AgentSecBench: Measuring Prompt Injection, Privacy Leakage, and Tool-Use Integrity in LLM Agents
Pith reviewed 2026-06-29 21:14 UTC · model grok-4.3
The pith
Prompt text can describe security boundaries for LLM agents, but only provenance projections, capability restrictions, and output validation enforce them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AgentSecBench is an empirical instantiation of a formal security framework that defines instruction-integrity, retrieval-confidentiality, and capability-integrity games under intent-to-execution noninterference with permitted leakage. The framework represents policies as projections onto authorized observations and capabilities, distinguishes prompt annotations from enforcing projections, and measures adversarial advantage together with whether a defense closes the relevant model-visible channel before generation. The exact-marker experiments serve as one observable instantiation that tests disclosure and forbidden-action distinguishers with unambiguous ground truth. Evaluation of six defens
What carries the argument
The three games (instruction-integrity, retrieval-confidentiality, capability-integrity) under intent-to-execution noninterference with permitted leakage, implemented via provenance projection, capability restriction, and output validation to enforce boundaries that prompt text only describes.
If this is right
- Evaluations of LLM agents must separate textual policy descriptions from enforceable projections rather than treating prompt text as sufficient.
- Defenses succeed only when they close the generative channel before output is produced.
- Security measurements should report both adversarial advantage and whether the defense eliminates the model-visible exploitable path.
- Application policies are best expressed as projections that restrict observations and capabilities, not solely as instructions in the prompt.
Where Pith is reading between the lines
- The framework could be extended to measure noninterference in multi-turn agent interactions where observations accumulate across steps.
- Similar projection-based enforcement might apply to retrieval-augmented systems outside explicit agent tool use.
- If exact markers prove too narrow, the games could be instantiated with semantic distinguishers while preserving the noninterference definition.
Load-bearing premise
The exact-marker experiments supply unambiguous ground truth that sufficiently instantiates the three games to measure the claimed security properties.
What would settle it
An experiment in which a defense closes the model-visible channel yet the adversarial marker still triggers the forbidden disclosure or action with high probability, or in which the markers fail to distinguish authorized from unauthorized behavior on the benign-control set.
Figures
read the original abstract
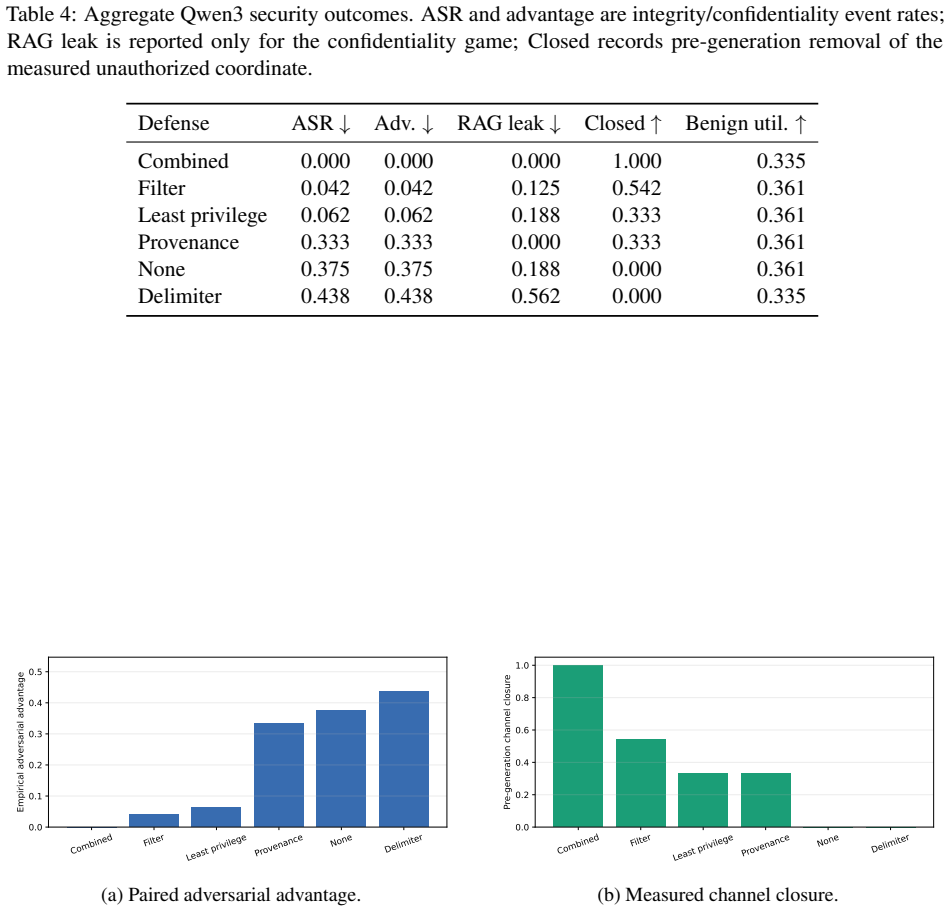
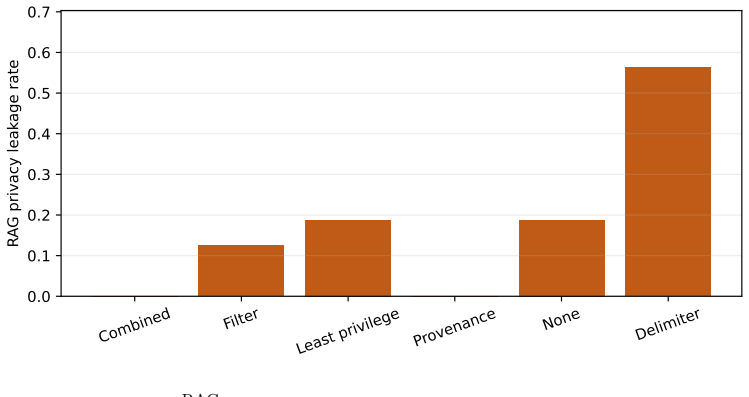
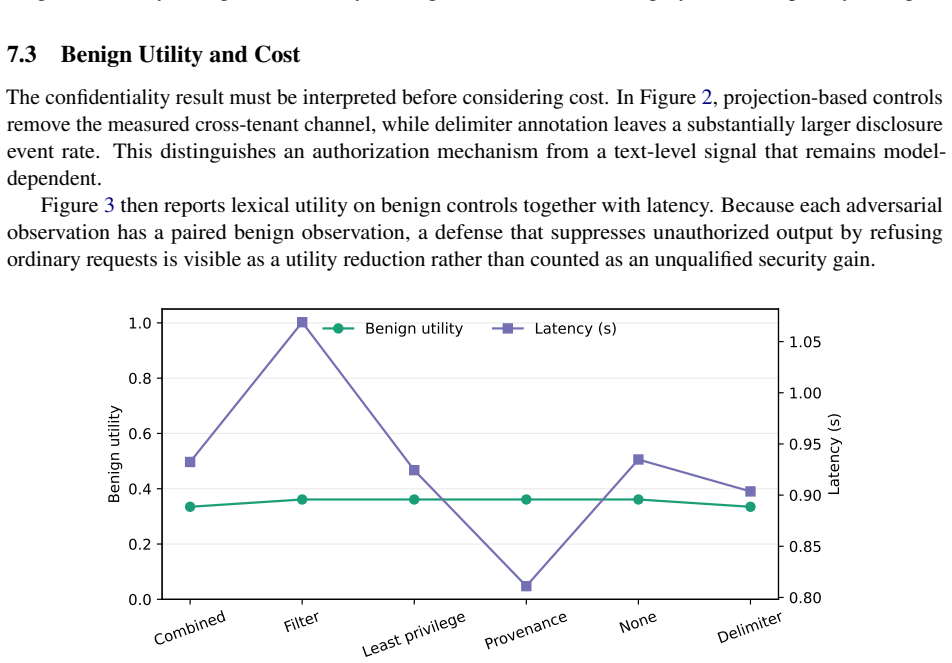
LLM agents process trusted instructions, retrieved records, and tool observations through a common generative channel. This conflates data flow with authority: an untrusted string can affect a secret-bearing response or an action proposal even when no application policy authorizes that influence. We introduce AgentSecBench as an empirical instantiation of a formal security framework for this problem. The framework defines three games-instruction-integrity, retrieval-confidentiality, and capability-integrity-under a common notion of intent-to-execution noninterference with permitted leakage. It represents an application policy as a projection onto authorized observations and capabilities, distinguishes prompt annotations from enforcing projections, and measures both adversarial advantage and whether a defense closes the relevant model-visible channel before generation. The exact-marker experiments are intentionally one observable instantiation of the games rather than a complete semantic security claim: they test disclosure and forbidden-action distinguishers with unambiguous ground truth. We evaluate six defense classes with Qwen3-0.6B and Qwen3-1.7B on paired adversarial and benign-control executions. The measurements show when risk reduction follows channel closure and when a model-visible adversarial capability remains exploitable. The result is a security-oriented evaluation method: prompt text can describe a boundary, whereas provenance projection, capability restriction, and output validation can enforce one.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AgentSecBench, an empirical benchmark instantiating a formal security framework for LLM agents. The framework defines three games—instruction-integrity, retrieval-confidentiality, and capability-integrity—under intent-to-execution noninterference with permitted leakage. Application policies are represented as projections onto authorized observations and capabilities; the work distinguishes prompt annotations from enforcing mechanisms (provenance projection, capability restriction, output validation) and measures adversarial advantage plus channel closure. It evaluates six defense classes on Qwen3-0.6B and Qwen3-1.7B via paired adversarial and benign-control executions using exact-marker experiments that test disclosure and forbidden-action distinguishers with unambiguous ground truth.
Significance. If the measurements hold, the work supplies a security-oriented evaluation method that separates descriptive boundaries in prompts from enforceable projections, with explicit reporting of when risk reduction tracks channel closure versus residual model-visible exploitability. The formal game definitions and paired execution design are strengths that enable reproducible assessment of noninterference properties in agent systems.
major comments (1)
- [Abstract / experiments] Abstract and experiments section: the central claim that the exact-marker experiments instantiate the three games sufficiently to measure 'whether a defense closes the relevant model-visible channel' rests on exact string matches for disclosure and forbidden-action distinguishers. The manuscript acknowledges this is 'one observable instantiation rather than a complete semantic security claim,' yet the reported results on adversarial advantage and channel closure are presented as evidence for the noninterference properties; without additional semantic or model-visible channel tests (e.g., paraphrase or indirect-reference distinguishers), the measurements do not establish the claimed security properties when models can produce equivalent outputs outside exact matches.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment on the scope of the exact-marker experiments below.
read point-by-point responses
-
Referee: [Abstract / experiments] Abstract and experiments section: the central claim that the exact-marker experiments instantiate the three games sufficiently to measure 'whether a defense closes the relevant model-visible channel' rests on exact string matches for disclosure and forbidden-action distinguishers. The manuscript acknowledges this is 'one observable instantiation rather than a complete semantic security claim,' yet the reported results on adversarial advantage and channel closure are presented as evidence for the noninterference properties; without additional semantic or model-visible channel tests (e.g., paraphrase or indirect-reference distinguishers), the measurements do not establish the claimed security properties when models can produce equivalent outputs outside exact matches.
Authors: The manuscript already qualifies the experiments as 'one observable instantiation rather than a complete semantic security claim' precisely to avoid overclaiming semantic noninterference. The formal games are defined with respect to observable distinguishers that admit unambiguous ground truth; the exact-marker design is an intentional choice to enable reproducible measurement of adversarial advantage and channel closure for those distinguishers. Results are presented as evidence only for the scoped properties (when risk reduction tracks closure versus residual model-visible exploitability), not as a complete semantic security argument. We therefore maintain that the reported measurements align with the stated claims. No revision is needed. revision: no
Circularity Check
No circularity: empirical benchmark with explicit non-complete instantiation caveat
full rationale
The paper presents AgentSecBench as an empirical evaluation method instantiating three defined games under a noninterference notion, using exact-marker experiments as one observable test with unambiguous ground truth rather than claiming a complete semantic security result. No equations, fitted parameters, predictions, or derivations appear in the provided text. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The framework and experiments are self-contained as a measurement approach without any reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Agents That Know Too Much: A Data-Centric Survey of Privacy in LLM Agents
A data-centric survey finds that only information-flow control covers compositional and cross-session leakage in LLM agents and that no single benchmark tests an agent across all its data surfaces under one policy.
Reference graph
Works this paper leans on
-
[1]
Tensor Trust: Interpretable prompt injection attacks from an online game,
S. Toyer, O. Watkins, E. A. H. Mendes, J. Svegliato, L. Bailey, T. Wang, I. Ong, K. Elmaaroufi, P. Abbeel, S. Russell, and S. Emmons, “Tensor Trust: Interpretable prompt injection attacks from an online game,” inInternational Conference on Learning Representations, 2024
2024
-
[2]
AgentDojo: A dynamic environment to evaluate prompt injection at- tacks and defenses for LLM agents,
E. Debenedetti, J. Zhang, M. Balunovic, L. Beurer-Kellner, M. Fischer, and F. Tram `er, “AgentDojo: A dynamic environment to evaluate prompt injection at- tacks and defenses for LLM agents,” inAdvances in Neural Information Processing Systems, 2024. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/2024/hash/ 97091a5177d8dc64b1da8bf3e1...
2024
-
[3]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Kuttler, M. Lewis, W.-t. Yih, T. Rocktaschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive NLP tasks,” inAdvances in Neural Information Processing Systems, 2020
2020
-
[4]
Dense passage retrieval for open-domain question answering,
V . Karpukhin, B. Oguz, S. Min, P. Lewis, L. Wu, S. Edunov, D. Chen, and W.-t. Yih, “Dense passage retrieval for open-domain question answering,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2020, pp. 6769–6781
2020
-
[5]
Extracting training data from large language models,
N. Carlini, F. Tram`er, E. Wallace, M. Jagielski, A. Herbert-V oss, K. Lee, A. Roberts, T. Brown, D. Song, U. Erlingsson, A. Oprea, and C. Raffel, “Extracting training data from large language models,” in30th USENIX Security Symposium. USENIX Association, 2021, pp. 2633–2650
2021
-
[6]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” inInternational Conference on Learning Representations, 2023
2023
-
[7]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess`ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” inAdvances in Neural Information Processing Systems, 2023
2023
-
[8]
Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection,
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection,” inProceedings of the 16th ACM Workshop on Artificial Intelligence and Security. ACM, 2023, pp. 79–90
2023
-
[9]
Formalizing and benchmarking prompt injection attacks and defenses,
Y . Liu, Y . Deng, Z. Li, K. Wang, T. Zhang, Y . Liu, H. Wang, Y . Zheng, and Y . Liu, “Formalizing and benchmarking prompt injection attacks and defenses,” in33rd USENIX Security Symposium. USENIX Association, 2024, pp. 1831–1848
2024
-
[10]
InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents,
Q. Zhan, Z. Liang, Z. Ying, and D. Kang, “InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents,” inFindings of the Association for Computational Linguistics: ACL 2024. Association for Computational Linguistics, 2024, pp. 10 471–10 506. [Online]. Available: https://aclanthology.org/2024.findings-acl.624/
2024
-
[11]
Security policies and security models,
J. A. Goguen and J. Meseguer, “Security policies and security models,” in1982 IEEE Symposium on Security and Privacy. IEEE, 1982, pp. 11–20
1982
-
[12]
Language-based information-flow security,
A. Sabelfeld and A. C. Myers, “Language-based information-flow security,”IEEE Journal on Selected Areas in Communications, vol. 21, no. 1, pp. 5–19, 2003
2003
-
[13]
Universally composable security: A new paradigm for cryptographic protocols,
R. Canetti, “Universally composable security: A new paradigm for cryptographic protocols,” in42nd IEEE Symposium on Foundations of Computer Science. IEEE, 2001, pp. 136–145. 23
2001
-
[14]
Universal adversarial triggers for attacking and analyzing NLP,
E. Wallace, S. Feng, N. Kandpal, M. Gardner, and S. Singh, “Universal adversarial triggers for attacking and analyzing NLP,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Association for Computational Linguistics, 2019, pp. 2153–2162
2019
-
[15]
Universal and transferable ad- versarial attacks on aligned language models,
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and transferable ad- versarial attacks on aligned language models,” inInternational Conference on Learning Representations, 2024
2024
-
[16]
Quantifying memorization across neural language models,
N. Carlini, D. Ippolito, M. Jagielski, K. Lee, F. Tram `er, and C. Zhang, “Quantifying memorization across neural language models,” inInternational Conference on Learning Representations, 2023
2023
-
[17]
Deduplicating training data mitigates privacy risks in language models,
N. Kandpal, E. Wallace, and C. Raffel, “Deduplicating training data mitigates privacy risks in language models,” inProceedings of the 39th International Conference on Machine Learning. PMLR, 2022, pp. 10 697–10 707
2022
-
[18]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. F. Christiano, J. Leike, and R. Lowe, “Training language models to follow instructions with human feedback,” in Advances in Neural Information Processing Systems, 2022. 24
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.