Recognition: 2 theorem links
· Lean TheoremGenerative Frontiers: Why Evaluation Matters for Diffusion Language Models
Pith reviewed 2026-05-13 20:08 UTC · model grok-4.3
The pith
Diffusion language models need generative frontiers, not just perplexity, to evaluate quality reliably.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
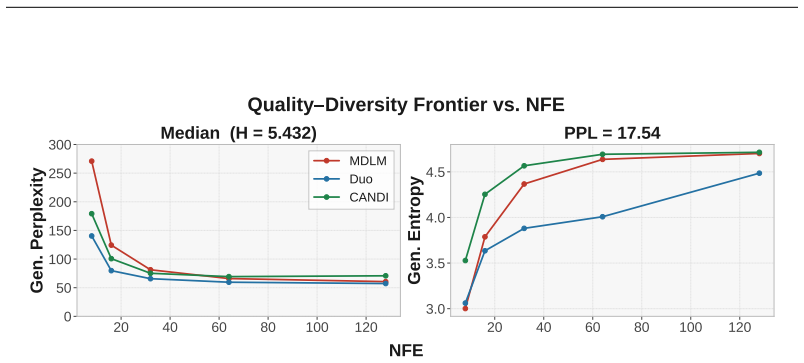
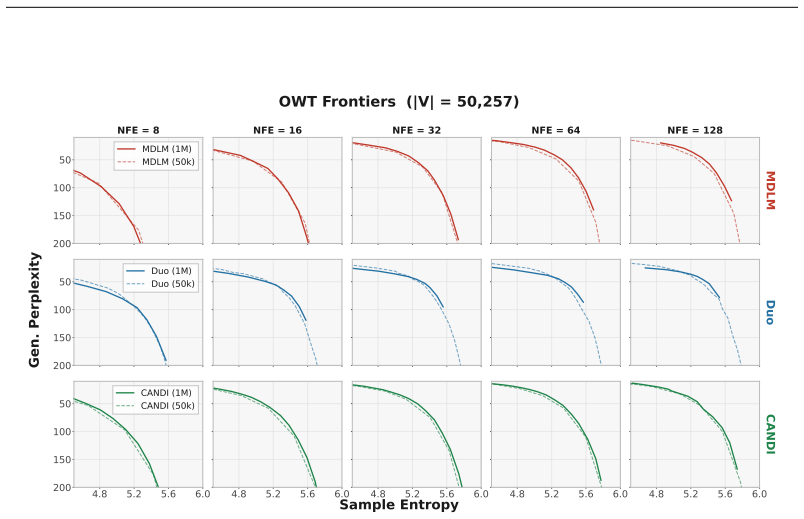
Generative perplexity and entropy together constitute the KL divergence to a reference distribution, which explains perplexity's sensitivity to entropy and motivates the use of generative frontiers to assess diffusion language model quality.
What carries the argument
The decomposition of KL divergence into generative perplexity and entropy components, which defines generative frontiers as a joint evaluation method.
If this is right
- Evaluations become more informative by considering both perplexity and entropy rather than perplexity alone.
- Comparisons between different diffusion language models can avoid misleading results from entropy variations.
- Model development at small scales like 150 million parameters can use this method to track genuine progress.
Where Pith is reading between the lines
- Generative frontiers could be applied to compare diffusion models against autoregressive ones more fairly.
- Testing the frontiers on larger models might reveal if the evaluation scales without new biases.
- Other generative models beyond diffusion could benefit from similar KL-based decompositions.
Load-bearing premise
The OpenWebText reference distribution correctly represents the desired target for measuring generative quality without selection biases.
What would settle it
Finding that models with better generative frontiers do not produce higher quality samples according to human evaluation would challenge the method's validity.
Figures




read the original abstract
Diffusion language models have seen exciting recent progress, offering far more flexibility in generative trajectories than autoregressive models. This flexibility has motivated a growing body of research into new approaches to diffusion language modeling, which typically begins at the scale of GPT-2 small (150 million parameters). However, these advances introduce new issues with evaluation methodology. In this technical note, we discuss the limitations of current methodology and propose principled augmentations to ensure reliable comparisons. We first discuss why OpenWebText has become the standard benchmark, and why alternatives such as LM1B are inherently less meaningful. We then discuss the limitations of likelihood evaluations for diffusion models, and explain why relying on generative perplexity alone as a metric can lead to uninformative results. To address this, we show that generative perplexity and entropy are two components of the KL divergence to a reference distribution. This decomposition explains generative perplexity's sensitivity to entropy, and naturally suggests generative frontiers as a principled method for evaluating model generative quality. We conclude with empirical observations on model quality at this scale. We include a blog post with interactive content to illustrate the argument at https://patrickpynadath1.github.io/blog/eval_methodology/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a technical note arguing that evaluation of diffusion language models (at GPT-2-small scale) is hampered by reliance on likelihood metrics and generative perplexity alone. It justifies OpenWebText as the standard benchmark over alternatives such as LM1B, shows that generative perplexity and entropy form an exact additive decomposition of KL divergence to a fixed reference distribution, uses this identity to explain observed sensitivities, and proposes generative frontiers as a more principled evaluation method, supported by empirical observations at this scale.
Significance. If the decomposition holds (as an algebraic identity) and generative frontiers can be estimated without new biases, the work supplies a mathematically grounded augmentation to current evaluation practices for diffusion LMs. The direct tie to KL divergence without fitted parameters is a clear strength, and the note could help standardize more reliable comparisons as these models develop greater generative flexibility than autoregressive baselines.
major comments (2)
- [generative frontiers proposal] The section proposing generative frontiers: the method's status as 'principled' depends on the reference distribution (tied to OpenWebText) being the appropriate target for generative quality; the manuscript provides no sensitivity analysis or justification for this choice, which is load-bearing for the claim that frontiers yield reliable model comparisons.
- [empirical observations] Empirical observations section: the claims about model quality at GPT-2-small scale rest on observations whose details (exact metrics, sample sizes, or frontier estimation procedure) are not reported, preventing assessment of whether the decomposition actually improves evaluation in practice.
minor comments (2)
- The decomposition identity should be written out explicitly with the relevant equations (e.g., relating perplexity, entropy, and KL) rather than described only in prose, to allow immediate verification.
- The provided blog link is useful, but the manuscript should summarize the interactive illustrations so the core argument remains self-contained without external resources.
Simulated Author's Rebuttal
We thank the referee for the constructive review and recommendation for minor revision. We address each major comment below and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: [generative frontiers proposal] The section proposing generative frontiers: the method's status as 'principled' depends on the reference distribution (tied to OpenWebText) being the appropriate target for generative quality; the manuscript provides no sensitivity analysis or justification for this choice, which is load-bearing for the claim that frontiers yield reliable model comparisons.
Authors: The manuscript includes a dedicated discussion justifying OpenWebText as the standard benchmark for diffusion language models at GPT-2-small scale, along with an explanation of why alternatives such as LM1B are inherently less suitable. This provides the rationale for tying the reference distribution to OpenWebText. We agree, however, that an explicit sensitivity analysis is absent and would strengthen the claim. In the revised manuscript we will add a short paragraph discussing robustness to reference choice, for instance by noting the algebraic invariance of the decomposition for any fixed reference and briefly considering the effect of a modest corpus perturbation where data permits. revision: partial
-
Referee: [empirical observations] Empirical observations section: the claims about model quality at GPT-2-small scale rest on observations whose details (exact metrics, sample sizes, or frontier estimation procedure) are not reported, preventing assessment of whether the decomposition actually improves evaluation in practice.
Authors: We acknowledge that the empirical observations section does not report the precise metrics, sample sizes, or the exact procedure used to estimate the generative frontiers. These details are necessary for reproducibility and for readers to evaluate the practical benefit of the decomposition. In the revised version we will expand the section to include this information, specifying the number of generated samples, the exact formulas employed for entropy and generative perplexity, and the method for constructing and comparing the frontiers. revision: yes
Circularity Check
No significant circularity; decomposition is direct algebraic identity
full rationale
The paper's core claim decomposes generative perplexity and entropy as additive components of KL divergence to a fixed reference distribution. This is exactly the standard identity KL(P||Q) = H(P) + cross-entropy(P,Q), with generative perplexity corresponding to the cross-entropy term. No parameters are fitted to data and then relabeled as predictions, no self-citation chain is load-bearing for the identity, and the reference distribution is adopted from prior literature rather than derived from the models under test. The derivation chain is therefore self-contained and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math KL divergence between model and reference distribution decomposes additively into a perplexity term and an entropy term
- domain assumption OpenWebText is the appropriate reference distribution for evaluating generative quality of diffusion language models at GPT-2-small scale
invented entities (1)
-
generative frontiers
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearKL(qgen∥pref) = H(qgen, pref) − H(qgen). The first term is the cross-entropy ... which is precisely what generative perplexity measures. The second term is the entropy of the generative distribution
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearGenPPL(qgen) = exp(KL(qgen∥pref) + H(qgen))
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Marianne Arriola, Aaron Gokaslan, Justin T Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and Volodymyr Kuleshov. Block diffusion: Interpolating between autoregressive and diffusion language models. In The Thirteenth International Conference on Learning Representations, 2025. URL https://arxiv.org/abs/2503.09573
-
[3]
Pattern Recognition and Machine Learning, volume 4
Christopher M Bishop. Pattern Recognition and Machine Learning, volume 4. Springer, New York, 2006. ISBN 978-0-387-31073-2. Section 10.1
work page 2006
-
[4]
One billion word benchmark for measuring progress in statistical language modeling
Ciprian Chelba, Tomas Mikolov, Mike Schuster, Qi Ge, Thorsten Brants, Phillipp Koehn, and Tony Robinson. One billion word benchmark for measuring progress in statistical language modeling, 2014. URL https://arxiv.org/abs/1312.3005
-
[5]
Aaron Gokaslan, Vanya Cohen, Ellie Pavlick, and Stefanie Tellex. Openwebtext corpus. http://Skylion007.github.io/OpenWebTextCorpus, 2019
work page 2019
-
[6]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution. 0 (arXiv:2310.16834), June 2024. doi:10.48550/arXiv.2310.16834. URL http://arxiv.org/abs/2310.16834. arXiv:2310.16834
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.16834 2024
-
[7]
Candi: Hybrid discrete-continuous diffusion models.arXiv preprint arXiv:2510.22510, 2025
Patrick Pynadath, Jiaxin Shi, and Ruqi Zhang. Candi: Hybrid discrete-continuous diffusion models, 2025. URL https://arxiv.org/abs/2510.22510
-
[8]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pp.\ 8748--8763. PmLR, 2021
work page 2021
-
[9]
Chiu, Alexander Rush, and Volodymyr Kuleshov
Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T. Chiu, Alexander Rush, and Volodymyr Kuleshov. Simple and effective masked diffusion language models. 0 (arXiv:2406.07524), November 2024. doi:10.48550/arXiv.2406.07524. URL http://arxiv.org/abs/2406.07524. arXiv:2406.07524
-
[10]
Subham Sekhar Sahoo, Justin Deschenaux, Aaron Gokaslan, Guanghan Wang, Justin T Chiu, and Volodymyr Kuleshov. The diffusion duality. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=9P9Y8FOSOk
work page 2025
-
[11]
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis K. Titsias. Simplified and generalized masked diffusion for discrete data. 0 (arXiv:2406.04329), June 2024. doi:10.48550/arXiv.2406.04329. URL http://arxiv.org/abs/2406.04329. arXiv:2406.04329
-
[12]
A note on the evaluation of generative models
Lucas Theis, Aäron van den Oord, and Matthias Bethge. A note on the evaluation of generative models, 2016. URL https://arxiv.org/abs/1511.01844
work page Pith review arXiv 2016
-
[13]
Kaiwen Zheng, Yongxin Chen, Hanzi Mao, Ming-Yu Liu, Jun Zhu, and Qinsheng Zhang. Masked diffusion models are secretly time-agnostic masked models and exploit inaccurate categorical sampling. arXiv preprint arXiv:2409.02908, 2024
-
[14]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[15]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[16]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.