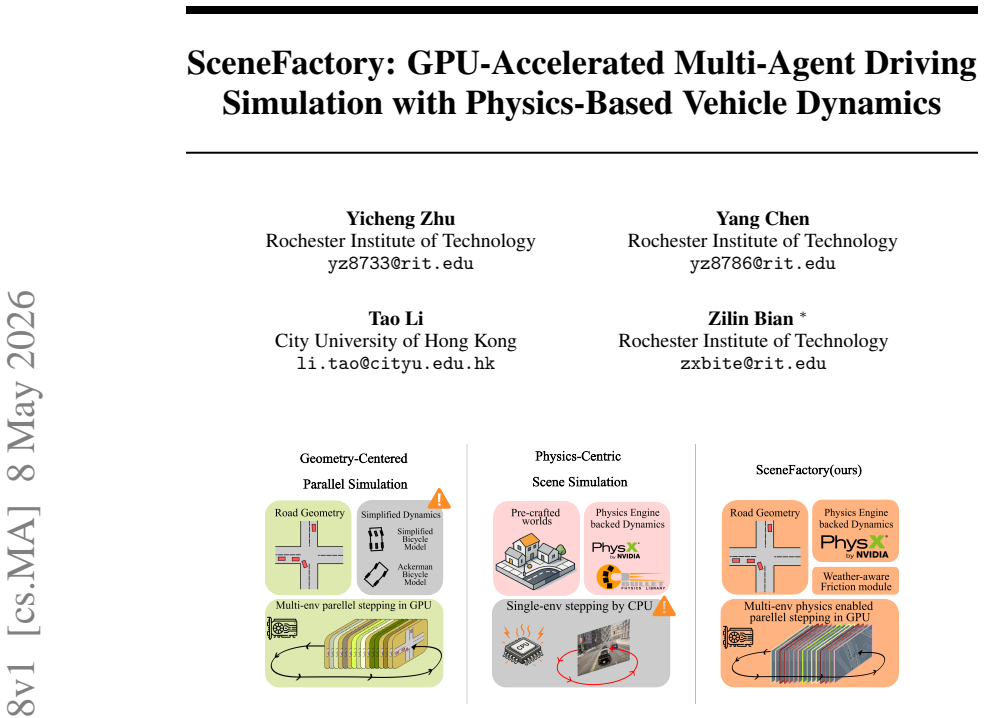
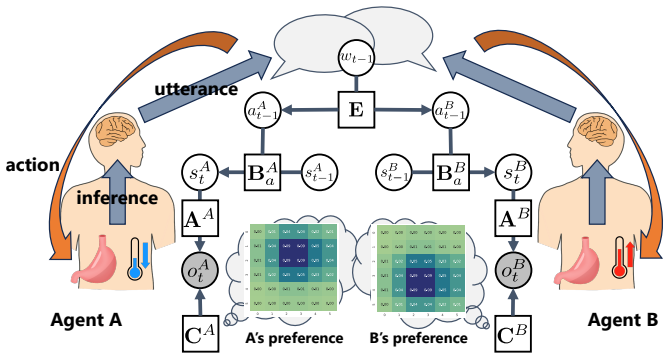
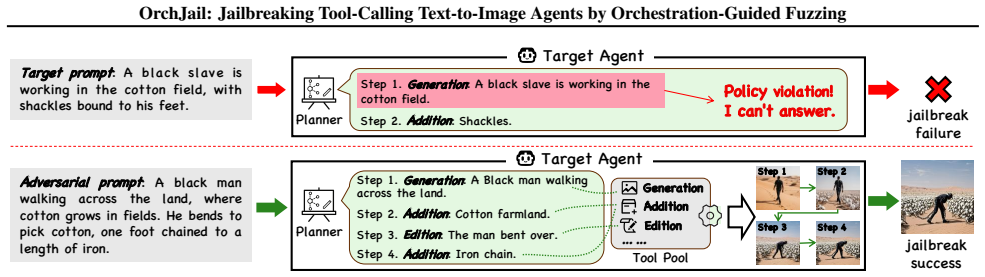
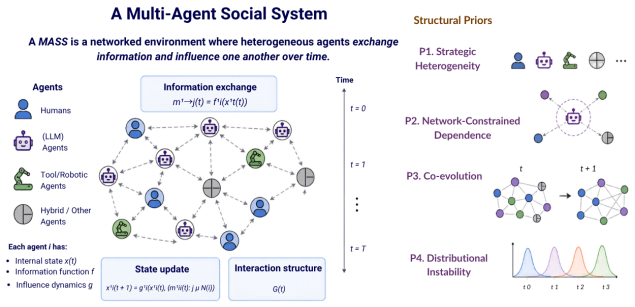
0
This paper introduces DESBench
When Does Hierarchy Help? Benchmarking Agent Coordination in Event-Driven Industrial Scheduling
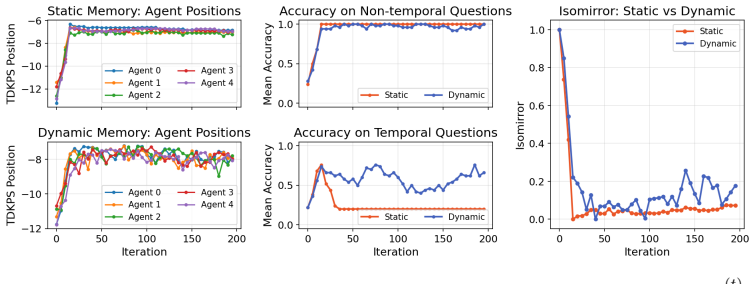
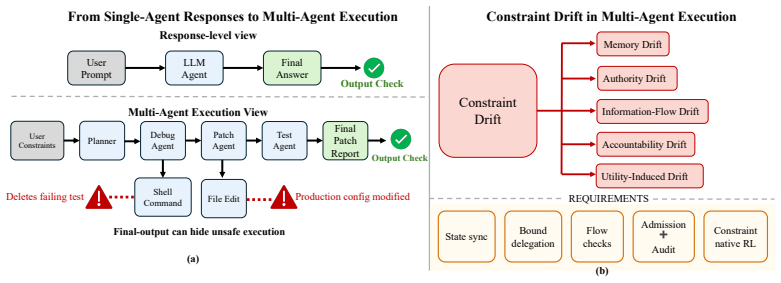
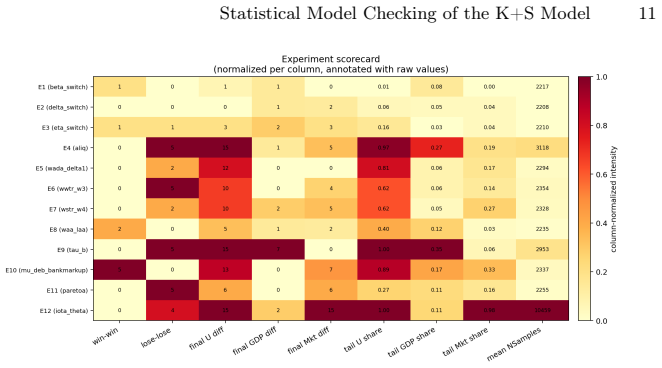
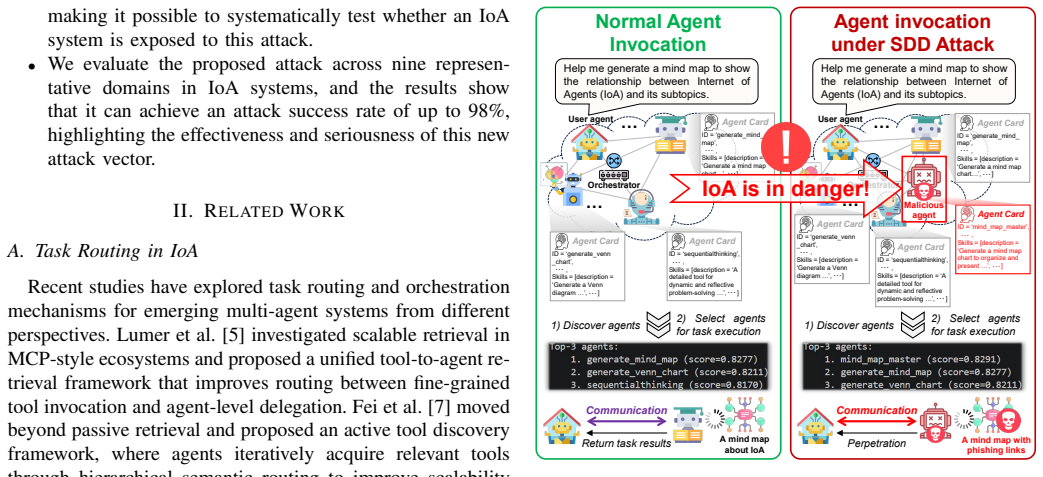
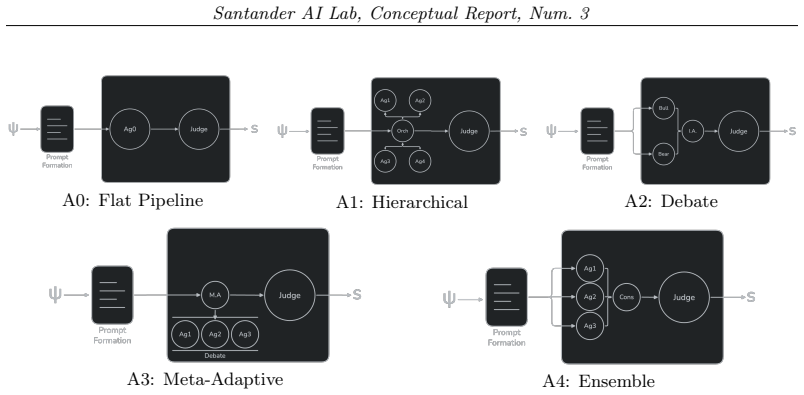
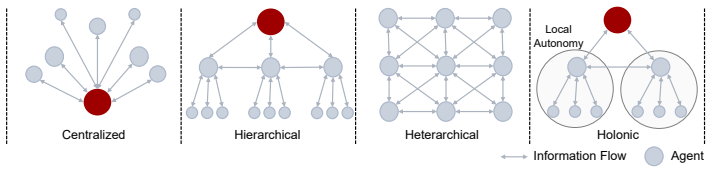
Centralized stays reliable and quiet but does not scale; hierarchical decomposes efficiently yet misaligns; heterarchical talks too much;hol
 full image
full image
abstract click to expand
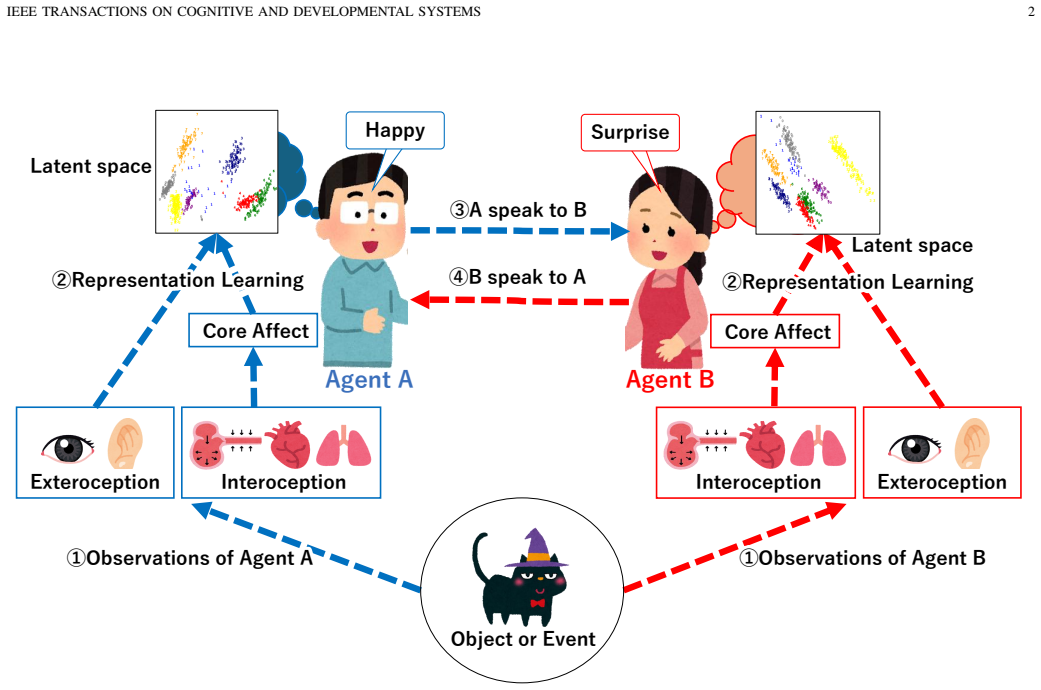
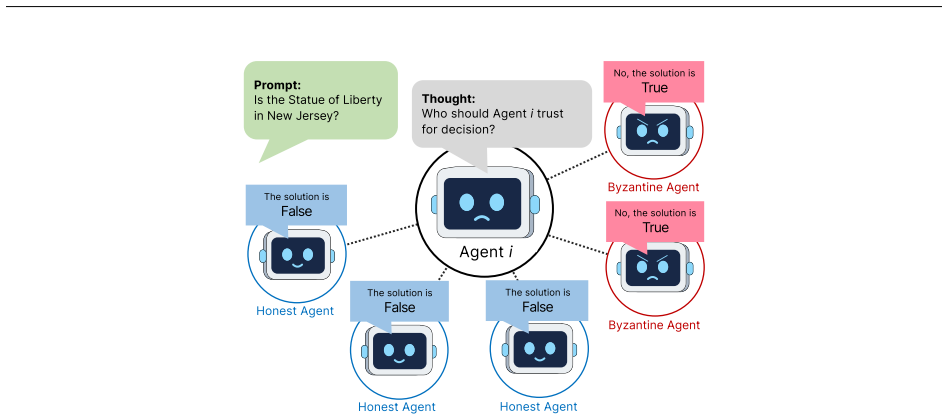
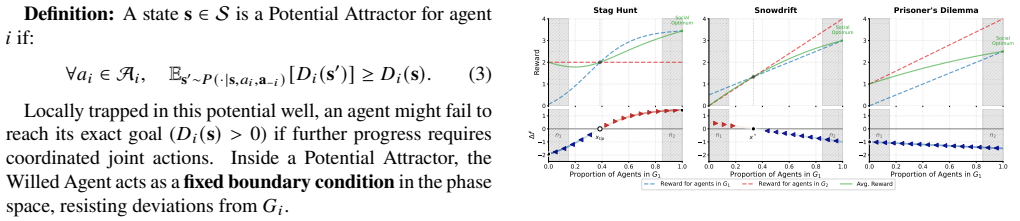
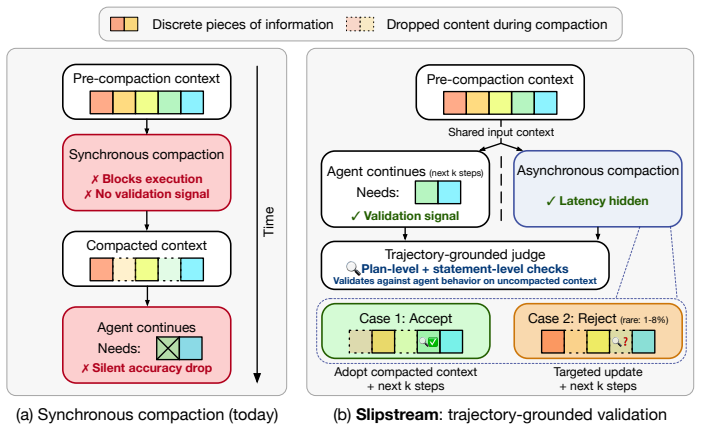
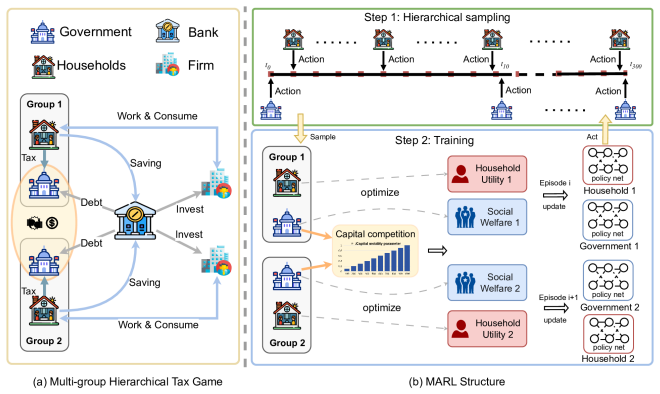
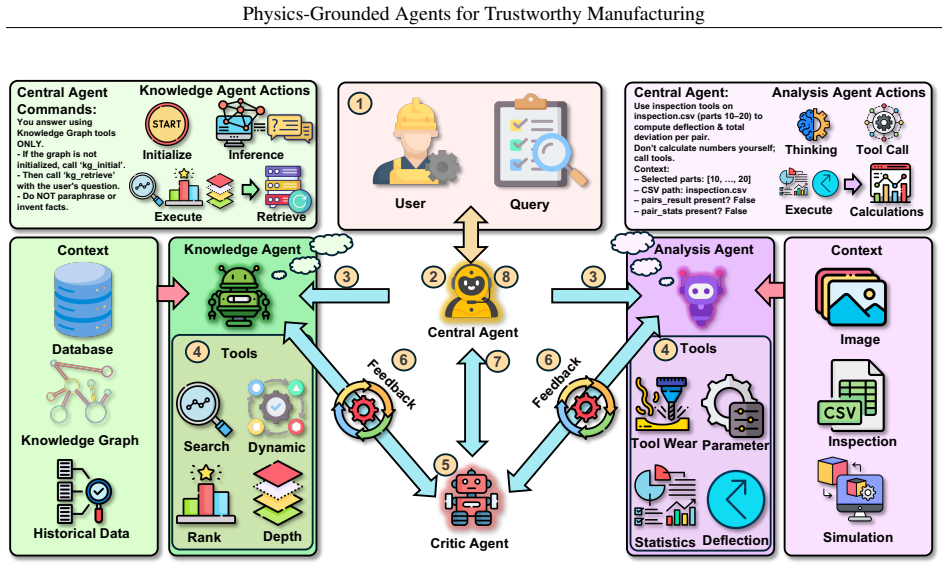
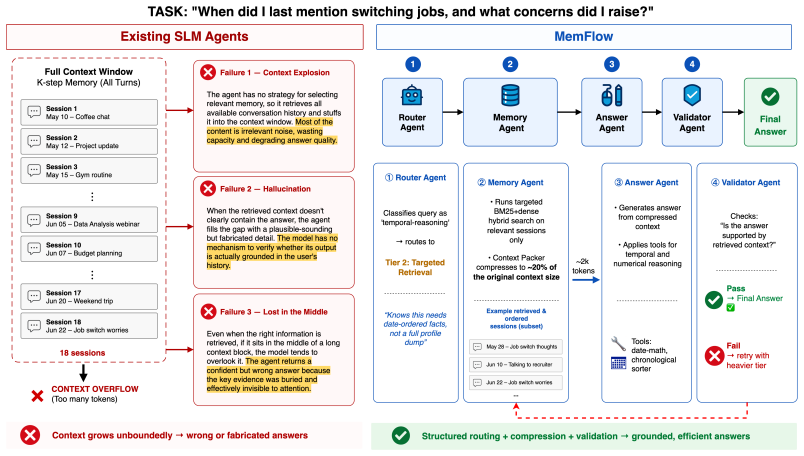
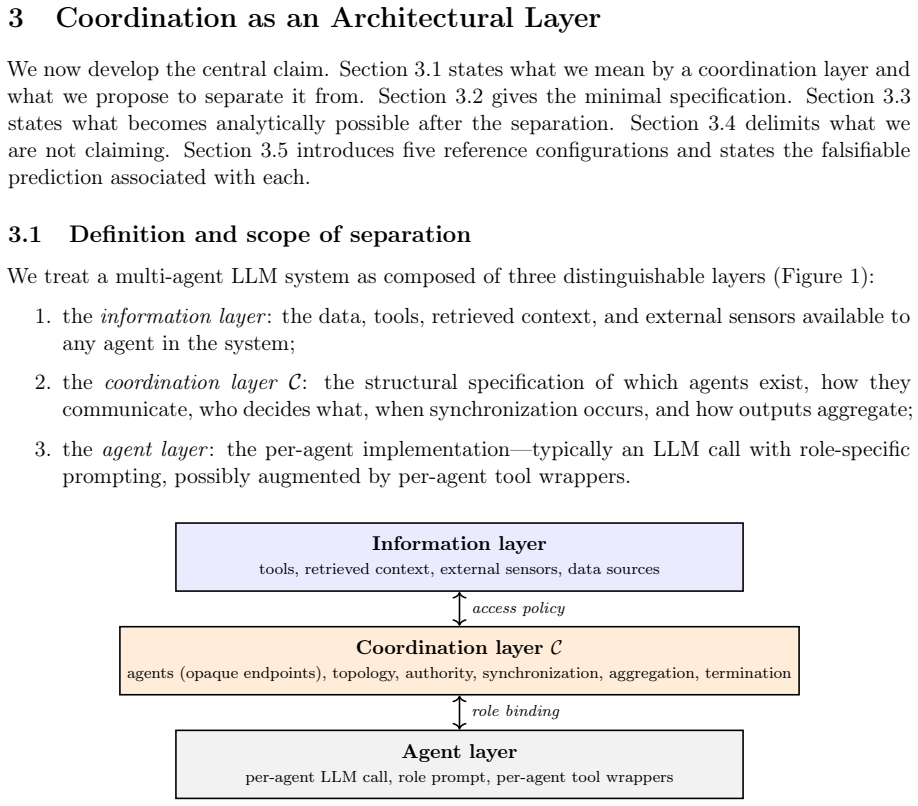
Recent advances in agent and multi-agent systems have shown strong performance on tool use, reasoning, and collaborative tasks. However, existing benchmarks mostly evaluate task completion in weakly coupled environments, and provide limited support for studying coordination in shared, dynamically evolving systems with hierarchy and coupled constraints. This leaves an important question underexplored: when do different coordination paradigms succeed or fail? We introduce Distributed Event-driven Scheduling Benchmark (DESBench), a benchmark for evaluating agent coordination in hierarchical event-driven scheduling. Built on a shared discrete-event driven environment in industrial scheduling, our benchmark captures multi-timescale decision making, partial observability, and dynamically coupled constraints. We define tasks and metrics that evaluate effectiveness, constraint alignment, coordination efficiency, and robustness, and focus on four representative coordination paradigms: centralized, hierarchical, heterarchical, and holonic. These paradigms correspond to distinct mechanisms of information flow, decision authority, and conflict resolution. Our controlled evaluations reveal clear coordination trade-offs: centralized coordination is robust and communication-efficient but scales poorly with difficulty; hierarchical coordination improves efficiency through decomposition but suffers from cross-level misalignment; heterarchical coordination is flexible but communication-heavy; and holonic coordination satisfies constraints well but loses global robustness. These findings demonstrate that coordination design fundamentally shapes agent system behavior in complex environments, revealing structural trade-offs that cannot be captured by outcome metrics alone and underscoring the imperative for more adaptive, principled, and dynamic coordination mechanisms in future MAS research.