Dual-Channel Tensor Neural Networks: Finite-Sample Theory and Conformal Structure Selection
Pith reviewed 2026-05-20 07:16 UTC · model grok-4.3
The pith
A dual-channel neural network decomposes each tensor into low-rank core plus sparse refinement for finite-sample valid structure selection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose the Dual-Channel Tensor Neural Network (DC-TNN) that decomposes each tensor input into a low-rank core and a sparse refinement and processes the two components through coupled neural channels. The framework accommodates CP, Tucker, and tensor-train cores. Non-asymptotic risk bounds are established that decompose into network approximation, core estimation, and refinement-selection terms, with effective dimension determined jointly by core rank and refinement sparsity. A structure-aware conformal ROC procedure calibrates within the core-refinement latent space to produce ROC and AUC confidence bands with finite-sample, distribution-free coverage, and a conformal structure selector,
What carries the argument
The dual-channel decomposition into low-rank core and sparse refinement, which separates global structure from local detail and permits conformal calibration directly in the reduced latent space.
If this is right
- Risk bounds depend on the joint dimension of core rank and refinement sparsity instead of the full ambient tensor size.
- The conformal ROC procedure supplies finite-sample distribution-free bands around ROC curves and AUC values.
- The conformal structure selector returns a decomposition (CP, Tucker, or tensor-train) with guaranteed finite-sample validity.
- Simulations and a protein-structure dataset exhibit competitive prediction accuracy together with reliable recovery of the underlying tensor structure.
Where Pith is reading between the lines
- The latent-space calibration may allow reliable model choice with smaller sample sizes than cross-validation when tensors exhibit approximate low-rank plus sparse structure.
- The same core-refinement split could be applied to other multiway data such as video volumes or spatiotemporal graphs to obtain valid uncertainty bands.
- The approach points toward a general template for marrying low-rank tensor models with neural networks while retaining distribution-free inference guarantees.
Load-bearing premise
Tensor inputs admit an effective low-rank core plus sparse refinement decomposition whose joint dimension governs risk, and conformal calibration performed inside that decomposed space automatically inherits distribution-free finite-sample coverage.
What would settle it
If repeated trials on fresh tensor data show that the empirical coverage of the conformal AUC bands falls below the nominal 1-alpha level for a decomposition whose core-refinement split is misspecified, the finite-sample guarantee is refuted.
Figures


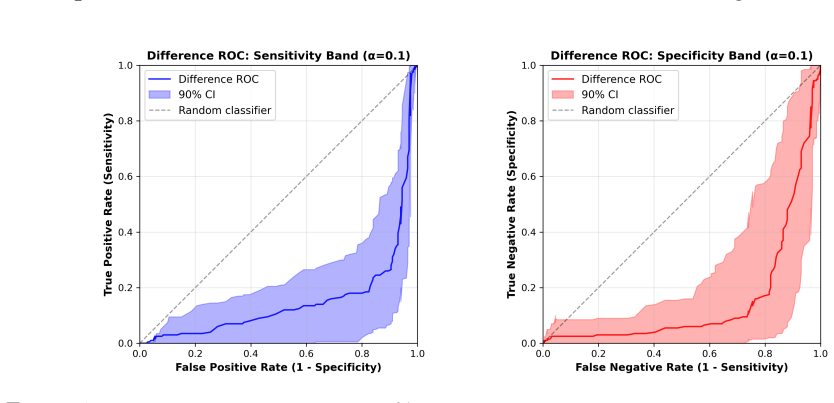

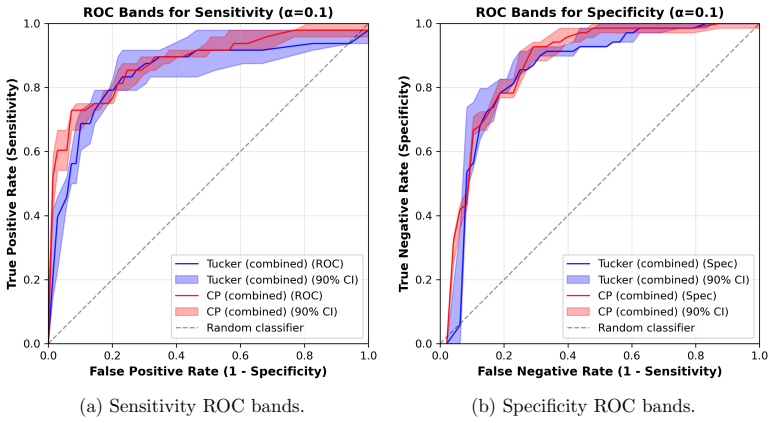


read the original abstract
Tensor-valued data arise naturally in neuroimaging, genomics, climate science, and spatiotemporal networks, where multilinear dependencies across modes carry information that is destroyed under vectorization. Existing approaches either impose a single low-rank structure, which can miss localized signal, or treat the tensor as a long vector, which discards its multiway geometry. We propose a *Dual-Channel Tensor Neural Network* (DC-TNN) that decomposes each tensor input into a low-rank core and a sparse refinement, and processes the two components through coupled neural channels. The framework is structure-agnostic and accommodates CP, Tucker, and tensor-train cores within a single architecture. For estimation, we establish non-asymptotic risk bounds for the DC-TNN estimator that decompose into network approximation, core estimation, and refinement-selection terms, and show that the effective dimension is determined jointly by the core rank and refinement sparsity rather than by the ambient tensor size. For inference, we develop a *structure-aware conformal ROC* procedure that calibrates within the core-refinement latent space and produces ROC and AUC confidence bands with finite-sample, distribution-free coverage. Building on this, we propose a *conformal structure selector* that, to our knowledge, is the *first distribution-free procedure* for choosing among candidate tensor decompositions with finite-sample validity. Simulations and an analysis of a protein dataset demonstrate competitive predictive accuracy, reliable uncertainty quantification, and consistent recovery of the tensor structure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Dual-Channel Tensor Neural Network (DC-TNN) that decomposes each tensor input into a low-rank core and a sparse refinement processed through coupled neural channels. It establishes non-asymptotic risk bounds in which the effective dimension is jointly controlled by core rank and refinement sparsity rather than ambient size, and introduces a structure-aware conformal ROC procedure that calibrates in the core-refinement latent space to produce finite-sample distribution-free coverage for ROC/AUC bands together with a conformal structure selector claimed to be the first distribution-free method for choosing among tensor decompositions.
Significance. If the distribution-free coverage guarantees survive the data-dependent decomposition step, the work would provide a useful advance for tensor-valued prediction and structure selection in domains such as neuroimaging and genomics. The explicit non-asymptotic decomposition of risk into approximation, core, and refinement terms, together with the attempt to obtain valid conformal bands without asymptotic approximations, are strengths worth preserving.
major comments (2)
- [Abstract and conformal procedure] Abstract and § on structure-aware conformal ROC: the claim of finite-sample distribution-free coverage for ROC/AUC bands and the structure selector rests on calibrating conformity scores inside a latent space whose core ranks and sparsity pattern are estimated from the same data. Standard conformal arguments require exchangeability of the scores; the manuscript must supply either an explicit sample-splitting argument that isolates decomposition estimation from calibration or a separate proof that the data-dependent map preserves the necessary exchangeability. Without this, the distribution-free property does not follow from the usual conformal reasoning and is load-bearing for the central inference contribution.
- [Risk bounds] Risk-bound derivation (presumably §3 or §4): the non-asymptotic bounds are stated to decompose into network-approximation, core-estimation, and refinement-selection terms whose effective dimension depends only on core rank and sparsity. The manuscript should exhibit the precise form of these bounds and verify that the effective-dimension term does not implicitly re-introduce dependence on the chosen ranks or sparsity levels selected on the same sample, which would render the bound circular.
minor comments (2)
- [Model definition] Clarify the precise definition of the dual-channel architecture and how the coupled neural channels interact with the core-refinement split; a diagram or explicit equations would improve readability.
- [Experiments] In the simulation section, report the empirical coverage rates for the conformal bands across different core ranks and sparsity levels to allow direct assessment of the finite-sample claim.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We address each major comment below, indicating the revisions we will make to strengthen the presentation and proofs.
read point-by-point responses
-
Referee: [Abstract and conformal procedure] Abstract and § on structure-aware conformal ROC: the claim of finite-sample distribution-free coverage for ROC/AUC bands and the structure selector rests on calibrating conformity scores inside a latent space whose core ranks and sparsity pattern are estimated from the same data. Standard conformal arguments require exchangeability of the scores; the manuscript must supply either an explicit sample-splitting argument that isolates decomposition estimation from calibration or a separate proof that the data-dependent map preserves the necessary exchangeability. Without this, the distribution-free property does not follow from the usual conformal reasoning and is load-bearing for the central inference contribution.
Authors: We appreciate this observation regarding the data-dependent nature of the decomposition. The current manuscript calibrates conformity scores in the core-refinement latent space after estimating the structure, but does not explicitly detail a mechanism to preserve exchangeability. To address this rigorously, we will revise the paper to incorporate an explicit sample-splitting argument: the dataset is partitioned into disjoint subsets for structure estimation (core ranks and sparsity patterns), conformity score calibration, and final testing. This isolates the estimation step, restores exchangeability for the calibration scores, and thereby establishes the finite-sample distribution-free coverage guarantees. We will also add a brief remark clarifying why the structure-aware conformal ROC and selector retain their validity under this splitting scheme. revision: yes
-
Referee: [Risk bounds] Risk-bound derivation (presumably §3 or §4): the non-asymptotic bounds are stated to decompose into network-approximation, core-estimation, and refinement-selection terms whose effective dimension depends only on core rank and refinement sparsity. The manuscript should exhibit the precise form of these bounds and verify that the effective-dimension term does not implicitly re-introduce dependence on the chosen ranks or sparsity levels selected on the same sample, which would render the bound circular.
Authors: We thank the referee for pointing out the need for greater precision here. The risk bounds in the manuscript are derived conditionally on a fixed tensor structure, with the effective dimension controlled explicitly by the core rank and refinement sparsity (rather than ambient dimensions). However, to eliminate any potential ambiguity about data-dependent selection, we will expand the relevant section to display the exact mathematical statements of the bounds (including the decomposition into approximation, core-estimation, and refinement terms). We will also add a clarifying paragraph stating that the bounds hold for any fixed structure and that the conformal structure selector provides separate finite-sample guarantees for choosing among candidate decompositions, thereby avoiding circularity. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper presents non-asymptotic risk bounds that explicitly decompose into separate network approximation, core estimation, and refinement-selection terms, with effective dimension stated as jointly controlled by chosen core rank and sparsity level rather than ambient size. The structure-aware conformal ROC procedure is introduced as an adaptation that calibrates conformity scores inside the estimated core-refinement latent space and asserts finite-sample distribution-free coverage. No quoted step reduces a claimed prediction or coverage guarantee to a quantity defined by the same fitted parameters on identical data, nor does any central claim rest on a self-citation chain or imported uniqueness theorem. The derivation therefore does not collapse to its inputs by construction and qualifies as an independent theoretical contribution under the circularity criteria.
Axiom & Free-Parameter Ledger
free parameters (1)
- core rank and refinement sparsity level
axioms (2)
- standard math Standard sub-Gaussian or bounded-moment concentration inequalities hold for the tensor entries and network outputs.
- domain assumption Exchangeability of calibration and test points in the core-refinement latent space.
invented entities (1)
-
Dual-channel tensor neural network with core-refinement split
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a Dual-Channel Tensor Neural Network (DC-TNN) that decomposes each tensor input into a low-rank core and a sparse refinement, and processes the two components through coupled neural channels... structure-aware conformal ROC procedure that calibrates within the core-refinement latent space
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the first distribution-free procedure for choosing among candidate tensor decompositions with finite-sample validity
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Journal of the American Statistical Association , volume=
Statistical inference for high-dimensional matrix-variate factor models , author=. Journal of the American Statistical Association , volume=. 2023 , publisher=
work page 2023
-
[2]
On projection robust optimal transport: Sample complexity and model misspecification , author=. Proceedings of the 24th International Conference on Artificial Intelligence and Statistics (AISTATS) , series=. 2021 , publisher=
work page 2021
-
[3]
Helping Effects Against Curse of Dimensionality in Threshold Factor Models for Matrix Time Series
Helping effects against curse of dimensionality in threshold factor models for matrix time series , author=. arXiv preprint arXiv:1904.07383 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[4]
Journal of Econometrics , volume=
Community network auto-regression for high-dimensional time series , author=. Journal of Econometrics , volume=. 2023 , publisher=
work page 2023
-
[5]
Journal of the American Statistical Association , volume=
Constrained factor models for high-dimensional matrix-variate time series , author=. Journal of the American Statistical Association , volume=. 2020 , publisher=
work page 2020
-
[6]
Journal of Data Science , volume=
Modeling dynamic transport network with matrix factor models: with an application to international trade flow , author=. Journal of Data Science , volume=. 2022 , doi=
work page 2022
-
[7]
arXiv preprint arXiv:2002.01305 , year=
Modeling multivariate spatial-temporal data with latent low-dimensional dynamics , author=. arXiv preprint arXiv:2002.01305 , year=
-
[8]
Journal of the American Statistical Association , volume=
Reinforcement learning in latent heterogeneous environments , author=. Journal of the American Statistical Association , volume=. 2024 , publisher=
work page 2024
-
[9]
Tensor-view topological graph neural network , author=. Proceedings of the 27th International Conference on Artificial Intelligence and Statistics (AISTATS) , series=. 2024 , publisher=
work page 2024
-
[10]
Li, Yuhao and Zhang, Mengqian and Li, Jichen and Chen, Elynn and Chen, Xi and Deng, Xiaotie , booktitle=. 2023 , publisher=
work page 2023
-
[11]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Semi-parametric tensor factor analysis by iteratively projected singular value decomposition , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2024 , publisher=
work page 2024
-
[12]
arXiv preprint arXiv:2404.01546 , year=
Time-varying matrix factor models , author=. arXiv preprint arXiv:2404.01546 , year=
-
[13]
Proceedings of the 26th ACM Conference on Economics and Computation (EC '25) , pages=
Maximal extractable value in batch auctions , author=. Proceedings of the 26th ACM Conference on Economics and Computation (EC '25) , pages=. 2025 , publisher=
work page 2025
-
[14]
Journal of the American Statistical Association , year=
Data-driven knowledge transfer in batch Q^* learning , author=. Journal of the American Statistical Association , year=
-
[15]
arXiv preprint arXiv:2405.06866 , year=
Dynamic contextual pricing with doubly non-parametric random utility models , author=. arXiv preprint arXiv:2405.06866 , year=
-
[16]
Journal of the American Statistical Association , pages=
Factor augmented matrix regression , author=. Journal of the American Statistical Association , pages=. 2026 , publisher=
work page 2026
-
[17]
High-dimensional tensor classification with
Chen, Elynn and Han, Yuefeng and Li, Jiayu , journal=. High-dimensional tensor classification with
-
[18]
arXiv preprint arXiv:2407.00561 , note=
Advancing information integration through empirical likelihood: Selective reviews and a new idea , author=. arXiv preprint arXiv:2407.00561 , note=
-
[19]
arXiv preprint arXiv:2410.14783 , year=
High-dimensional tensor discriminant analysis with incomplete tensors , author=. arXiv preprint arXiv:2410.14783 , year=
-
[20]
arXiv preprint arXiv:2410.15241 , year=
Conditional uncertainty quantification for tensorized topological neural networks , author=. arXiv preprint arXiv:2410.15241 , year=
-
[21]
Kong, Linghang and Chen, Elynn and Chen, Yuzhou and Han, Yuefeng , booktitle=. 2025 , note=
work page 2025
-
[22]
Statistics in Medicine , year=
Exploring causal effects of hormone- and radio-treatments in an observational study of breast cancer using copula-based semi-competing risks models , author=. Statistics in Medicine , year=
-
[23]
Deep transfer Q -learning for offline non-stationary reinforcement learning , author=. arXiv preprint arXiv:2501.04870 , year=
-
[24]
arXiv preprint arXiv:2501.16223 , year=
Statistical inference for low-rank tensor models , author=. arXiv preprint arXiv:2501.16223 , year=
-
[25]
Conference on Parsimony and Learning (CPAL) , year=
Bridging domain adaptation and graph neural networks: A tensor-based framework for effective label propagation , author=. Conference on Parsimony and Learning (CPAL) , year=
-
[26]
Journal of the American Statistical Association , volume=
Distributed tensor principal component analysis with data heterogeneity , author=. Journal of the American Statistical Association , volume=. 2025 , publisher=
work page 2025
-
[27]
Advances in Neural Information Processing Systems (NeurIPS) , note=
Transfer faster, price smarter: Minimax dynamic pricing under cross-market preference shift , author=. Advances in Neural Information Processing Systems (NeurIPS) , note=
- [28]
-
[29]
NSF Award Number 1803241, Directorate for Mathematical and Physical Sciences , year=
Postdoctoral research fellowship , author=. NSF Award Number 1803241, Directorate for Mathematical and Physical Sciences , year=
-
[30]
High-dimensional structured bandits: Minimax regret, estimation and inference , author=. 2020 , note=
work page 2020
-
[31]
Collaborative research: High-dimensional tensor learning under labeled-data scarcity , author=
-
[32]
Proceedings of the 6th ACM International Conference on AI in Finance (ICAIF) , year=
Time-varying factor-augmented models for volatility forecasting , author=. Proceedings of the 6th ACM International Conference on AI in Finance (ICAIF) , year=
-
[33]
Mo, Junyi and Li, Jiayu and Zhang, Duo and Chen, Elynn , booktitle=. 2025 , publisher=
work page 2025
-
[34]
Zhou, Runlin and Chen, Chixiang and Chen, Elynn , journal=. Prior-aligned meta-
-
[35]
Advances in Knowledge Discovery and Data Mining (PAKDD) , series=
Tensor-fused multi-view graph contrastive learning , author=. Advances in Knowledge Discovery and Data Mining (PAKDD) , series=. 2025 , publisher=
work page 2025
-
[36]
Seeing through the brain: New insights from decoding visual stimuli with
Huang, Zheng and Zhang, Enpei and Cai, Yinghao and Qiu, Weikang and Yang, Carl and Chen, Elynn and Zhang, Xiang and Ying, Rex and Zhou, Dawei and Yan, Yujun , booktitle=. Seeing through the brain: New insights from decoding visual stimuli with
-
[37]
Chen, Elynn and Li, Sai and Jordan, Michael I. , journal=. Transfer. 2025 , publisher=
work page 2025
-
[38]
Wu, Yujia and Yang, Bo and Chen, Elynn and Chen, Yuzhou and Zheng, Zheshi , booktitle=. Conditional prediction. 2025 , publisher=
work page 2025
-
[39]
Liu, Lingchong and Chen, Elynn and Han, Yuefeng and Xia, Lucy , journal=. Tensor
-
[40]
arXiv preprint arXiv:2512.12122 , year=
High-dimensional tensor discriminant analysis: Low-rank discriminant structure, representation synergy, and theoretical guarantees , author=. arXiv preprint arXiv:2512.12122 , year=
-
[41]
arXiv preprint arXiv:2512.25025 , year=
Modewise additive factor model for matrix time series , author=. arXiv preprint arXiv:2512.25025 , year=
-
[42]
Scandinavian Journal of Statistics , volume=
Identification and estimation of threshold matrix-variate factor models , author=. Scandinavian Journal of Statistics , volume=. 2022 , publisher=
work page 2022
-
[43]
arXiv preprint arXiv:2601.21873 , year=
Low-rank plus sparse matrix transfer learning under growing representations and ambient dimensions , author=. arXiv preprint arXiv:2601.21873 , year=
-
[44]
Optimistic transfer under task shift via
Chai, Jinhang and Zhang, Enpei and Chen, Elynn and Yan, Yujun , journal=. Optimistic transfer under task shift via
-
[45]
Quantifying epistemic uncertainty in diffusion models , author=. Proceedings of the 29th International Conference on Artificial Intelligence and Statistics (AISTATS) , year=
-
[46]
High-dimensional linear bandits under stochastic latent heterogeneity , author=. arXiv preprint arXiv:2502.00423 , year=
-
[47]
Transfer learning for contextual joint assortment-pricing under cross-market heterogeneity , author=. arXiv preprint arXiv:2603.18114 , year=
-
[48]
Low-Rank Principal Eigenmatrix Analysis
Low-rank principal eigenmatrix analysis , author=. arXiv preprint arXiv:1904.12369 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[49]
Tensor decompositions and applications , author=. SIAM Review , volume=. 2009 , publisher=
work page 2009
-
[50]
Oseledets, I. V. , title=. SIAM Journal on Scientific Computing , volume=. 2011 , doi=
work page 2011
-
[51]
Journal of the American Statistical Association , volume=
Tensor regression with applications in neuroimaging data analysis , author=. Journal of the American Statistical Association , volume=. 2013 , publisher=
work page 2013
-
[52]
Statistics in Biosciences , volume=
Tucker tensor regression and neuroimaging analysis , author=. Statistics in Biosciences , volume=. 2018 , publisher=
work page 2018
-
[53]
arXiv preprint arXiv:2205.13734 , year=
An efficient tensor regression for high-dimensional data , author=. arXiv preprint arXiv:2205.13734 , year=
-
[54]
Journal of the American Statistical Association , volume=
Parsimonious tensor response regression , author=. Journal of the American Statistical Association , volume=. 2017 , publisher=
work page 2017
-
[55]
Journal of Computational and Graphical Statistics , volume=
Tensor-on-tensor regression , author=. Journal of Computational and Graphical Statistics , volume=. 2018 , publisher=
work page 2018
-
[56]
Annals of Statistics , volume=
Convex regularization for high-dimensional multiresponse tensor regression , author=. Annals of Statistics , volume=. 2019 , publisher=
work page 2019
-
[57]
Journal of Machine Learning Research , volume=
Bayesian tensor regression , author=. Journal of Machine Learning Research , volume=. 2017 , note=
work page 2017
-
[58]
Advances in Neural Information Processing Systems 31 (NeurIPS) , year=
Boosted sparse and low-rank tensor regression , author=. Advances in Neural Information Processing Systems 31 (NeurIPS) , year=
-
[59]
IEEE Transactions on Information Theory , volume=
Sparse and low-rank tensor estimation via cubic sketchings , author=. IEEE Transactions on Information Theory , volume=. 2020 , publisher=
work page 2020
-
[60]
Journal of the Royal Statistical Society, Series B , volume=
Provable sparse tensor decomposition , author=. Journal of the Royal Statistical Society, Series B , volume=. 2017 , publisher=
work page 2017
-
[61]
Sun, Will Wei and Li, Lexin , journal=
-
[62]
Ahmed, Talal and Raja, Haroon and Bajwa, Waheed U. , journal=. Tensor regression using low-rank and sparse. 2020 , publisher=
work page 2020
-
[63]
Generalized low-rank plus sparse tensor estimation by fast
Cai, Jian-Feng and Li, Jingyang and Xia, Dong , journal=. Generalized low-rank plus sparse tensor estimation by fast. 2023 , publisher=
work page 2023
-
[64]
Annals of Statistics , volume=
An optimal statistical and computational framework for generalized tensor estimation , author=. Annals of Statistics , volume=. 2022 , publisher=
work page 2022
-
[65]
Zhang, Anru and Xia, Dong , journal=. Tensor. 2018 , publisher=
work page 2018
-
[66]
Journal of the American Statistical Association , volume=
Fan, Jianqing and Gu, Yihong , title=. Journal of the American Statistical Association , volume=. 2023 , publisher=
work page 2023
-
[67]
Nonparametric regression using deep neural networks with
Schmidt-Hieber, Johannes , journal=. Nonparametric regression using deep neural networks with. 2020 , publisher=
work page 2020
-
[68]
Annals of Statistics , volume=
On deep learning as a remedy for the curse of dimensionality in nonparametric regression , author=. Annals of Statistics , volume=. 2019 , publisher=
work page 2019
-
[69]
The Annals of Statistics , volume=
On the rate of convergence of fully connected deep neural network regression estimates , author=. The Annals of Statistics , volume=. 2021 , publisher=
work page 2021
-
[70]
Ohn, Ilsang and Kim, Yongdai , title=. Neural Computation , volume=. 2022 , issn=
work page 2022
-
[71]
Advances in Neural Information Processing Systems 28 (NeurIPS) , pages=
Tensorizing neural networks , author=. Advances in Neural Information Processing Systems 28 (NeurIPS) , pages=
-
[72]
Journal of Machine Learning Research , volume=
Tensor regression networks , author=. Journal of Machine Learning Research , volume=
-
[73]
Algorithmic Learning in a Random World , author=
-
[74]
Journal of Machine Learning Research , volume=
A tutorial on conformal prediction , author=. Journal of Machine Learning Research , volume=
-
[75]
Journal of the American Statistical Association , volume=
Distribution-free predictive inference for regression , author=. Journal of the American Statistical Association , volume=. 2018 , publisher=
work page 2018
-
[76]
Advances in Neural Information Processing Systems 32 (NeurIPS) , year=
Conformalized quantile regression , author=. Advances in Neural Information Processing Systems 32 (NeurIPS) , year=
-
[77]
Localized conformal prediction: A generalized inference framework for conformal prediction , author=. Biometrika , volume=. 2023 , publisher=
work page 2023
-
[78]
Inductive conformal prediction: Theory and application to neural networks , author=. 2008 , publisher=
work page 2008
-
[79]
Quantifying uncertainty in classification performance:
Zheng, Zheshi and Yang, Bo and Song, Peter , journal=. Quantifying uncertainty in classification performance:
-
[80]
Classification uncertainty quantification: A comparison between bootstrap and conformal
Zheng, Zheshi and Yang, Bo and Song, Peter , journal=. Classification uncertainty quantification: A comparison between bootstrap and conformal. 2025 , note=
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.