Multi-Agent Systems are Mixtures of Experts: Who Becomes an Influencer?
Pith reviewed 2026-06-29 19:24 UTC · model grok-4.3
The pith
Multi-agent LLM deliberation functions as an input-dependent mixture of experts
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
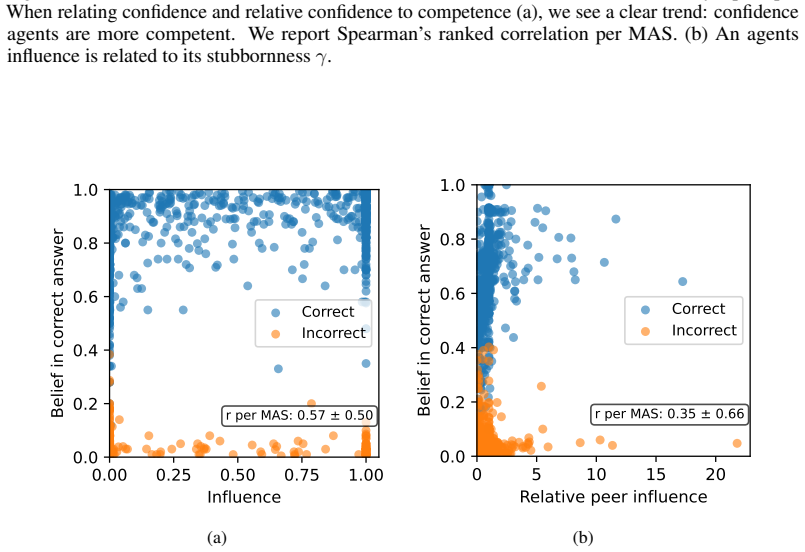
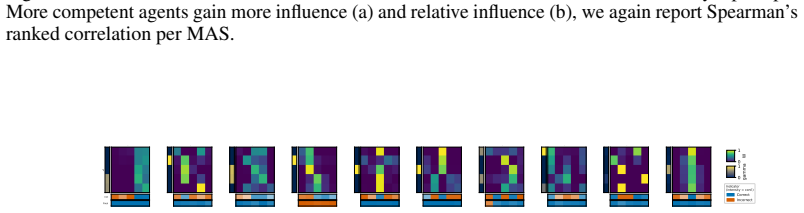
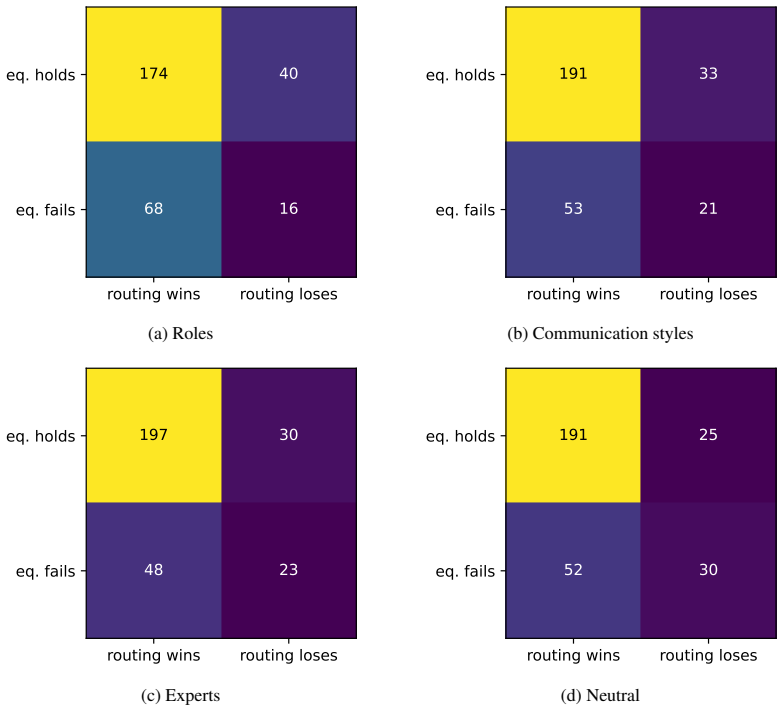
The Friedkin-Johnsen parameters governing multi-agent deliberation are input-dependent, which recasts multi-agent systems as mixtures of experts capable of outperforming single agents and static ensembles when the routing of influence aligns with agent competence.
What carries the argument
Friedkin-Johnsen opinion dynamics, a model that tracks how individual stubbornness and interpersonal influence shape opinion updates over time in a group.
Load-bearing premise
The Friedkin-Johnsen model accurately represents the deliberation and opinion change processes observed in groups of large language models.
What would settle it
A direct measurement showing that the effective influence exerted by each agent in a multi-agent LLM discussion does not change as a function of the input topic or question.
Figures
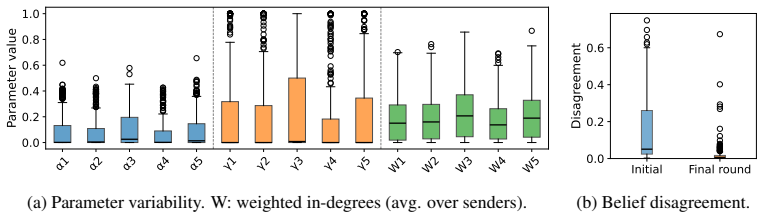

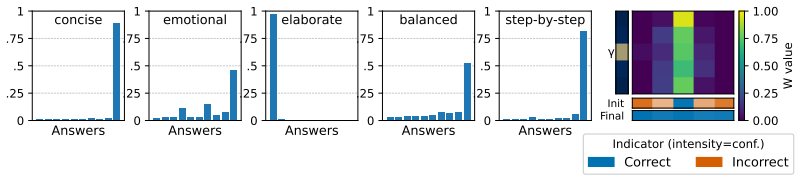


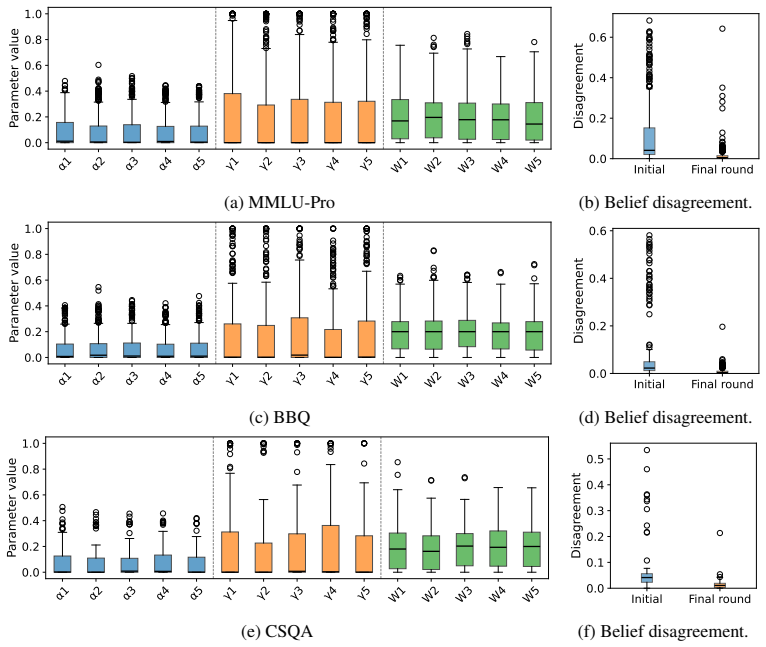
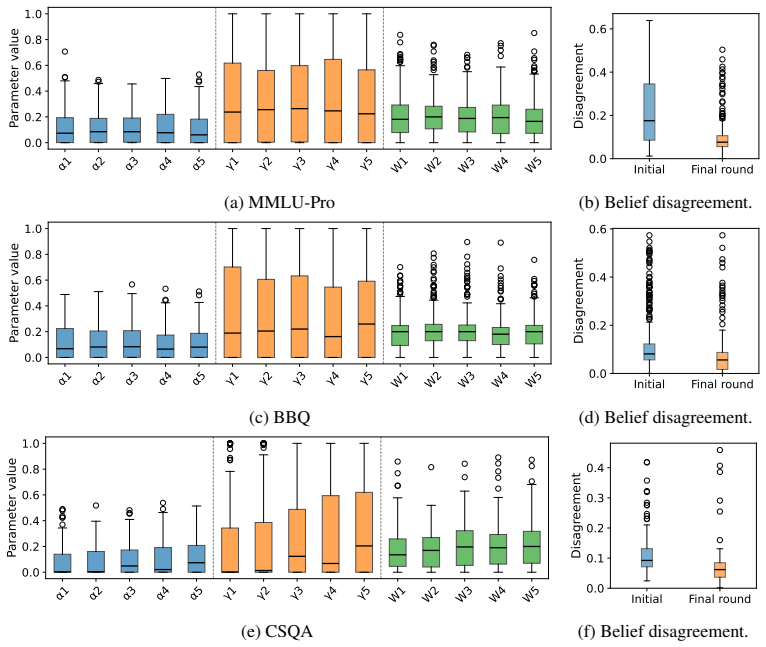
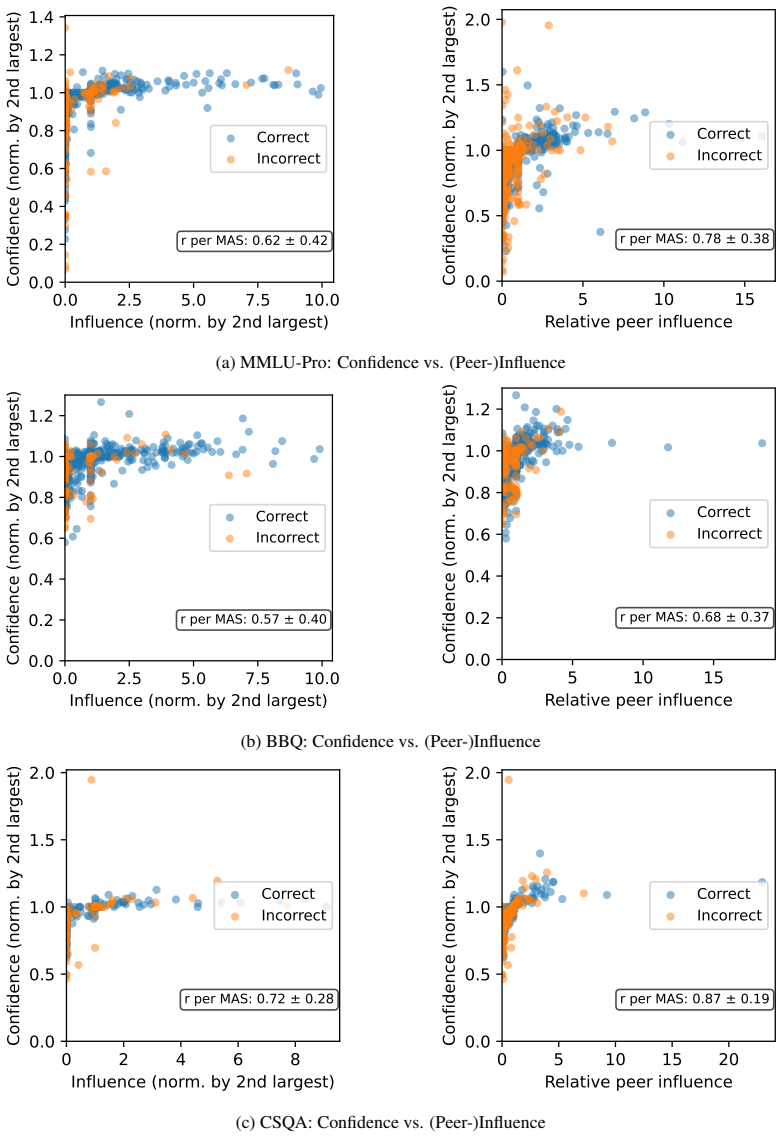
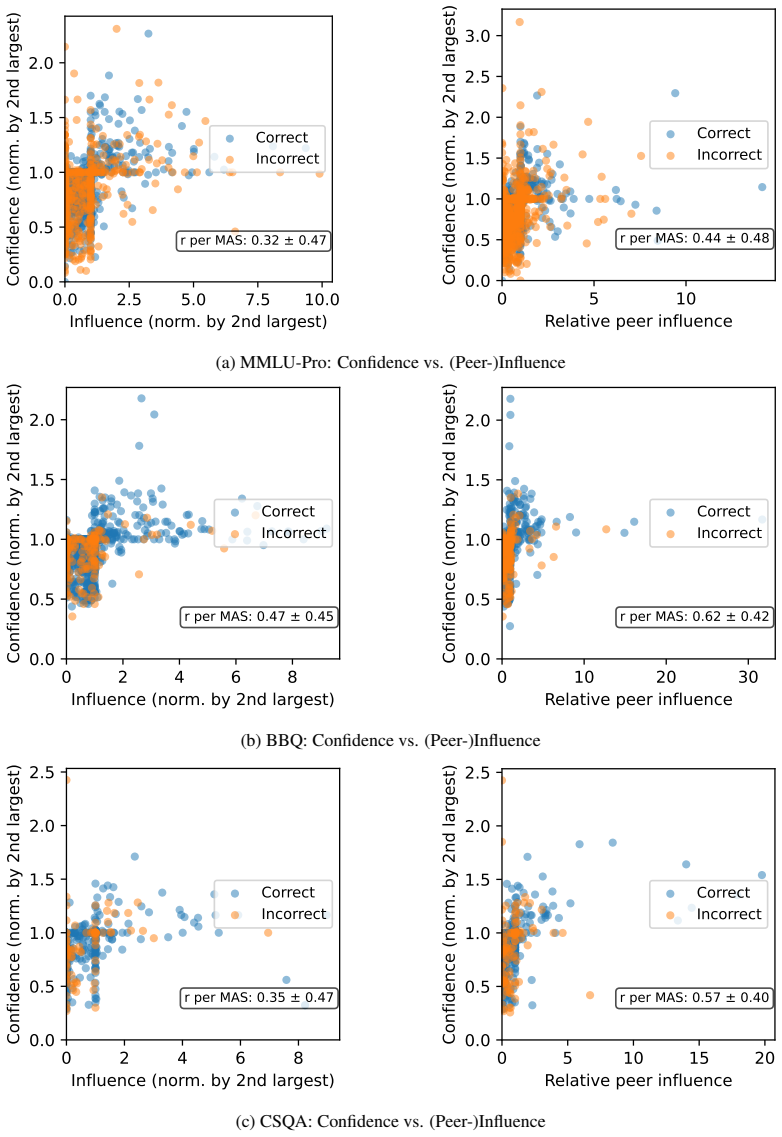
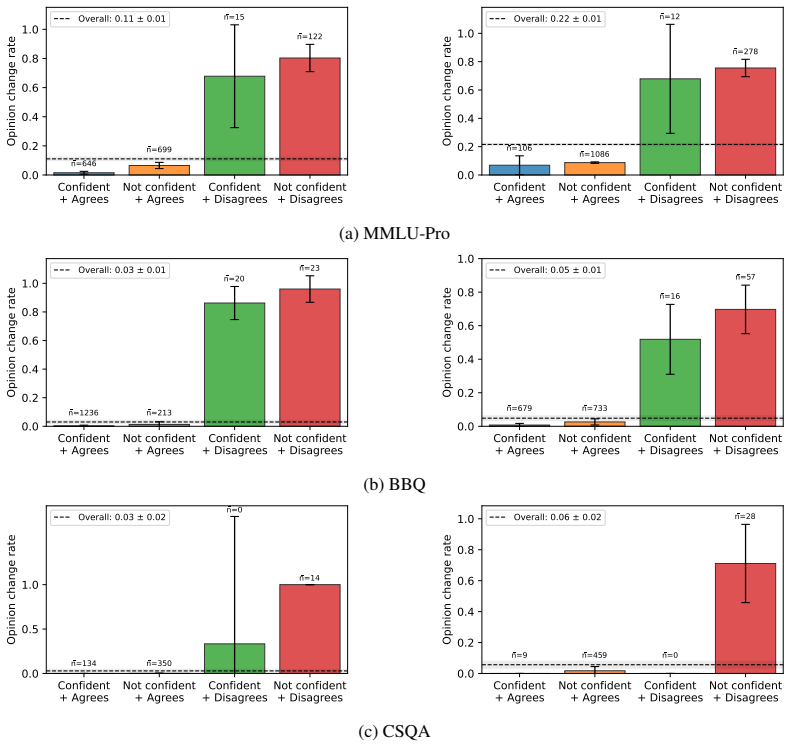



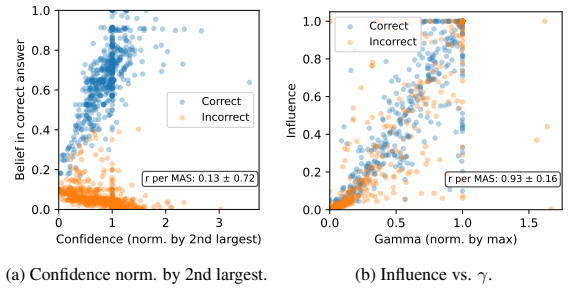


read the original abstract
The effectiveness of multi-agent LLM deliberation depends not only on the agents' individual predictions, but also on how they communicate and collaborate. We study this mechanism through the lens of Friedkin-Johnsen (FJ) opinion dynamics, a tractable model for analyzing stubbornness, influence, and opinion change in multi-agent systems that captures empirically observed deliberation patterns. We show that the FJ parameters are input-dependent, turning multi-agent deliberation into a mixture of experts. This perspective implies that multi-agent systems can outperform single agents and static ensembles when routing reflects agent competence. Since competence is latent in practice, we analyze how influence is established through observable proxies: agents' self-assessed confidence, their perceived confidence, and initial alignment with other agents' views.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper models multi-agent LLM deliberation using the Friedkin-Johnsen (FJ) opinion dynamics framework. It claims that the FJ parameters are input-dependent, which recasts the deliberation process as a mixture of experts. This is used to argue that multi-agent systems can outperform single agents and static ensembles when influence routing aligns with latent agent competence, with influence analyzed via observable proxies including self-assessed confidence, perceived confidence, and initial alignment.
Significance. If the central modeling assumption holds, the work supplies a tractable analytic lens for influence and routing in multi-agent LLM systems, connecting classical opinion dynamics to modern LLM collaboration and offering a route to dynamic, competence-aware ensembles.
major comments (2)
- [Abstract] Abstract: The claim that the FJ model 'captures empirically observed deliberation patterns' is presented without any quantitative support (parameter recovery, trajectory matching, or predictive accuracy against observed LLM opinion updates). This assumption is load-bearing for the subsequent interpretation that input-dependent parameters create a mixture-of-experts routing mechanism.
- [Abstract] The manuscript provides no empirical validation that the FJ model accurately reproduces deliberation dynamics in actual multi-agent LLM interactions. Without such evidence, the claims that input-dependent parameters enable performance gains over static ensembles and that competence can be proxied by the listed observables do not transfer to the target systems.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed report. The two major comments both concern the empirical grounding of the Friedkin-Johnsen modeling assumption. We address each point below and will revise the manuscript to clarify the scope of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the FJ model 'captures empirically observed deliberation patterns' is presented without any quantitative support (parameter recovery, trajectory matching, or predictive accuracy against observed LLM opinion updates). This assumption is load-bearing for the subsequent interpretation that input-dependent parameters create a mixture-of-experts routing mechanism.
Authors: We agree the abstract phrasing is imprecise. The statement references the established literature on FJ dynamics in social systems rather than new quantitative validation on LLM trajectories. We will revise the abstract to read that the FJ model 'provides a tractable analytic framework previously shown to capture patterns in human deliberation' and will add an explicit caveat that direct parameter recovery or trajectory matching on LLM data is left for future work. The mixture-of-experts interpretation follows mathematically from the demonstrated input dependence and does not require the stronger empirical claim. revision: yes
-
Referee: [Abstract] The manuscript provides no empirical validation that the FJ model accurately reproduces deliberation dynamics in actual multi-agent LLM interactions. Without such evidence, the claims that input-dependent parameters enable performance gains over static ensembles and that competence can be proxied by the listed observables do not transfer to the target systems.
Authors: The manuscript is primarily a theoretical contribution that derives the input-dependent FJ equivalence and the resulting mixture-of-experts view, then analyzes observable influence proxies under that model. We do not present new experiments showing that FJ reproduces LLM deliberation trajectories. We will therefore (i) add a limitations paragraph stating that performance gains are conditional on the modeling assumption holding for LLMs and (ii) rephrase the relevant claims to indicate they are implications of the model rather than validated predictions. These changes will prevent over-transfer of the results to deployed systems. revision: yes
Circularity Check
No circularity: derivation relies on external model assumption without self-referential reduction
full rationale
The provided abstract and context present the Friedkin-Johnsen model as an adopted lens that 'captures empirically observed deliberation patterns,' followed by analysis showing input-dependent parameters that reframe deliberation as a mixture of experts. No equations, parameter-fitting steps, or self-citations are quoted that reduce any claimed prediction or uniqueness result to the inputs by construction. The central modeling choice functions as an independent assumption rather than a fitted quantity renamed as output, and the paper's claims about competence proxies and performance advantages remain logically downstream of that assumption without circular collapse. This is the most common honest finding for papers that introduce an external dynamical model.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Don’t trust stubborn neighbors: A security framework for agentic networks.CoRR, abs/2603.15809, 2026
Samira Abedini, Sina Mavali, Lea Schönherr, Martin Pawelczyk, and Rebekka Burkholz. Don’t trust stubborn neighbors: A security framework for agentic networks.CoRR, abs/2603.15809, 2026
-
[2]
Pan, Shuyi Yang, Lakshya A
Mert Cemri, Melissa Z. Pan, Shuyi Yang, Lakshya A. Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, Matei Zaharia, Joseph E. Gonzalez, and Ion Stoica. Why do multi-agent LLM systems fail?, 2025
2025
-
[3]
A survey on llm-based multi-agent system: Recent advances and new frontiers in application
Shuaihang Chen, Yuanxing Liu, Wei Han, Weinan Zhang, and Ting Liu. A survey on llm- based multi-agent system: Recent advances and new frontiers in application.arXiv preprint arXiv:2412.17481, 2024
-
[4]
Towards understanding mixture-of-experts layer in deep learning
Zixiang Chen, Yihe Deng, Yue Wu, Quanquan Gu, and Yuanzhi Li. Towards understanding mixture-of-experts layer in deep learning. InAdvances in Neural Information Processing Systems, volume 35, 2022
2022
-
[5]
Morris H. DeGroot. Reaching a consensus.Journal of the American Statistical Association, 69(345):118–121, 1974
1974
-
[6]
Dietterich
Thomas G. Dietterich. Ensemble methods in machine learning. InMultiple Classifier Systems, pages 1–15. Springer, 2000
2000
-
[7]
Tenenbaum, and Igor Mordatch
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 11409–11431. PMLR, 2024
2024
-
[8]
Friedkin and Eugene C
Noah E. Friedkin and Eugene C. Johnsen. Social influence and opinions.Journal of Mathemati- cal Sociology, 15(3–4):193–206, 1990
1990
-
[9]
Friedkin and Eugene C
Noah E. Friedkin and Eugene C. Johnsen.Social Influence Network Theory: A Sociological Examination of Small Group Dynamics. Cambridge University Press, 2011
2011
-
[10]
Yulong He, Dutao Zhang, Sergey Kovalchuk, Pengyi Li, and Artem Sedakov. Opinion dynamics and mutual influence with llm agents through dialog simulation.arXiv preprint arXiv:2602.12583, 2026
-
[11]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. Metagpt: Meta programming for a multi-agent collaborative framework. InInternational Conference on Learning Representations, 2024
2024
-
[12]
Expert personas improve llm alignment but damage accuracy: Bootstrapping intent-based persona routing with prism, 2026
Zizhao Hu, Mohammad Rostami, and Jesse Thomason. Expert personas improve llm alignment but damage accuracy: Bootstrapping intent-based persona routing with prism, 2026
2026
-
[13]
Jacobs, Michael I
Robert A. Jacobs, Michael I. Jordan, Steven J. Nowlan, and Geoffrey E. Hinton. Adaptive mixtures of local experts.Neural Computation, 3(1):79–87, 1991. 10
1991
-
[14]
Wenxin Jiang and Martin A. Tanner. Hierarchical mixtures-of-experts for generalized linear models: Some results on denseness and consistency. InProceedings of the Seventh International Workshop on Artificial Intelligence and Statistics, volume R2 ofProceedings of Machine Learning Research, 03–06 Jan 1999
1999
-
[15]
Jordan and Robert A
Michael I. Jordan and Robert A. Jacobs. Hierarchical mixtures of experts and the em algorithm. Neural Computation, 6(2):181–214, 1994
1994
-
[16]
Changgeon Ko, Jisu Shin, Hoyun Song, Huije Lee, Eui Jun Hwang, and Jong C. Park. Social dy- namics as critical vulnerabilities that undermine objective decision-making in LLM collectives, 2026
2026
-
[17]
Better zero-shot reasoning with role-play prompting
Aobo Kong, Shiwan Zhao, Hao Chen, Qicheng Li, Yong Qin, Ruiqi Sun, Xin Zhou, Enzhi Wang, and Xiaohang Dong. Better zero-shot reasoning with role-play prompting. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, Mexico City, M...
2024
-
[18]
Jae Hee Lee, Anne Lauscher, and Stefano V Albrecht. Towards ethical multi-agent sys- tems of large language models: A mechanistic interpretability perspective.arXiv preprint arXiv:2512.04691, 2025
-
[19]
CAMEL: Communicative agents for ”mind” exploration of large language model society
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. CAMEL: Communicative agents for ”mind” exploration of large language model society. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[20]
Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jana Thomp- son, Phu Mon Htut, and Samuel R. Bowman. BBQ: A hand-built bias benchmark for question answering. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors,Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, May 22-27, 20...
2022
-
[21]
Parsegov, Anton V
Sergey E. Parsegov, Anton V . Proskurnikov, Roberto Tempo, and Noah E. Friedkin. Novel multidimensional models of opinion dynamics in social networks.IEEE Transactions on Automatic Control, 62(5):2270–2285, May 2017
2017
-
[22]
Proskurnikov and Roberto Tempo
Anton V . Proskurnikov and Roberto Tempo. A tutorial on modeling and analysis of dynamic social networks. part i.Annual Reviews in Control, 43:65–79, 2017
2017
-
[23]
Chatdev: Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, et al. Chatdev: Communicative agents for software development. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 15174–15186, 2024
2024
-
[24]
When shift happens - confounding is to blame
Abbavaram Gowtham Reddy, Celia Rubio-Madrigal, Rebekka Burkholz, and Krikamol Muandet. When shift happens - confounding is to blame. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[25]
Boosting for predictive sufficiency
Abbavaram Gowtham Reddy, Rajeev Verma, Celia Rubio-Madrigal, Krikamol Muandet, and Rebekka Burkholz. Boosting for predictive sufficiency. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[26]
Explainability in human–agent systems.Autonomous agents and multi-agent systems, 33(6):673–705, 2019
Avi Rosenfeld and Ariella Richardson. Explainability in human–agent systems.Autonomous agents and multi-agent systems, 33(6):673–705, 2019
2019
-
[27]
Should we be going MAD? A look at multi-agent debate strategies for LLMs
Andries Petrus Smit, Nathan Grinsztajn, Paul Duckworth, Thomas D Barrett, and Arnu Pretorius. Should we be going MAD? A look at multi-agent debate strategies for LLMs. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International Conference on Mac...
2024
-
[28]
Robustness of mixtures of experts to feature noise
Dong Sun, Rahul Nittala, and Rebekka Burkholz. Robustness of mixtures of experts to feature noise. InForty-third International Conference on Machine Learning, 2026
2026
-
[29]
Commonsenseqa: A question answering challenge targeting commonsense knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. Commonsenseqa: A question answering challenge targeting commonsense knowledge. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (...
2019
-
[30]
Opinion dynamics in social networks with stubborn agents: An issue-based perspective.Automatica, 96:213–223, 2018
Ye Tian and Long Wang. Opinion dynamics in social networks with stubborn agents: An issue-based perspective.Automatica, 96:213–223, 2018
2018
-
[31]
Dat Tran and Douwe Kiela. Single-agent llms outperform multi-agent systems on multi-hop reasoning under equal thinking token budgets.arXiv preprint arXiv:2604.02460, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Decoding echo chambers: LLM-powered simulations revealing polarization in social networks
Chenxi Wang, Zongfang Liu, Dequan Yang, and Xiuying Chen. Decoding echo chambers: LLM-powered simulations revealing polarization in social networks. In Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, and Steven Schockaert, editors,Proceedings of the 31st International Conference on Computational Linguistics, pages 3913–3...
2025
-
[33]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[34]
MMLU-pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. MMLU-pro: A more robust and challenging multi-task language understanding benchmark. InThe Thirty-eight Conference on Neural Information Processin...
2024
-
[35]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems 35: Annual Conference on Neura...
2022
-
[36]
John Wiley & Sons, 2 edition, 2009
Michael Wooldridge.An Introduction to MultiAgent Systems. John Wiley & Sons, 2 edition, 2009
2009
-
[37]
Opinion dynamics in learning systems, 2026
Jiduan Wu, Rediet Abebe, and Celestine Mendler-Dünner. Opinion dynamics in learning systems, 2026
2026
-
[38]
Autogen: Enabling next-gen LLM applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, and Chi Wang. Autogen: Enabling next-gen LLM applications via multi-agent conversations. InFirst Conference on Language Modeling, 2024
2024
-
[39]
teacher": ###Role### You are an excellent teacher and always teach your students problems correctly
Hangfan Zhang, Zhiyao Cui, Jianhao Chen, Xinrun Wang, Qiaosheng Zhang, Zhen Wang, Dinghao Wu, and Shuyue Hu. Stop overvaluing multi-agent debate – we must rethink evaluation and embrace model heterogeneity, 2025. 12 A Theory: Proofs of theorems and discussion Equilibrium beliefs are convex ensembles.The Friedkin-Johnsen dynamics induce a graph- dependent ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.