GroupTravelBench: Benchmarking LLM Agents on Multi-Person Travel Planning
Pith reviewed 2026-06-30 11:26 UTC · model grok-4.3
The pith
Even the strongest LLM agents achieve below 12% plan validity on multi-person travel tasks that require preference elicitation and fairness balancing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
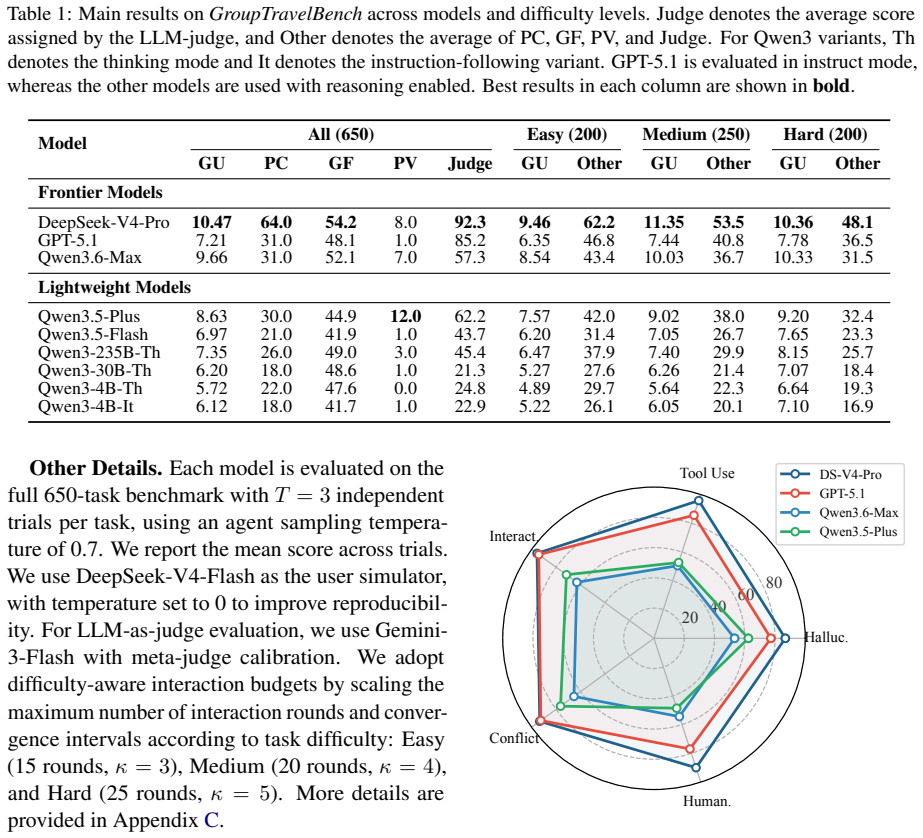
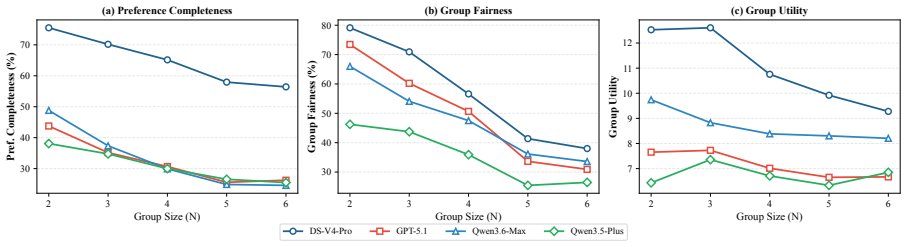
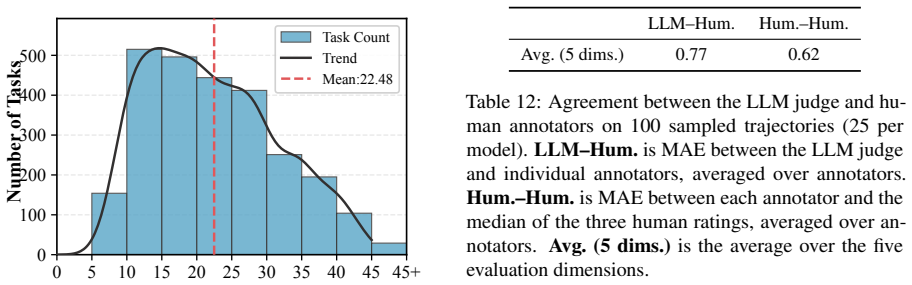
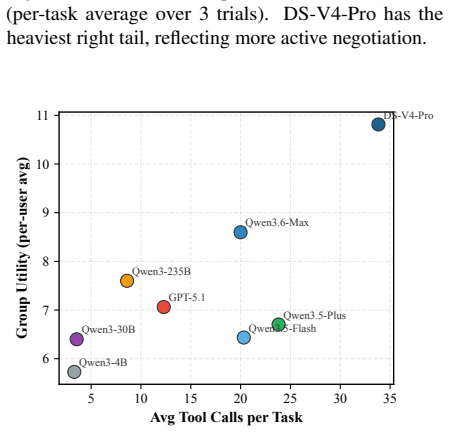
GroupTravelBench is the first benchmark that moves travel planning from single-user to multi-user, multi-turn settings. It supplies 650 tasks across three difficulty levels inside a synchronous group-chat environment with cached tools, and measures both outcome quality via rule-based metrics and process quality via LLM judges. Evaluation of current agents demonstrates that plan validity stays below 12% even for the strongest models, indicating that group-level coordination remains an open limitation.
What carries the argument
GroupTravelBench, a benchmark of 650 tasks in a synchronous group-chat sandbox that evaluates elicitation of private preferences, coordination of inter-user conflicts, and planning that balances group utility against fairness.
If this is right
- Agents must actively elicit private preferences through multi-turn dialogue rather than assume all information is given upfront.
- Successful group plans require explicit mechanisms for surfacing and resolving conflicts between users.
- Outcome evaluation must separately track both aggregate utility and fairness across participants.
- Single-user tool-use and reasoning benchmarks are insufficient for measuring readiness for collaborative real-world tasks.
Where Pith is reading between the lines
- Similar group-interaction gaps likely exist in other domains that current single-user benchmarks cover, such as collaborative coding or shared decision-making.
- Training or fine-tuning on explicit multi-agent dialogue traces may be required before agents can reach usable performance on these tasks.
- The benchmark's offline cached-tool design allows direct comparison of future agent architectures without live API costs.
Load-bearing premise
The constructed tasks and metrics accurately reflect the core challenges of real-world multi-person travel planning.
What would settle it
An experiment in which human groups complete the same 650 tasks and produce plans whose validity scores under the same rule-based metrics exceed 50%.
Figures







read the original abstract
Travel planning in the real world is overwhelmingly a \textit{group} activity, yet existing LLM travel-planning benchmarks reduce it to a single user, where the field is approaching saturation. This single-user assumption sidesteps what makes group planning hard for an agent: discovering private preferences across multiple users, surfacing conflicts, and balancing utility against fairness. To bring the task back to its multi-user reality, we introduce \textbf{\textit{GroupTravelBench}}, the first benchmark for \textbf{multi-user, multi-turn} travel planning. Built from real user profiles, POI data, and ticket prices, it comprises 650 tasks across three difficulty levels, each running in a synchronous group-chat sandbox with cached tool data for reproducible offline evaluation. Beyond the multi-step reasoning and tool use that single-user benchmarks already test, GroupTravelBench probes three group-specific capabilities: \textit{(i) elicitation} of private preferences through multi-turn dialogue; \textit{(ii) coordination} of inter-user conflicts via compromise or subgrouping; and \textit{(iii) planning} that balances group utility against fairness. We pair this with a complementary evaluation framework combining rule-based outcome metrics and LLM-judge process metrics. Across a wide range of frontier models, even the strongest agents fall short on all four rule-based outcome metrics, with plan validity below 12\%, suggesting that group-level outcome quality is a key open challenge for LLM travel-planning agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GroupTravelBench, the first benchmark for multi-user, multi-turn travel planning. It comprises 650 tasks across three difficulty levels, constructed from real user profiles, POI data, and ticket prices, and executed in a synchronous group-chat sandbox with cached tools for reproducible evaluation. The benchmark targets three group-specific capabilities—elicitation of private preferences, coordination of conflicts, and planning that balances utility against fairness—beyond single-user reasoning and tool use. Evaluation combines rule-based outcome metrics and LLM-judge process metrics; results show that even frontier models achieve plan validity below 12% on all four rule-based metrics, indicating group-level outcome quality remains an open challenge.
Significance. If the benchmark's tasks and metrics faithfully represent real-world multi-person travel planning difficulties, the low performance results establish that multi-user coordination and fairness tradeoffs constitute a distinct, unsolved capability gap for LLM agents. The reproducible sandbox and cached-tool design is a clear strength that supports community follow-up work.
major comments (1)
- [Abstract / task construction] Abstract and task-construction description: The central claim that low agent performance demonstrates an open challenge for group planning rests on the assumption that the 650 tasks accurately reflect real elicitation, conflict, and fairness difficulties. However, the manuscript provides no external validation—such as expert review of generated conflicts, comparison against observed group itineraries, or statistical matching of preference distributions—to confirm fidelity to real-world patterns. This is load-bearing for interpreting the <12% validity result.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for highlighting the importance of establishing task fidelity. We address the concern regarding external validation of the 650 tasks below.
read point-by-point responses
-
Referee: [Abstract / task construction] Abstract and task-construction description: The central claim that low agent performance demonstrates an open challenge for group planning rests on the assumption that the 650 tasks accurately reflect real elicitation, conflict, and fairness difficulties. However, the manuscript provides no external validation—such as expert review of generated conflicts, comparison against observed group itineraries, or statistical matching of preference distributions—to confirm fidelity to real-world patterns. This is load-bearing for interpreting the <12% validity result.
Authors: We agree that external validation (expert review, comparison to observed itineraries, or statistical matching of preference distributions) is not reported in the manuscript. The tasks were constructed by sampling real user profiles, POI data, and ticket prices, then programmatically instantiating the three group-specific capabilities (elicitation via private-preference queries, conflict coordination, and utility-fairness trade-offs) inside the synchronous sandbox. This grounding in real data sources provides a reproducible testbed, and the uniformly low performance (<12% validity) across frontier models on all four rule-based metrics indicates that the defined group dynamics remain challenging even under these conditions. We will revise the manuscript to expand the task-construction section with explicit details on sampling procedures and to add a limitations paragraph that explicitly discusses the absence of the external validation steps noted by the referee. revision: partial
Circularity Check
No significant circularity
full rationale
The paper introduces GroupTravelBench as a new benchmark constructed from real user profiles, POI data, and ticket prices, with tasks and metrics defined directly. There are no equations, derivations, fitted parameters, predictions, or self-citation chains that reduce any claim to its own inputs by construction. The central contribution is benchmark definition and evaluation, which is self-contained without circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deeptravel: An end-to-end agentic reinforce- ment learning framework for autonomous travel plan- ning agents.arXiv preprint arXiv:2509.21842. OpenAI. 2025. GPT-5.1 is Now Available: A Smarter and More Conversational ChatGPT. https:// openai.com/index/gpt-5-1/. Accessed: 2025- 11-12. Cheng Qian, Emre Can Acikgoz, Qi He, Hongru WANG, Xiusi Chen, Dilek Hakka...
-
[2]
InThe Fourteenth International Conference on Learning Representations
Chinatravel: An open-ended travel planning benchmark with compositional constraint validation for language agents. InThe Fourteenth International Conference on Learning Representations. Zijian Shao, Jiancan Wu, Weijian Chen, and Xiang Wang. 2025. Personal travel solver: A preference- driven LLM-solver system for travel planning. In Proceedings of the 63rd...
-
[3]
Decoupled Travel Planning with Behavior Forest
Qwen3 technical report. Dongjie Yang, Chengqiang Lu, Qimeng Wang, Xinbei Ma, Yan Gao, Yao Hu, and hai zhao. 2026. Wide- horizon thinking and simulation-based evaluation for real-world LLM planning with multifaceted con- straints. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Used for the first user in each group, producing a fully original preference set
Independent: A fresh LLM call generates the complete preference table, conditioned on the user’s sampled real profile. Used for the first user in each group, producing a fully original preference set
-
[5]
Only the fine-grained name-level preferences (must_visit, reject_visit, must_eat, reject_eat) are regenerated by the LLM
Copy_minor: The global constraints and city- level category preferences are inherited from a reference user (typically the partner or close companion). Only the fine-grained name-level preferences (must_visit, reject_visit, must_eat, reject_eat) are regenerated by the LLM. This simulates couples or close friends who share broad preferences but differ on s...
-
[6]
All city-specific preferences and meso-level category preferences are regener- ated
Copy_moderate: Only the top-level global con- straints (budget, transport mode, intensity, hotel class) are inherited. All city-specific preferences and meso-level category preferences are regener- ated. This simulates friends who share a similar travel style but have distinct interests
-
[7]
These mem- bers still appear in the group and affect the participants field of the plan but do not con- tribute to utility scoring
Skip: For members who do not carry inde- pendent preferences (e.g., toddlers aged 0–8), no preference table is generated. These mem- bers still appear in the group and affect the participants field of the plan but do not con- tribute to utility scoring. After generation, each preference table under- goes three validation passes: • POI name validation: Eve...
-
[8]
You are Boyfriend A
The user’srolewithin the group (e.g., “You are Boyfriend A”)
-
[9]
The user’scomplete preference tablein struc- tured format
-
[10]
tend to agree when the agent asks for a compromise, and append a machine- readable marker
Acompromise blockthat varies based on the compromisable flag: compromisable users are instructed to “tend to agree when the agent asks for a compromise, and append a machine- readable marker”; non-compromisable users are instructed to “politely but firmly decline com- promise requests on strong-tier preferences.”
-
[11]
In all other situations, the user emits[pass]
Five behavioral scenariosdefining when the user should speak: (A) when @-mentioned by the agent, (B) when a conflict with their strong preferences is detected, (C) to ask the agent fac- tual questions, (D) to respond to a compromise request, (E) to acknowledge the agent’s answer to a previous question. In all other situations, the user emits[pass]
-
[12]
Strict prohibitions: no spontaneous prefer- ence disclosure, no planning suggestions, no @-mentioning other users, no pretending to have tool access, no repetition of previously stated preferences, no idle chat, and no answering on behalf of others
-
[13]
I’d rather not, but I can live with it
Tone mapping rules: must = firm and non- negotiable, reject = firm refusal, prefer = mild suggestion, avoid = mild discomfort. Detailed guidelines distinguish avoid (“I’d rather not, but I can live with it”) from reject (“absolutely not”). The user simulator is deployed at temperature 0 with a strong instruction-following LLM to min- imize behavioral vari...
2025
-
[14]
The agent identifies a conflict and @-mentions the relevant user (e.g., @User2 Would you accept switching to high-speed rail?)
-
[15]
The scheduler grants the @-mentioned user im- mediate speaking priority
-
[16]
high-speed rail
If the user is compromisable ( κi >0 ), the simulator replies with natural-language agreement plus a trailing machine-readable marker: [transport.must : ["high-speed rail"]]
-
[17]
The framework validates that the preceding mes- sage was indeed the agent @-mentioning this user
-
[18]
On validation success: the marker is parsed, the modification is applied to peff i via dotted-path traversal, the marker is stripped from the visible message, κi is decremented, and if κi reaches 0, the user’s system prompt is rebuilt to mark them as non-compromisable
-
[19]
Maximum compromise quota.Each user can agree to at most K= 2 compromises
On validation failure (e.g., the marker refers to a nonexistent field path, or the preceding message was not from the agent): the user’s response is regenerated (up to 3 retries). Maximum compromise quota.Each user can agree to at most K= 2 compromises. After 2 accepted compromises, the user becomes non- compromisable for the remainder of the conver- sati...
-
[20]
The agent emits a structurally valid travel plan JSON (immediate termination, no revision loop)
-
[21]
The maximum number of turns is reached (the framework force-injects a final-plan instruction and the agent must generate a plan within 3 attempts)
-
[22]
15 Subgrouping mechanics.When the agent de- cides to subgroup, the group is partitioned into Ke subgroups with disjoint membership at split event e
A safety guard is triggered: (a) a user persis- tently emits [pass] after being @-mentioned (mention exhaustion), (b) the same (tool_name, arguments) tuple is called ≥3 times across iter- ations or appears in two consecutive agent turns (repetitive tool-call termination), or (c) the per- round event cap (5×|polling_order|) is breached (runaway prevention)...
-
[23]
Inter-city transportation: every required inter- city leg is covered by a flight or train segment with a feasible schedule
-
[24]
Hotel coverage: every overnight stay in a des- tination city is matched by a hotel booking; no night is left uncovered or double-booked
-
[25]
Temporal consistency: arrival times precede departure times on every segment, and no two activities overlap for the same user or subgroup
-
[26]
Activity overlap: no scheduled activity (attrac- tion visit, meal, lodging) overlaps in time with another for the same participant
-
[27]
Opening-hour compliance: every attraction or restaurant is visited within its declared opening hours
-
[28]
Local transportation continuity: between con- secutive intra-city activities, a feasible local- transport segment exists (walking, taxi, metro, etc.)
-
[29]
Day-level temporal monotonicity: events within each day are in non-decreasing temporal order
-
[30]
Cost completeness: each scheduled item carries a cost field consistent with the corresponding tool return
-
[31]
find a coffee shop near my route
Participant validity: every participants field references group members declared at task start; preschool members are not assigned tasks beyond physically reasonable activities. A.9 Dataset Statistics The remaining subsections summarize the geo- graphic, group-size, preference, and temporal dis- tributions of the 650 released tasks. A.9.1 Geographic Distr...
2025
-
[32]
The tool call’s normalized argument JSON is used as the cache key
-
[33]
If an exact match exists, the cached response is returned immediately
-
[34]
Beijing” vs. “Beijing
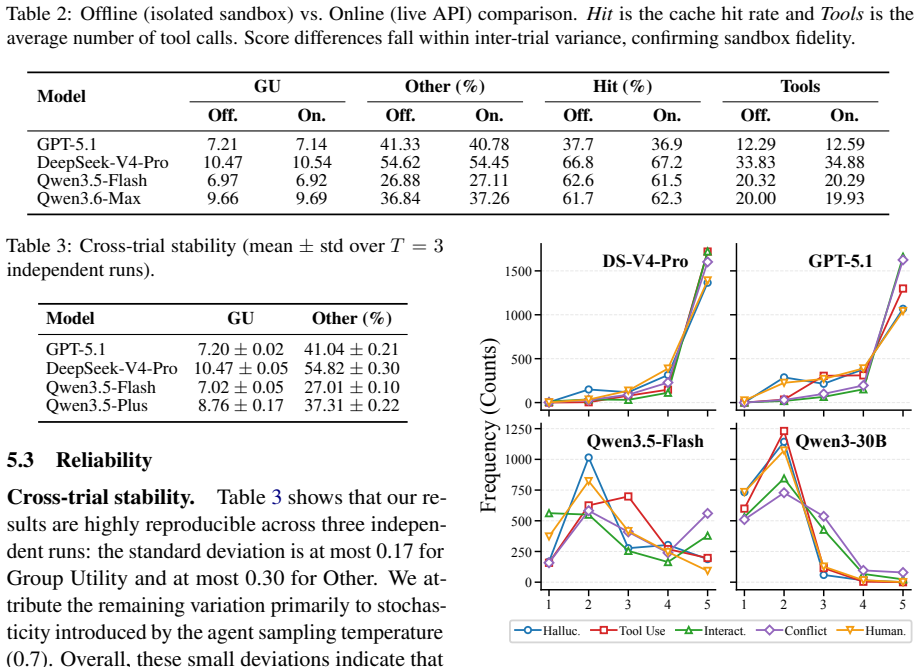
If no exact match exists (cache miss), the system falls back to theembedding-retrieval + ICL simulationstrategy (§B.3). This ensures that identical agent trajectories on identical cached states produce identical tool out- puts, eliminating environmental variance from the evaluation. ONLINE mode (for cache warming).During the initial cache-building phase, ...
2025
-
[35]
Embeddings are stored as .npzfiles alongside each tool’s cache
Embedding precomputation: We precompute embeddings for all cached tool-call inputs using Qwen3-Embedding-8B, deployed as a remote embedding service. Embeddings are stored as .npzfiles alongside each tool’s cache
-
[36]
FAISS-based retrieval: When a cache miss occurs, the current tool call’s input is embed- ded and used to query a FAISS index (built at startup) to retrieve the top-8 most similar cached entries
-
[37]
A tool- simulator LLM generates a plausible response that is consistent with the real tool’s output for- mat and the retrieved examples
ICL simulation: The retrieved (input, out- put) pairs are formatted as few-shot examples, along with the tool’s schema definition. A tool- simulator LLM generates a plausible response that is consistent with the real tool’s output for- mat and the retrieved examples
-
[38]
Hallucination
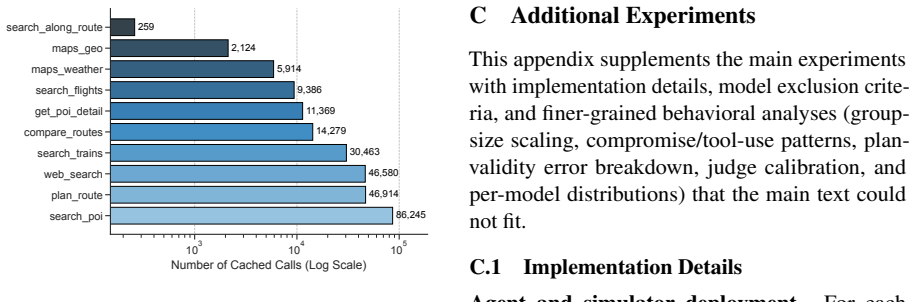
Transparent logging: Simulated responses are saved to the missed-calls file but arenotwritten back to the main cache, ensuring that the pri- mary cache remains a faithful record of real API responses. This strategy ensures that (1) the simulated re- sponse distribution stays close to the real tool’s 20 103 104 105 Number of Cached Calls (Log Scale) search...
2025
-
[39]
All preferences must strictly come from the provided candidate lists ; do not fabricate attraction names, food categories , or hotel categories not in the lists
-
[40]
Total preferences per major category should be controlled to 2−4 items (must/ prefer / avoid / reject combined); fewer is better than more
-
[41]
popular preferences
Preferences should reflect the user profile ' s real characteristics , not generic "popular preferences ."
-
[42]
Attraction preferences should prioritize city − specific features (e.g ., ancient architecture in Beijing , gardens in Suzhou); whether positive or negative , prioritize top−ranked popular attractions
-
[43]
Attraction Category Options
Attraction categories ( category_pref ) must be strictly selected from the " Attraction Category Options" list for the corresponding city ; each city can only use categories listed for that city . Note: tags in parentheses after Top100 attraction names are specific attraction tags , NOT equal to the category options −− do not confuse them
-
[44]
Food preferences should comprehensively consider local specialty cuisines and the user profile ' s personal taste preferences
-
[45]
For multi−city trips , food preference categories across cities should be as diverse as possible ; avoid selecting the same food category in multiple cities
-
[46]
Overall preferences must maintain internal consistency (e.g ., a low−budget user should not prefer luxury hotels )
-
[47]
Based on user profiles , proactively infer reasonable negative preferences
Actively generate negative / avoid / reject preferences . Based on user profiles , proactively infer reasonable negative preferences . Each user ' s preferences should include at least 1 negative / avoid / reject preference
-
[48]
Budget must reference provided real transportation fare data : per−person total budget must at least cover round−trip transportation costs (lowest fare x 2) plus basic food and lodging expenses
-
[49]
city_specific_preferences must be in dict ( dictionary ) format: key is city name, value is that city ' s preference object ; do NOT use list / array format
-
[50]
boyfriend
Output must be valid JSON with no additional explanatory text or markdown code block markers. [User Prompt] Based on the following information , generate a travel preference profile for this user . ## User Profile Summary {user_profile_summary} ## Travel Information − Departure city : { departure_city } − Destination cities : { cities } − Travel duration ...
-
[51]
Collect and organize each user ' s preferences (budget, transport , accommodation, intensity , attractions and food for each city ) , maintaining the preference table in the prescribed structure
-
[52]
Identify conflict points between users (e.g ., budget differences , time conflicts , different activity preferences ) and propose compromise solutions
-
[53]
Answer users ' questions (e.g ., location recommendations, plan comparisons, ticket inquiries , weather queries , etc .)
-
[54]
Call tools to query real data ( flights , trains , hotels , attractions , routes , etc .) . 28
-
[55]
[ Interaction Rules (Must Be Strictly Followed)]
Finally output a detailed travel plan in JSON format. [ Interaction Rules (Must Be Strictly Followed)]
-
[56]
@User1 requires high−speed rail , while @User3 requires self −driving
**@−Mention Mechanism**: − The only legitimate use of @ is to **ask a specific user a question ** (e.g ., collecting preferences , mediating conflicts , asking whether they will compromise), format: @UserX specific question − ** Strictly forbidden to @ any user when making statements, summaries, answering questions , or relaying information **. You may on...
-
[57]
skip / silence
**You Must Speak When It's Your Turn**: − You have no "skip / silence " option . Each time it ' s your turn , you must do one of : ask users about unexpressed preference fields , mediate identified conflicts (@ a user to ask about compromise if necessary ) , call tools to query real information needed for planning , proceed to output the final travel plan...
-
[58]
next steps
**Speaking Requirements**: − Prioritize using tools to obtain information . All answers or suggestions must be backed by real tool return data ; fabrication is forbidden . − Fully understand the chat history before answering. Do not include "next steps " plans in your final answer; if you have a plan , you should directly call tools to continue reasoning ...
-
[59]
@User1 What other preferences do you have for this trip ?
**Early Planning Phase: Proactive Inquiry and Preference Collection **: − **Every field in the preference table may have a value . Users will NOT proactively tell you all their preferences −− if you don' t ask , they won't say. ** Therefore , before generating the plan , you must proactively @ each user to fill in their preference table as completely as p...
-
[60]
can you change it
**Timing of Plan Output (Extremely Important) **: − **Once you output the final travel plan JSON, the conversation terminates immediately with no opportunity for modification . ** − Therefore , before outputting the plan , you must ensure : − All users ' preferences have been collected − All significant conflicts have been identified and handled (compromi...
-
[61]
user name −> preference
Directly output a top−level JSON object mapping "user name −> preference" (do not wrap with any outer key) , strictly following the prescribed structure
-
[62]
Field names must strictly use the prescribed names
-
[63]
Allowed tiers per field : − transport : must / prefer / avoid / reject − attractions : must_visit / reject_visit + category_pref . positive / negative − food: must_eat / prefer_eat / avoid_eat / reject_eat − hotel_preference : only prefer / avoid (no must/ reject ) − intensity : max_poi_per_day / max_active_hours (both are upper limits ) − avg_budget: int...
-
[64]
city_specific_preferences must be a dict (key=city name, value=that city ' s preferences ) , not a list
-
[65]
the maximum this one user is willing to spend on this trip ,
avg_budget semantics (extremely important ) : it is that user ' s individual per−person budget cap −− i .e ., "the maximum this one user is willing to spend on this trip ," NOT the team total budget
-
[66]
Unexpressed fields : list fields keep []; scalar avg_budget if unmentioned then omit entirely ; intensity if both items unmentioned then omit
-
[67]
City names must exactly match those in the query
-
[68]
D.5 Agent Convergence Summary Prompt Prompt: Convergence Summary Based on the current chat history and collected user preferences , make a summary statement
Do not output any explanatory text , only JSON. D.5 Agent Convergence Summary Prompt Prompt: Convergence Summary Based on the current chat history and collected user preferences , make a summary statement. You must do one of the following ( silence / skipping is not allowed) :
-
[69]
Mediate conflicts : Summarize currently identified preference conflict points and indicate your preferred trade −off direction (you may @ a relevant user to ask about compromise)
-
[70]
Information collection : Collect still −missing key information by @−mentioning a specific user
-
[71]
Notes: − This is a normal utterance that enters the shared chat history ; keep it concise and progressive
Plan generation : If information is sufficiently complete, directly call tools and generate the complete travel plan . Notes: − This is a normal utterance that enters the shared chat history ; keep it concise and progressive . − If you need to ask a specific user , use @UserX format; you may only @ one user per message. − When key information is missing ,...
-
[72]
Try to call tools to query real information ( flights / trains / hotels / attractions , etc .)
-
[73]
See the scoring rules and splitting mechanism in the system prompt.)
Plan with the goal of maximizing the sum of all users ' preference scores ( strong tier : satisfied +2 / violated −2; weak tier : satisfied +1 / violated −1; when splitting : K parallel teams incur (K−1) penalty points . See the scoring rules and splitting mechanism in the system prompt.)
-
[74]
For conflicting preferences , weigh total score and make trade−offs independently ; for arrangements involving obvious trade −offs , explain briefly
-
[75]
For missing information , make reasonable assumptions
-
[76]
limit reached , please retry
Strictly follow the JSON structure defined in the system prompt's output format and format constraints . D.7 Agent Force-Finish Instruction Appended to the system prompt when the per-turn tool-call iteration limit is hit. 31 Prompt: Force-Finish Instruction [Force−Finish Directive ] You have reached the maximum tool−call count for this turn or repetitive ...
-
[77]
Do not self − identify as AI/model/system
** Identity and Perspective **: You are {user_name}; always speak from this identity . Do not self − identify as AI/model/system
-
[78]
can only come from [Your Personal Preferences ]
** Faithfulness **: Your needs, preferences , budget, etc . can only come from [Your Personal Preferences ]. Do not add settings beyond your personal information
-
[79]
anything is fine / no particular preference / you all decide
**Unmentioned = Unknown**: If asked about preferences not contained in your personal information , answer naturally with "anything is fine / no particular preference / you all decide ."
-
[80]
check flights / trains / hotels /weather/ routes ,
**No Tool Capability **: You have absolutely no ability to query/compare prices /book tickets / navigate / search , and cannot access any external data . When the Agent or other users ask you to "check flights / trains / hotels /weather/ routes ," "compare prices ," or "help book," you MUST clearly state you cannot do it (e.g ., "I can' t look that up, yo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.