GraphMind: From Operational Traces to Self-Evolving Workflow Automation
Pith reviewed 2026-05-20 12:02 UTC · model grok-4.3
The pith
GraphMind builds action-centric workflow graphs from past resolution traces and lets them evolve through execution feedback to automate incident investigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
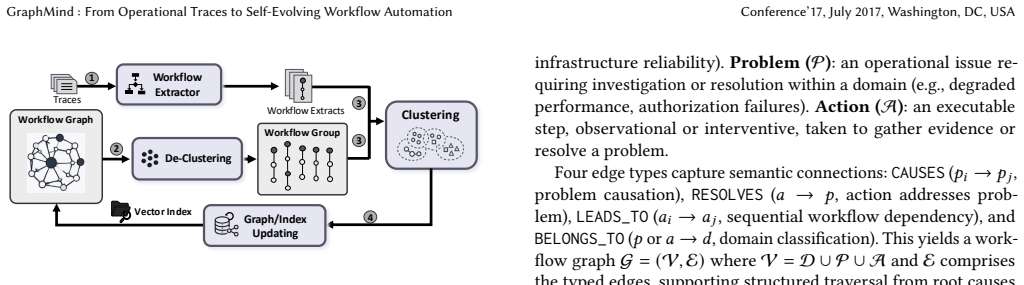
GraphMind constructs, executes, and evolves action-centric workflow graphs without human effort through an offline extraction pipeline that builds graphs from resolution traces, an online multi-agent traversal engine that navigates and executes them, and an Adaptive Traversal Reinforcement layer that reinforces successful paths while decaying stale elements.
What carries the argument
Action-centric workflow graphs, built offline from traces and traversed online by a multi-agent engine, with Adaptive Traversal Reinforcement updating the graph from execution results.
If this is right
- Operational workflows can run with far less ongoing human input once the initial graph is built from traces.
- Diagnostic performance improves over simple retrieval of similar past traces in reach, accuracy, and speed.
- The graph adapts to shifting conditions through direct feedback from its own executions rather than external updates.
- Production deployment across multiple services is feasible at the scale of real cloud operations.
Where Pith is reading between the lines
- Similar trace-to-graph pipelines could be tried in other high-volume operational domains such as IT support tickets or supply-chain adjustments.
- Over time the reinforced graph might capture patterns that human-written procedures miss because it draws directly from observed outcomes.
- Testing the system on entirely novel problems outside the initial trace distribution would reveal how far the evolution mechanism extends coverage.
Load-bearing premise
The offline pipeline accurately extracts causal relationships and structured workflow graphs from human resolution traces without introducing significant noise or missing key context.
What would settle it
A clear drop in mitigation success or a rise in required human corrections when the system encounters new incident types absent from the original traces would show the extraction and evolution steps are not sufficient.
Figures






read the original abstract
Complex operational workflows coordinating personnel, tools, and information are central to system operations, yet end-to-end automation remains challenging due to extensive human input requirements and limited ability to adapt over time. We present GraphMind, a system that constructs, executes, and evolves action-centric workflow graphs with minimal human effort. The system operates in three phases. First, a scalable offline pipeline extracts structured workflow graphs from large volumes of human resolution traces, capturing problems, actions, and their causal relationships. Second, an online multi-agent traversal engine navigates the graph to dynamically construct and execute workflows, combining graph-guided retrieval with LLM-driven reasoning at each step. Third, Adaptive Traversal Reinforcement (ATR) reinforces successful traversal paths, enabling execution-informed graph adaptation. GraphMind has been deployed across four production cloud database services for incident investigation. Evaluated on 93 held-out incidents and validated via blind expert review, the system outperforms an Agentic Summary-RAG baseline in mitigation reach, hallucination rate, and diagnostic throughput while requiring 8x less retrieval context. The ATR layer reduces hallucination rate by 26%, demonstrating that workflow graphs can learn from execution feedback. A 12-week field study confirms practical value: 97% of scored conversations yield actionable results within interactive latency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents GraphMind, an end-to-end system that constructs, executes, and evolves action-centric workflow graphs from human resolution traces for automating complex operational workflows. It operates via three phases: an offline pipeline extracting structured graphs capturing problems, actions, and causal relationships; an online multi-agent traversal engine combining graph-guided retrieval with LLM reasoning; and Adaptive Traversal Reinforcement (ATR) for reinforcing successful paths and enabling self-optimization. The system is reported to be deployed across four production cloud database services for incident investigation, substantially outperforming a Trace-RAG baseline in mitigation reach, groundedness, and diagnostic throughput, with a 4.95/5 blind expert review score and further gains from ATR.
Significance. If the extraction accuracy and evaluation results hold, the work could meaningfully advance self-evolving automation in enterprise IT operations by minimizing human inputs and enabling adaptation to changing conditions. The production deployment across multiple services and the closed-loop ATR mechanism represent practical strengths with potential for broader impact in AI-driven workflow systems. However, the absence of methodological details currently limits the assessed significance.
major comments (2)
- [Abstract] Abstract: The abstract reports strong production results, outperformance over Trace-RAG, and a 4.95/5 expert score but provides no details on evaluation methodology, baselines, statistical significance, trace processing, or dataset scale. This is load-bearing for the central claims, as it prevents verification of whether the gains are robust or influenced by post-hoc choices.
- [Offline pipeline] Offline pipeline description: The system's foundation is the offline extraction of causal relationships and structured workflow graphs from human resolution traces. No quantitative metrics on extraction accuracy, error analysis, ablation studies on graph quality, or handling of noise/missing context are provided, which directly affects confidence in the online traversal, mitigation reach, and ATR-based evolution claims.
minor comments (1)
- [Abstract] Abstract: A high-level figure illustrating the three-phase flow (offline extraction to online traversal to ATR) would improve clarity of the system architecture.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the practical value of GraphMind's production deployment and closed-loop ATR mechanism. We address each major comment below and describe the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract reports strong production results, outperformance over Trace-RAG, and a 4.95/5 expert score but provides no details on evaluation methodology, baselines, statistical significance, trace processing, or dataset scale. This is load-bearing for the central claims, as it prevents verification of whether the gains are robust or influenced by post-hoc choices.
Authors: We agree that the abstract, due to length constraints, presents results at a high level. The full manuscript contains the requested details on evaluation methodology, dataset scale, Trace-RAG baseline construction, and expert review protocol in the Experiments section. To improve accessibility, we will revise the abstract to incorporate a concise statement on evaluation setup, dataset size, and statistical reporting while preserving the high-level focus. revision: yes
-
Referee: [Offline pipeline] Offline pipeline description: The system's foundation is the offline extraction of causal relationships and structured workflow graphs from human resolution traces. No quantitative metrics on extraction accuracy, error analysis, ablation studies on graph quality, or handling of noise/missing context are provided, which directly affects confidence in the online traversal, mitigation reach, and ATR-based evolution claims.
Authors: The referee is correct that the current description of the offline pipeline lacks quantitative validation. While the pipeline architecture and causal extraction process are detailed in the manuscript, we did not report accuracy metrics or ablations. In the revised manuscript we will add a dedicated evaluation subsection reporting precision/recall on a held-out annotated trace set, an error analysis for noise and missing context, and an ablation on graph quality's impact on downstream traversal performance. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper describes a three-phase pipeline: (1) offline extraction of structured workflow graphs from human resolution traces, (2) online multi-agent traversal combining graph-guided retrieval with LLM reasoning, and (3) ATR that reinforces successful paths and decays stale elements using execution-derived feedback. Evaluation metrics (mitigation reach, groundedness, diagnostic throughput, 4.95/5 expert review) are reported against a Trace-RAG baseline on production data from four deployed services. No equations, fitted parameters, or self-citations are presented that reduce any claimed prediction or result to the input traces by construction. The reinforcement loop explicitly draws from new execution outcomes rather than re-using the original trace data for both construction and scoring. The central claims therefore rest on externally observable deployment performance and comparative evaluation rather than tautological re-labeling of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human resolution traces contain extractable problems, actions, and causal relationships that form accurate workflow graphs.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Adaptive Traversal Reinforcement (ATR) reinforces successful traversal paths and decays stale elements... inspired by Ant Colony Optimization
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
workflow graph G=(V,E) with typed nodes (domains, problems, actions) and edges (CAUSES, RESOLVES, LEADS_TO)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.