DADF: A Distribution-Aware Debiasing Framework for Watch-Time Regression in Recommender Systems
Pith reviewed 2026-06-30 18:52 UTC · model grok-4.3
The pith
A second-stage multiplicative correction framework fixes residual overestimation of short views and underestimation of long views in watch-time regression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DADF performs second-stage multiplicative residual correction on top of an existing watch-time predictor. It combines a dynamic distribution-aware transformation for stabilizing long-tailed correction targets, a debias-factor-aware module for modeling heterogeneous residual patterns using inference-time observable factors especially video duration, and a multi-label-aware module that exploits auxiliary prediction signals from engagement heads. On public benchmarks and a large-scale industrial ranking system this yields consistent gains in pointwise accuracy and ranking quality.
What carries the argument
Second-stage multiplicative residual correction performed by DADF on an existing watch-time predictor, using distribution-aware transformation and modules driven by inference-time factors.
If this is right
- Consistently reduces mean absolute error across datasets and backbones.
- Delivers an aggregated 2.07 percentage-point gain in ranking quality over the production baseline.
- Produces statistically significant online lifts of 0.649 percent in average time spent per device and 0.656 percent in total app time.
- Supplies a plug-in solution that works with different first-stage models without retraining them.
Where Pith is reading between the lines
- The same residual-correction pattern could be tested on other long-tailed continuous targets such as dwell time or session length in recommendation.
- Because the method operates only on inference-time observables, it may allow debiasing when the first-stage model is a black box or too costly to modify.
- Further experiments on non-video recommendation domains would show whether the three-module design generalizes beyond short-video watch time.
Load-bearing premise
Residual errors in watch-time prediction can be effectively modeled and corrected using inference-time observable factors like video duration and auxiliary engagement predictions without introducing new biases or requiring changes to the first-stage model.
What would settle it
Applying DADF to held-out data or a production system and observing no reduction in MAE or no gain in ranking metrics relative to the unmodified baseline predictor.
Figures


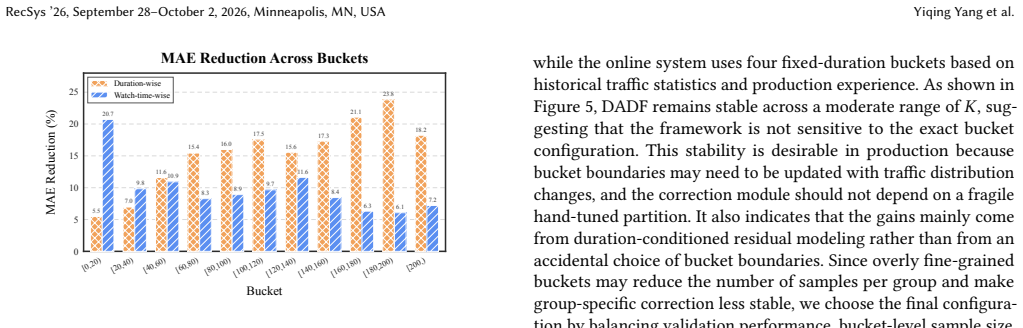
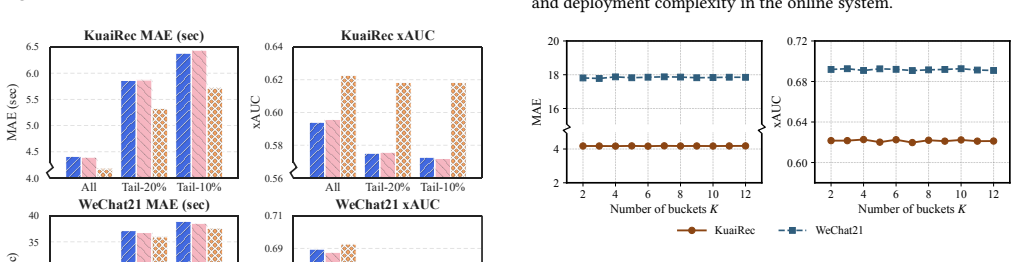


read the original abstract
Watch-time prediction is a central regression task in short-video recommender systems, where labels are highly long-tailed and residual errors vary systematically across observed watch-time regions. In practice, a model may appear globally calibrated while still overestimating short views and underestimating long views, because opposite errors cancel out in aggregate. Existing methods mainly improve the first-stage watch-time predictor, but often leave such residual distributional bias insufficiently corrected. We propose DADF, a distribution-aware debiasing framework for watch-time regression. Instead of replacing a deployed predictor, DADF performs second-stage multiplicative residual correction on top of it. DADF combines three complementary designs: a dynamic distribution-aware transformation for stabilizing long-tailed correction targets, a debias-factor-aware module for modeling heterogeneous residual patterns using inference-time observable factors, especially video duration, and a multi-label-aware module that exploits auxiliary prediction signals from engagement heads. We evaluate DADF on public short-video benchmarks and a large-scale industrial ranking system. DADF consistently improves both pointwise accuracy and ranking quality across datasets and backbones. In the industrial setting, it achieves an aggregated 2.07 percentage-point ranking-quality gain over the production baseline, consistently reduces MAE, and yields statistically significant online lifts of 0.649% in average time spent per device and 0.656% in total app time. These results demonstrate that DADF effectively mitigates local calibration bias and provides a practical plug-in solution for debiasing long-tailed continuous targets. The source code is available at https://github.com/liuzhao09/DADF.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DADF, a distribution-aware debiasing framework for watch-time regression in short-video recommender systems. Rather than replacing the first-stage predictor, it applies a second-stage multiplicative residual correction combining a dynamic distribution-aware transformation for long-tailed targets, a debias-factor-aware module that models heterogeneous residuals using inference-time observables (especially video duration), and a multi-label-aware module exploiting auxiliary engagement predictions. Evaluations on public short-video benchmarks and a large-scale industrial ranking system report consistent gains in pointwise accuracy and ranking quality (including an aggregated 2.07 percentage-point improvement over the production baseline), reduced MAE, and statistically significant online lifts of 0.649% in average time spent per device and 0.656% in total app time. Source code is released at https://github.com/liuzhao09/DADF.
Significance. If the reported gains prove robust, DADF supplies a practical plug-in correction for local calibration bias in long-tailed continuous targets that global metrics overlook. This is valuable for industrial short-video systems where watch-time is a core signal and first-stage models are already deployed. The public code release is a clear strength that supports reproducibility and community verification.
major comments (2)
- [Experiments / Industrial evaluation] The central empirical claim of a 2.07 pp aggregated ranking-quality gain (and the online lifts) rests on the second-stage correction successfully mitigating residual distributional bias without introducing new biases. An explicit ablation isolating the contribution of the debias-factor-aware module (particularly video duration) versus the other two modules would be needed to confirm this does not simply trade one form of bias for another.
- [Method / Ablation study] The multi-label-aware module exploits auxiliary engagement heads; however, the manuscript does not quantify how much of the reported MAE and ranking gains are attributable to these auxiliary signals versus the distribution-aware transformation alone. This matters because the central claim is that the three designs are complementary.
minor comments (3)
- [Abstract and Experiments] Clarify the exact definition of 'aggregated' ranking-quality gain and the aggregation procedure across backbones and datasets.
- [Method] The description of the dynamic distribution-aware transformation would benefit from an explicit equation or pseudocode showing how the long-tailed correction target is stabilized.
- [Industrial evaluation] Online A/B test details (test duration, number of devices/users, variance estimates) should be added to support the statistical significance claims for the 0.649% and 0.656% lifts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We address each major comment below and will incorporate the requested ablations to strengthen the empirical validation of module contributions.
read point-by-point responses
-
Referee: [Experiments / Industrial evaluation] The central empirical claim of a 2.07 pp aggregated ranking-quality gain (and the online lifts) rests on the second-stage correction successfully mitigating residual distributional bias without introducing new biases. An explicit ablation isolating the contribution of the debias-factor-aware module (particularly video duration) versus the other two modules would be needed to confirm this does not simply trade one form of bias for another.
Authors: We agree that an explicit ablation isolating the debias-factor-aware module is necessary to substantiate that the observed gains arise from complementary debiasing rather than bias trade-offs. In the revised manuscript we will add a dedicated ablation table that evaluates (i) the full DADF, (ii) DADF without the debias-factor-aware module, and (iii) variants that retain only the distribution-aware transformation. All variants will be assessed on the same industrial ranking metrics and MAE to directly address the concern. revision: yes
-
Referee: [Method / Ablation study] The multi-label-aware module exploits auxiliary engagement heads; however, the manuscript does not quantify how much of the reported MAE and ranking gains are attributable to these auxiliary signals versus the distribution-aware transformation alone. This matters because the central claim is that the three designs are complementary.
Authors: We acknowledge that the current ablations do not isolate the incremental value of the multi-label-aware module from the distribution-aware transformation. In the revision we will include new experiments that compare (a) a baseline using only the dynamic distribution-aware transformation against (b) the same baseline augmented with the multi-label-aware module, reporting delta MAE and ranking-quality improvements on both public benchmarks and the industrial dataset. This will quantify the auxiliary-signal contribution and support the complementarity claim. revision: yes
Circularity Check
No significant circularity; empirical framework with independent evaluations
full rationale
The paper introduces DADF as a second-stage multiplicative correction framework with three explicit modules (dynamic distribution-aware transformation, debias-factor-aware module using video duration and auxiliary signals, multi-label-aware module). No derivation chain, uniqueness theorem, or first-principles result is claimed; all reported gains (MAE reduction, ranking-quality lift, online A/B metrics) are presented as outcomes of empirical evaluation on public benchmarks and a production system. The method is a plug-in on top of an existing predictor and does not redefine its inputs or predictions by construction. No self-citation load-bearing steps or ansatz smuggling appear in the provided text. This is a standard empirical systems paper whose central claims rest on external data rather than internal definitional reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Narayanaswamy Balakrishnan and Asit P. Basu. 1996.Exponential Distribution: Theory, Methods and Applications
1996
-
[2]
Bartlett
Maurice S. Bartlett. 1936. The Square Root Transformation in Analysis of Variance. Supplement to the Journal of the Royal Statistical Society3, 1 (1936), 68–78
1936
-
[3]
Bartlett
Maurice S. Bartlett. 1947. The Use of Transformations.Biometrics3, 1 (1947), 39–52
1947
-
[4]
Christopher M. Bishop. 1994.Mixture Density Networks. Technical Report. Aston University
1994
-
[5]
Stephen Bonner and Flavian Vasile. 2018. Causal Embeddings for Recommen- dation. InProceedings of the 12th ACM Conference on Recommender Systems. 104–112
2018
-
[6]
George E. P. Box and David R. Cox. 1964. An Analysis of Transformations.Journal of the Royal Statistical Society: Series B (Methodological)26, 2 (1964), 211–252
1964
-
[7]
Qingpeng Cai, Shuchang Liu, Xueliang Wang, Tianyou Zuo, Wentao Xie, Bin Yang, Dong Zheng, Peng Jiang, and Kun Gai. 2023. Reinforcing User Retention in a Billion Scale Short Video Recommender System. InCompanion Proceedings of the ACM Web Conference 2023. 421–426
2023
-
[8]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep Neural Networks for YouTube Recommendations. InProceedings of the 10th ACM Conference on Recommender Systems. 191–198
2016
-
[9]
Naihua Duan. 1983. Smearing Estimate: A Nonparametric Retransformation Method.J. Amer. Statist. Assoc.78, 383 (1983), 605–610
1983
-
[10]
Silvia Ferrari and Francisco Cribari-Neto. 2004. Beta Regression for Modelling Rates and Proportions.Journal of Applied Statistics31, 7 (2004), 799–815
2004
-
[11]
D. J. Finney. 1941. On the Distribution of a Variate Whose Logarithm Is Normally Distributed.Supplement to the Journal of the Royal Statistical Society7, 2 (1941), 155–161
1941
-
[12]
Chongming Gao, Shijun Li, Wenqiang Lei, Jiawei Chen, Biao Li, Peng Jiang, Xiangnan He, Jiaxin Mao, and Tat-Seng Chua. 2022. KuaiRec: A Fully-observed Dataset and Insights for Evaluating Recommender Systems. InProceedings of the 31st ACM International Conference on Information and Knowledge Management. 540–550
2022
-
[13]
Chongming Gao, Shijun Li, Yuan Zhang, Jiawei Chen, Biao Li, Wenqiang Lei, Peng Jiang, and Xiangnan He. 2022. KuaiRand: An Unbiased Sequential Rec- ommendation Dataset with Randomly Exposed Videos. InProceedings of the 31st ACM International Conference on Information and Knowledge Management. 3953–3957
2022
-
[14]
Xudong Gong, Qinlin Feng, Yuan Zhang, Jiangling Qin, Weijie Ding, Biao Li, Peng Jiang, and Kun Gai. 2022. Real-Time Short Video Recommendation on Mobile Devices. InProceedings of the 31st ACM International Conference on Information and Knowledge Management. 3103–3112
2022
-
[15]
Jie Hu, Li Shen, and Gang Sun. 2018. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 7132–7141
2018
-
[16]
Koch and Gary M
Roy W. Koch and Gary M. Smillie. 1986. Bias in Hydrologic Prediction Using Log-Transformed Regression Models.Journal of the American Water Resources Association22, 5 (1986), 717–723
1986
-
[17]
Ron Kohavi, Alex Deng, Brian Frasca, Toby Walker, Ya Xu, and Nils Pohlmann
-
[18]
InProceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining
Online Controlled Experiments at Large Scale. InProceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 1168–1176
- [19]
-
[20]
Xiao Lin, Xiaokai Chen, Linfeng Song, Jingwei Liu, Biao Li, and Peng Jiang. 2023. Tree Based Progressive Regression Model for Watch-Time Prediction in Short- Video Recommendation. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4497–4506
2023
-
[21]
Jiaqi Ma, Zhe Zhao, Xinyang Yi, Jilin Chen, Lichan Hong, and Ed H. Chi. 2018. Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture- of-Experts. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 1930–1939
2018
-
[22]
Xiao Ma, Liqin Zhao, Guan Huang, Zhi Wang, Zelin Hu, Xiaoqiang Zhu, and Kun Gai. 2018. Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate. InProceedings of the 41st International ACM SIGIR Conference on Research and Development in Information Retrieval. 1137–1140
2018
-
[23]
McLachlan, Sharon X
Geoffrey J. McLachlan, Sharon X. Lee, and Suren I. Rathnayake. 2019. Finite Mixture Models.Annual Review of Statistics and Its Application6 (2019), 355–378
2019
-
[24]
Mean Absolute Error. 2016. Mean Absolute Error. Retrieved September 19, 2016, 14
2016
- [25]
-
[26]
Michael C. Newman. 1993. Regression Analysis of Log-Transformed Data: Sta- tistical Bias and Its Correction.Environmental Toxicology and Chemistry12, 6 (1993), 1129–1133
1993
-
[27]
Jerzy Neyman and Elizabeth L. Scott. 1960. Correction for Bias Introduced by a Transformation of Variables.The Annals of Mathematical Statistics31, 3 (1960), 643–655
1960
-
[28]
Vincent Moshi Ouma, Samuel Musili Mwalili, and Anthony Wanjoya Kiberia
-
[29]
Poisson Inverse Gaussian Regression Model for Infectious Disease Count Data.American Journal of Theoretical and Applied Statistics5, 5 (2016), 326–333
2016
-
[30]
Yunzhu Pan, Chen Gao, Jianxin Chang, Yanan Niu, Yang Song, Kun Gai, Depeng Jin, and Yong Li. 2023. Understanding and Modeling Passive-Negative Feedback for Short-Video Sequential Recommendation. InProceedings of the 17th ACM Conference on Recommender Systems. 540–550
2023
-
[31]
George Papamakarios, Eric Nalisnick, Danilo Jimenez Rezende, Shakir Mohamed, and Balaji Lakshminarayanan. 2021. Normalizing Flows for Probabilistic Model- ing and Inference.Journal of Machine Learning Research22, 57 (2021), 1–64
2021
-
[32]
Yuta Saito, Suguru Yaginuma, Yuta Nishino, Kazuhide Nakata, and Keiichi Sakata
-
[33]
InProceedings of the 13th International Conference on Web Search and Data Mining
Unbiased Recommender Learning from Missing-Not-at-Random Implicit Feedback. InProceedings of the 13th International Conference on Web Search and Data Mining. 501–509
-
[34]
Remi M. Sakia. 1992. The Box-Cox Transformation Technique: A Review.Journal of the Royal Statistical Society: Series D (The Statistician)41, 2 (1992), 169–178
1992
-
[35]
Hiroshi Shono. 2008. Application of the Tweedie Distribution to Zero-Catch Data in CPUE Analysis.Fisheries Research93, 1–2 (2008), 154–162
2008
-
[36]
Stow, Kenneth H
Craig A. Stow, Kenneth H. Reckhow, and Song S. Qian. 2006. A Bayesian Approach to Retransformation Bias in Transformed Regression.Ecology87, 6 (2006), 1472– 1477
2006
-
[37]
Strimbu, Alexandru Amarioarei, John Paul McTague, and Mihaela M
Bogdan M. Strimbu, Alexandru Amarioarei, John Paul McTague, and Mihaela M. Paun. 2018. A Posteriori Bias Correction of Three Models Used for Environmental Reporting.Forestry: An International Journal of Forest Research91, 1 (2018), 49–62
2018
-
[38]
Jie Sun, Zhaoying Ding, Xiaoshuang Chen, Qi Chen, Yincheng Wang, Kaiqiao Zhan, and Ben Wang. 2024. CREAD: A Classification-Restoration Framework with Error Adaptive Discretization for Watch Time Prediction in Video Recom- mender Systems.Proceedings of the AAAI Conference on Artificial Intelligence38, 8 (2024), 9027–9034
2024
-
[39]
Diane Tang, Ashish Agarwal, Deirdre O’Brien, and Mike Meyer. 2010. Over- lapping Experiment Infrastructure: More, Better, Faster Experimentation. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 17–26
2010
-
[40]
Hongyan Tang, Junning Liu, Ming Zhao, and Xudong Gong. 2020. Progres- sive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations. InProceedings of the 14th ACM Conference on Recommender Systems. 269–278
2020
-
[41]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. InAdvances in Neural Information Processing Systems, Vol. 30. 5998– 6008
2017
-
[42]
Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & Cross Network for Ad Click Predictions. InProceedings of the ADKDD’17. 1–7
2017
-
[43]
Tianxin Wang, Jingwu Chen, Fuzhen Zhuang, Leyu Lin, Feng Xia, Lihuan Du, and Qing He. 2020. Capturing Attraction Distribution: Sequential Attentive Network for Dwell Time Prediction. InECAI 2020. 529–536
2020
-
[44]
Wenjie Wang, Fuli Feng, Xiangnan He, and Tat-Seng Chua. 2021. Deconfounded Recommendation for Alleviating Bias Amplification. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1717–1725
2021
-
[45]
Yunpeng Weng, Xing Tang, Zhenhao Xu, Fuyuan Lyu, Dugang Liu, Zexu Sun, and Xiuqiang He. 2024. OptDist: Learning Optimal Distribution for Customer Lifetime Value Prediction. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 2523–2533
2024
-
[46]
Siqi Wu, Marian-Andrei Rizoiu, and Lexing Xie. 2018. Beyond Views: Measuring and Predicting Engagement in Online Videos.Proceedings of the International AAAI Conference on Web and Social Media12, 1 (2018), 434–442
2018
-
[47]
Dongbo Xi, Zhen Chen, Peng Yan, Yao Zhang, Yongchun Zhu, Fuzhen Zhuang, and Yu Chen. 2021. Modeling the Sequential Dependence among Audience Multi- Step Conversions with Multi-Task Learning in Targeted Display Advertising. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3745–3755
2021
-
[48]
Xing Yi, Liangjie Hong, Erheng Zhong, Nanthan Nan Liu, and Suju Rajan. 2014. Beyond Clicks: Dwell Time for Personalization. InProceedings of the 8th ACM Conference on Recommender Systems. 113–120
2014
- [49]
-
[50]
Ruohan Zhan, Changhua Pei, Qiang Su, Jianfeng Wen, Xueliang Wang, Guanyu Mu, Dong Zheng, Peng Jiang, and Kun Gai. 2022. Deconfounding Duration Bias in Watch-Time Prediction for Video Recommendation. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4472–4481
2022
-
[51]
Haiyuan Zhao, Guohao Cai, Jieming Zhu, Zhenhua Dong, Jun Xu, and Ji-Rong Wen. 2024. Counteracting Duration Bias in Video Recommendation via Coun- terfactual Watch Time. InProceedings of the 30th ACM SIGKDD Conference on RecSys ’26, September 28–October 2, 2026, Minneapolis, MN, USA Yiqing Yang et al. Knowledge Discovery and Data Mining. 4455–4466
2024
-
[52]
Haiyuan Zhao, Lei Zhang, Jun Xu, Guohao Cai, Zhenhua Dong, and Ji-Rong Wen
-
[53]
InProceedings of the 17th ACM Conference on Recommender Systems
Uncovering User Interest from Biased and Noised Watch Time in Video Recommendation. InProceedings of the 17th ACM Conference on Recommender Systems. 528–539
-
[54]
Xu Zhao, RuiBo Ma, Jiaqi Chen, Weiqi Zhao, Ping Yang, and Yao Hu. 2025. Multi-Granularity Distribution Modeling for Video Watch Time Prediction via Exponential-Gaussian Mixture Network. InProceedings of the 19th ACM Confer- ence on Recommender Systems. 309–318
2025
-
[55]
Yu Zheng, Chen Gao, Jingtao Ding, Lingling Yi, Depeng Jin, Yong Li, and Meng Wang. 2022. DVR: Micro-Video Recommendation Optimizing Watch-Time-Gain under Duration Bias. InProceedings of the 30th ACM International Conference on Multimedia. 334–345
2022
-
[56]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep Interest Network for Click- Through Rate Prediction. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 1059–1068
2018
-
[57]
Xinhua Zhuang, Yan Huang, Kannappan Palaniappan, and Yunxin Zhao. 1996. Gaussian Mixture Density Modeling, Decomposition, and Applications.IEEE Transactions on Image Processing5, 9 (1996), 1293–1302. A Proofs A.1 Long-Tailedness Inheritance of the Multiplicative Correction Factor We provide a simple theoretical argument showing that the ratio- style multi...
1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.