LLMTabBench: Evaluating LLMs on Binary Tabular Classification From Zero to Few Shots
Pith reviewed 2026-06-30 14:22 UTC · model grok-4.3
The pith
Large language models can match or exceed few-shot performance on binary tabular classification using only zero-shot task descriptions, but additional examples sometimes degrade results due to conflicts with prior knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
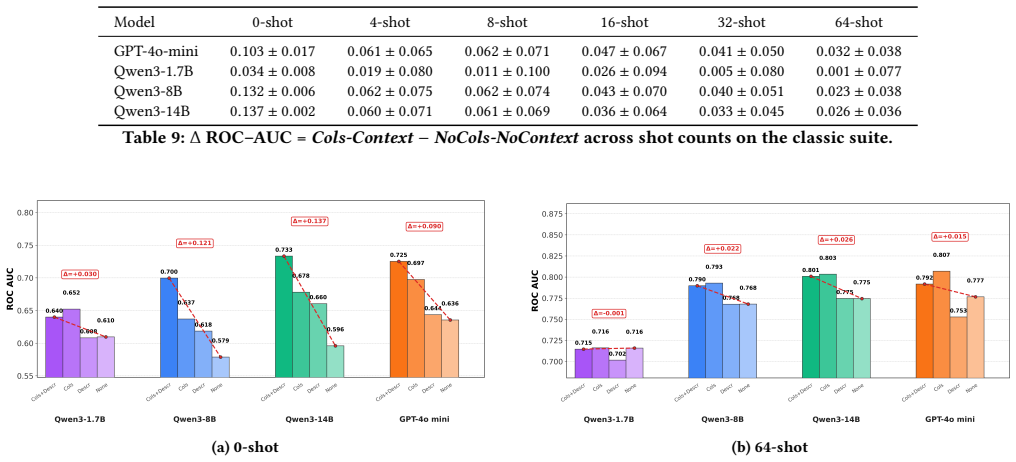
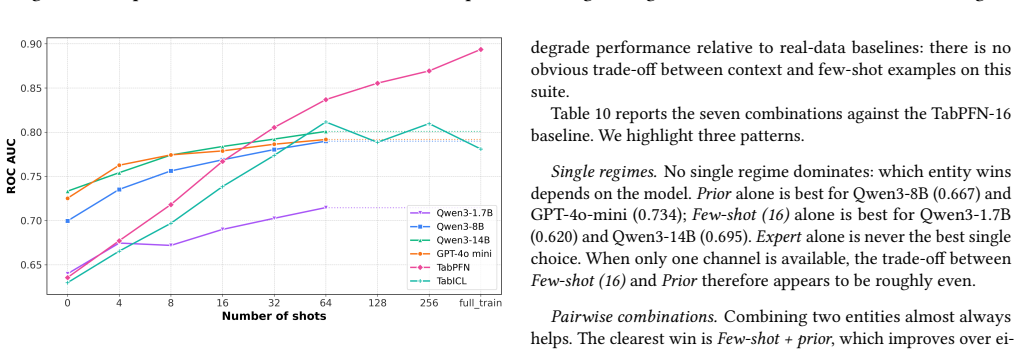
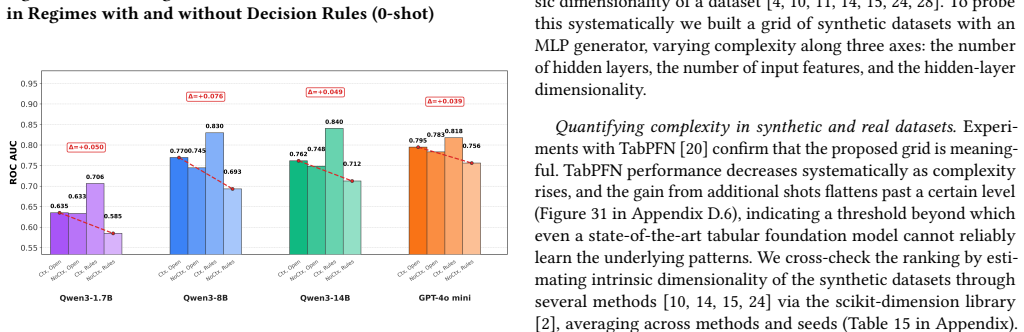
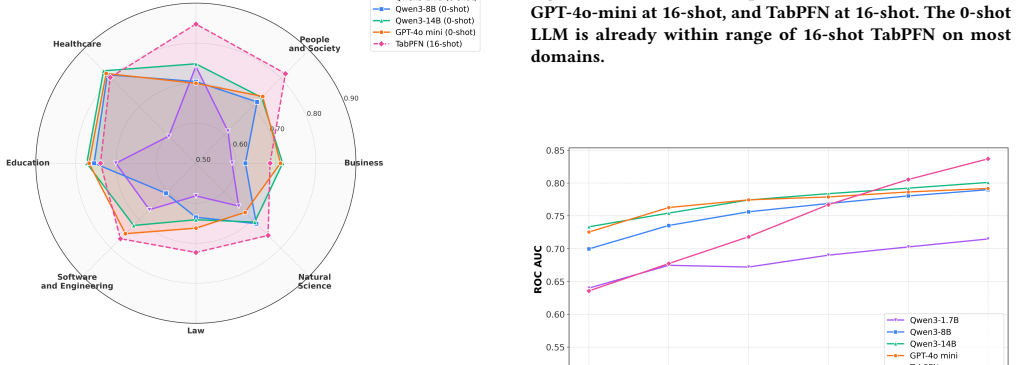
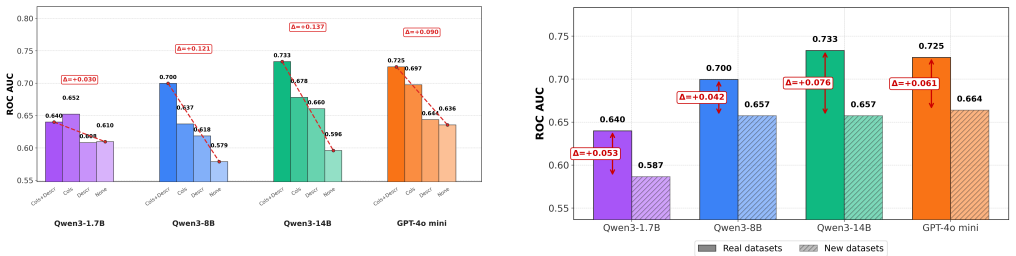
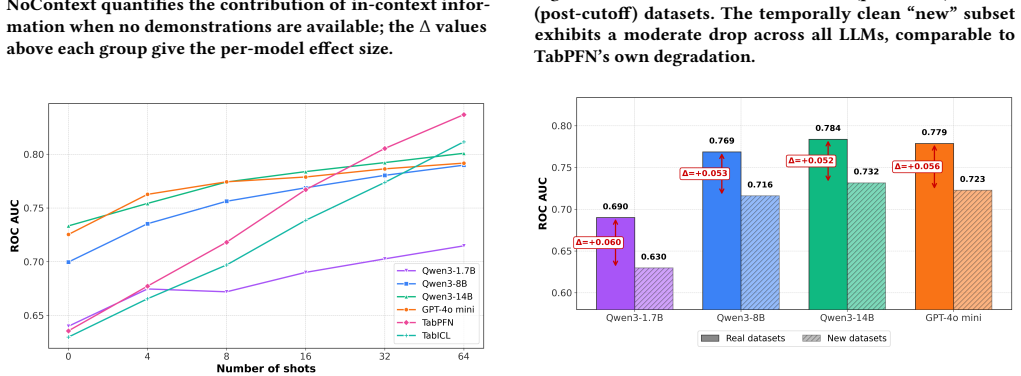
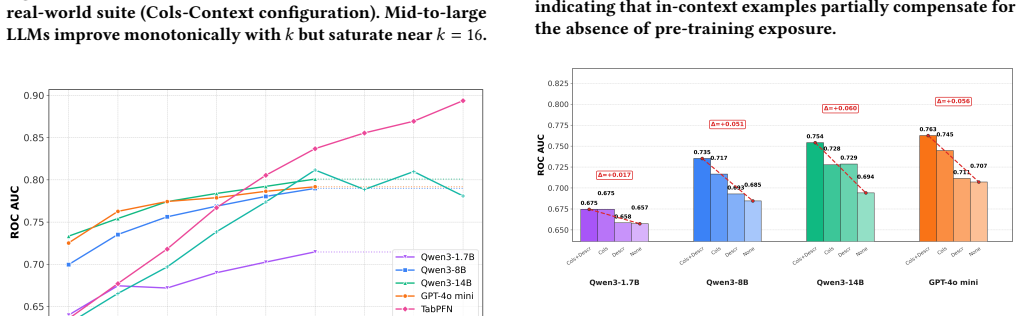
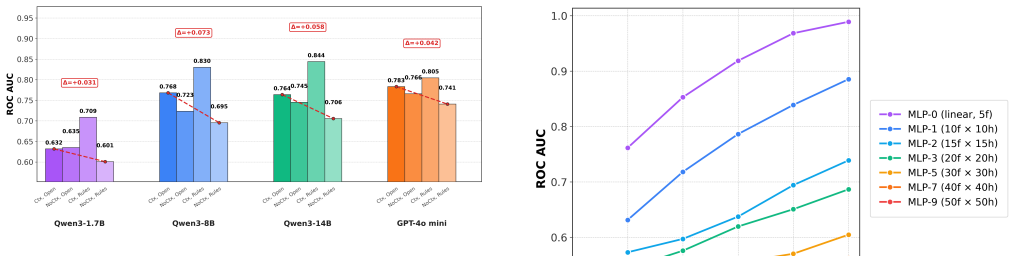
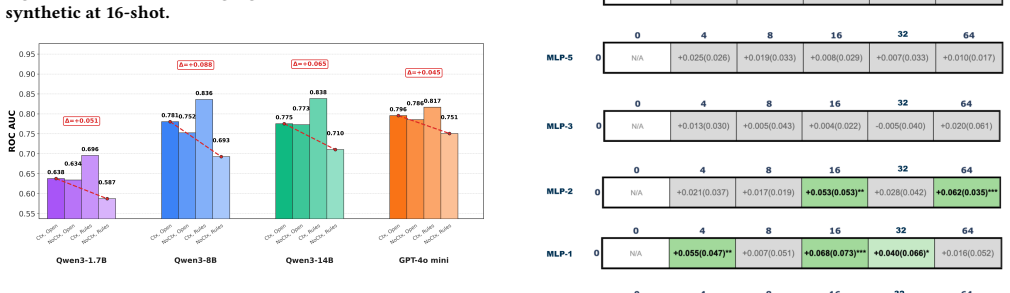
LLMs achieve competitive or superior accuracy on binary tabular classification in zero-shot settings compared to few-shot, with examples sometimes conflicting with prior knowledge to reduce performance, and a complexity threshold beyond which LLM effectiveness drops and examples become less useful.
What carries the argument
LLMTabBench benchmark evaluating LLM interactions between prior knowledge, task descriptions, and in-context examples across real-world and synthetic datasets of varying complexity.
If this is right
- Zero-shot LLM use can suffice or outperform few-shot for certain tabular problems.
- In-context examples must be chosen to align with rather than contradict model knowledge.
- There exists a data complexity level where LLM tabular classification stops scaling with more shots.
- The benchmark reveals limits of in-context learning for tabular data in low-data regimes.
Where Pith is reading between the lines
- Prior knowledge in LLMs may serve a role similar to large-scale pretraining on synthetic data for tabular tasks.
- Methods to mitigate knowledge conflicts could extend the usefulness of few-shot prompting.
- The findings may generalize to multi-class or regression tasks on tabular data if similar patterns hold.
- Testing on additional real-world domains could confirm the complexity threshold.
Load-bearing premise
The selected real-world and synthetic datasets with their task descriptions capture the typical interactions between LLM knowledge and examples in low-data tabular classification.
What would settle it
Observing consistent performance gains from additional examples without degradation across a broader range of tabular datasets or no clear drop at higher complexities would challenge the claims.
Figures











read the original abstract
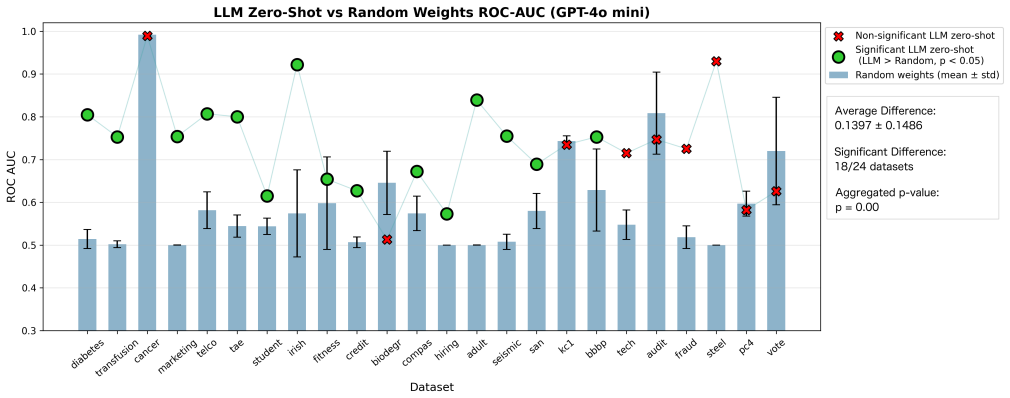
Supervised classification on tabular data remains a central machine learning task, but its dependence on large labeled datasets limits its applicability in data-scarce settings. Few-shot methods such as TabPFN achieve strong performance through large-scale synthetic pretraining, yet still require labeled context examples. Large Language Models (LLMs) offer a more flexible alternative through zero- and few-shot in-context learning from task descriptions, but their behavior on tabular data remains inconsistent. We introduce LLMTabBench, a benchmark for evaluating LLMs on tabular classification under low-data conditions. The benchmark studies how LLM prior knowledge interacts with task descriptions and few-shot examples, and how performance changes with increasing data complexity across real-world and controlled synthetic datasets. We find that LLMs can be highly competitive in zero-shot settings, sometimes outperforming models given few-shot examples. However, additional examples may conflict with prior knowledge, thereby degrading performance. We also observe a complexity threshold at which LLM performance declines and few-shot examples become less useful. These results clarify key limits of in-context learning for tabular data and inform the deployment of LLMs in low-data regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LLMTabBench, a benchmark for evaluating LLMs on binary tabular classification in zero- to few-shot regimes. It studies interactions between LLM prior knowledge, task descriptions, and in-context examples on real-world and synthetic datasets, claiming that LLMs are often competitive (sometimes superior) in zero-shot settings, that adding examples can degrade performance by conflicting with priors, and that a complexity threshold exists beyond which few-shot examples become less useful.
Significance. If the empirical patterns hold after addressing controls, the benchmark and findings would usefully document limits of in-context learning on tabular data and inform when zero-shot LLM use is preferable to few-shot in low-data settings. The inclusion of both real and controlled synthetic data is a positive design choice for isolating complexity effects.
major comments (2)
- [Abstract and §4] Abstract and §4 (results on few-shot degradation): the mechanistic claim that performance drops occur because 'additional examples may conflict with prior knowledge' is not supported by controls that isolate this from confounds such as prompt length, token budget, or example noise. No label-flip or consistency-controlled experiments (holding features and length fixed while varying label agreement with priors) are described.
- [§3] §3 (dataset and task construction): the representativeness assumption underlying generalization of the complexity-threshold and prior-knowledge interaction findings is not justified. No analysis shows that the chosen real-world and synthetic datasets span the relevant distribution of tabular problems or that task descriptions are typical of deployment scenarios.
minor comments (2)
- [§2] Notation for zero-shot vs. few-shot prompting variants should be defined once in §2 and used consistently in all tables and figures.
- [Figures in §4] Figure captions for performance-vs-complexity plots should explicitly state the number of runs, error-bar definition, and whether statistical significance tests were applied.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond to each major point below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] the mechanistic claim that performance drops occur because 'additional examples may conflict with prior knowledge' is not supported by controls that isolate this from confounds such as prompt length, token budget, or example noise. No label-flip or consistency-controlled experiments (holding features and length fixed while varying label agreement with priors) are described.
Authors: We agree that the manuscript interprets the observed degradation in few-shot performance as potentially arising from conflicts with model priors, but does so on the basis of patterns across real and synthetic datasets rather than through experiments that hold prompt length and features fixed while varying label agreement. No label-flip or consistency-controlled ablations are present. We will revise the abstract and §4 to present the prior-conflict account as one plausible interpretation supported by the data, while explicitly acknowledging alternative explanations (including length and noise effects) and noting the absence of isolating controls. A short paragraph will be added to the discussion outlining how such controls could be implemented in follow-up work. revision: yes
-
Referee: [§3] the representativeness assumption underlying generalization of the complexity-threshold and prior-knowledge interaction findings is not justified. No analysis shows that the chosen real-world and synthetic datasets span the relevant distribution of tabular problems or that task descriptions are typical of deployment scenarios.
Authors: The datasets were selected to cover multiple real-world domains together with synthetic constructions that systematically vary complexity; however, the manuscript contains no formal analysis demonstrating that the collection is representative of the broader space of tabular classification tasks or that the task descriptions mirror typical deployment phrasing. We will revise §3 to clarify the selection rationale and will add a dedicated limitations subsection that discusses the scope of the benchmark, the generalizability of the reported thresholds and interactions, and the need for wider validation across additional tabular distributions and prompt styles. revision: yes
Circularity Check
Empirical benchmark evaluation with no derivations or self-referential structure
full rationale
This paper introduces LLMTabBench as an empirical evaluation framework for LLMs on binary tabular classification in zero- and few-shot regimes. The central claims consist of observed performance patterns across real-world and synthetic datasets, with no equations, parameter fitting presented as prediction, uniqueness theorems, or ansatzes. All load-bearing statements are direct experimental outcomes rather than reductions to prior self-citations or input definitions. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sercan Ö Arik and Tomas Pfister. 2021. Tabnet: Attentive interpretable tabular learning. InProceedings of the AAAI conference on artificial intelligence, Vol. 35. 6679–6687
2021
-
[2]
Jonathan Bac, Evgeny M Mirkes, Alexander N Gorban, Ivan Tyukin, and Andrei Zinovyev. 2021. Scikit-dimension: a python package for intrinsic dimension estimation.Entropy23, 10 (2021), 1368
2021
-
[3]
Bernd Bischl, Giuseppe Casalicchio, Matthias Feurer, Pieter Gijsbers, Frank Hut- ter, Michel Lang, Rafael Gomes Mantovani, Jan N van Rijn, and Joaquin Van- schoren. 2021. Openml: A benchmarking layer on top of openml to quickly create, download, and share systematic benchmarks.NeurIPS–Track on Datasets and Benchmarks(2021)
2021
-
[4]
Kevin M Carter, Raviv Raich, and Alfred O Hero III. 2009. On local intrinsic dimension estimation and its applications.IEEE Transactions on Signal Processing 58, 2 (2009), 650–663
2009
-
[5]
Jintai Chen, Kuanlun Liao, Yao Wan, Danny Z Chen, and Jian Wu. 2022. Danets: Deep abstract networks for tabular data classification and regression. InProceed- ings of the AAAI Conference on Artificial Intelligence, Vol. 36. 3930–3938
2022
-
[6]
Tianqi Chen. 2016. XGBoost: A Scalable Tree Boosting System.Cornell University (2016)
2016
- [7]
-
[8]
Elizabeth R DeLong, David M DeLong, and Daniel L Clarke-Pearson. 1988. Com- paring the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach.Biometrics(1988), 837–845
1988
-
[9]
Nick Erickson, Lennart Purucker, Andrej Tschalzev, David Holzmüller, Pra- teek Mutalik Desai, David Salinas, and Frank Hutter. 2025. Tabarena: A living benchmark for machine learning on tabular data.arXiv preprint arXiv:2506.16791 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Elena Facco, Maria d’Errico, Alex Rodriguez, and Alessandro Laio. 2017. Estimat- ing the intrinsic dimension of datasets by a minimal neighborhood information. Scientific reports7, 1 (2017), 12140
2017
-
[11]
Mingyu Fan, Nannan Gu, Hong Qiao, and Bo Zhang. 2010. Intrinsic dimension estimation of data by principal component analysis.arXiv preprint arXiv:1002.2050 (2010)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[12]
Ronald A Fisher. 1922. On the interpretation of 𝜒 2 from contingency tables, and the calculation of P.Journal of the royal statistical society85, 1 (1922), 87–94
1922
-
[13]
Ronald Aylmer Fisher. 1970. Statistical methods for research workers. InBreak- throughs in statistics: Methodology and distribution. Springer, 66–70
1970
-
[14]
Keinosuke Fukunaga and David R Olsen. 1971. An algorithm for finding intrinsic dimensionality of data.IEEE Transactions on computers100, 2 (1971), 176–183
1971
- [15]
- [16]
-
[17]
Aditya Gorla and Ratish Puduppully. 2026. The Illusion of Generalization: Re- examining Tabular Language Model Evaluation.arXiv preprint arXiv:2602.04031 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Léo Grinsztajn, Klemens Flöge, Oscar Key, Felix Birkel, Philipp Jund, Brendan Roof, Benjamin Jäger, Dominik Safaric, Simone Alessi, Adrian Hayler, et al. 2025. Tabpfn-2.5: Advancing the state of the art in tabular foundation models.arXiv preprint arXiv:2511.08667(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Stefan Hegselmann, Alejandro Buendia, Hunter Lang, Monica Agrawal, Xiaoyi Jiang, and David Sontag. 2023. Tabllm: Few-shot classification of tabular data with large language models. InInternational conference on artificial intelligence and statistics. PMLR, 5549–5581
2023
-
[20]
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. 2022. Tabpfn: A transformer that solves small tabular classification problems in a second.arXiv preprint arXiv:2207.01848(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Xin Huang, Ashish Khetan, Milan Cvitkovic, and Zohar Karnin. 2012. Tabtrans- former: tabular data modeling using contextual embeddings (2020).arXiv preprint arXiv:2012.06678(2012)
work page internal anchor Pith review Pith/arXiv arXiv 2012
- [22]
-
[23]
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. 2017. Lightgbm: A highly efficient gradient boosting decision tree.Advances in neural information processing systems30 (2017)
2017
-
[24]
Elizaveta Levina and Peter Bickel. 2004. Maximum likelihood estimation of intrinsic dimension.Advances in neural information processing systems17 (2004)
2004
-
[25]
Ruixue Liu, Shaozu Yuan, Aijun Dai, Lei Shen, Tiangang Zhu, Meng Chen, and Xiaodong He. 2022. Few-Shot Table Understanding: A Benchmark Dataset and Pre-Training Baseline. InProceedings of the 29th International Conference on Computational Linguistics, Nicoletta Calzolari, Chu-Ren Huang, Hansaem Kim, James Pustejovsky, Leo Wanner, Key-Sun Choi, Pum-Mo Ryu,...
2022
-
[26]
Hariharan Manikandan, Yiding Jiang, and J Zico Kolter. 2023. Language models are weak learners.Advances in Neural Information Processing Systems36 (2023), 50907–50931
2023
-
[27]
Duncan McElfresh, Sujay Khandagale, Jonathan Valverde, Vishak Prasad C, Ganesh Ramakrishnan, Micah Goldblum, and Colin White. 2023. When do neural nets outperform boosted trees on tabular data?Advances in Neural Information Processing Systems36 (2023), 76336–76369
2023
-
[28]
Evgeny M Mirkes, Jeza Allohibi, and Alexander Gorban. 2020. Fractional norms and quasinorms do not help to overcome the curse of dimensionality.Entropy 22, 10 (2020), 1105
2020
-
[29]
Liudmila Prokhorenkova, Gleb Gusev, Aleksandr Vorobev, Anna Veronika Doro- gush, and Andrey Gulin. 2018. CatBoost: unbiased boosting with categorical features.Advances in neural information processing systems31 (2018)
2018
-
[30]
Jingang QU, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. 2025. TabICL: A Tabular Foundation Model for In-Context Learning on Large Data. In Forty-second International Conference on Machine Learning. https://openreview .net/forum?id=0VvD1PmNzM
2025
- [31]
-
[32]
Samuel A Stouffer, Edward A Suchman, Leland C DeVinney, Shirley A Star, and Robin M Williams Jr. 1949. The american soldier: Adjustment during army life.(studies in social psychology in world war ii), vol. 1. (1949)
1949
- [33]
-
[34]
Dongjie Wang, Yanyong Huang, Wangyang Ying, Haoyue Bai, Nanxu Gong, Xinyuan Wang, Sixun Dong, Tao Zhe, Kunpeng Liu, Meng Xiao, et al. 2025. To- wards data-centric ai: A comprehensive survey of traditional, reinforcement, and generative approaches for tabular data transformation.arXiv preprint arXiv:2501.10555(2025)
-
[35]
Xianjie Wu, Jian Yang, Linzheng Chai, Ge Zhang, Jiaheng Liu, Xeron Du, Di Liang, Daixin Shu, Xianfu Cheng, Tianzhen Sun, et al. 2025. Tablebench: A com- prehensive and complex benchmark for table question answering. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 25497–25506
2025
-
[36]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025). A Datasets We use four dataset suites:(i)acore real-world suiteof 24 binary- classification tasks spanning eight knowledge domains (Section A.1); (ii)anew suiteof ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.