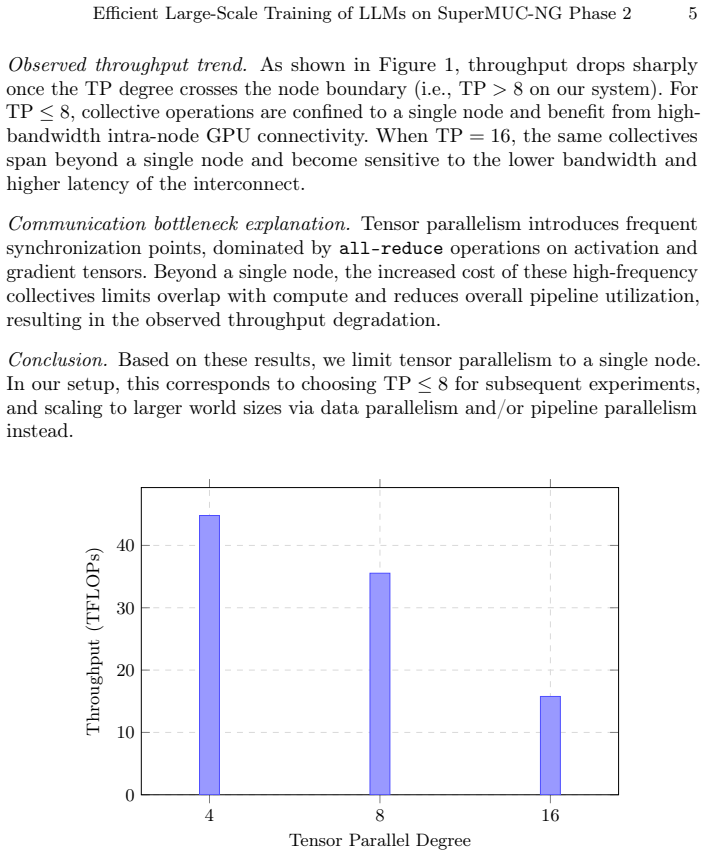
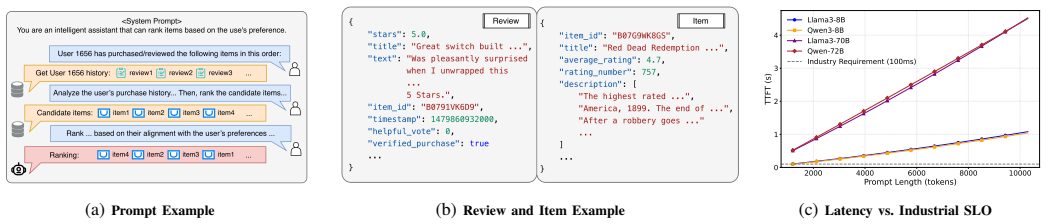
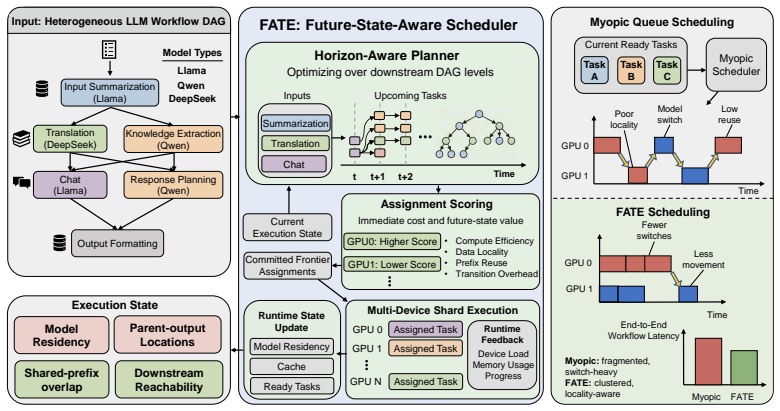
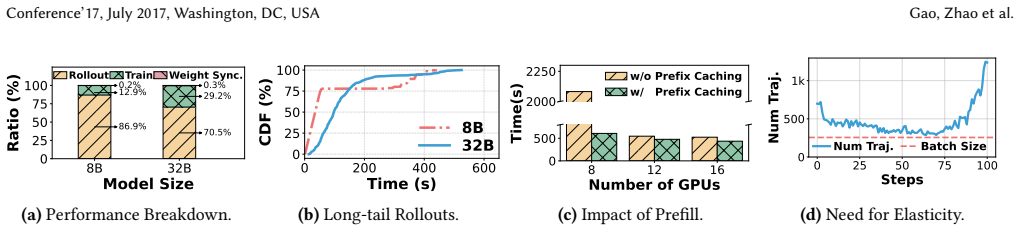
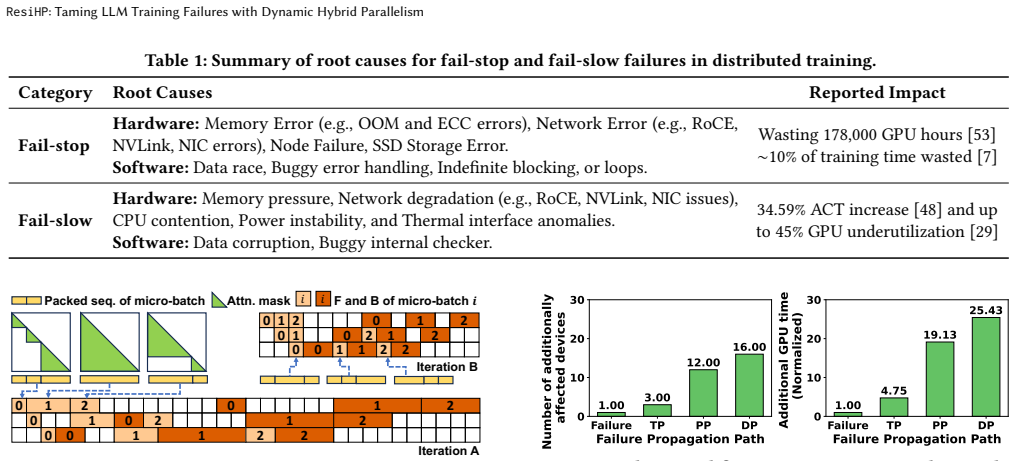
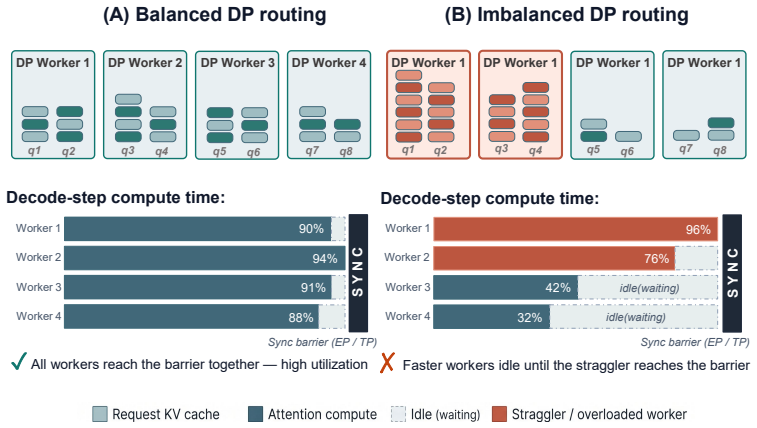
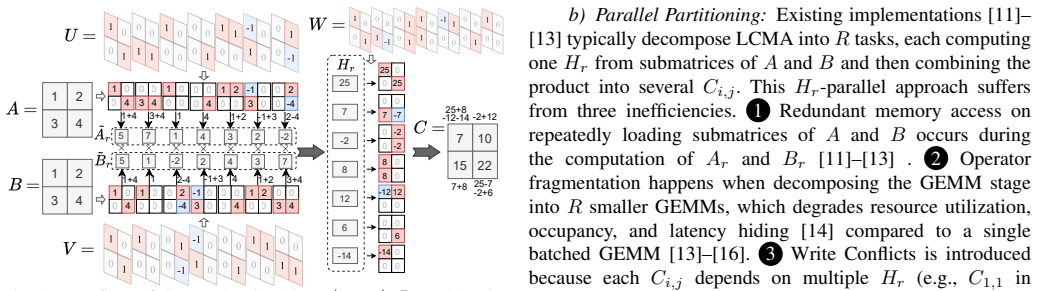
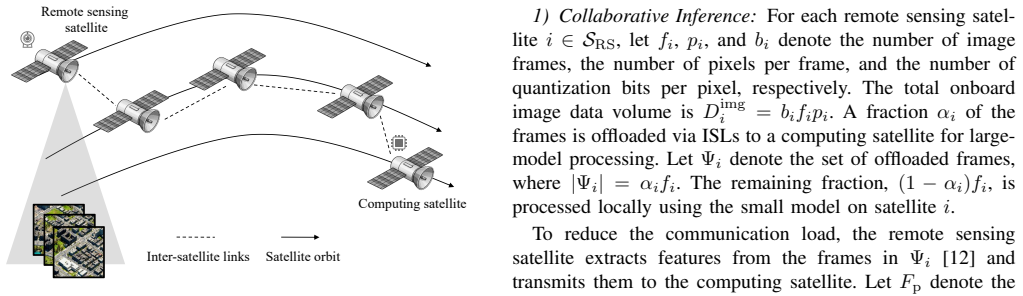
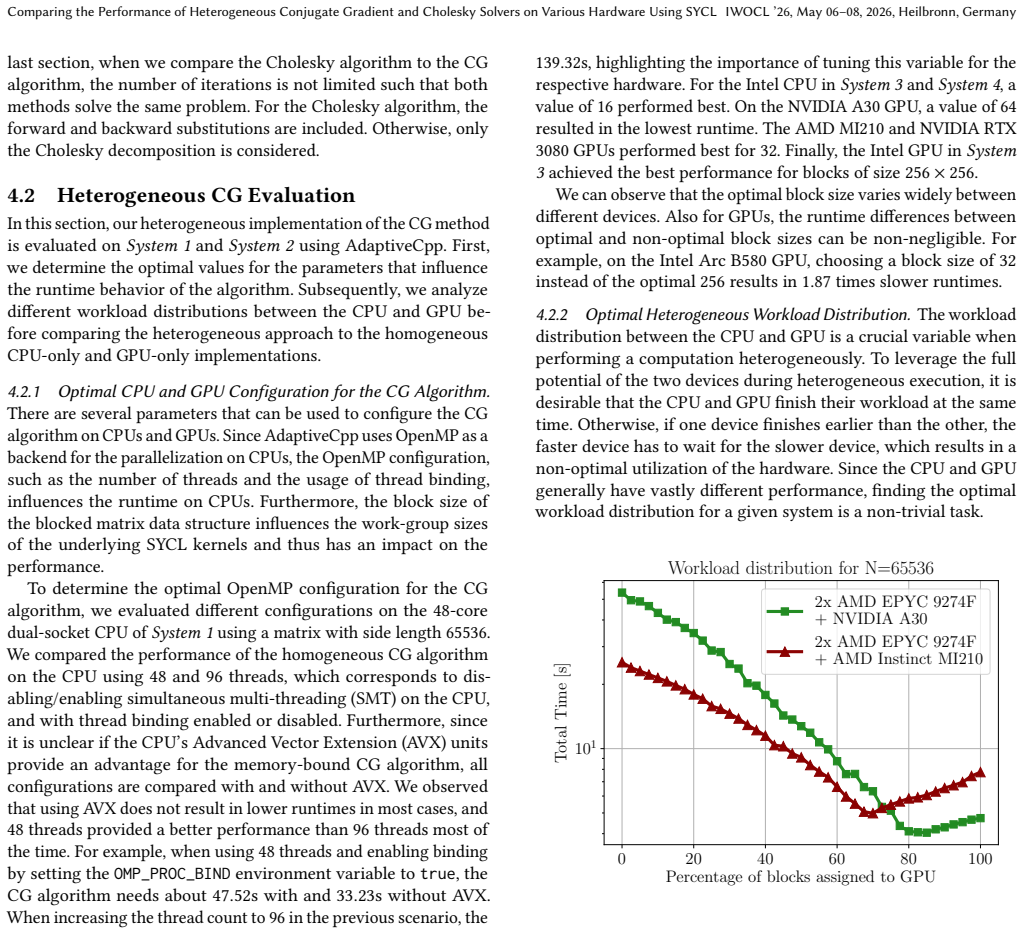
0
Heterogeneous solvers up to 32% faster than GPU-only for big matrices
Splitting CG and Cholesky work across CPU and GPU with SYCL beats pure-GPU code on NVIDIA, AMD and Intel systems.
 full image
full image
abstract click to expand
Many important real-world applications, such as System Identification with Gaussian Processes, involve solving linear systems with symmetric positive-definite matrices. The iterative CG method and direct solvers based on the Cholesky decomposition are two popular methods that can be applied in this case. Since often very large systems have to be solved when dealing with such real-world scenarios, GPUs are commonly used to accelerate the computations. However, homogeneous approaches that only leverage the GPU in the system do not take full advantage of the often powerful CPUs located in modern HPC systems. In this work, we present multi-vendor, heterogeneous implementations of the CG method and the Cholesky decomposition that leverage the CPU and GPU of a heterogeneous system simultaneously using SYCL. Furthermore, we compare their runtime behavior to traditional, homogeneous approaches. The results show that for large matrices, our heterogeneous implementation is up to 32 percent faster for the CG method and up to 29 percent faster for the Cholesky decomposition compared to the corresponding GPU-only implementations. In addition, for large matrices, our heterogeneous implementation of the Cholesky decomposition can achieve at least 12 percent faster runtimes across several systems with GPUs from NVIDIA, AMD, and Intel.