Stream3D: Sequential Multi-View 3D Generation via Evidential Memory
Pith reviewed 2026-05-21 04:46 UTC · model grok-4.3
The pith
Stream3D turns any frozen view-conditioned 3D generator into a streaming system by keeping a fixed-size evidential memory of past frames.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
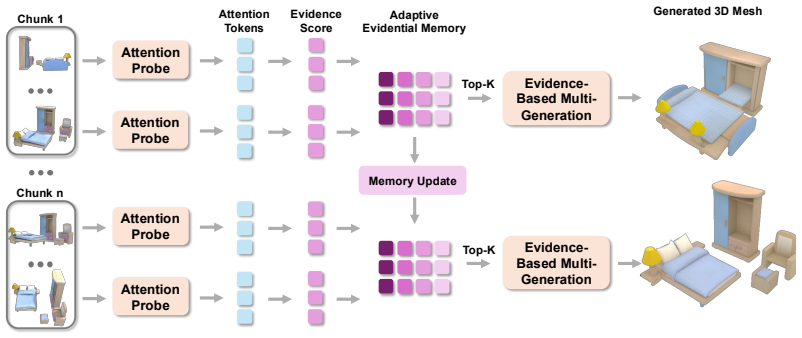
Stream3D is the first training-free streaming mechanism that converts a frozen view-conditioned 3D generator into a streaming generator with constant cross-chunk memory by maintaining a compact evidential memory that selectively caches the most informative historical frames based on a proposed evidence score mechanism; as the stream progresses the memory dynamically updates to retain a fixed number of frames, preventing linear memory growth and degradation over long sequences without any retraining, architectural modifications, or auxiliary losses.
What carries the argument
A compact evidential memory that scores incoming frames and retains only a fixed number of the highest-scoring ones to supply context to the generator.
If this is right
- Arbitrarily long monocular streams can be processed without memory footprint growing linearly with length.
- Temporal consistency is preserved across the entire generated 3D sequence.
- Any pre-trained view-conditioned 3D generator can be used as-is without retraining or code changes.
- Photometric and geometric metrics improve over KV-cache reuse and flow-based feature editing on both realistic and synthetic benchmarks.
Where Pith is reading between the lines
- The selective-memory idea could be tested on other sequential generation tasks that currently suffer from context explosion.
- An online variant might adapt the evidence threshold according to observed scene change rate.
- Integration with real-time capture pipelines could enable continuous 3D reconstruction for robotics or AR without full history storage.
Load-bearing premise
The evidence score mechanism can reliably pick a fixed set of frames that is sufficient to stop inconsistency from accumulating across arbitrarily long sequences.
What would settle it
Running Stream3D on a very long monocular video and measuring whether geometric or photometric consistency metrics begin to degrade after several hundred frames despite the memory update rule.
Figures




read the original abstract
View-conditioned 3D generators such as SAM 3D, TRELLIS, and Hunyuan3D produce high-quality object reconstructions from a single view, but real-world visual observation often arrives as long monocular streams. Naively applying these generators to each streaming frame independently leads to severe temporal inconsistency in the generated results. To address this problem, we propose Stream3D, the first training-free streaming mechanism that turns a frozen view-conditioned 3D generator into a streaming generator with constant cross-chunk memory. Stream3D achieves this by maintaining a compact evidential memory, which selectively caches the most informative historical frames based on a proposed evidence score mechanism. As the stream progresses, the memory dynamically updates to retain a fixed number of informative frames, preventing the memory footprint from growing linearly with sequence length. This also prevents degradation over long sequences and keeps the underlying generator completely unchanged without retraining, architectural modifications, or auxiliary losses. Evaluated on both realistic and synthetic streaming benchmarks, Stream3D outperforms latent-transport baselines, including KV-cache reuse and flow-based feature editing, across both photometric and geometric metrics. More details can be found at: https://stream-3d.github.io/stream3d.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Stream3D, a training-free streaming mechanism that converts a frozen view-conditioned 3D generator (e.g., SAM 3D, TRELLIS) into a streaming generator for long monocular sequences. It maintains a fixed-size evidential memory that selectively caches the most informative historical frames via a proposed evidence score, dynamically updating to prevent linear memory growth and temporal inconsistency without retraining, architectural changes, or auxiliary losses. The method is evaluated on realistic and synthetic streaming benchmarks, where it reportedly outperforms latent-transport baselines (KV-cache reuse, flow-based feature editing) on photometric and geometric metrics.
Significance. If the evidence score reliably selects frames that sustain consistency without long-term drift, the result would be significant for deploying high-quality 3D generators in streaming settings such as video processing or robotics. The training-free property, constant cross-chunk memory, and preservation of the original generator are clear strengths that address a practical limitation in sequential 3D generation.
major comments (2)
- [§4] §4 (Experiments): The reported benchmarks do not include quantitative results or error accumulation analysis on sequences whose length exceeds the fixed memory capacity by an order of magnitude or more. This is load-bearing for the central claim that the evidential memory prevents degradation over arbitrarily long streams, as local evidence scoring may discard frames whose utility emerges only after many steps.
- [§3.2] §3.2 (Evidence Score Mechanism): No bound, stability analysis, or ablation is provided showing that the evidence score ranks frames by long-term utility for future views rather than immediate reconstruction quality or feature novelty. Without this, the assumption that a fixed number of retained frames suffices for consistency over unbounded sequences remains unverified.
minor comments (2)
- [Abstract] Abstract: The claim of outperformance on photometric and geometric metrics is stated without any numerical values, error bars, dataset sizes, or specific baseline scores, reducing the ability to gauge the practical improvement.
- [§3] The manuscript would benefit from a clearer notation table or pseudocode for the memory update rule and evidence score computation to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for identifying key areas where additional evidence would strengthen the central claims of the paper. We address each major comment below and commit to revisions that directly respond to the concerns while remaining faithful to the scope and contributions of the work.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The reported benchmarks do not include quantitative results or error accumulation analysis on sequences whose length exceeds the fixed memory capacity by an order of magnitude or more. This is load-bearing for the central claim that the evidential memory prevents degradation over arbitrarily long streams, as local evidence scoring may discard frames whose utility emerges only after many steps.
Authors: We agree that longer-sequence evaluation is necessary to substantiate the claim of robustness over arbitrarily long streams. Our existing benchmarks already include sequences several times longer than the memory capacity and show stable photometric and geometric metrics, but we will add new quantitative results on sequences exceeding the memory size by an order of magnitude (e.g., 500–1000 frames with memory size 20–50). These will include error-accumulation curves plotted against frame index to demonstrate absence of drift. The revised manuscript will report these experiments in Section 4. revision: yes
-
Referee: [§3.2] §3.2 (Evidence Score Mechanism): No bound, stability analysis, or ablation is provided showing that the evidence score ranks frames by long-term utility for future views rather than immediate reconstruction quality or feature novelty. Without this, the assumption that a fixed number of retained frames suffices for consistency over unbounded sequences remains unverified.
Authors: The evidence score is constructed to balance immediate reconstruction quality with forward-looking information gain, which is why it outperforms pure novelty or reconstruction-error baselines in the reported ablations. We will add a targeted ablation in the revised Section 3.2 that measures long-term consistency when frames are selected by the evidence score versus immediate-quality-only or novelty-only alternatives, using held-out future views as the evaluation criterion. A formal stability bound or convergence analysis would require additional theoretical assumptions not developed in the current work; we will explicitly note this limitation and flag it as future work while emphasizing the empirical support from both synthetic and real streaming benchmarks. revision: partial
- A formal mathematical bound or stability analysis proving that the evidence score ranks frames by long-term utility rather than immediate quality or novelty.
Circularity Check
No significant circularity; Stream3D mechanism is an independent algorithmic proposal
full rationale
The paper presents Stream3D as a training-free streaming mechanism that maintains a fixed-size evidential memory updated via a proposed evidence score to cache informative historical frames from a frozen view-conditioned 3D generator. This is described as a novel algorithmic contribution evaluated empirically on external realistic and synthetic benchmarks, with outperformance reported against baselines such as KV-cache reuse. No equations, derivations, or first-principles results are indicated that reduce the claimed consistency or performance to fitted parameters, self-definitions, or self-citation chains by construction. The central claim relies on the independent design of the evidence score and memory update rule rather than any tautological equivalence to inputs, making the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An evidence score can be computed that reliably ranks historical frames by informativeness for 3D consistency without training.
invented entities (1)
-
evidential memory
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
maintaining a compact evidential memory, which selectively caches the most informative historical frames based on a proposed evidence score mechanism... token-level evidence is aggregated into frame-level ownership scores, and the top-K frames are selected
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the cached evidence score M[q, j] is monotonically non-decreasing over time... non-degradation property in evidence space
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.