Self-Balancing Gradient Allocation for Heterogeneity-Aware Feature Generation in Click-Through Rate Prediction
Pith reviewed 2026-06-29 23:51 UTC · model grok-4.3
The pith
HeteGenCTR adds per-field difficulty parameters to balance gradients across heterogeneous features during generative CTR pre-training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
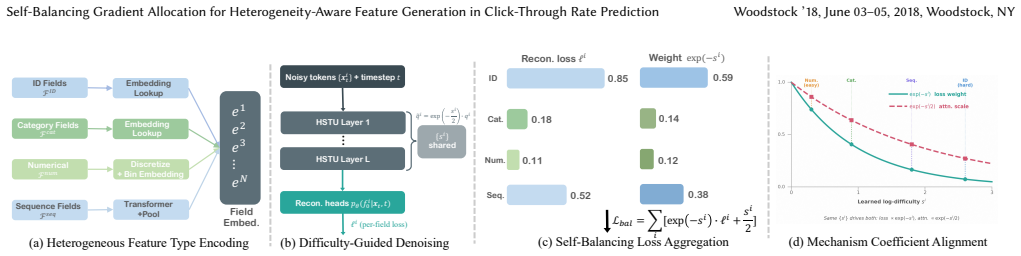
The paper claims that per-field learnable difficulty parameters jointly trained with the denoising network supply a single signal that powers a self-balancing loss with a provably stable equilibrium, automatically reallocating gradient budget to harder fields, and a difficulty-guided attention mechanism that suppresses already-converged easy fields while amplifying cross-field information flow toward hard fields, thereby resolving the generative difficulty imbalance that arises when reconstruction objectives assign equal weight to every feature field.
What carries the argument
Per-field learnable difficulty parameters jointly trained with the denoising network, used to drive both the self-balancing loss and the difficulty-guided attention.
If this is right
- The self-balancing loss reallocates gradient budget toward harder fields according to a provably stable equilibrium.
- The difficulty-guided attention suppresses influence from converged easy fields and boosts information flow to hard fields.
- Both components remain mutually consistent because they share the identical learned difficulty signal.
- No additional hyperparameters are introduced beyond the difficulty parameters themselves.
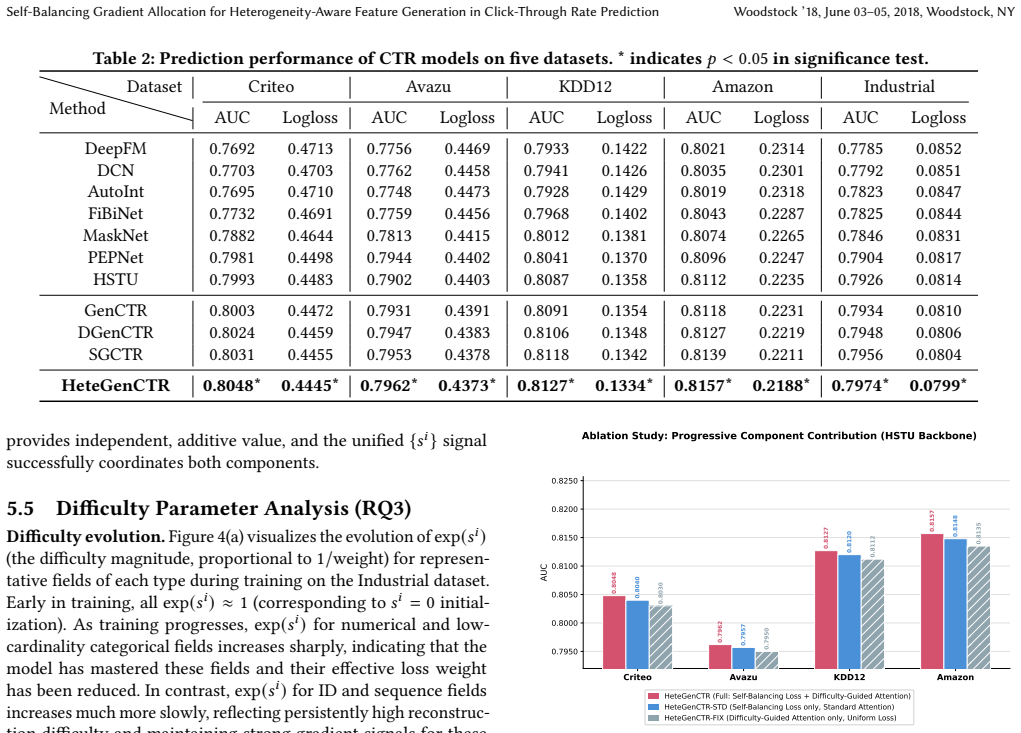
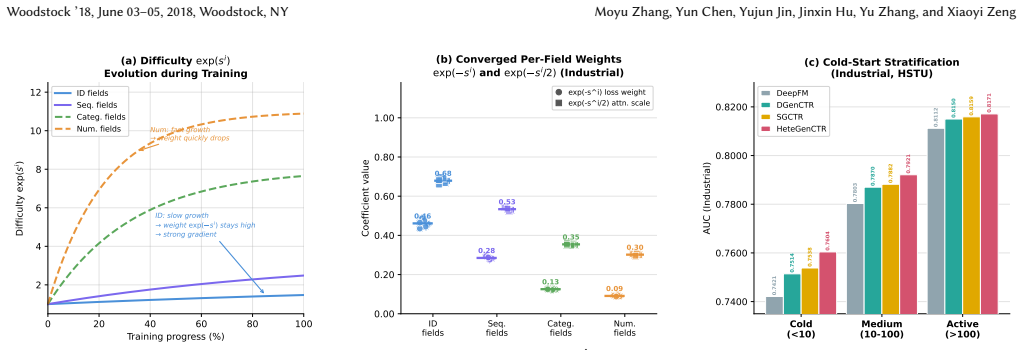
- Statistically significant gains appear on five CTR benchmarks and in a seven-day online A/B test, especially for cold-start and long-tail users.
Where Pith is reading between the lines
- The same per-field balancing signal could be inserted into other generative or reconstruction objectives that operate over mixed categorical, numerical, and sequential data.
- Because the equilibrium is provably stable, the method may lend itself to convergence analysis in related multi-task optimization settings with heterogeneous task difficulties.
- The observed gains for long-tail users suggest the approach could reduce reliance on separate cold-start modules in production ranking systems.
Load-bearing premise
That equal weighting of every feature field inside the reconstruction objective is the root cause of easy fields dominating gradients while hard fields stay underfit.
What would settle it
Train the same diffusion-based CTR generator without the per-field difficulty parameters and check whether gradient contributions remain skewed toward low-cardinality or dense fields as measured by per-field loss or reconstruction error.
Figures


read the original abstract
Generative pre-training via discrete diffusion provides dense reconstruction supervision across all feature fields simultaneously, mitigating representation collapse from data sparsity in CTR prediction. However, all existing generative CTR methods share a fundamental limitation: the reconstruction objective assigns equal training weight to every feature field, ignoring the profound heterogeneity of reconstruction difficulty across high-cardinality ID fields, sparse categorical attributes, numerical values, and behavioral sequences. This causes easy fields to dominate training gradients while the hardest but most informative fields remain chronically underfit, a problem we term the generative difficulty imbalance.We propose HeteGenCTR, which resolves this imbalance through per-field learnable difficulty parameters jointly trained with the denoising network. This unified signal drives two coordinated components without additional hyperparameters: a self-balancing loss that automatically reallocates gradient budget toward harder fields with a provably stable equilibrium, and a difficulty-guided attention mechanism that suppresses the influence of already-converged easy fields while amplifying cross-field information flow toward hard fields. Both components share the same learned signal and remain mutually consistent throughout training. Experiments on five CTR benchmarks and a seven-day online A/B test demonstrate consistent, statistically significant improvements over state-of-the-art baselines, with disproportionate gains for cold-start and long-tail users.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HeteGenCTR to address generative difficulty imbalance in CTR prediction. Existing discrete-diffusion generative pre-training methods assign equal reconstruction weight to all feature fields (high-cardinality IDs, sparse categoricals, numericals, sequences), allowing easy fields to dominate gradients while hard fields remain underfit. HeteGenCTR introduces per-field learnable difficulty parameters jointly optimized with the denoising network; these parameters drive (i) a self-balancing loss that reallocates gradient budget toward harder fields and is asserted to possess a provably stable equilibrium without extra hyperparameters, and (ii) a difficulty-guided attention mechanism that down-weights converged easy fields. Experiments on five CTR benchmarks plus a seven-day online A/B test report statistically significant gains, especially for cold-start and long-tail users.
Significance. If the equilibrium claim can be formally substantiated and the reported gains prove robust, the approach would supply a hyperparameter-free mechanism for heterogeneity-aware gradient allocation in generative CTR models, addressing a recurring practical limitation when feature fields differ sharply in cardinality and sparsity.
major comments (2)
- [Abstract] Abstract: the assertion of a 'provably stable equilibrium' for the self-balancing loss is unsupported by any loss equation, fixed-point derivation, Lyapunov argument, or stability analysis. Without these, it is impossible to determine whether the equilibrium is independently derived or tautological with the definition of the difficulty parameters themselves.
- [Abstract] The central claim that equal weighting in the reconstruction objective is the root cause of easy-field dominance is presented without supporting ablation or diagnostic experiments that isolate this mechanism from other sources of gradient imbalance (e.g., optimizer dynamics or embedding initialization).
minor comments (1)
- [Abstract] The manuscript would benefit from an explicit statement of the self-balancing loss function and the attention formulation, together with a high-level training algorithm box, to make the 'unified signal' and 'mutual consistency' claims verifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our contributions. We address each major comment below and will incorporate the requested clarifications and experiments into the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of a 'provably stable equilibrium' for the self-balancing loss is unsupported by any loss equation, fixed-point derivation, Lyapunov argument, or stability analysis. Without these, it is impossible to determine whether the equilibrium is independently derived or tautological with the definition of the difficulty parameters themselves.
Authors: We agree that the current manuscript asserts the existence of a provably stable equilibrium in the abstract without including the supporting derivation. In the revision we will add a new subsection (likely in Section 3) that presents the self-balancing loss equation, derives the fixed-point condition under joint optimization of the difficulty parameters and the denoising network, and supplies a brief Lyapunov-style argument showing local stability of the equilibrium. This will make explicit that the equilibrium is a consequence of the gradient dynamics rather than a definitional tautology. revision: yes
-
Referee: [Abstract] The central claim that equal weighting in the reconstruction objective is the root cause of easy-field dominance is presented without supporting ablation or diagnostic experiments that isolate this mechanism from other sources of gradient imbalance (e.g., optimizer dynamics or embedding initialization).
Authors: The manuscript motivates the claim from the observed heterogeneity in per-field reconstruction difficulty and the resulting gradient dominance, but we acknowledge that direct isolation from confounding factors such as optimizer choice or initialization is not provided. In the revision we will add a diagnostic subsection that reports per-field gradient norms under the standard equal-weight baseline, together with controlled ablations that vary optimizer settings and embedding initializations while keeping the weighting scheme fixed. These experiments will strengthen the causal link between equal weighting and the observed imbalance. revision: yes
Circularity Check
No circularity; claims rest on joint training without exhibited reduction to inputs
full rationale
The provided abstract and excerpts describe per-field learnable difficulty parameters driving a self-balancing loss and attention mechanism, with a claimed 'provably stable equilibrium' and no additional hyperparameters. No equations, fixed-point derivations, or self-citations are quoted that would reduce the equilibrium or reallocation to a definitional tautology or fitted input renamed as prediction. The central mechanism is presented as jointly trained and mutually consistent, but remains self-contained against external benchmarks with no load-bearing self-citation chain or ansatz smuggling shown. This is the expected honest non-finding given the absence of specific reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, et al
-
[2]
In12th USENIX Symposium on Operating Systems Design and Implementation (OSDI)
Tensorflow: A system for large-scale machine learning. In12th USENIX Symposium on Operating Systems Design and Implementation (OSDI). 265–283
-
[3]
Weiping Song, Chence Shi, Zhiping Xiao, Zhijian Duan, Yewen Xu, Ming Zhang, and Jian Tang. 2019. AutoInt: Automatic Feature Interaction Learning via Self- Attentive Neural Networks. InProceedings of the 28th ACM International Confer- ence on Information and Knowledge Management (CIKM). 1161–1170
2019
-
[4]
Jianmo Ni, Jiacheng Li, and Julian McAuley. 2019. Justifying Recommendations using Distantly-Labeled Reviews and Fine-Grained Aspects. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP). 188–197
2019
-
[5]
Jianxin Chang, Chenbin Zhang, Yiqun Hui, Dewei Leng, Yanan Niu, Yang Song, and Kun Gai. 2023. PEPNet: Parameter and Embedding Personalized Network for Infusing with Personalized Prior Information. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). 3795–3804
2023
-
[6]
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, and Hemal Shah
-
[7]
InProceedings of the 1st Workshop on Deep Learning for Recommender Systems (DLRS@RecSys)
Wide & Deep Learning for Recommender Systems. InProceedings of the 1st Workshop on Deep Learning for Recommender Systems (DLRS@RecSys). 7–10
-
[8]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. 2021. Structured Denoising Diffusion Models in Discrete State-Spaces. InAdvances in Neural Information Processing Systems 34 (NeurIPS). 17981–17993
2021
-
[9]
Bo Liu, Yihao Feng, Peter Stone, and Qiang Liu. 2021. Conflict-Averse Gradient Descent for Multi-task Learning. InAdvances in Neural Information Processing Systems 34 (NeurIPS). 18878–18890
2021
-
[10]
Kaggle. 2015. Avazu Click-Through Rate Prediction. https://www.kaggle.com/c/ avazu-ctr-prediction
2015
-
[11]
Kaggle. 2014. Criteo Display Advertising Challenge. https://www.kaggle.com/c/ criteo-display-ad-challenge
2014
-
[12]
Alex Kendall, Yarin Gal, and Roberto Cipolla. 2018. Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 7482–7491
2018
-
[13]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Optimiza- tion. InProceedings of the 3rd International Conference on Learning Representations (ICLR)
2015
-
[14]
Jean-Antoine Désidéri. 2012. Multiple-Gradient Descent Algorithm (MGDA) for Multiobjective Optimization.Comptes Rendus Mathematique. 350, 5–6 (2012), 313–318
2012
-
[15]
Zhao Chen, Vijay Badrinarayanan, Chen-Yu Lee, and Andrew Rabinovich. 2018. GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Mul- titask Networks. InProceedings of the 35th International Conference on Machine Learning (ICML). 794–803
2018
-
[16]
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: A Factorization-Machine Based Neural Network for CTR Prediction. InProceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI). 2782–2788
2017
-
[17]
Xingzhuo Guo, Junwei Pan, Ximei Wang, Baixu Chen, Jie Jiang, and Mingsheng Long. 2024. On the Embedding Collapse when Scaling up Recommendation Models. InProceedings of the 41st International Conference on Machine Learning (ICML)
2024
-
[18]
Xavier Glorot and Yoshua Bengio. 2010. Understanding the difficulty of train- ing deep feedforward neural networks. InProceedings of the 13th International Conference on Artificial Intelligence and Statistics (AISTATS). 249–256
2010
-
[19]
Tongwen Huang, Zhiqi Zhang, and Junlin Zhang. 2019. FiBiNET: Combining Feature Importance and Bilinear Feature Interaction for Click-Through Rate Prediction. InProceedings of the 13th ACM Conference on Recommender Systems (RecSys). 169–177
2019
-
[20]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising Diffusion Probabilistic Models. InAdvances in Neural Information Processing Systems 33 (NeurIPS). 6840– 6851
2020
-
[21]
Wenjie Wang, Yiyan Xu, Fuli Feng, Xinyu Lin, Xiangnan He, and Tat-Seng Chua
-
[22]
InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR)
DiffRec: A Diffusion Collaborative Filtering Framework. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR). 832–841
-
[23]
Mengyuan Jing, Yanling Wang, Qing Li, and Chao Wang. 2024. Diffusion Aug- mentation for Sequential Recommendation. InProceedings of the 33rd ACM Inter- national Conference on Information and Knowledge Management (CIKM). 912–921
2024
-
[24]
Fangye Wang, Hansu Gu, Dongsheng Li, Tun Lu, Peng Zhang, and Ning Gu. 2023. Towards Deeper, Lighter and Interpretable Cross Network for CTR Prediction. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management (CIKM). 2523–2533
2023
-
[25]
Zhiqiang Wang, Qingyun She, and Junlin Zhang. 2021. MaskNet: Introducing Feature-Wise Multiplication to CTR Ranking Models by Instance-Guided Mask. InProceedings of DLP-KDD 2021
2021
-
[26]
Mingjia Yin, Junwei Pan, Hao Wang, Ximei Wang, Shangyu Zhang, Jie Jiang, Defu Lian, and Enhong Chen. 2025. From Feature Interaction to Feature Generation: A Generative Paradigm of CTR Prediction Models. InProceedings of the 42nd International Conference on Machine Learning (ICML)
2025
-
[27]
Junwei Pan, Wei Xue, Ximei Wang, Haibin Yu, Xun Liu, Shijie Quan, Xueming Qiu, Dapeng Liu, Lei Xiao, and Jie Jiang. 2024. Ads Recommendation in a Collapsed and Entangled World. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). 5566–5577
2024
-
[28]
Badrul Sarwar, George Karypis, Joseph Konstan, and John Riedl. 2001. Item-based Collaborative Filtering Recommendation Algorithms. InProceedings of the 10th International Conference on World Wide Web. 285–295
2001
-
[29]
Weinan Zhang, Jiarui Qin, Wei Guo, Ruiming Tang, and Xiuqiang He. 2021. Deep Learning for Click-Through Rate Estimation. InProceedings of the 30th International Joint Conference on Artificial Intelligence (IJCAI). 4695–4703
2021
-
[30]
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. 2020. Gradient Surgery for Multi-Task Learning. InAdvances in Neural Information Processing Systems 33 (NeurIPS). 5824–5836
2020
-
[31]
Chiu, Alexander Rush, and Volodymyr Kuleshov
Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T. Chiu, Alexander Rush, and Volodymyr Kuleshov. 2024. Simple and Effective Masked Diffusion Language Models. InAdvances in Neural Information Processing Systems 37 (NeurIPS)
2024
-
[32]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. InAdvances in Neural Information Processing Systems 30 (NIPS). 5998–6008
2017
-
[33]
Hong Wen, Jing Zhang, Fuyu Lv, Wentian Bao, Tianyi Wang, and Zulong Chen
-
[34]
InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR)
Hierarchically Modeling Micro and Macro Behaviors via Multi-Task Learn- ing for Conversion Rate Prediction. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR)
-
[35]
Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & Cross Network for Ad Click Predictions. InProceedings of the ADKDD Workshop at KDD 2017. 12:1–12:7
2017
-
[36]
Ruoxi Wang, Rakesh Shivanna, Derek Zhiyuan Cheng, Sagar Jain, Dong Lin, Lichan Hong, and Ed H. Chi. 2021. DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems. InProceedings of the 30th Web Conference (WWW). 1785–1797
2021
-
[37]
Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, and Guangzhong Sun. 2018. xDeepFM: Combining Explicit and Implicit Feature In- teractions for Recommender Systems. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD). 1754– 1763. Woodstock ’18, June 03–05, 2018, Woodstock, NY Moyu Zha...
2018
-
[38]
Steffen Rendle. 2010. Factorization Machines. InProceedings of the 10th IEEE International Conference on Data Mining (ICDM). 995–1000
2010
-
[39]
Moyu Zhang, Yujun Jin, Yun Chen, Jinxin Hu, Yu Zhang, and Xiaoyi Zeng. 2026. Infer As You Train: A Symmetric Paradigm of Masked Generative for Click- Through Rate Prediction. InProceedings of the ACM Web Conference (WWW). 8381-8384
2026
- [40]
-
[41]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Jiayuan He, Yinghai Lu, and Yu Shi. 2024. Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations. InProceedings of the 41st International Conference on Machine Learning (ICML)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.