Rad-VLSM: A Cross-Modal Framework with Semantics-Assisted Prompting for Medical Segmentation and Diagnosis
Pith reviewed 2026-05-20 11:55 UTC · model grok-4.3
The pith
Semantic guidance first locates lesions in medical images then uses the resulting masks to ground diagnosis in visual evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
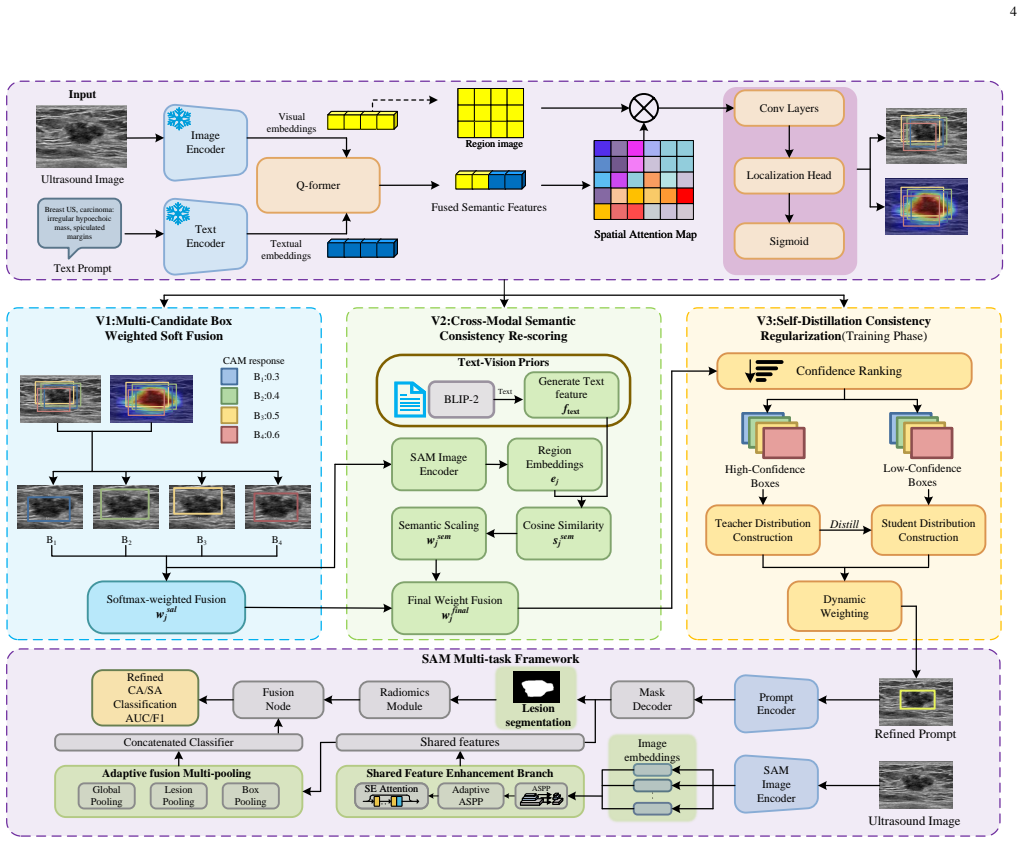
Rad-VLSM is a cross-modal framework that first applies semantic guidance to identify lesion-related candidate regions and convert them into box prompts, then feeds the prompts into a multitask network that aggregates candidates for stable segmentation, and finally uses the predicted masks as spatial priors in a visual-radiomics fusion head for diagnosis.
What carries the argument
Semantics-assisted prompting that turns language descriptions into box prompts for guiding lesion segmentation and supplying spatial priors to diagnosis.
If this is right
- Segmentation accuracy rises because multi-candidate aggregation stabilizes prompts against single-region errors.
- Diagnosis becomes traceable to actual lesion masks rather than relying on direct text-to-image mappings.
- The model handles background distractions and artifacts better by restricting attention to semantically selected regions.
- Performance holds across both private clinical breast ultrasound data and public benchmarks.
Where Pith is reading between the lines
- The same separation of semantic localization from prediction could be tested on CT or MRI datasets to check cross-modality robustness.
- Clinicians might gain trust from seeing explicit lesion masks that justify the diagnostic output.
- Extending the radiomics fusion to include temporal sequences could address dynamic imaging tasks.
Load-bearing premise
Semantic descriptions can reliably steer identification of the correct lesion regions even when medical images contain acoustic artifacts and surrounding tissues.
What would settle it
A set of ultrasound images with known lesions where the semantic guidance step consistently selects incorrect or empty candidate regions, causing downstream segmentation and diagnosis to degrade.
Figures



read the original abstract
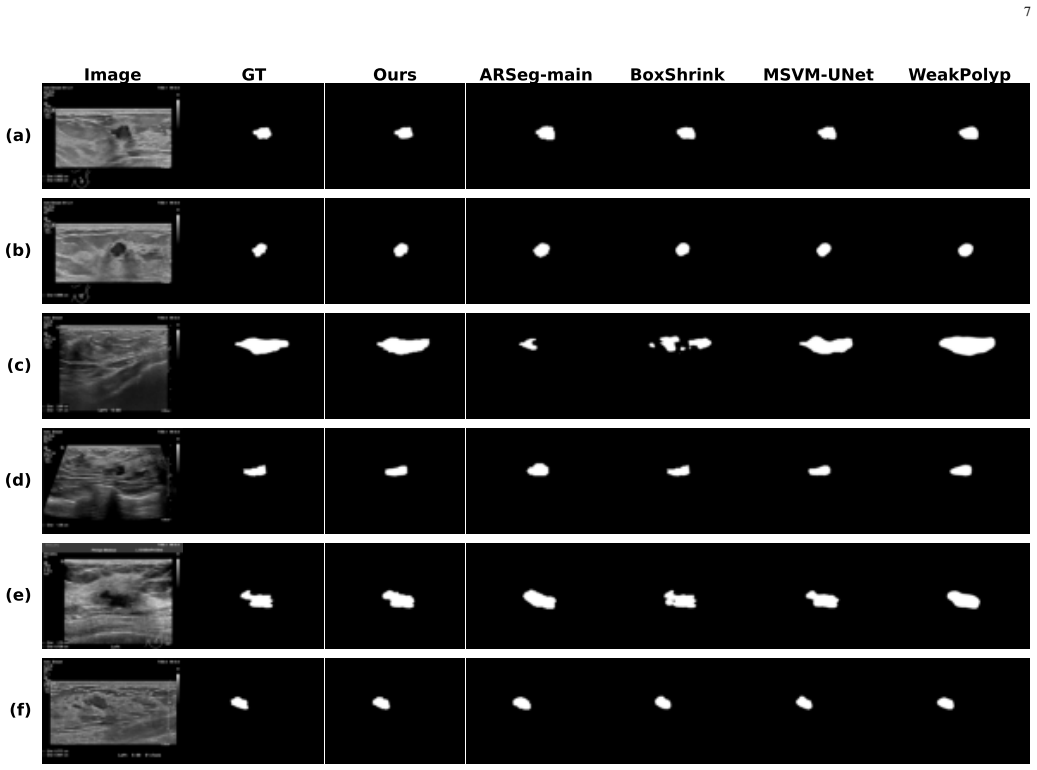
Medical image segmentation is more clinically valuable when it supports diagnosis rather than merely producing lesion masks. However, diagnostically relevant lesion cues are often subtle and localized, while existing models may be distracted by background tissues, acoustic artifacts, and irrelevant visual correlations. To address this problem, we propose Rad-VLSM, a two-stage cross-modal framework for semantics-assisted lesion focusing, robust segmentation, and visually grounded diagnosis. In the first stage, a BLIP-2-based vision-language alignment module identifies lesion-related candidate regions under semantic guidance and converts them into box prompts. In the second stage, these prompts are fed into a SAM-based multitask network, where a multi-candidate region aggregation strategy improves prompt stability and guides lesion segmentation. The predicted masks are then used as spatial priors for diagnosis, and a visual-radiomics fusion head integrates lesion-aware visual features with selected radiomics descriptors. By using semantic information for localization rather than direct prediction, Rad-VLSM reduces text-to-diagnosis dependence and grounds diagnosis in lesion-level evidence. Experiments on a private clinical breast ultrasound dataset and public benchmarks show that Rad-VLSM achieves strong segmentation and diagnostic performance with favorable generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Rad-VLSM, a two-stage cross-modal framework for medical image segmentation and diagnosis. Stage 1 employs a BLIP-2 vision-language alignment module to identify lesion-related candidate regions under semantic guidance and convert them to box prompts. Stage 2 feeds these prompts into a SAM-based multitask network that applies multi-candidate region aggregation for stable segmentation; the resulting masks serve as spatial priors for a visual-radiomics fusion head that integrates lesion-aware features with radiomics descriptors. The central claim is that semantic guidance for localization (rather than direct text-to-diagnosis) reduces dependence on text prediction and grounds diagnosis in lesion-level evidence. Experiments are reported on a private clinical breast ultrasound dataset and public benchmarks, with claims of strong segmentation and diagnostic performance plus favorable generalization.
Significance. If the localization step proves reliable, the framework offers a concrete way to make segmentation outputs more clinically actionable by linking them directly to diagnostic reasoning in artifact-prone modalities such as ultrasound. The separation of semantic prompting from final diagnosis could improve robustness and interpretability compared with end-to-end text-to-diagnosis models.
major comments (2)
- [Methods (first stage)] Methods, first-stage BLIP-2 module: no standalone quantitative metrics (IoU, precision, or failure rate of generated box prompts) are reported for the vision-language alignment step on the private breast ultrasound set. Because the central claim that semantic guidance grounds diagnosis in lesion-level evidence depends on this module reliably identifying lesion-related regions despite acoustic artifacts and background tissue, the absence of isolated validation leaves the source of reported gains ambiguous.
- [Experiments] Experiments section: overall segmentation and diagnosis metrics are presented, yet no ablation isolates the contribution of the semantic box prompts versus the SAM stage or radiomics fusion alone. Without such controls it is difficult to confirm that performance gains arise from the claimed semantics-assisted localization rather than from the downstream components.
minor comments (2)
- [Abstract] Abstract: the phrase 'strong segmentation and diagnostic performance' is used without any numerical values, dataset sizes, or baseline comparisons, which reduces immediate assessability of the claims.
- [Methods (second stage)] Notation: the term 'multi-candidate region aggregation strategy' is introduced without a clear equation or pseudocode definition; adding a concise formal description would improve reproducibility.
Simulated Author's Rebuttal
We sincerely thank the referee for the constructive feedback and the recommendation for major revision. We have carefully reviewed the comments on validation of the first-stage module and the need for ablations. Our responses below indicate the specific revisions we will make to strengthen the manuscript while preserving its core contributions.
read point-by-point responses
-
Referee: Methods, first-stage BLIP-2 module: no standalone quantitative metrics (IoU, precision, or failure rate of generated box prompts) are reported for the vision-language alignment step on the private breast ultrasound set. Because the central claim that semantic guidance grounds diagnosis in lesion-level evidence depends on this module reliably identifying lesion-related regions despite acoustic artifacts and background tissue, the absence of isolated validation leaves the source of reported gains ambiguous.
Authors: We agree that isolated quantitative metrics for the BLIP-2 vision-language alignment step would better substantiate the reliability of the semantic box prompts. In the revised manuscript we will add a dedicated evaluation subsection reporting IoU, precision, recall, and failure rates of the generated box prompts on the private breast ultrasound dataset, together with qualitative examples illustrating robustness to acoustic artifacts. These additions will directly address the concern that the source of performance gains remains ambiguous. revision: yes
-
Referee: Experiments section: overall segmentation and diagnosis metrics are presented, yet no ablation isolates the contribution of the semantic box prompts versus the SAM stage or radiomics fusion alone. Without such controls it is difficult to confirm that performance gains arise from the claimed semantics-assisted localization rather than from the downstream components.
Authors: We acknowledge the value of component-wise ablations. The revised manuscript will include new ablation experiments that isolate the semantic box prompts by comparing the full Rad-VLSM against (i) a SAM-only baseline with grid or random prompts, (ii) the model without multi-candidate region aggregation, and (iii) the model without the radiomics fusion head. These controls will quantify the incremental benefit of semantics-assisted localization for both segmentation stability and diagnostic accuracy. revision: yes
Circularity Check
No circularity in framework architecture or claims
full rationale
The manuscript presents an applied two-stage vision-language framework (BLIP-2 semantic localization feeding SAM-based segmentation and radiomics fusion) without any equations, derivations, or parameter-fitting steps that could reduce outputs to inputs by construction. Claims about semantic guidance grounding diagnosis rest on architectural choices and reported experimental results on private and public datasets rather than self-definitional loops or self-citation chains. No load-bearing uniqueness theorems or ansatzes imported from prior author work appear in the provided text. This is the expected non-finding for a methods paper whose core contribution is an engineering pipeline rather than a closed-form mathematical result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inInternational Conference on Medical image computing and computer-assisted intervention, pp. 234– 241, Springer, 2015
work page 2015
-
[2]
3d u-net: learning dense volumetric segmentation from sparse anno- tation,
¨O. C ¸ ic ¸ek, A. Abdulkadir, S. S. Lienkamp, T. Brox, and O. Ronneberger, “3d u-net: learning dense volumetric segmentation from sparse anno- tation,” inInternational conference on medical image computing and computer-assisted intervention, pp. 424–432, Springer, 2016
work page 2016
-
[3]
nnu-net: a self-configuring method for deep learning- based biomedical image segmentation,
F. Isenseeet al., “nnu-net: a self-configuring method for deep learning- based biomedical image segmentation,”Nature Methods, vol. 18, pp. 203–211, 2021
work page 2021
-
[4]
J. Chen, J. Mei, X. Li, Y . Lu, Q. Yu, Q. Wei, X. Luo, Y . Xie, E. Adeli, Y . Wang,et al., “Transunet: Rethinking the u-net architecture design for medical image segmentation through the lens of transformers,”Medical Image Analysis, vol. 97, p. 103280, 2024
work page 2024
-
[5]
A. Kirillovet al., “Segment anything,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 4015–4026, 2023
work page 2023
-
[6]
Segment anything in medical images,
J. Maet al., “Segment anything in medical images,”Nature Communi- cations, vol. 15, no. 1, p. 654, 2024
work page 2024
-
[7]
Medical phrase grounding with region-phrase context contrastive alignment,
Z. Chen, Y . Zhou, A. Tran, J. Zhao, L. Wan, G. S. K. Ooi, L. T.- E. Cheng, C. H. Thng, X. Xu, Y . Liu, and H. Fu, “Medical phrase grounding with region-phrase context contrastive alignment,” inInterna- tional Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), pp. 371–381, 2023
work page 2023
-
[8]
Uncertainty-aware medical diagnostic phrase identification and grounding,
K. Zou, Y . Bai, B. Liu, Y . Chen, Z. Chen, Y . Zhou, X. Yuan, M. Wang, X. Shen, X. Cao,et al., “Uncertainty-aware medical diagnostic phrase identification and grounding,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[9]
Explainable ai in medical imaging: An overview for clinical practitioners,
K. Boryset al., “Explainable ai in medical imaging: An overview for clinical practitioners,”Radiology: Artificial Intelligence, vol. 5, no. 1, p. e220066, 2023
work page 2023
-
[10]
M. Yahyatabar, P. Jouvet, and F. Cheriet, “Joint classification and segmentation for an interpretable diagnosis of acute respiratory distress syndrome from chest x-rays,”Journal of Medical Imaging, vol. 10, no. 5, pp. 054504–054504, 2023
work page 2023
-
[11]
Multitask deep learning for segmentation and classifica- tion of primary bone tumors on radiographs,
C. E. von Schacky, N. J. Wilhelm, V . S. Sch ¨afer, Y . Leonhardt, F. G. Gassert, S. C. Foreman, F. T. Gassert, M. Jung, P. M. Jungmann, M. F. Russe,et al., “Multitask deep learning for segmentation and classifica- tion of primary bone tumors on radiographs,”Radiology, vol. 301, no. 2, pp. 398–406, 2021
work page 2021
-
[12]
Multi-task deep learning for medical image computing and analysis: A review,
Y . Zhao, X. Wang, T. Che, G. Bao, and S. Li, “Multi-task deep learning for medical image computing and analysis: A review,”Computers in Biology and Medicine, vol. 153, p. 106496, 2023
work page 2023
-
[13]
Methods for the segmentation and classification of breast ultrasound images: a review,
A. E. Ilesanmi, U. Chaumrattanakul, and S. S. Makhanov, “Methods for the segmentation and classification of breast ultrasound images: a review,”Journal of Ultrasound, vol. 24, no. 4, pp. 367–382, 2021. 13
work page 2021
-
[14]
Frequency- aware interaction network for ultrasound image segmentation,
D. Wang, T. Zhou, Y . Zhang, S. Gao, and J. Yang, “Frequency- aware interaction network for ultrasound image segmentation,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 7, pp. 7020–7032, 2024
work page 2024
-
[15]
Trustworthy breast ultrasound image semantic segmentation based on fuzzy uncertainty reduction,
K. Huang, Y . Zhang, H.-D. Cheng, and P. Xing, “Trustworthy breast ultrasound image semantic segmentation based on fuzzy uncertainty reduction,” inHealthcare, vol. 10, p. 2480, MDPI, 2022
work page 2022
-
[16]
Explaining a deep learning based breast ultrasound im- age classifier with saliency maps,
M. Byraet al., “Explaining a deep learning based breast ultrasound im- age classifier with saliency maps,”Scientific Reports, vol. 12, p. 12363, 2022
work page 2022
-
[17]
I.-N. A. Nastase, S. Moldovanu, K. C. Biswas, and L. Moraru, “Role of inter-and extra-lesion tissue, transfer learning, and fine-tuning in the robust classification of breast lesions,”Scientific Reports, vol. 14, no. 1, p. 22754, 2024
work page 2024
-
[18]
Segment anything model for medical image analysis: an experimental study,
M. A. Mazurowskiet al., “Segment anything model for medical image analysis: an experimental study,”Medical Image Analysis, vol. 89, p. 102918, 2023
work page 2023
-
[19]
Medsam-u: Uncertainty-guided auto multi-prompt adaptation for reliable medsam,
N. Zhou, K. Zou, K. Ren, M. Luo, L. He, M. Wang, Y . Chen, Y . Zhang, H. Chen, and H. Fu, “Medsam-u: Uncertainty-guided auto multi-prompt adaptation for reliable medsam,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 36, no. 3, pp. 3768–3781, 2026
work page 2026
-
[20]
Cross-hierarchical decoding with sam for semi-supervised medical image segmentation,
H. Chi, M. Liu, J. Wang, X. Gao, G. Luo, B. Zhang, and W. Liu, “Cross-hierarchical decoding with sam for semi-supervised medical image segmentation,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 36, no. 3, pp. 3742–3753, 2026
work page 2026
-
[21]
De-lightsam: Modality-decoupled lightweight sam for generalizable medical segmentation,
Q. Xu, J. Li, X. He, C. Li, F. B. Tesema, W. Duan, Z. Chen, R. Qu, J. M. Garibaldi, and C. W. Chen, “De-lightsam: Modality-decoupled lightweight sam for generalizable medical segmentation,”IEEE Trans- actions on Circuits and Systems for Video Technology, vol. 36, no. 3, pp. 3782–3794, 2026
work page 2026
-
[22]
Adaptation follow human attention: Gaze-assisted medical segment anything model,
R. Ge, R. Li, C. Wang, Y . Liu, H. Zhu, J.-L. Coatrieux, D. Zhang, J. Lu, Y . Chen, S. Li,et al., “Adaptation follow human attention: Gaze-assisted medical segment anything model,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
work page 2025
-
[23]
Masksam: Auto-prompt sam with mask classification for volumetric medical image segmentation,
B. Xie, H. Tang, B. Duan, D. Cai, Y . Yan, and G. Agam, “Masksam: Auto-prompt sam with mask classification for volumetric medical image segmentation,” inProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pp. 24423–24433, 2025
work page 2025
-
[24]
Robust box prompt based sam for medical image segmentation,
Y . Huang, X. Yang, H. Zhou, Y . Cao, H. Dou, F. Dong, and D. Ni, “Robust box prompt based sam for medical image segmentation,” in International Workshop on Machine Learning in Medical Imaging, pp. 1–11, Springer, 2024
work page 2024
-
[25]
Sam-clip: Merging vision foundation models towards semantic and spatial under- standing,
H. Wang, P. K. A. Vasu, F. Faghri, R. Vemulapalli, M. Farajtabar, S. Mehta, M. Rastegari, O. Tuzel, and H. Pouransari, “Sam-clip: Merging vision foundation models towards semantic and spatial under- standing,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3635–3647, 2024
work page 2024
-
[26]
Vision-language models in medical image analysis: From simple fusion to general large models,
X. Li, L. Li, Y . Jiang, H. Wang, X. Qiao, T. Feng, H. Luo, and Y . Zhao, “Vision-language models in medical image analysis: From simple fusion to general large models,”Information Fusion, vol. 118, p. 102995, 2025
work page 2025
-
[27]
Integrating language into medical visual recog- nition and reasoning: A survey,
Y . Lu and A. Wang, “Integrating language into medical visual recog- nition and reasoning: A survey,”Medical image analysis, vol. 102, p. 103514, 2025
work page 2025
-
[28]
X. Huang, Y . Zhang,et al., “Gloria: A multimodal global-local represen- tation learning framework for label-efficient medical image recognition,” inProceedings of ICCV, pp. 3942–3951, 2021
work page 2021
-
[29]
Medklip: Medical knowledge enhanced language-image pre-training for x-ray diagnosis,
C. Wu, X. Zhang, Y . Zhang, Y . Wang, and W. Xie, “Medklip: Medical knowledge enhanced language-image pre-training for x-ray diagnosis,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 21372–21383, 2023
work page 2023
-
[30]
C. Ong Ly, B. Unnikrishnan, T. Tadic, T. Patel, J. Duhamel, S. Kandel, Y . Moayedi, M. Brudno, A. Hope, H. Ross,et al., “Shortcut learning in medical ai hinders generalization: method for estimating ai model generalization without external data,”NPJ digital medicine, vol. 7, no. 1, p. 124, 2024
work page 2024
-
[31]
Localizing before answering: A benchmark for grounded medical visual question answering,
D. Nguyen, M. K. Ho, H. Ta, T. T. Nguyen, Q. Chen, K. Rav, Q. D. Dang, S. Ramchandre, S. L. Phung, Z. Liao,et al., “Localizing before answering: A benchmark for grounded medical visual question answering,” inThirty-Fourth International Joint Conference on Artificial Intelligence (IJCAI-25), International Joint Conferences on Artificial Intelligence Organi...
work page 2025
-
[32]
Visual cues in the interpretation of medical images,
H. L. Kundel, “Visual cues in the interpretation of medical images,” Journal of Clinical Neurophysiology, vol. 7, no. 4, pp. 472–483, 1990
work page 1990
-
[33]
M. E. Mayerhoefer, A. Materka, G. Langs, I. H ¨aggstr¨om, P. Szczypi´nski, P. Gibbs, and G. Cook, “Introduction to radiomics,”Journal of Nuclear Medicine, vol. 61, no. 4, pp. 488–495, 2020
work page 2020
-
[34]
Radiomics and digital image texture analysis in oncology,
A. Litvin, D. Burkin, A. Kropinov, and F. Paramzin, “Radiomics and digital image texture analysis in oncology,”Modern Technologies in Medicine, vol. 13, no. 2, pp. 97–104, 2021
work page 2021
-
[35]
Radiomics: extracting more information from medical images using advanced feature analysis,
P. Lambinet al., “Radiomics: extracting more information from medical images using advanced feature analysis,”European Journal of Cancer, 2012
work page 2012
-
[36]
Radiomics knowledge-driven deep learning framework for breast can- cer ultrasound video diagnosis,
D. Guo, Z. Xue, D. Chen, C. Lu, J. Fu, J. Yuan, and Y . Huang, “Radiomics knowledge-driven deep learning framework for breast can- cer ultrasound video diagnosis,”Expert Systems with Applications, p. 129800, 2025
work page 2025
-
[37]
H. Yeet al., “Integrated model combining deep learning, radiomics and clinical features for breast ultrasound diagnosis,”Medical Physics, 2025
work page 2025
-
[38]
A dual-stage deep learning framework for breast ultrasound image segmentation and classification,
P. Bruno, M. Macr `ı, and C. Dodaro, “A dual-stage deep learning framework for breast ultrasound image segmentation and classification,” Journal of Medical Systems, vol. 49, no. 1, p. 162, 2025
work page 2025
-
[39]
Joint retina segmentation and classification for early glaucoma diagnosis,
J. Wang, Z. Wang, F. Li, G. Qu, Y . Qiao, H. Lv, and X. Zhang, “Joint retina segmentation and classification for early glaucoma diagnosis,” Biomedical optics express, vol. 10, no. 5, pp. 2639–2656, 2019
work page 2019
-
[40]
M. Li, W. Gong, P. Yan, X. Li, Y . Jiang, H. Luo, H. Zhou, and S. Yin, “Joint lesion detection and classification of breast ultrasound video via a clinical knowledge-aware framework,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 1, pp. 45–61, 2024
work page 2024
-
[41]
Y . Zhou, H. Chen, Y . Li, Q. Liu, X. Xu, S. Wang, P.-T. Yap, and D. Shen, “Multi-task learning for segmentation and classification of tumors in 3d automated breast ultrasound images,”Medical image analysis, vol. 70, p. 101918, 2021
work page 2021
-
[42]
A unified multi-task learning model for simultaneous skin lesion segmentation and diagnosis,
M. A. Al-Masniet al., “A unified multi-task learning model for simultaneous skin lesion segmentation and diagnosis,”Bioengineering, vol. 11, no. 11, p. 1173, 2024
work page 2024
-
[43]
Y . Luet al., “Automatic joint segmentation and classification of breast ultrasound images using object contextual attention,”Frontiers in On- cology, vol. 15, p. 1567577, 2025
work page 2025
-
[44]
A multi-task frame- work for breast cancer segmentation and classification in ultrasound imaging,
C. Aumente-Maestro, J. D ´ıez, and B. Remeseiro, “A multi-task frame- work for breast cancer segmentation and classification in ultrasound imaging,”Computer methods and programs in biomedicine, vol. 260, p. 108540, 2025
work page 2025
-
[45]
G. Dai, D. Dai, C. Wang, Q. Tang, M. Hamilton, H. Chen, and Y . Zhang, “Multi-task learning network for medical image analysis guided by lesion regions and spatial relationships of tissues,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
work page 2025
-
[46]
J. S. Ryu, H. Kang, Y . Chu, and S. Yang, “Vision-language foundation models for medical imaging: a review of current practices and inno- vations,”Biomedical Engineering Letters, vol. 15, no. 5, pp. 809–830, 2025
work page 2025
-
[47]
Vision-language models for medical report generation and visual question answering: A review,
R. Hartsock and G. Rasool, “Vision-language models for medical report generation and visual question answering: A review,”Biomedical Signal Processing and Control, vol. 90, p. 105825, 2024
work page 2024
-
[48]
G. Reale-Nosei, E. Amador-Dom ´ınguez, and E. Serrano, “From vision to text: A comprehensive review of natural image captioning in medical diagnosis and radiology report generation,”Medical Image Analysis, vol. 97, p. 103264, 2024
work page 2024
-
[49]
Multimodal large language models in medical imaging: current state and future directions,
Y . Nam, D. Y . Kim, S. Kyung, J. Seo, J. M. Song, J. Kwon, J. Kim, W. Jo, H. Park, J. Sung,et al., “Multimodal large language models in medical imaging: current state and future directions,”Korean Journal of Radiology, vol. 26, no. 10, p. 900, 2025
work page 2025
-
[50]
S. Zhanget al., “Biomedclip: A multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs,”arXiv preprint arXiv:2303.00915, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Z. Chenet al., “Fine-grained image-text alignment in medical imaging enables explainable cyclic image-report generation,” inProceedings of ACL, 2024
work page 2024
-
[52]
Y . Gao and D.-W. Ding, “Fadiaframe: Improving fairness and accuracy of deep learning-based diagnosis for dermatological lesions via a novel post-processing framework,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 36, no. 2, pp. 2259–2272, 2026
work page 2026
-
[53]
D. Muhammad and M. Bendechache, “Unveiling the black box: A systematic review of explainable artificial intelligence in medical image analysis,”Computational and structural biotechnology journal, vol. 24, pp. 542–560, 2024
work page 2024
-
[54]
Assessing the trustworthiness of saliency maps for localizing abnormalities in medical imaging,
N. Arun, N. Gaw, P. Singh, K. Chang, M. Aggarwal, B. Chen, K. Hoebel, S. Gupta, J. Patel, M. Gidwani,et al., “Assessing the trustworthiness of saliency maps for localizing abnormalities in medical imaging,” Radiology: Artificial Intelligence, vol. 3, no. 6, p. e200267, 2021
work page 2021
-
[55]
Revisiting the trustworthiness of saliency methods in radiology ai,
J. Zhang, H. Chao, G. Dasegowda, G. Wang, M. K. Kalra, and P. Yan, “Revisiting the trustworthiness of saliency methods in radiology ai,” Radiology: Artificial Intelligence, vol. 6, no. 1, p. e220221, 2023. 14
work page 2023
-
[56]
Radiomics in clinical radiology: advances, challenges, and future directions,
K. Linton-Reid, M. Chen, M. B. Martell, J. M. Posma, and E. O. Aboagye, “Radiomics in clinical radiology: advances, challenges, and future directions,”Clinical Radiology, p. 107165, 2025
work page 2025
-
[57]
P. P. Ray, “A review on explainable artificial intelligence in radiomics: State-of-the-art tools, prospective use cases, challenges and future direc- tions,”European Journal of Radiology Artificial Intelligence, p. 100069, 2025
work page 2025
-
[58]
X. Yanget al., “Deep learning radiomics on grayscale ultrasound images assists in diagnosing benign and malignant breast lesions,”Scientific Reports, vol. 14, p. 83347, 2024
work page 2024
-
[59]
D. Gutman, N. C. Codella, E. Celebi, B. Helba, M. Marchetti, N. Mishra, and A. Halpern, “Skin lesion analysis toward melanoma detection: A challenge at the international symposium on biomedical imaging (isbi) 2016, hosted by the international skin imaging collaboration (isic),” arXiv preprint arXiv:1605.01397, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[60]
N. Codella, V . Rotemberg, P. Tschandl, M. E. Celebi, S. Dusza, D. Gutman, B. Helba, A. Kalloo, K. Liopyris, M. Marchetti,et al., “Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic),”arXiv preprint arXiv:1902.03368, 2019
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[61]
Dataset of breast ultrasound images,
W. Al-Dhabyani, M. Gomaa, H. Khaled, and A. Fahmy, “Dataset of breast ultrasound images,”Data in brief, vol. 28, p. 104863, 2020
work page 2020
-
[62]
J. Bernal, F. J. S ´anchez, G. Fern ´andez-Esparrach, D. Gil, C. Rodr ´ıguez, and F. Vilari ˜no, “Wm-dova maps for accurate polyp highlighting in colonoscopy: Validation vs. saliency maps from physicians,”Comput- erized medical imaging and graphics, vol. 43, pp. 99–111, 2015
work page 2015
-
[63]
Automated polyp detection in colonoscopy videos using shape and context information,
N. Tajbakhsh, S. R. Gurudu, and J. Liang, “Automated polyp detection in colonoscopy videos using shape and context information,”IEEE transactions on medical imaging, vol. 35, no. 2, pp. 630–644, 2015
work page 2015
-
[64]
Toward embedded detection of polyps in wce images for early diagnosis of colorectal cancer,
J. Silva, A. Histace, O. Romain, X. Dray, and B. Granado, “Toward embedded detection of polyps in wce images for early diagnosis of colorectal cancer,”International journal of computer assisted radiology and surgery, vol. 9, no. 2, pp. 283–293, 2014
work page 2014
-
[65]
Kvasir-seg: A segmented polyp dataset,
D. Jha, P. H. Smedsrud, M. A. Riegler, P. Halvorsen, T. De Lange, D. Johansen, and H. D. Johansen, “Kvasir-seg: A segmented polyp dataset,” inInternational conference on multimedia modeling, pp. 451– 462, Springer, 2019
work page 2019
-
[66]
A multi- centre polyp detection and segmentation dataset for generalisability assessment,
S. Ali, D. Jha, N. Ghatwary, S. Realdon, R. Cannizzaro, O. E. Salem, D. Lamarque, C. Daul, M. A. Riegler, K. V . Anonsen,et al., “A multi- centre polyp detection and segmentation dataset for generalisability assessment,”Scientific Data, vol. 10, no. 1, p. 75, 2023
work page 2023
-
[67]
S. Ali, N. Ghatwary, D. Jha, E. Isik-Polat, G. Polat, C. Yang, W. Li, A. Galdran, M.- ´A. G. Ballester, V . Thambawita,et al., “Assessing generalisability of deep learning-based polyp detection and segmenta- tion methods through a computer vision challenge,”Scientific Reports, vol. 14, no. 1, p. 2032, 2024
work page 2032
-
[68]
S. Ali, M. Dmitrieva, N. Ghatwary, S. Bano, G. Polat, A. Temizel, A. Krenzer, A. Hekalo, Y . B. Guo, B. Matuszewski,et al., “Deep learn- ing for detection and segmentation of artefact and disease instances in gastrointestinal endoscopy,”Medical image analysis, vol. 70, p. 102002, 2021
work page 2021
-
[69]
M. Buda, A. Saha, and M. A. Mazurowski, “Association of genomic subtypes of lower-grade gliomas with shape features automatically extracted by a deep learning algorithm,”Computers in biology and medicine, vol. 109, pp. 218–225, 2019
work page 2019
-
[70]
Simtxtseg: Weakly-supervised medical image segmentation with simple text cues,
Y . Xie, T. Zhou, Y . Zhou, and G. Chen, “Simtxtseg: Weakly-supervised medical image segmentation with simple text cues,” inInternational Conference on Medical Image Computing and Computer-Assisted Inter- vention, pp. 634–644, Springer, 2024
work page 2024
-
[71]
Boxshrink: From bounding boxes to segmentation masks,
M. Gr ¨oger, V . Borisov, and G. Kasneci, “Boxshrink: From bounding boxes to segmentation masks,” inWorkshop on Medical Image Learning with Limited and Noisy Data, pp. 65–75, Springer, 2022
work page 2022
-
[72]
Microscopic-mamba: revealing the secrets of microscopic images with just 4m parameters,
S. Zou, Z. Zhang, Y . Zou, and G. Gao, “Microscopic-mamba: revealing the secrets of microscopic images with just 4m parameters,”arXiv preprint arXiv:2409.07896, 2024
-
[73]
Medmamba: Vision mamba for medical image classification,
Y . Yue and Z. Li, “Medmamba: Vision mamba for medical image classification,”arXiv preprint arXiv:2403.03849, 2024
-
[74]
Diffmic: Dual-guidance diffusion network for medical image classi- fication,
Y . Yang, H. Fu, A. I. Aviles-Rivero, C.-B. Sch ¨onlieb, and L. Zhu, “Diffmic: Dual-guidance diffusion network for medical image classi- fication,” inInternational conference on medical image computing and computer-assisted intervention, pp. 95–105, Springer, 2023
work page 2023
-
[75]
Miafex: an attention-based feature extraction method for medical image classification,
O. Ramos-Soto, J. Ramos-Frutos, E. Perez-Zarate, D. Oliva, and S. E. Balderas-Mata, “Miafex: an attention-based feature extraction method for medical image classification,”Knowledge-Based Systems, p. 114468, 2025
work page 2025
-
[76]
X. Zhang, Z. Xiao, J. Ma, X. Wu, J. Zhao, S. Zhang, R. Li, Y . Pan, and J. Liu, “Adaptive dual-axis style-based recalibration network with class-wise statistics loss for imbalanced medical image classification,” IEEE Transactions on Image Processing, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.