OpenSkillEval: Automatically Auditing the Open Skill Ecosystem for LLM Agents
Pith reviewed 2026-05-25 04:15 UTC · model grok-4.3
The pith
Many publicly popular skills for LLM agents do not consistently outperform base agents without skills.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
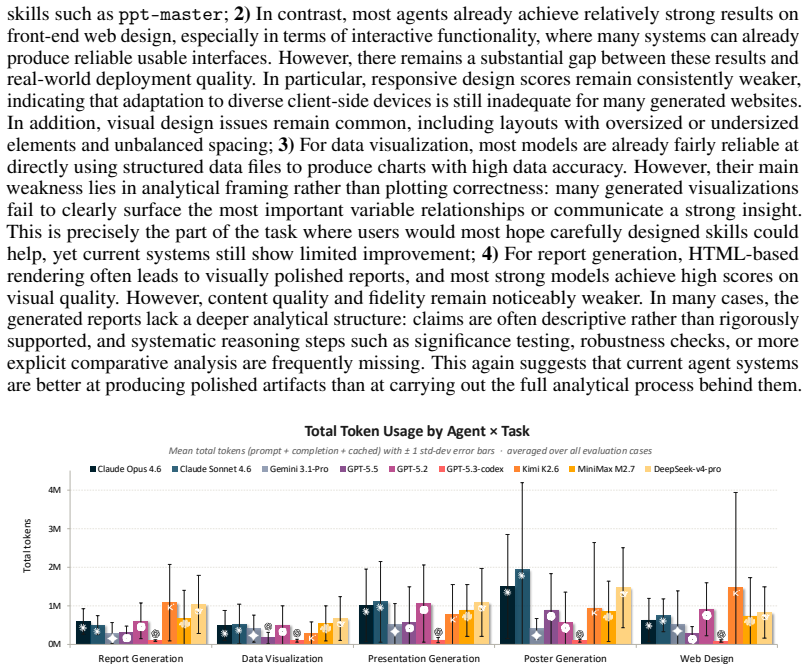
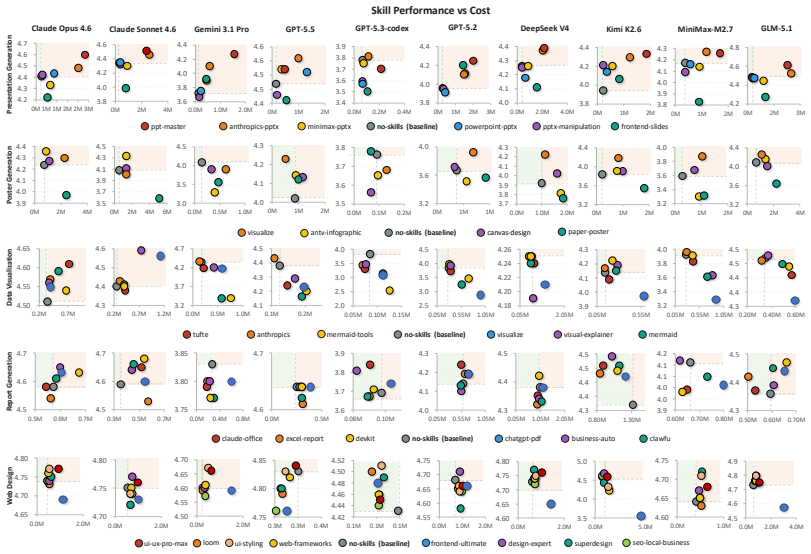
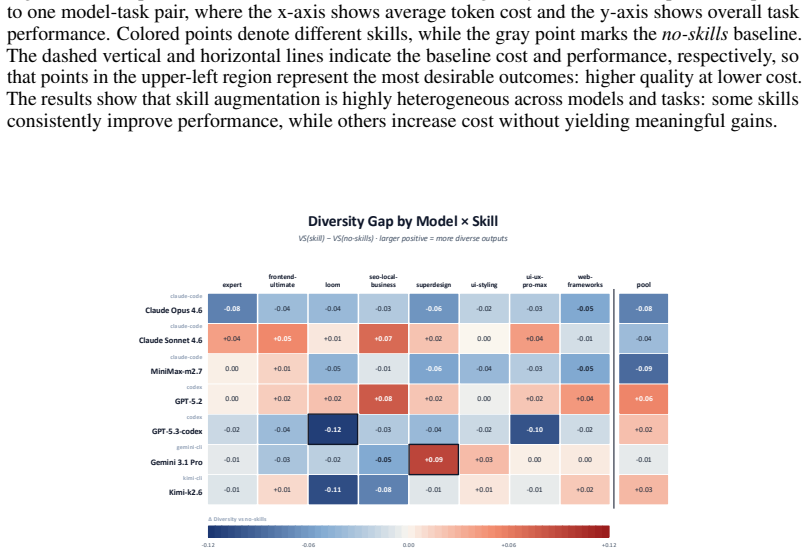
OpenSkillEval automatically constructs realistic task instances from evolving real-world artifacts across five categories of downstream applications and collects community-contributed skills for controlled comparison under unified settings. Using more than 600 dynamically generated task instances and 30 open-source skills, the evaluation shows that skill availability does not guarantee effective skill usage, that the benefit of skill augmentation depends strongly on both the underlying model and the agent framework, and that many publicly popular skills do not consistently outperform base agents without skills.
What carries the argument
OpenSkillEval, an automatic evaluation framework that dynamically generates task instances from real-world artifacts for side-by-side testing of skill-augmented LLM agent systems.
If this is right
- Skill selection must be done per model and per agent framework rather than treating skills as plug-and-play improvements.
- Skill authors should test their instructions across multiple base models instead of a single one.
- Agent frameworks need better mechanisms to decide when to invoke a skill versus running without one.
- The open skill ecosystem would benefit from continuous re-evaluation as models and artifacts evolve.
- Base agents without skills can remain competitive choices when cost or reliability is prioritized.
Where Pith is reading between the lines
- Platforms hosting skills could add automated quality checks that rerun evaluations whenever new models appear.
- The same generation approach could be applied to other agent domains such as code editing or scientific workflows to test generality.
- If skills are to be treated as modular components, the field may need interface standards that reduce model-specific tuning.
- The observed variance suggests that some skills might be better reframed as lightweight prompt templates rather than full workflows.
Load-bearing premise
The dynamically generated task instances drawn from real-world artifacts are realistic enough proxies for actual downstream user tasks.
What would settle it
A controlled study in which real users complete the same categories of tasks with and without the evaluated skills and report measurably higher success rates or lower effort for the popular skills would falsify the claim that many skills fail to outperform base agents.
Figures







read the original abstract
Skills, i.e., structured workflow instructions distilled for large language models (LLMs), are becoming an increasingly important mechanism for improving agent performance on real-world downstream tasks. However, as the open-source skill ecosystem rapidly expands, it remains unclear how different models and agent frameworks interact with skills, how to evaluate skill quality, and how users should select skills under practical cost-performance trade-offs. In this paper, we present \textsc{OpenSkillEval}, an automatic evaluation framework for both skill-augmented agent systems and the skills themselves. Instead of relying on static benchmarks, \textsc{OpenSkillEval} automatically constructs realistic task instances from evolving real-world artifacts across five categories of downstream applications: presentation generation, front-end web design, poster generation, data visualization, and report generation. It further collects and organizes community-contributed skills for controlled comparison under unified task settings. Using more than 600 dynamically generated task instances and 30 open-source skills, we conduct a systematic evaluation of state-of-the-art models and agent frameworks. Our results show that skill availability does not guarantee effective skill usage, that the benefit of skill augmentation depends strongly on both the underlying model and the agent framework, and that many publicly popular skills do not consistently outperform base agents without skills. These findings highlight the need for dynamic, task-grounded evaluation and provide practical insights into the design, selection, and deployment of skills for LLM agents. Additional cases and benchmark resources are available on the project website: https://yingjiahao14.github.io/OpenSkillEval-Web/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OpenSkillEval, an automatic evaluation framework that dynamically constructs over 600 task instances from real-world artifacts across five categories (presentation generation, front-end web design, poster generation, data visualization, report generation). It organizes 30 community-contributed open-source skills for controlled comparison against base agents using state-of-the-art models and frameworks, concluding that skill availability does not guarantee effective usage, that augmentation benefits depend strongly on the underlying model and agent framework, and that many popular skills fail to consistently outperform base agents without skills.
Significance. If the task instances prove representative, the work would offer timely empirical evidence on the practical limitations of the expanding open skill ecosystem for LLM agents, underscoring the value of dynamic, task-grounded evaluation over static benchmarks and supplying actionable insights for skill design and selection.
major comments (2)
- [Methods (task construction)] Methods (task construction): The central claims rest on 600+ dynamically generated instances derived from real-world artifacts, yet the manuscript describes no external validation (expert ratings, comparison to logged user sessions, or hold-out real tasks) to confirm that the automatic construction process yields faithful proxies for downstream user tasks; without this, observed non-improvements and model/framework interactions risk being artifacts of the generation procedure rather than general properties of the skill ecosystem.
- [Evaluation setup] Evaluation setup (§ on experimental design): No details are provided on statistical controls, variance estimation across task instances, or error analysis for the reported comparisons; this leaves the strength of the model- and framework-dependent interaction claims difficult to assess.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief explicit statement of the five task categories and the exact number of skills per category to improve readability.
- [Conclusion] Project website link is provided but the manuscript does not indicate whether the generated task instances and skill implementations are released as open resources.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that directly strengthen the claims regarding task fidelity and statistical rigor.
read point-by-point responses
-
Referee: [Methods (task construction)] The central claims rest on 600+ dynamically generated instances derived from real-world artifacts, yet the manuscript describes no external validation (expert ratings, comparison to logged user sessions, or hold-out real tasks) to confirm that the automatic construction process yields faithful proxies for downstream user tasks; without this, observed non-improvements and model/framework interactions risk being artifacts of the generation procedure rather than general properties of the skill ecosystem.
Authors: We agree that external validation would further substantiate the representativeness of the generated tasks. The construction procedure directly ingests and adapts real-world artifacts (e.g., actual slide decks, web pages, and data tables) rather than synthesizing from scratch, which we argue already provides a stronger proxy than static benchmarks. Nevertheless, to address the concern explicitly, we will add a targeted expert validation study on a random subset of tasks in the revised manuscript. revision: yes
-
Referee: [Evaluation setup] Evaluation setup (§ on experimental design): No details are provided on statistical controls, variance estimation across task instances, or error analysis for the reported comparisons; this leaves the strength of the model- and framework-dependent interaction claims difficult to assess.
Authors: We acknowledge that the current manuscript omits explicit statistical controls and variance reporting. In the revision we will include (1) details of the statistical tests performed to assess model–framework–skill interactions, (2) per-category variance and confidence intervals across the 600+ instances, and (3) a qualitative error analysis highlighting representative failure modes. revision: yes
Circularity Check
No circularity: empirical evaluation independent of inputs
full rationale
The paper presents an empirical auditing framework that constructs task instances from external real-world artifacts and compares skill-augmented agents against base agents using community-contributed skills. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations are present in the derivation of the central claims. Results are measured directly on held-out generated instances rather than reducing to the construction process by definition.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
skill availability does not guarantee effective skill usage; benefit depends strongly on model and framework
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.