara, Jose Eusebio, Shayok Chakraborty, and Sethuraman Panchanathan. Deep hashing network for unsupervised domain adaptation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5018–5027, 2017
2017
-
[54]
Matching networks for one shot learning.Advances in neural information processing systems, 29, 2016
Oriol Vinyals, Charles Blundell, Timothy Lillicrap, Daan Wierstra, et al. Matching networks for one shot learning.Advances in neural information processing systems, 29, 2016
2016
-
[55]
SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models
Xiaoxuan Wang, Ziniu Hu, Pan Lu, Yanqiao Zhu, Jieyu Zhang, Satyen Subramaniam, Arjun R Loomba, Shichang Zhang, Yizhou Sun, and Wei Wang. Scibench: Evaluating college-level scientific problem-solving abilities of large language models.arXiv preprint arXiv:2307.10635, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
Usb: A unified semi-supervised learning benchmark for classification.Advances in Neural Information Processing Systems, 35:3938–3961, 2022
Yidong Wang, Hao Chen, Yue Fan, Wang Sun, Ran Tao, Wenxin Hou, Renjie Wang, Linyi Yang, Zhi Zhou, Lan-Zhe Guo, et al. Usb: A unified semi-supervised learning benchmark for classification.Advances in Neural Information Processing Systems, 35:3938–3961, 2022
2022
-
[57]
Hjalmar Wijk, Tao Lin, Joel Becker, Sami Jawhar, Neev Parikh, Thomas Broadley, Lawrence Chan, Michael Chen, Josh Clymer, Jai Dhyani, et al. Re-bench: Evaluating frontier ai r&d capabilities of language model agents against human experts.arXiv preprint arXiv:2411.15114, 2024
-
[58]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search.arXiv preprint arXiv:2504.08066, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Yousefpour et al.Opacus: User-Friendly Differential Privacy Li- brary in PyTorch
Ashkan Yousefpour, Igor Shilov, Alexandre Sablayrolles, Davide Testuggine, Karthik Prasad, Mani Malek, John Nguyen, Sayan Ghosh, Akash Bharadwaj, Jessica Zhao, et al. Opacus: User-friendly differential privacy library in pytorch.arXiv preprint arXiv:2109.12298, 2021
-
[60]
Sergey Zagoruyko and Nikos Komodakis. Wide residual networks.arXiv preprint arXiv:1605.07146, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[61]
Barlow twins: Self- supervised learning via redundancy reduction
Jure Zbontar, Li Jing, Ishan Misra, Yann LeCun, and Stéphane Deny. Barlow twins: Self- supervised learning via redundancy reduction. InInternational conference on machine learning, pages 12310–12320. PMLR, 2021
2021
-
[62]
Continual learning through synaptic intelligence
Friedemann Zenke, Ben Poole, and Surya Ganguli. Continual learning through synaptic intelligence. InInternational conference on machine learning, pages 3987–3995. PMLR, 2017
2017
-
[63]
Pfllib: Personalized federated learning algorithm library.arXiv preprint arXiv:2312.04992, 2023
Jianqing Zhang, Yang Liu, Yang Hua, Hao Wang, Tao Song, Zhengui Xue, Ruhui Ma, and Jian Cao. Pfllib: Personalized federated learning algorithm library.arXiv preprint arXiv:2312.04992, 2023
-
[64]
Jingyang Zhang, Jingkang Yang, Pengyun Wang, Haoqi Wang, Yueqian Lin, Haoran Zhang, Yiyou Sun, Xuefeng Du, Yixuan Li, Ziwei Liu, et al. Openood v1. 5: Enhanced benchmark for out-of-distribution detection.arXiv preprint arXiv:2306.09301, 2023
-
[65]
Keli Zhang, Shengyu Zhu, Marcus Kalander, Ignavier Ng, Junjian Ye, Zhitang Chen, and Lujia Pan. gcastle: A python toolbox for causal discovery.arXiv preprint arXiv:2111.15155, 2021
-
[66]
Dags with no tears: Continuous optimization for structure learning.Advances in neural information processing systems, 31, 2018
Xun Zheng, Bryon Aragam, Pradeep K Ravikumar, and Eric P Xing. Dags with no tears: Continuous optimization for structure learning.Advances in neural information processing systems, 31, 2018
2018
-
[67]
Da-Wei Zhou, Fu-Yun Wang, Han-Jia Ye, and De-Chuan Zhan. Pycil: a python toolbox for class-incremental learning, 2023. 13 A Task descriptions This appendix gives a short description of each of the 18 research tasks in FML-bench, one paragraph per task. For every task we identify the dataset, the baseline algorithm, the agent’s optimization target, and the...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.