Learning View-Dependent Splatting Kernels
Pith reviewed 2026-06-29 19:55 UTC · model grok-4.3
The pith
A differentiable framework learns view-dependent 2D kernels that improve reconstruction quality and efficiency in novel 3D view synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
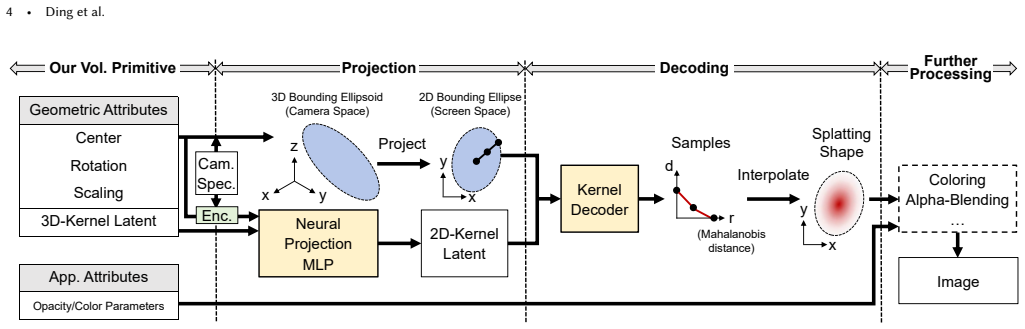
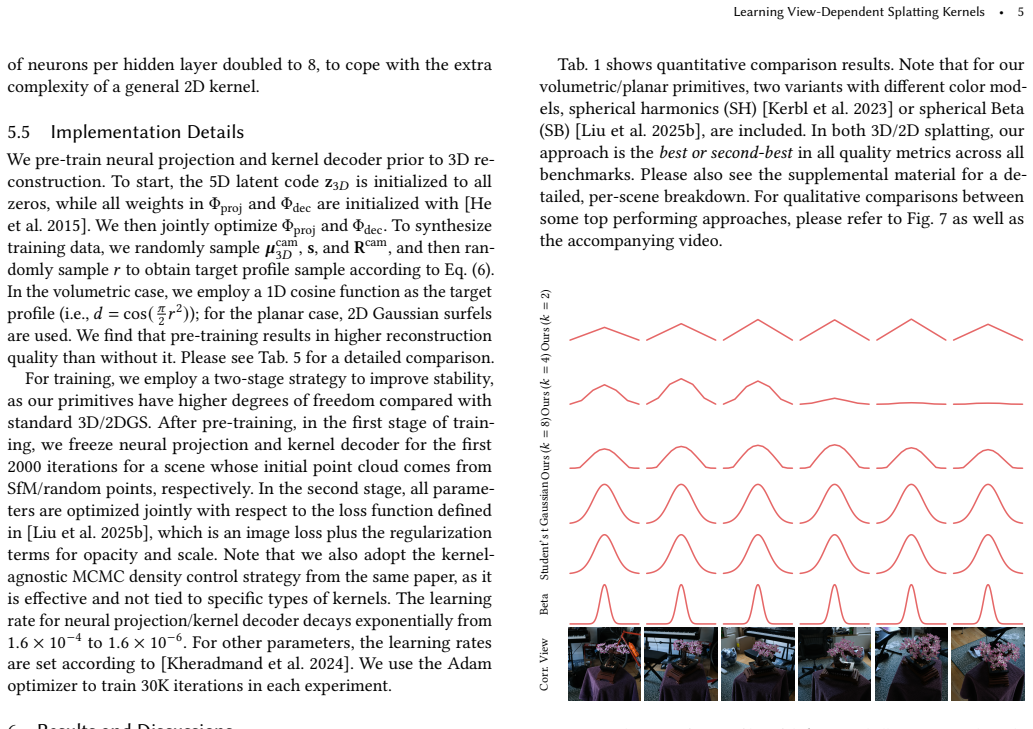
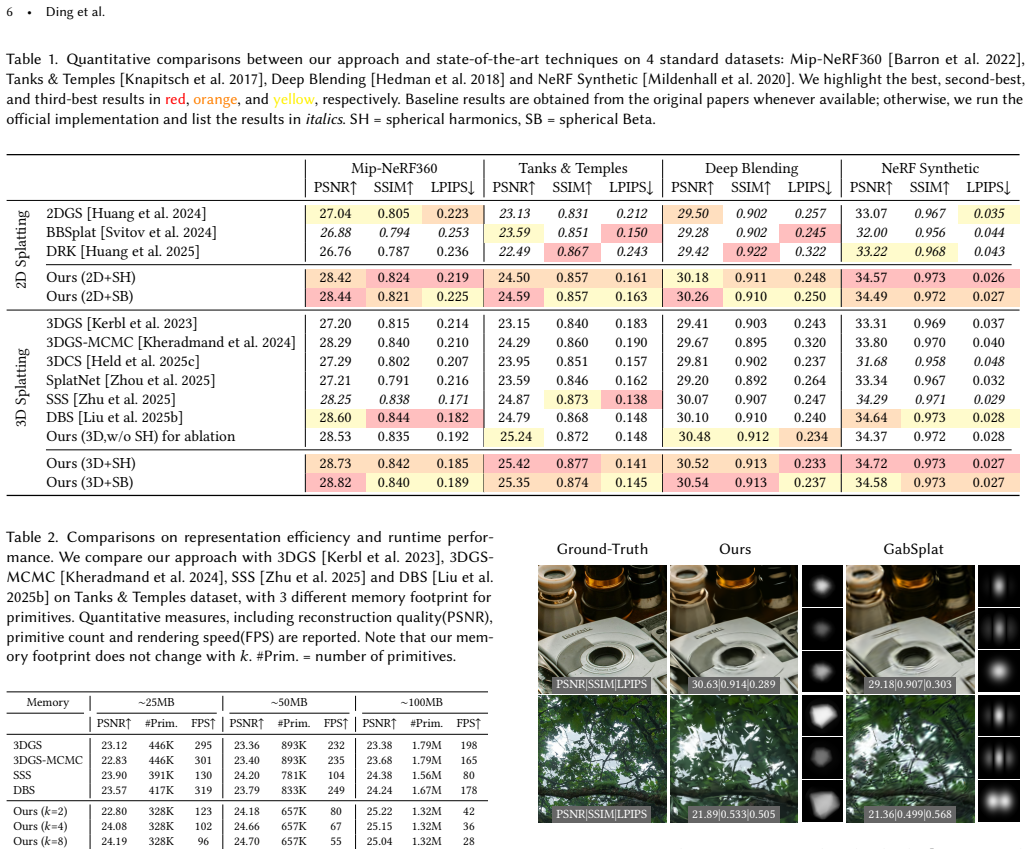
We present a differentiable framework to automatically learn view-dependent 2D kernels in a splatting-based pipeline to improve reconstruction quality and representation efficiency for novel 3D view synthesis. Our volumetric primitive is defined as a bounding ellipsoid and a 3D-kernel latent vector. We first learn a projection network to output a 2D-kernel latent, taking the attributes of the ellipsoid and the 3D-kernel latent as input. Next, the result is sent to a decoder to produce a radially symmetric 2D kernel in terms of Mahalanobis distance, bounded by the projected ellipsoid. The neural networks along with per-primitive attributes are jointly optimized. The effectiveness of our appro
What carries the argument
The projection network that outputs a 2D-kernel latent from ellipsoid attributes and 3D-kernel latent, combined with a decoder that produces the radially symmetric 2D kernel bounded by the projected ellipsoid.
If this is right
- The learned kernels lead to improved reconstruction quality compared to state-of-the-art analytical and learned kernels on benchmarks.
- Representation efficiency increases as the adaptive kernels allow better use of primitives in the splatting pipeline.
- The framework extends to learning general 2D kernels for 2D splatting tasks and image representation.
- Joint optimization of networks and attributes enables the kernels to become view-dependent.
Where Pith is reading between the lines
- If the method scales, fewer primitives might suffice for the same visual quality in scene representations.
- The idea of learning kernels this way could apply to other primitive-based rendering methods beyond splatting.
- Further tests on more complex scenes or with different optimization strategies could validate broader applicability.
Load-bearing premise
The assumption that a learned projection network plus decoder can produce effective radially symmetric 2D kernels bounded by the projected ellipsoid that, when jointly optimized, outperform state-of-the-art kernels on benchmarks.
What would settle it
A benchmark evaluation where the proposed method shows no improvement or worse performance in reconstruction metrics like PSNR compared to existing kernels would disprove the central effectiveness claim.
Figures





read the original abstract
We present a differentiable framework to automatically learn view-dependent 2D kernels in a splatting-based pipeline to improve reconstruction quality and representation efficiency for novel 3D view synthesis. Our volumetric primitive is defined as a bounding ellipsoid and a 3D-kernel latent vector. We first learn a projection network to output a 2D-kernel latent, taking the attributes of the ellipsoid and the 3D-kernel latent as input. Next, the result is sent to a decoder to produce a radially symmetric 2D kernel in terms of Mahalanobis distance, bounded by the projected ellipsoid. The neural networks along with per-primitive attributes are jointly optimized. The effectiveness of our approach is demonstrated on standard benchmarks, comparing favorably against state-of-the-art techniques on both analytical and learned kernels. Finally, we extend the idea to learn general 2D kernels for 2D splatting as well as image representation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes a differentiable framework for automatically learning view-dependent 2D kernels in a splatting pipeline for novel 3D view synthesis. The primitive consists of a bounding ellipsoid and a 3D-kernel latent vector. A projection network takes these as input to produce a 2D-kernel latent, which is then decoded into a radially symmetric 2D kernel defined via Mahalanobis distance and bounded by the projected ellipsoid. The networks and per-primitive attributes are jointly optimized. The method is evaluated on standard benchmarks against state-of-the-art techniques and extended to general 2D kernels for 2D splatting and image representation.
Significance. If the claimed improvements hold, this work provides a flexible, end-to-end trainable alternative to fixed or analytical kernels in splatting-based rendering, which could enhance both quality and efficiency in 3D reconstruction and novel view synthesis tasks.
minor comments (1)
- [Abstract] The abstract claims comparison 'favorably against state-of-the-art techniques on both analytical and learned kernels' but does not name the specific methods or benchmarks; this information is necessary to assess the contribution.
Simulated Author's Rebuttal
We thank the referee for their summary of our work and for noting its potential significance as a flexible, end-to-end trainable alternative to fixed or analytical kernels. We are pleased that the overall approach was viewed positively and would be happy to address any specific points that contributed to the uncertain recommendation.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces a new end-to-end differentiable pipeline: ellipsoid attributes plus 3D latent vector are fed to a learned projection network producing 2D latent, which a decoder turns into a radially symmetric kernel (Mahalanobis) whose support is the projected ellipsoid. All components are jointly optimized. No equation reduces to its own input by construction, no fitted parameter is relabeled as a prediction, and no load-bearing premise rests on a self-citation chain. The architecture is presented as an empirical trainable system whose performance is evaluated on external benchmarks rather than derived from prior fitted quantities of the same authors.
Axiom & Free-Parameter Ledger
free parameters (2)
- 3D-kernel latent vector
- 2D-kernel latent
axioms (1)
- domain assumption The decoder produces a radially symmetric 2D kernel in terms of Mahalanobis distance bounded by the projected ellipsoid.
Reference graph
Works this paper leans on
-
[1]
Zoubin Bi, Yixin Zeng, Chong Zeng, Fan Pei, Xiang Feng, Kun Zhou, and Hongzhi Wu
Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields.CVPR(2022). Zoubin Bi, Yixin Zeng, Chong Zeng, Fan Pei, Xiang Feng, Kun Zhou, and Hongzhi Wu
2022
-
[2]
3D Gaussian Splatting as a New Era: A Survey,
GS 3: Efficient Relighting with Triple Gaussian Splatting. InSIGGRAPH Asia 2024 Conference Papers. Adam Celarek, George Kopanas, George Drettakis, Michael Wimmer, and Bernhard Kerbl. 2025. Does 3D Gaussian Splatting Need Accurate Volumetric Rendering? arXiv:2502.19318 [cs.GR] https://arxiv.org/abs/2502.19318 Brian Chao, Hung-Yu Tseng, Lorenzo Porzi, Chen ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.