TUBE: Tangent Upper Bound on Evidence for Discrete Diffusion Language Models
Pith reviewed 2026-06-30 15:21 UTC · model grok-4.3
The pith
TUBE gives a variational upper bound showing block MDMs and AO-ARMs lie strictly below exact ARM log-likelihood.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TUBE is introduced as a variational upper bound on log-likelihood that admits an unbiased Monte Carlo estimator. When applied to block masked diffusion models and block any-order ARMs, the bound reveals that these models achieve strictly lower likelihood than the exact values obtained by autoregressive models, establishing that ARMs dominate in this metric.
What carries the argument
TUBE, the Tangent Upper Bound on Evidence: a variational upper bound on log-likelihood for latent-variable models that supports an unbiased Monte Carlo estimator.
If this is right
- Likelihood comparisons between ARMs and block diffusion models can now be made with both lower and upper bounds.
- Block MDMs and block AO-ARMs are shown to remain below the exact ARM baseline.
- ARMs continue to dominate discrete diffusion approaches when evaluated by likelihood.
Where Pith is reading between the lines
- Design efforts on diffusion language models may need to target the remaining likelihood gap with ARMs.
- TUBE could be tested on additional families of discrete generative models that lack exact likelihoods.
- If the gap persists under tighter bounds, it would strengthen the case for retaining autoregressive architectures for high-likelihood modeling.
Load-bearing premise
TUBE remains a valid upper bound when applied to the block variants of MDMs and AO-ARMs, and the Monte Carlo estimator stays unbiased under the sampling procedures used.
What would settle it
An exact log-likelihood computation on a small block MDM or block AO-ARM that exceeds the TUBE value computed on the same model would falsify the bound.
Figures

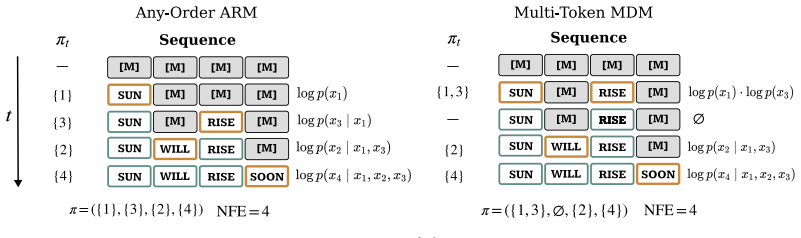
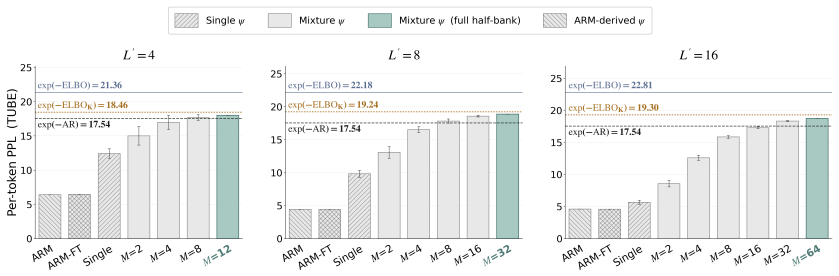


read the original abstract
Log-likelihood is a standard metric for evaluating generative models. Unfortunately, in contrast to autoregressive models (ARMs), discrete diffusion models generally do not admit exact computation of this quantity. Existing evaluations, therefore, rely on the evidence lower bound (ELBO), leaving unclear how much higher the true value may be. We address this by introducing the Tangent Upper Bound on Evidence (TUBE), a variational upper bound on log-likelihood that admits an unbiased Monte Carlo estimator. Our TUBE extends across latent-variable models, including masked diffusion models (MDMs), any-order ARMs (AO-ARMs), and block variants of both. Applied to block MDMs and block AO-ARMs, TUBE reveals our key empirical finding that these models lie strictly below the exact ARM baseline, showing that ARMs still dominate in likelihood.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Tangent Upper Bound on Evidence (TUBE), a variational upper bound on log-likelihood for discrete diffusion language models. TUBE is claimed to admit an unbiased Monte Carlo estimator and to extend to masked diffusion models (MDMs), any-order ARMs (AO-ARMs), and their block variants. Applied to the block variants, TUBE is used to show that these models lie strictly below the exact likelihood of standard ARMs, supporting the conclusion that ARMs dominate in likelihood.
Significance. If the bound holds with the claimed properties, TUBE would supply a practical, unbiased upper bound for evaluating evidence in models where exact log-likelihood is intractable, enabling tighter comparisons between diffusion-style and autoregressive approaches. The reported empirical result would then be a substantive finding for language model evaluation.
major comments (2)
- [§3] §3 (TUBE derivation and extension to block variants): The central claim that TUBE is a valid strict upper bound for block MDMs and block AO-ARMs requires that the tangent construction continues to upper-bound the log-evidence under block masking and sampling. The manuscript provides no re-derivation or verification that the required concavity/curvature conditions on the evidence function still hold after the block modification; without this, the reported strict inequality versus the exact ARM baseline does not follow.
- [§5] §5 (Monte Carlo estimator and experiments): The unbiasedness of the MC estimator for TUBE is asserted for the block variants, but the block sampling procedure introduces additional dependencies that are not shown to preserve unbiasedness. This is load-bearing for the key empirical comparison, as any bias would invalidate the conclusion that block models lie strictly below the ARM baseline.
minor comments (2)
- [§3] Notation for the tangent point and the evidence function should be introduced with an explicit equation before the block extension is discussed.
- [Abstract] The abstract states the empirical finding but does not mention the assumptions required for the bound to apply to block models; a short clarifying sentence would improve readability.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments. We address each major comment below, indicating the revisions we will make.
read point-by-point responses
-
Referee: [§3] §3 (TUBE derivation and extension to block variants): The central claim that TUBE is a valid strict upper bound for block MDMs and block AO-ARMs requires that the tangent construction continues to upper-bound the log-evidence under block masking and sampling. The manuscript provides no re-derivation or verification that the required concavity/curvature conditions on the evidence function still hold after the block modification; without this, the reported strict inequality versus the exact ARM baseline does not follow.
Authors: We agree that an explicit verification is needed for the block case. The concavity of the evidence function is preserved under block masking because the block procedure corresponds to a marginalization over a subset of independent masking variables, which maintains the required curvature. In the revised manuscript we will add a short re-derivation in §3 confirming that the tangent line remains an upper bound and that the strict inequality versus ARMs continues to hold. revision: yes
-
Referee: [§5] §5 (Monte Carlo estimator and experiments): The unbiasedness of the MC estimator for TUBE is asserted for the block variants, but the block sampling procedure introduces additional dependencies that are not shown to preserve unbiasedness. This is load-bearing for the key empirical comparison, as any bias would invalidate the conclusion that block models lie strictly below the ARM baseline.
Authors: We acknowledge that the unbiasedness argument for block sampling was not spelled out. Because the block sampler draws from the exact joint distribution defined by the model (with the block mask applied to the appropriate coordinates), linearity of expectation still guarantees that the Monte Carlo average is unbiased for the TUBE value. In the revision we will insert a short proof of this fact in §5, explicitly treating the block dependencies. revision: yes
Circularity Check
No circularity: TUBE introduced as independent variational construction
full rationale
The provided abstract and context present TUBE as a newly defined variational upper bound admitting an unbiased MC estimator, extended to MDMs/AO-ARMs and block variants, then applied to produce an empirical comparison against exact ARM likelihood. No equations, self-citations, or fitted parameters are quoted that reduce the bound or the strict inequality claim to a definition, prior author result, or input by construction. The derivation chain is self-contained against external benchmarks (exact ARM likelihood) with no load-bearing self-citation or renaming of known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sarah Alamdari, Nitya Thakkar, Rianne van den Berg, Alex X. Lu, Nicolo Fusi, Ava P. Amini, and Kevin K. Yang. Protein generation with evolutionary diffusion: sequence is all you need. bioRxiv, 2023. doi:10.1101/2023.09.11.556673
-
[2]
Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and Volodymyr Kuleshov
Marianne Arriola, Aaron Gokaslan, Justin T. Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and Volodymyr Kuleshov. Block diffusion: Interpolating between autoregressive and diffusion language models. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[3]
Structured denoising diffusion models in discrete state-spaces
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces. Advances in neural information processing systems, 34: 0 17981--17993, 2021
2021
-
[4]
LLaDA2.0: Scaling Up Diffusion Language Models to 100B
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, Chengxi Li, Chongxuan Li, Jianguo Li, Zehuan Li, Huabin Liu, Ling Liu, Guoshan Lu, Xiaocheng Lu, Yuxin Ma, Jianfeng Tan, Lanning Wei, Ji-Rong Wen, Yipeng Xing, Xiaolu Zhang, Junbo Zhao, Da Zheng, Jun Zhou, Junlin Zhou, Zhanchao Zhou, L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Importance weighted autoencoders
Yuri Burda, Roger Grosse, and Ruslan Salakhutdinov. Importance weighted autoencoders. In International Conference on Learning Representations (ICLR), 2016
2016
-
[6]
One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling
Ciprian Chelba, Tomas Mikolov, Mike Schuster, Qi Ge, Thorsten Brants, Phillipp Koehn, and Tony Robinson. One billion word benchmark for measuring progress in statistical language modeling, 2014. URL https://arxiv.org/abs/1312.3005
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[7]
Generative pretraining from pixels
Mark Chen, Alec Radford, Jeff Wu, Heewoo Jun, Prafulla Dhariwal, David Luan, and Ilya Sutskever. Generative pretraining from pixels. In International Conference on Machine Learning, 2020. URL https://api.semanticscholar.org/CorpusID:219781060
2020
-
[8]
Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei
Paul F. Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[9]
Adji Bousso Dieng, Dustin Tran, Rajesh Ranganath, John Paisley, and David M. Blei. Variational inference via -upper bound minimization. In Advances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[10]
Openwebtext corpus
Aaron Gokaslan and Vanya Cohen. Openwebtext corpus. http://Skylion007.github.io/OpenWebTextCorpus, 2019
2019
-
[11]
Vector quantized diffusion model for text-to-image synthesis
Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, Bo Zhang, Dongdong Chen, Lu Yuan, and Baining Guo. Vector quantized diffusion model for text-to-image synthesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10696--10706, 2022
2022
-
[12]
Gurbuz, O g ul Can, and Eli Waxman
Etrit Haxholli, Yeti Z. Gurbuz, O g ul Can, and Eli Waxman. Efficient perplexity bound and ratio matching in discrete diffusion language models. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[13]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33: 0 6840--6851, 2020
2020
-
[14]
Training compute-optimal large language models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, pages 30016--30030, 2022
2022
-
[15]
Gritsenko, Jasmijn Bastings, Ben Poole, Rianne van den Berg, and Tim Salimans
Emiel Hoogeboom, Alexey A. Gritsenko, Jasmijn Bastings, Ben Poole, Rianne van den Berg, and Tim Salimans. Autoregressive diffusion models. In The Tenth International Conference on Learning Representations (ICLR), 2022
2022
-
[16]
Information-theoretic discrete diffusion
Moongyu Jeon, Sangwoo Shin, Dongjae Jeon, and Albert No. Information-theoretic discrete diffusion. arXiv preprint arXiv:2510.24088, 2025
-
[17]
Stochastic variational inference via upper bound
Chunlin Ji and Haige Shen. Stochastic variational inference via upper bound. In NeurIPS Workshop on Bayesian Deep Learning, 2019. arXiv:1912.00650 -- KL-based EUBO; included for completeness, distinct from SPG's R\'enyi-based bound
-
[18]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[19]
FS-DFM : Fast and accurate long text generation with few-step diffusion language models
Amin Karimi Monsefi, Nikhil Bhendawade, Manuel Rafael Ciosici, Dominic Culver, Yizhe Zhang, and Irina Belousova. FS-DFM : Fast and accurate long text generation with few-step diffusion language models. In The Fourteenth International Conference on Learning Representations, 2026
2026
-
[20]
Discriminator guidance for autoregressive diffusion models
Filip Ekstr \"o m Kelvinius and Fredrik Lindsten. Discriminator guidance for autoregressive diffusion models. In International Conference on Artificial Intelligence and Statistics, pages 3403--3411. PMLR, 2024
2024
-
[21]
Mercury: Ultra-Fast Language Models Based on Diffusion
Samar Khanna, Siddhant Kharbanda, Shufan Li, Harshit Varma, Eric Wang, Sawyer Birnbaum, Ziyang Luo, Yanis Miraoui, Akash Palrecha, Stefano Ermon, Aditya Grover, and Volodymyr Kuleshov. Mercury: Ultra-fast language models based on diffusion. arXiv preprint arXiv:2506.17298, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[23]
Genmol: A drug discovery generalist with discrete diffusion
Seul Lee, Karsten Kreis, Srimukh Prasad Veccham, Meng Liu, Danny Reidenbach, Yuxing Peng, Saee Gopal Paliwal, Weili Nie, and Arash Vahdat. Genmol: A drug discovery generalist with discrete diffusion. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=KM7pXWG1xj
2025
-
[24]
Discovering non-monotonic autoregressive orderings with variational inference
Xuanlin Li, Brandon Trabucco, Dong Huk Park, Michael Luo, Sheng Shen, Trevor Darrell, and Yang Gao. Discovering non-monotonic autoregressive orderings with variational inference. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=jP1vTH3inC
2021
-
[25]
Yingzhen Li and Richard E. Turner. R\'enyi divergence variational inference. In Advances in Neural Information Processing Systems (NeurIPS), 2016
2016
-
[26]
Discrete diffusion modeling by estimating the ratios of the data distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution. In Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, 2024
2024
-
[27]
The thermodynamic variational objective
Vaden Masrani, Tuan Anh Le, and Frank Wood. The thermodynamic variational objective. In Advances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[28]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models. arXiv preprint arXiv:2502.09992, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Your absorbing discrete diffusion secretly models the conditional distributions of clean data
Jingyang Ou, Shen Nie, Kaiwen Xue, Fengqi Zhu, Jiacheng Sun, Zhenguo Li, and Chongxuan Li. Your absorbing discrete diffusion secretly models the conditional distributions of clean data. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[30]
Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[31]
Art B. Owen. Monte Carlo theory, methods and examples. Stanford University, 2013
2013
-
[32]
Randar: Decoder-only autoregressive visual generation in random orders
Ziqi Pang, Tianyuan Zhang, Fujun Luan, Yunze Man, Hao Tan, Kai Zhang, William T Freeman, and Yu-Xiong Wang. Randar: Decoder-only autoregressive visual generation in random orders. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 45--55, 2025
2025
-
[33]
Mauve: Measuring the gap between neural text and human text using divergence frontiers
Krishna Pillutla, Swabha Swayamdipta, Rowan Zellers, John Thickstun, Sean Welleck, Yejin Choi, and Zaid Harchaoui. Mauve: Measuring the gap between neural text and human text using divergence frontiers. In Advances in Neural Information Processing Systems, 2021
2021
-
[34]
Generative Frontiers: Why Evaluation Matters for Diffusion Language Models
Patrick Pynadath, Jiaxin Shi, and Ruqi Zhang. Generative frontiers: Why evaluation matters for diffusion language models. arXiv preprint arXiv:2604.02718, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Improving language understanding by generative pre-training
Alec Radford and Karthik Narasimhan. Improving language understanding by generative pre-training. 2018. URL https://api.semanticscholar.org/CorpusID:49313245
2018
-
[36]
Manning, Stefano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[37]
Chiu, Alexander M
Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T. Chiu, Alexander M. Rush, and Volodymyr Kuleshov. Simple and effective masked diffusion language models. In Advances in Neural Information Processing Systems, volume 37, 2024
2024
-
[38]
Esoteric Language Models: A Family of Any-Order Diffusion LLMs
Subham Sekhar Sahoo, Zhihan Yang, Yash Akhauri, Johnna Liu, Deepansha Singh, Zhoujun Cheng, Zhengzhong Liu, Eric Xing, John Thickstun, and Arash Vahdat. Esoteric language models. arXiv preprint arXiv:2506.01928, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Beyond single tokens: Distilling discrete diffusion models via discrete MMD
Tim Salimans, Thomas Mensink, Jonathan Heek, and Emiel Hoogeboom. Beyond single tokens: Distilling discrete diffusion models via discrete MMD . arXiv preprint arXiv:2603.20155, 2026
-
[40]
Learning flexible forward trajectories for masked molecular diffusion
Hyunjin Seo, Taewon Kim, Sihyun Yu, and SungSoo Ahn. Learning flexible forward trajectories for masked molecular diffusion. arXiv preprint arXiv:2505.16790, 2025
-
[41]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. DeepSeekMath : Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Simplified and generalized masked diffusion for discrete data
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis Titsias. Simplified and generalized masked diffusion for discrete data. Advances in neural information processing systems, 37: 0 103131--103167, 2024
2024
-
[43]
Training and inference on any-order autoregressive models the right way
Andy Shih, Dorsa Sadigh, and Stefano Ermon. Training and inference on any-order autoregressive models the right way. Advances in Neural Information Processing Systems, 35: 0 2762--2775, 2022
2022
-
[44]
Bounding evidence and estimating log-likelihood in VAE
ukasz Struski, Marcin Mazur, Pawe Batorski, Przemys aw Spurek, and Jacek Tabor. Bounding evidence and estimating log-likelihood in VAE . In Proceedings of The 26th International Conference on Artificial Intelligence and Statistics, volume 206 of Proceedings of Machine Learning Research, pages 675--693, 2023
2023
-
[45]
DUEL : Exact likelihood for masked diffusion via deterministic unmasking
Gilad Turok, Chris De Sa, and Volodymyr Kuleshov. DUEL : Exact likelihood for masked diffusion via deterministic unmasking. arXiv preprint arXiv:2603.01367, 2026
-
[46]
A deep and tractable density estimator
Benigno Uria, Iain Murray, and Hugo Larochelle. A deep and tractable density estimator. In International Conference on Machine Learning, pages 467--475. PMLR, 2014
2014
-
[47]
SPG : Sandwiched policy gradient for masked diffusion language models
Chenyu Wang, Paria Rashidinejad, DiJia Su, Song Jiang, Sid Wang, Siyan Zhao, Cai Zhou, Shannon Zejiang Shen, Feiyu Chen, Tommi Jaakkola, Yuandong Tian, and Bo Liu. SPG : Sandwiched policy gradient for masked diffusion language models. In The Fourteenth International Conference on Learning Representations, 2026. Poster
2026
-
[48]
DPLM-2 : A multimodal diffusion protein language model
Xinyou Wang, Zaixiang Zheng, Fei Ye, Dongyu Xue, Shujian Huang, and Quanquan Gu. DPLM-2 : A multimodal diffusion protein language model. In The Thirteenth International Conference on Learning Representations (ICLR), 2025 a
2025
-
[49]
Learning-order autoregressive models with application to molecular graph generation
Zhe Wang, Jiaxin Shi, Nicolas Heess, Arthur Gretton, and Michalis Titsias. Learning-order autoregressive models with application to molecular graph generation. In Forty-second International Conference on Machine Learning, 2025 b . URL https://openreview.net/forum?id=EY6pXIDi3G
2025
-
[50]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models. arXiv preprint arXiv:2508.15487, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Masked diffusion models are secretly time-agnostic masked models and exploit inaccurate categorical sampling
Kaiwen Zheng, Yongxin Chen, Hanzi Mao, Ming-Yu Liu, Jun Zhu, and Qinsheng Zhang. Masked diffusion models are secretly time-agnostic masked models and exploit inaccurate categorical sampling. In The Thirteenth International Conference on Learning Representations (ICLR), 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.