RAPTOR+: A Visually Grounded Vision-Language Framework to Improve Clinical Trust and Auditability in Automated Cancer Referral Processing
Pith reviewed 2026-06-29 22:19 UTC · model grok-4.3
The pith
Fine-tuned vision-language models achieve 96.1 percent reading accuracy and 60.6 percent strict safety on colorectal cancer referral forms by directly linking outputs to visual evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
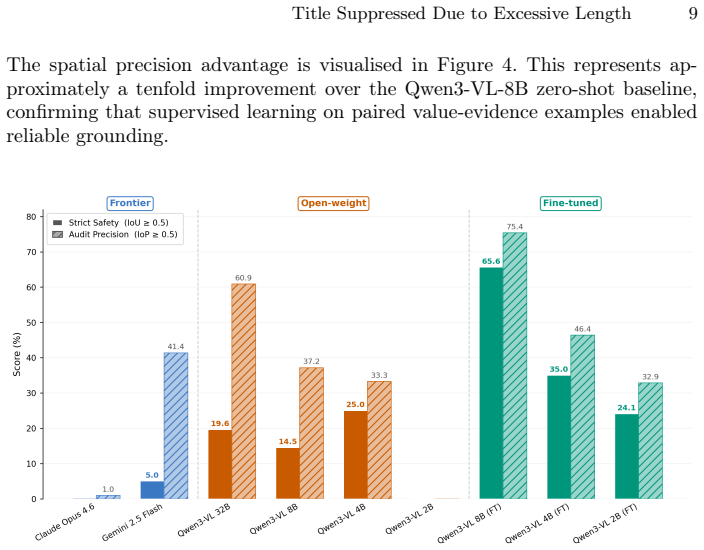
RAPTOR+ shows that fine-tuning a vision-language model on clinically curated referral forms produces both high reading accuracy (96.1 percent) and markedly better evidence localisation (60.6 percent Strict Safety), whereas zero-shot models such as Gemini 2.5 Flash reach 92.6 percent accuracy but only 1.2 percent strict safety. The resulting pipeline therefore allows every extracted referral decision to be traced back to specific visual evidence inside the document, removing the linkage loss that occurred in the original OCR-based approach.
What carries the argument
A grounding-aware evaluation framework that separately measures reading accuracy and strict evidence localisation for each extracted field across the referral form.
If this is right
- Extracted referral decisions can be directly linked to specific regions in the source image.
- Automated triage can advance with reduced manual review for cases that pass strict safety checks.
- The separate OCR stage and its associated handwriting and layout errors are eliminated.
- The same fine-tuning procedure can be repeated for other semi-structured clinical document workflows.
Where Pith is reading between the lines
- Hospitals could integrate the grounded outputs directly into electronic health record systems to cut transcription time.
- The strict-safety metric may serve as a reusable audit tool for other vision-language applications in medicine.
- Expanding the fine-tuning set beyond the current 223 forms could raise strict safety scores further while preserving accuracy.
Load-bearing premise
The performance differences observed on these 223 CRC referral forms will generalise to other clinical document types and institutions.
What would settle it
Repeating the evaluation on referral documents from a second hospital or on non-CRC clinical forms shows that the fine-tuned model no longer outperforms zero-shot models on the strict safety metric.
Figures



read the original abstract
Urgent suspected colorectal cancer (CRC) referrals create operational bottlenecks because semi-structured clinical documents often require manual review and transcription. The original RAPTOR system used Large Language Models for structured extraction but relied on a separate OCR stage, making it vulnerable to handwriting, layout variation, and loss of visual evidence linkage. We present RAPTOR+, a multimodal extension that uses Vision-Language Models (VLMs) for end-to-end referral understanding. We evaluate fine-tuned VLMs, commercial and open-source zero-shot VLMs, and the original OCR-based pipeline on 223 clinically curated CRC urgent referral forms. We also introduce a grounding-aware evaluation framework that measures both extraction accuracy and evidence localisation. Results show a clear grounding gap in zero-shot models. Gemini 2.5 Flash achieved 92.6% Reading Accuracy but only 1.2% Strict Safety. In contrast, fine-tuned Qwen3-VL-8B achieved 96.1% Reading Accuracy and 60.6% Strict Safety, substantially improving verifiable evidence grounding. These findings show that task-specific fine-tuning is essential for reliable, auditable clinical document understanding. RAPTOR+ enables extracted referral decisions to be linked to visual evidence, supporting safer and more efficient cancer referral triage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RAPTOR+, a multimodal vision-language model extension of the original RAPTOR system for end-to-end structured extraction from semi-structured colorectal cancer (CRC) urgent referral forms. It evaluates fine-tuned VLMs (e.g., Qwen3-VL-8B), zero-shot commercial and open-source VLMs, and the prior OCR-based pipeline on a set of 223 clinically curated CRC forms. The authors report that the fine-tuned Qwen3-VL-8B reaches 96.1% Reading Accuracy and 60.6% Strict Safety while zero-shot models such as Gemini 2.5 Flash reach 92.6% Reading Accuracy but only 1.2% Strict Safety. They introduce a grounding-aware evaluation framework and conclude that task-specific fine-tuning is essential for reliable, auditable clinical document understanding with verifiable visual evidence linkage.
Significance. If the reported gains in evidence grounding and safety metrics hold under broader testing, the work would provide a concrete demonstration that VLM fine-tuning can close the grounding gap in clinical document processing, directly supporting auditability and trust in automated cancer referral triage. The introduction of a grounding-aware metric set is a positive contribution to evaluation practices in this domain.
major comments (2)
- [Abstract] Abstract: The central claim that 'task-specific fine-tuning is essential for reliable, auditable clinical document understanding' is not supported by the evaluation design. All reported results (96.1% Reading Accuracy, 60.6% Strict Safety for fine-tuned Qwen3-VL-8B versus 1.2% Strict Safety for Gemini 2.5 Flash) are obtained on the same 223 CRC urgent referral forms; no cross-institution, cross-domain, or out-of-distribution test set is described, so the performance gap may reflect domain match rather than a general necessity of fine-tuning.
- [Abstract] Abstract / Evaluation description: No information is supplied on dataset splits, fine-tuning procedure (learning rate, epochs, data augmentation), statistical testing of the accuracy/safety differences, or potential curation bias in the 223 forms. These omissions make it impossible to determine whether the 60.6% Strict Safety figure is robust or an artifact of the narrow document class.
minor comments (1)
- [Abstract] Abstract: The terms 'Reading Accuracy' and 'Strict Safety' are used without inline definitions or reference to the precise formulas or annotation protocol that produce the reported percentages.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address the two major concerns regarding the scope of our evaluation and the completeness of methodological details. We agree that the current manuscript would benefit from clearer qualification of claims and additional experimental information, and we will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'task-specific fine-tuning is essential for reliable, auditable clinical document understanding' is not supported by the evaluation design. All reported results (96.1% Reading Accuracy, 60.6% Strict Safety for fine-tuned Qwen3-VL-8B versus 1.2% Strict Safety for Gemini 2.5 Flash) are obtained on the same 223 CRC urgent referral forms; no cross-institution, cross-domain, or out-of-distribution test set is described, so the performance gap may reflect domain match rather than a general necessity of fine-tuning.
Authors: We acknowledge that the evaluation is performed on a single clinically curated set of 223 CRC urgent referral forms and that no cross-institution, cross-domain, or out-of-distribution testing is reported. This limits the strength of the general claim. The observed gap in Strict Safety (60.6% vs 1.2%) nevertheless illustrates a concrete grounding failure of zero-shot models even on in-domain data. We will revise the abstract to qualify the conclusion as applying to this clinical document class and will add an explicit Limitations section discussing the need for multi-institution validation. revision: partial
-
Referee: [Abstract] Abstract / Evaluation description: No information is supplied on dataset splits, fine-tuning procedure (learning rate, epochs, data augmentation), statistical testing of the accuracy/safety differences, or potential curation bias in the 223 forms. These omissions make it impossible to determine whether the 60.6% Strict Safety figure is robust or an artifact of the narrow document class.
Authors: The manuscript describes the 223 forms as clinically curated by domain experts (Section 3), but we agree that train/test splits, fine-tuning hyperparameters, statistical testing, and explicit discussion of curation bias are insufficiently detailed. We will expand the Methods and Evaluation sections to report the split (70/30), fine-tuning settings (learning rate, epochs, augmentation), statistical significance tests on the accuracy and safety differences, and a discussion of potential curation effects. These additions will allow readers to assess robustness. revision: yes
Circularity Check
No circularity in empirical model comparison
full rationale
The paper reports performance metrics from evaluating fine-tuned and zero-shot VLMs on a fixed set of 223 CRC referral forms, with no equations, derivations, or self-citations that reduce any claim to its inputs by construction. The central findings (e.g., 96.1% Reading Accuracy for fine-tuned Qwen3-VL-8B) are direct empirical observations rather than predictions or theorems derived from fitted parameters or prior self-citations. This is a standard model benchmarking study whose claims rest on the reported test-set differences, not on any self-referential loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Interventions to improve timely cancer diagnosis: an integrative review.Diagnosis, 12(2):153–162, 2025
Mark L Graber, Bradford D Winters, Roni Matin, Rosann T Cholankeril, Daniel R Murphy, Hardeep Singh, and Andrea Bradford. Interventions to improve timely cancer diagnosis: an integrative review.Diagnosis, 12(2):153–162, 2025
2025
-
[2]
Characterising the volume and variation of multiple urgent suspected cancer referrals in england, april 2013–march 2018: a national cohort study.BMJ open, 15(4):e097180, 2025
Kirstin Roberts, Nicola Cooper, Laura Webster, Ben Sharpless, Thomas Round, Carolynn Gildea, and Brian D Nicholson. Characterising the volume and variation of multiple urgent suspected cancer referrals in england, april 2013–march 2018: a national cohort study.BMJ open, 15(4):e097180, 2025
2013
-
[3]
Codesigned standardised referral form: simplifying the complexity.BMJ health & care informatics, 31(1):e100926, 2024
Scott Laing, Sarah Jarmain, Jacobi Elliott, Janet Dang, Vala Gylfadottir, Kayla Wierts, and Vineet Nair. Codesigned standardised referral form: simplifying the complexity.BMJ health & care informatics, 31(1):e100926, 2024
2024
-
[4]
Automated medical chart review for breast cancer outcomes research: a novel natural language processing extraction system.BMC medical research methodology, 22(1):136, 2022
Yifu Chen, Lucy Hao, Vito Z Zou, Zsuzsanna Hollander, Raymond T Ng, and Kathryn V Isaac. Automated medical chart review for breast cancer outcomes research: a novel natural language processing extraction system.BMC medical research methodology, 22(1):136, 2022
2022
-
[5]
Raptor: Generative ai for parsing colorectal cancer referrals to streamline faster diagnostic standard pathways
Sofiat Abioye, Shazad Ashraf, Junaid Qadir, Adam Byfield, Anusha Jose, William Poulett, Ben Wallace, Adil Butt, Colm Forde, Marcus Mottershead, et al. Raptor: Generative ai for parsing colorectal cancer referrals to streamline faster diagnostic standard pathways. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pag...
2025
-
[6]
Layoutlmv3: Pre-training for document ai with unified text and image masking
Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, and Furu Wei. Layoutlmv3: Pre-training for document ai with unified text and image masking. InProceedings of the 30th ACM international conference on multimedia, pages 4083–4091, 2022
2022
-
[7]
Ocr-free document understanding transformer
Geewook Kim, Teakgyu Hong, Moonbin Yim, JeongYeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, and Seunghyun Park. Ocr-free document understanding transformer. InEuropean Conference on Computer Vision, pages 498–517. Springer, 2022
2022
-
[8]
Ufaq Khan, Umair Nawaz, LDMSS Teja, Numaan Saeed, Muhammad Bilal, Yu- tong Xie, Mohammad Yaqub, and Muhammad Haris Khan. Medobvious: Ex- posing the medical moravec’s paradox in vlms via clinical triage.arXiv preprint arXiv:2603.23501, 2026
-
[9]
Surveyofhallucinationinnatural language generation.ACM computing surveys, 55(12):1–38, 2023
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, YeJinBang,AndreaMadotto,andPascaleFung. Surveyofhallucinationinnatural language generation.ACM computing surveys, 55(12):1–38, 2023. 12 S. Abioye et al
2023
-
[10]
Towards improv- ing faithfulness in abstractive summarization.Advances in Neural Information Processing Systems, 35:24516–24528, 2022
Xiuying Chen, Mingzhe Li, Xin Gao, and Xiangliang Zhang. Towards improv- ing faithfulness in abstractive summarization.Advances in Neural Information Processing Systems, 35:24516–24528, 2022
2022
-
[11]
Advances in ai and machine learning for predictive medicine.Journal of Human Genetics, 69(10):487–497, 2024
Alok Sharma, Artem Lysenko, Shangru Jia, Keith A Boroevich, and Tatsuhiko Tsunoda. Advances in ai and machine learning for predictive medicine.Journal of Human Genetics, 69(10):487–497, 2024
2024
-
[12]
Hybrid classfication for heart disease prediction using artificial intelligence
Jasmeen Gill et al. Hybrid classfication for heart disease prediction using artificial intelligence. In2021 5th international conference on computing methodologies and communication (ICCMC), pages 1779–1785. IEEE, 2021
2021
-
[13]
Federated learning framework for self- powered iot sensor networks with explainable ai: A novel approach for sustainable and privacy-preserving distributed intelligence
Waheed Rasheed, Anthonette Chidinma, Kazeem Adamson Mutiu, Olufemi Owolabi, Onome Jennifer Jike, Okiki Olumide, Oluwatosin Oyeladun, Gabriel Ovie, and Obinna Emmanuel Obi-Akwari. Federated learning framework for self- powered iot sensor networks with explainable ai: A novel approach for sustainable and privacy-preserving distributed intelligence. InProcee...
2025
-
[14]
The minimum information about clinical artificial intelli- gence checklist for generative modeling research (mi-claim-gen).Nature medicine, 31(5):1394, 2025
Brenda Y Miao, Irene Y Chen, Christopher YK Williams, Jaysón Davidson, Au- gusto Garcia-Agundez, Shenghuan Sun, Travis Zack, Suchi Saria, Rima Arnaout, Giorgio Quer, et al. The minimum information about clinical artificial intelli- gence checklist for generative modeling research (mi-claim-gen).Nature medicine, 31(5):1394, 2025
2025
-
[15]
Large language models are few-shot health learners.arXiv preprint arXiv:2305.15525, 2023
Xin Liu, Daniel McDuff, Geza Kovacs, Isaac Galatzer-Levy, Jacob Sunshine, Jien- ing Zhan, Ming-Zher Poh, Shun Liao, Paolo Di Achille, and Shwetak Patel. Large language models are few-shot health learners.arXiv preprint arXiv:2305.15525, 2023
-
[16]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Selfai:Building a self-training ai system with llm agents.arXiv preprint arXiv:2512.00403, 2025
Xiao Wu, Ting-Zhu Huang, Liang-Jian Deng, Xiaobing Yu, Yu Zhong, Shangqi Deng,UfaqKhan,JianghaoWu,XiaofengLiu,ImranRazzak,etal. Selfai:Building a self-training ai system with llm agents.arXiv preprint arXiv:2512.00403, 2025
-
[18]
Reporting guideline for the early stage clinical evaluation of decision support systems driven by artificial intelligence: Decide-ai.bmj, 377, 2022
Baptiste Vasey, Myura Nagendran, Bruce Campbell, David A Clifton, Gary S Collins, Spiros Denaxas, Alastair K Denniston, Livia Faes, Bart Geerts, Mudathir Ibrahim, et al. Reporting guideline for the early stage clinical evaluation of decision support systems driven by artificial intelligence: Decide-ai.bmj, 377, 2022
2022
-
[19]
Rethinking pascal-voc and ms-coco dataset for small object detection.Journal of Visual Communication and Image Representation, 93:103830, 2023
Kang Tong and Yiquan Wu. Rethinking pascal-voc and ms-coco dataset for small object detection.Journal of Visual Communication and Image Representation, 93:103830, 2023
2023
-
[20]
Ngiou loss: Gener- alized intersection over union loss based on a new bounding box regression.Applied Sciences, 12(24):12785, 2022
Chenghao Tong, Xinhao Yang, Qing Huang, and Feiyang Qian. Ngiou loss: Gener- alized intersection over union loss based on a new bounding box regression.Applied Sciences, 12(24):12785, 2022
2022
-
[21]
Health care language models and their fine-tuning for information extraction: scoping review.JMIR medical informatics, 12(1):e60164, 2024
Miguel Nunes, Joao Bone, Joao C Ferreira, and Luis B Elvas. Health care language models and their fine-tuning for information extraction: scoping review.JMIR medical informatics, 12(1):e60164, 2024
2024
-
[22]
Usability of a human factors-based clinical decision support in the emergency department: lessons learned for design and implementa- tion.Human factors, 66(3):647–657, 2024
Megan E Salwei, Peter Hoonakker, Pascale Carayon, Douglas Wiegmann, Michael Pulia, and Brian W Patterson. Usability of a human factors-based clinical decision support in the emergency department: lessons learned for design and implementa- tion.Human factors, 66(3):647–657, 2024
2024
-
[23]
Vision-language models for medical report generation and visual question answering: A review.Frontiers in artificial intelli- gence, 7:1430984, 2024
Iryna Hartsock and Ghulam Rasool. Vision-language models for medical report generation and visual question answering: A review.Frontiers in artificial intelli- gence, 7:1430984, 2024. Title Suppressed Due to Excessive Length 13
2024
-
[24]
Efficient detection of adversarial, out-of- distribution and other misclassified samples.Neurocomputing, 470:335–343, 2022
Julia Lust and Alexandru P Condurache. Efficient detection of adversarial, out-of- distribution and other misclassified samples.Neurocomputing, 470:335–343, 2022
2022
-
[25]
Ai safety for everyone.Nature Machine Intelligence, 7(4):531–542, 2025
Balint Gyevnar and Atoosa Kasirzadeh. Ai safety for everyone.Nature Machine Intelligence, 7(4):531–542, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.