AlignedServe: Orchestrating Prefix-aware Batching to Build a High-throughput and Computing-efficient LLM Serving System
Pith reviewed 2026-05-25 03:09 UTC · model grok-4.3
The pith
AlignedServe groups LLM requests by similar KV-cache lengths to cut iteration bubbles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By grouping requests with similar KV-cache lengths into the same batch, AlignedServe reduces iteration-level bubbles caused by varying per-token costs; it supports this with a large CPU-resident request pool, batch-level scheduling, and a GPU-Prefetch-For-GPU architecture that moves KV caches between GPUs.
What carries the argument
Prefix-aware batching that groups requests by KV-cache length similarity to align computation times within each decode iteration.
Load-bearing premise
Grouping requests by similar KV-cache lengths will produce large reductions in iteration-level bubbles without being offset by the overhead of maintaining a large CPU-resident request pool or by changes in cache hit rates.
What would settle it
Run the same workloads on a system where all requests already have nearly identical KV-cache lengths and measure whether throughput gains disappear.
Figures

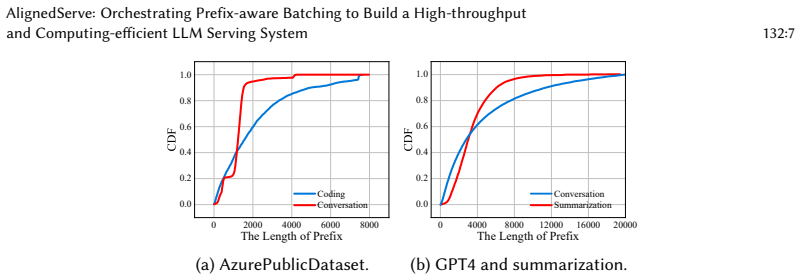



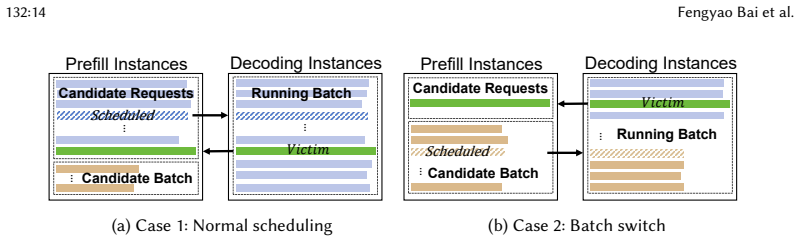
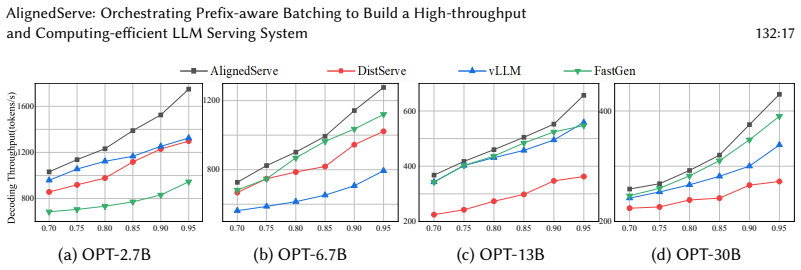








read the original abstract
High-throughput inference serving is essential for applications built on large language models (LLMs). Existing serving frameworks reduce request-level and batch-level bubbles through batching and scheduling, but often overlook bubbles within each decode iteration. Tokens generated in the same iteration may incur different costs because they depend on KV caches of different lengths; tokens with long KV caches can become bottlenecks and delay the next iteration. We propose AlignedServe, an LLM serving framework built around prefix-aware batching. It groups requests with similar KV-cache lengths into the same batch to reduce iteration-level bubbles. To support this policy efficiently, AlignedServe uses large CPU memory to maintain sufficient in-flight requests for batching and applies a batch-level scheduling policy to reduce batch-level bubbles. It also introduces a GPU-Prefetch-For-GPU architecture, where one GPU prefetches KV cache for another to reduce CPU-to-GPU transfer latency. Experiments on synthetic and application workloads show that AlignedServe improves decoding throughput by up to 1.98 times and reduces latency by up to 7.4 times over state-of-the-art systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AlignedServe, an LLM serving framework that introduces prefix-aware batching to group requests with similar KV-cache lengths into the same batch, thereby reducing iteration-level bubbles caused by varying per-token costs. It supports this via a large CPU-resident pool of in-flight requests, batch-level scheduling to reduce batch bubbles, and a GPU-Prefetch-For-GPU architecture to hide CPU-to-GPU KV-cache transfer latency. Experiments on synthetic and application workloads are reported to yield up to 1.98× higher decoding throughput and 7.4× lower latency versus state-of-the-art systems.
Significance. If the experimental claims hold after detailed validation, the work would represent a practical advance in LLM inference serving by targeting an intra-iteration source of inefficiency that prior batching and scheduling techniques have largely ignored. The combination of CPU-side request pooling with cross-GPU prefetching offers a concrete engineering path to higher utilization; explicit credit is due for the focus on measurable iteration bubbles, though no machine-checked proofs or fully reproducible artifacts are referenced.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: The headline claims (1.98× throughput, 7.4× latency) are stated without any description of workloads, baseline configurations, hardware, measurement methodology, or error bars. This absence is load-bearing because the central contribution is an empirical performance improvement whose magnitude cannot be assessed or reproduced from the given information.
- [System Design] System overview / request-pool description: The design relies on maintaining a large CPU-resident request pool to enable prefix-aware grouping, yet no quantitative breakdown is supplied of CPU-side scheduling overhead, memory pressure, or possible degradation in cache hit rates versus the claimed reduction in per-iteration bubbles. Without this accounting, it is impossible to confirm that the GPU-side savings are not offset by the mechanisms introduced to support the policy.
minor comments (2)
- [Introduction] The term 'iteration-level bubbles' is used repeatedly but never given a concise operational definition (e.g., variance in per-token decode time within one forward pass); adding one sentence in the introduction would improve accessibility.
- Figure captions and axis labels should explicitly state whether throughput numbers are normalized to a particular baseline or reported in absolute tokens/s.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to provide the requested details and analysis.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: The headline claims (1.98× throughput, 7.4× latency) are stated without any description of workloads, baseline configurations, hardware, measurement methodology, or error bars. This absence is load-bearing because the central contribution is an empirical performance improvement whose magnitude cannot be assessed or reproduced from the given information.
Authors: We agree that the abstract omits these specifics due to length constraints. The Evaluation section describes synthetic and application workloads but does not explicitly enumerate all configurations, hardware, methodology, or error bars. We will revise the Evaluation section to add a dedicated experimental setup subsection listing workloads, baselines and configurations, hardware, measurement methodology, and error bars from repeated runs. A brief reference to key setup elements will also be added to the abstract if space permits. revision: yes
-
Referee: [System Design] System overview / request-pool description: The design relies on maintaining a large CPU-resident request pool to enable prefix-aware grouping, yet no quantitative breakdown is supplied of CPU-side scheduling overhead, memory pressure, or possible degradation in cache hit rates versus the claimed reduction in per-iteration bubbles. Without this accounting, it is impossible to confirm that the GPU-side savings are not offset by the mechanisms introduced to support the policy.
Authors: We acknowledge that the current manuscript does not provide quantitative measurements of CPU-side overheads. We will add an analysis section in the revision that reports CPU scheduling overhead, memory usage of the request pool, and any impact on cache hit rates, then compare these costs against the measured reduction in iteration bubbles to confirm net gains. revision: yes
Circularity Check
No circularity: experimental validation of system design
full rationale
The paper describes an engineering system (prefix-aware batching, CPU-resident request pool, GPU-Prefetch-For-GPU) and reports measured throughput/latency gains on synthetic and application workloads. No equations, fitted parameters, or derivation chain appear in the provided text; the central claims are presented as direct experimental outcomes rather than predictions derived from a model. No self-citation load-bearing steps, self-definitional constructs, or fitted-input-as-prediction patterns are present. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shubham Agarwal, Sai Sundaresan, Subrata Mitra, Debabrata Mahapatra, Archit Gupta, Rounak Sharma, Nirmal Joshua Kapu, Tong Yu, and Shiv Saini. 2025. Cache-Craft: Managing Chunk-Caches for Efficient Retrieval-Augmented Generation.Proc. ACM Manag. Data3, 3, Article 136 (June 2025), 28 pages. doi:10.1145/3725273
-
[2]
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, Santa Clara, CA, 117–134. https://www.usenix....
2024
-
[3]
Amey Agrawal, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S Gulavani, and Ramachandran Ramjee
-
[4]
Sarathi: Efficient llm inference by piggybacking decodes with chunked prefills.arXiv preprint arXiv:2308.16369 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Brown, Benjamin Mann, Nick Ryder, et al
Tom B. Brown, Benjamin Mann, Nick Ryder, et al. 2020. Language models are few-shot learners. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 33. 1877–1901
work page 2020
-
[6]
Weijian Chen, Shuibing He, Haoyang Qu, Ruidong Zhang, Siling Yang, Ping Chen, Yi Zheng, Baoxing Huai, and Gang Chen. 2025. IMPRESS: An Importance-Informed Multi-Tier Prefix KV Storage System for Large Language Model Inference. In23rd USENIX Conference on File and Storage Technologies (FAST 25). USENIX Association, Santa Clara, CA, 187–201. https://www.use...
work page 2025
-
[7]
Arman Cohan, Franck Dernoncourt, Doo Soon Kim, Trung Bui, Seokhwan Kim, Walter Chang, and Nazli Goharian
-
[8]
A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). Association for Computational Linguistics, New Orleans, Louisiana, 615–621. doi:10.18653/v1/N18-2097
-
[9]
Yangyang Feng, Minhui Xie, Zijie Tian, Shuo Wang, Youyou Lu, and Jiwu Shu. 2023. Mobius: Fine tuning large-scale models on commodity gpu servers. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 489–501. Proc. ACM Manag. Data, Vol. 4, No. 3 (SIGMOD), Article 132. Pub...
work page 2023
-
[10]
Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, and Pengfei Zuo. 2024. Cost-efficient large language model serving for multi-turn conversations with CachedAttention. In Proceedings of the 2024 USENIX Conference on Usenix Annual Technical Conference(Santa Clara, CA, USA)(USENIX ATC’24). USENIX Associatio...
work page 2024
-
[11]
Shihong Gao, Xin Zhang, Yanyan Shen, and Lei Chen. 2025. Apt-Serve: Adaptive Request Scheduling on Hybrid Cache for Scalable LLM Inference Serving.Proc. ACM Manag. Data3, 3, Article 130 (June 2025), 28 pages. doi:10.1145/3725394
-
[12]
GitHub. 2021. GitHub Copilot. https://github.com/features/copilot
work page 2021
-
[13]
Google. 2024. Our next-generation model: Gemini 1.5. https://blog.google/technology/ai/google-gemini-next- generationmodel-february-2024/
work page 2024
-
[14]
Connor Holmes, Masahiro Tanaka, Michael Wyatt, Ammar Ahmad Awan, Jeff Rasley, Samyam Rajbhandari, Reza Yaz- dani Aminabadi, Heyang Qin, Arash Bakhtiari, Lev Kurilenko, et al. 2024. Deepspeed-fastgen: High-throughput text generation for llms via mii and deepspeed-inference.arXiv preprint arXiv:2401.08671(2024)
- [15]
- [16]
-
[17]
Yitao Hu, Xiulong Liu, Guotao Yang, Linxuan Li, Kai Zeng, Zhixin Zhao, Sheng Chen, Laiping Zhao, Wenxin Li, and Keqiu Li. 2025. TightLLM: Maximizing Throughput for LLM Inference via Adaptive Offloading Policy.IEEE Trans. Comput.74, 7 (2025), 2195–2209. doi:10.1109/TC.2025.3558009
-
[18]
Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. 2020. Efficient Attention: A Fast and Memory-Efficient Method for Transformers. InAdvances in Neural Information Processing Systems, Vol. 33. 17902–17914
work page 2020
-
[19]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th Symposium on Operating Systems Principles. 611–626
work page 2023
-
[20]
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. 2024. InfiniGen: Efficient Generative Inference of Large Language Models with Dynamic KV Cache Management. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, Santa Clara, CA, 155–172. https://www.usenix.org/conference/ osdi24/presentation/lee
work page 2024
-
[21]
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Dan Jurafsky, ...
-
[22]
Yuhang Li, Rong Gu, Chengying Huan, Zhibin Wang, Renjie Yao, Chen Tian, and Guihai Chen. 2025. HotPrefix: Hotness-Aware KV Cache Scheduling for Efficient Prefix Sharing in LLM Inference Systems.Proc. ACM Manag. Data3, 4, Article 250 (Sept. 2025), 27 pages. doi:10.1145/3749168
-
[23]
Meta AI. 2023. Code Llama: An Open Foundation Model for Code. https://ai.meta.com/research/code-llama/
work page 2023
-
[24]
Moonshot AI. 2024. Kimi: Your AI Assistant. https://kimi.moonshot.cn/
2024
-
[25]
Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R Devanur, Gregory R Ganger, Phillip B Gibbons, and Matei Zaharia. 2019. PipeDream: Generalized pipeline parallelism for DNN training. InProceedings of the 27th ACM symposium on operating systems principles. 1–15
work page 2019
-
[26]
OpenAI. 2022. ChatGPT. https://openai.com/blog/chatgpt/
2022
-
[27]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini
-
[28]
In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA)
Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 118–132
-
[29]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. 2025. Mooncake: Trading More Storage for Less Computation — A KVCache-centric Architecture for Serving LLM Chatbot. In23rd USENIX Conference on File and Storage Technologies (FAST 25). USENIX Association, Santa Clara, CA, 155–170. https://www.u...
work page 2025
- [30]
-
[31]
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Beidi Chen, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang. 2023. FlexGen: high-throughput generative inference of large language models with a single GPU. InProceedings of the 40th International Conference on Machine Learning(Honolulu, Hawaii, USA)(ICML’23). JMLR.org, Article 1288,...
work page 2023
-
[32]
Vikranth Srivatsa, Zijian He, Reyna Abhyankar, Dongming Li, and Yiying Zhang. 2025. Preble: Efficient Distributed Prompt Scheduling for LLM Serving. InThe Thirteenth International Conference on Learning Representations. https: //openreview.net/forum?id=meKEKDhdnx
work page 2025
-
[33]
Foteini Strati, Sara McAllister, Amar Phanishayee, Jakub Tarnawski, and Ana Klimovic. [n. d.]. DéjàVu: KV-cache Streaming for Fast, Fault-tolerant Generative LLM Serving. InForty-first International Conference on Machine Learning
-
[34]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurélien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. LLaMA: Open and Efficient Foundation Language Models.CoRRabs/2302.13971 (2023). arXiv:2302.13971 doi:10.48550/ARXIV.2302.13971
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971 2023
-
[35]
A Vaswani. 2017. Attention is all you need.Advances in Neural Information Processing Systems(2017)
work page 2017
-
[36]
vllm-project. 2024. vllm: Easy, fast, and cheap LLM serving for everyone. https://github.com/vllm-project/vllm
work page 2024
-
[37]
Guan Wang, Sijie Cheng, Xianyuan Zhan, Xiangang Li, Sen Song, and Yang Liu. 2023. OpenChat: Advancing Open- Source Language Models with Mixed-Quality Data
work page 2023
- [38]
-
[39]
Bingyang Wu, Yinmin Zhong, Zili Zhang, Gang Huang, Xuanzhe Liu, and Xin Jin. 2023. Fast distributed inference serving for large language models.arXiv preprint arXiv:2305.05920(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A Distributed Serving System for Transformer-Based Generative Models. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). USENIX Association, Carlsbad, CA, 521–538. https://www.usenix.org/conference/ osdi22/presentation/yu
work page 2022
-
[41]
OPT: Open Pre-trained Transformer Language Models
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona T. Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, and Luke Zettlemoyer. 2022. OPT: Open Pre-trained Transformer Language Models. CoRRabs/2205.01068 (2...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2205.01068 2022
-
[42]
Zhen Zheng, Xin Ji, Taosong Fang, Fanghao Zhou, Chuanjie Liu, and Gang Peng. 2025. BatchLLM: Optimizing Large Batched LLM Inference with Global Prefix Sharing and Throughput-oriented Token Batching. arXiv:2412.03594 [cs.CL] https://arxiv.org/abs/2412.03594
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving. arXiv:2401.09670 [cs.DC] Received October 2025; revised January 2026; accepted February 2026 Proc. ACM Manag. Data, Vol. 4, No. 3 (SIGMOD), Article 132. Pu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.