Detail Consistent Stage-Wise Distillation for Efficient 3D MRI Segmentation
Pith reviewed 2026-06-29 22:09 UTC · model grok-4.3
The pith
Stage-wise wavelet distillation lets compact 3D MRI segmenters retain fine lesion boundaries without inference cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that aligning directional detail components in the wavelet domain at each encoder stage, while leaving the coarse approximation comparatively unconstrained, transfers fine structural information from a large teacher to a compact student 3D segmenter. Because the method is active only during training, the final deployed model incurs no extra memory or latency. On BraTS 2024 and ISLES 2022 the approach yields higher segmentation accuracy than competing distillation and compression techniques for 3D multi-modal MRI.
What carries the argument
Detail Consistent Distillation (DCD): a stage-wise framework that distills only the directional wavelet detail sub-bands between teacher and student features while leaving the approximation band relatively free.
If this is right
- Compact 3D encoders can match or exceed the lesion-boundary accuracy of full-size teachers on BraTS and ISLES benchmarks.
- The method adds no runtime overhead once training is complete.
- Global context learning remains intact because the low-frequency wavelet band is not strongly regularized.
- The same stage-wise pattern can be applied to any multi-resolution 3D encoder architecture.
Where Pith is reading between the lines
- The same selective wavelet alignment could be tested on CT or ultrasound volumes where fine detail is equally critical.
- Pairing DCD with quantization or pruning might produce even smaller models whose accuracy still holds on boundary-sensitive structures.
- If the wavelet basis is changed from the default to a more anisotropic one, the method might better suit elongated anatomical features such as vessels.
Load-bearing premise
Aligning directional detail components in the wavelet domain at each stage preserves fine structural cues without negatively impacting the learning of global semantics.
What would settle it
A controlled ablation in which the student trained without wavelet-detail alignment shows measurably lower Dice scores on small enhancing-tumor or acute-stroke regions compared with the DCD-trained student on the same data splits.
Figures
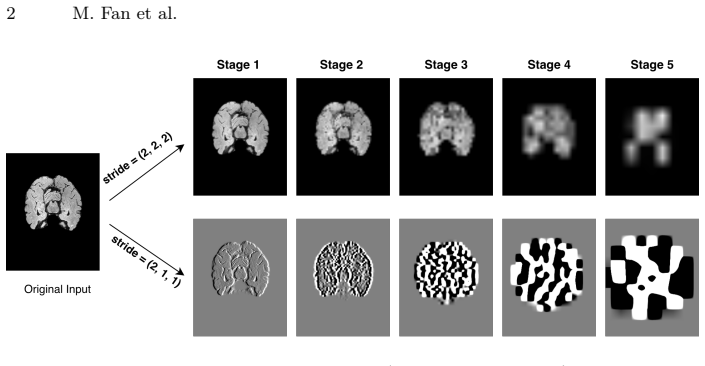
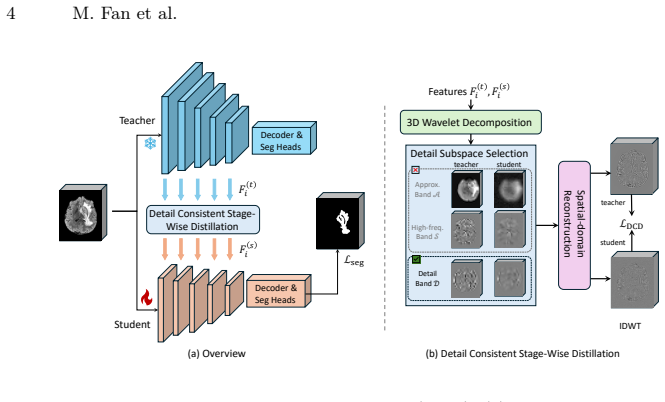
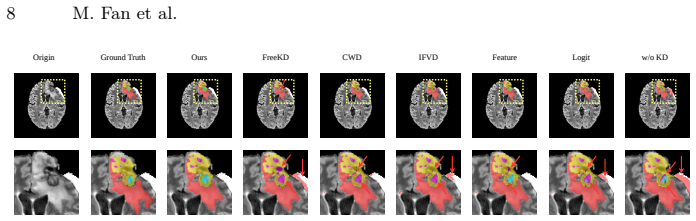
read the original abstract
Deploying high-performing 3D medical image segmenters (e.g., nnU-Net) is often limited by memory footprint and inference latency. Compression is therefore necessary, but compact 3D encoders tend to lose fine structural cues (small lesions and sharp boundaries) as downsampling repeats across multi-resolution stages. We propose Detail Consistent Distillation (DCD), a stage-wise distillation framework that preserves structural detail across scales by aligning teacher-student features in a wavelet-decomposed representation. At each encoder stage, DCD distills directional detail components in the wavelet domain while leaving the coarse approximation comparatively unconstrained, avoiding over-regularization of global semantics. DCD is used only during training and introduces no inference-time overhead. Experiments on the BraTS 2024 and ISLES 2022 benchmarks demonstrate that our approach achieves superior performance in MRI segmentation using 3D multi-modal data. Code and implementation details for DCD are publicly available at https://github.com/ClinicaAlpha/DCD-3D-MedSeg.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Detail Consistent Distillation (DCD), a stage-wise knowledge distillation framework for efficient 3D MRI segmentation. At each encoder stage, directional detail components are aligned in the wavelet domain between a teacher (e.g., nnU-Net) and a compact student while the coarse approximation remains comparatively unconstrained. The method is training-only, adds no inference overhead, and is claimed to achieve superior performance on the BraTS 2024 and ISLES 2022 benchmarks for 3D multi-modal data.
Significance. If the empirical claims are substantiated, the work would address a practical bottleneck in deploying high-performing 3D medical segmenters by mitigating loss of fine structural detail during compression. Public code release would further support reproducibility. The core premise—that selective wavelet detail alignment preserves cues without harming global semantics—targets a relevant gap, but requires verification to establish impact.
major comments (2)
- [Abstract] Abstract: the claim that the approach 'achieves superior performance' on BraTS 2024 and ISLES 2022 supplies no quantitative metrics, tables, ablation studies, or experimental details, preventing verification that the data supports the central claim.
- [Method] Method section (DCD description): the premise that distilling only directional wavelet components while leaving the coarse approximation unconstrained 'avoids over-regularization of global semantics' is untested; no ablation isolates the coarse pathway, no feature-map analysis is provided, and no examination of back-propagation through shared encoder weights or skip connections is given, leaving the separation assumption load-bearing but unsupported.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the approach 'achieves superior performance' on BraTS 2024 and ISLES 2022 supplies no quantitative metrics, tables, ablation studies, or experimental details, preventing verification that the data supports the central claim.
Authors: We agree the abstract lacks specific numbers. In revision we will insert concise quantitative results (e.g., mean Dice on each benchmark versus the teacher and prior distillation baselines) while preserving the abstract's length limit. Full tables and protocols remain in the Results section. revision: yes
-
Referee: [Method] Method section (DCD description): the premise that distilling only directional wavelet components while leaving the coarse approximation unconstrained 'avoids over-regularization of global semantics' is untested; no ablation isolates the coarse pathway, no feature-map analysis is provided, and no examination of back-propagation through shared encoder weights or skip connections is given, leaving the separation assumption load-bearing but unsupported.
Authors: The observation is correct: the manuscript does not contain an ablation that isolates the coarse pathway or feature-map/back-propagation analysis. We will add (i) an ablation comparing DCD against a variant that also distills the coarse approximation and (ii) qualitative feature visualizations plus a short discussion of gradient flow through the shared encoder and skip connections. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes Detail Consistent Distillation (DCD) as a novel stage-wise training procedure that aligns directional wavelet detail components while leaving coarse approximations unconstrained. This is framed as an empirical method with no inference overhead, evaluated directly on external public benchmarks (BraTS 2024 and ISLES 2022) against standard baselines. No equations, self-citations, or claims reduce outputs to inputs by construction; the central performance claims rest on experimental results rather than tautological fits or renamed assumptions. The derivation is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining
Buciluˇ a, C., Caruana, R., Niculescu-Mizil, A.: Model compression. In: Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining. pp. 535–541 (2006)
2006
- [2]
-
[3]
In: International conference on medical image computing and computer-assisted intervention
Çiçek, Ö., Abdulkadir, A., Lienkamp, S.S., Brox, T., Ronneberger, O.: 3d u-net: learning dense volumetric segmentation from sparse annotation. In: International conference on medical image computing and computer-assisted intervention. pp. 424–432. Springer (2016)
2016
-
[4]
Daubechies, I.: Ten Lectures on Wavelets, CBMS-NSF Regional Conference Series in Applied Mathematics, vol. 61. Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA (1992).https://doi.org/10.1137/1.9781611970104
-
[5]
In: 2024 27th International Conference on Information Fusion (FUSION)
Fan, M., Geng, B., Li, K., Wang, X., Varshney, P.K.: Interpretable data fusion for distributed learning: A representative approach via gradient matching. In: 2024 27th International Conference on Information Fusion (FUSION). pp. 1–8. IEEE (2024)
2024
-
[6]
In: 2025 International Joint Confer- ence on Neural Networks (IJCNN)
Fan, M., Li, K., Zhang, T., Tian, Q., Geng, B.: Pfeddst: Personalized federated learning with decentralized selection training. In: 2025 International Joint Confer- ence on Neural Networks (IJCNN). pp. 1–8. IEEE (2025)
2025
-
[7]
In: Proceedings of the 7th ACM International Con- ference on Multimedia in Asia
Fan, M., Zhang, T., Geng, B.: A unified framework for the convergence and weight pruning in federated learning. In: Proceedings of the 7th ACM International Con- ference on Multimedia in Asia. pp. 1–5 (2025)
2025
-
[8]
Intelligent Systems with Applications p
Fan, M., Zhang, T., Ma, X., Guo, J., Zhan, Z., Zhou, S., Qin, M., Ding, C., Geng, B., Fardad, M., et al.: A unified dnn weight compression framework using reweighted optimization methods. Intelligent Systems with Applications p. 200556 (2025) 10 M. Fan et al
2025
-
[9]
Field, D.J.: Relations between the statistics of natural images and the response properties of cortical cells. Journal of the Optical Society of America A4(12), 2379–2394 (1987).https://doi.org/10.1364/JOSAA.4.002379
-
[10]
Sci- entific Data9, 762 (2022).https://doi.org/10.1038/s41597-022-01875-5
Hernandez Petzsche, M.R., Kiesel, S., Huber, F., Labuschagne, C.A., Zamboni, N.S., Noth, J., Zietz, K., Buerger, M.G., Kaesmacher, J., Wiest, R., Reyes, M.: Public dataset of ischemic stroke lesion segmentation from multi-modal mri. Sci- entific Data9, 762 (2022).https://doi.org/10.1038/s41597-022-01875-5
-
[11]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015),https://arxiv.org/abs/1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[12]
Nature methods18(2), 203–211 (2021)
Isensee, F., Jaeger, P.F., Kohl, S.A., Petersen, J., Maier-Hein, K.H.: nnu-net: a self-configuring method for deep learning-based biomedical image segmentation. Nature methods18(2), 203–211 (2021)
2021
-
[13]
arXiv preprint arXiv:2601.09191 (2026)
Lan, Q., Choi, A., Ma, J., Wang, B., Zhao, Z., Jiang, X., Hsu, Y.C.: From perfor- mance to practice: Knowledge-distilled segmentator for on-premises clinical work- flows. arXiv preprint arXiv:2601.09191 (2026)
-
[14]
Visual detector compression via location-aware discrimi- nant analysis
Lan, Q., Hsu, Y.C., Khan, N.S., Jiang, X.: Reco-kd: Region-and context-aware knowledge distillation for efficient 3d medical image segmentation. arXiv preprint arXiv:2601.08301 (2026)
-
[15]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Lan,Q.,Tian,Q.:Acam-kd:adaptiveandcooperativeattentionmaskingforknowl- edge distillation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3957–3966 (2025)
2025
-
[16]
IEEE transactions on pattern analysis and machine intelligence11(7), 674–693 (1989)
Mallat, S.G.: A theory for multiresolution signal decomposition: the wavelet repre- sentation. IEEE transactions on pattern analysis and machine intelligence11(7), 674–693 (1989)
1989
-
[17]
IEEE transactions on medical imaging 34(10), 1993–2024 (2014)
Menze, B.H., Jakab, A., Bauer, S., Kalpathy-Cramer, J., Farahani, K., Kirby, J., Burren, Y., Porz, N., Slotboom, J., Wiest, R., et al.: The multimodal brain tumor image segmentation benchmark (brats). IEEE transactions on medical imaging 34(10), 1993–2024 (2014)
1993
-
[18]
Radiology195(2), 297–315 (1995)
Mezrich, R.: A perspective on k-space. Radiology195(2), 297–315 (1995)
1995
-
[19]
Biomedical imaging and intervention journal4(1), e15 (2008)
Moratal, D., Vallés-Luch, A., Martí-Bonmatí, L., Brummer, M.E.: k-space tutorial: an mri educational tool for a better understanding of k-space. Biomedical imaging and intervention journal4(1), e15 (2008)
2008
-
[20]
In: International conference on machine learning
Rahaman, N., Baratin, A., Arpit, D., Draxler, F., Lin, M., Hamprecht, F., Ben- gio, Y., Courville, A.: On the spectral bias of neural networks. In: International conference on machine learning. pp. 5301–5310. PMLR (2019)
2019
-
[21]
In: International Conference on Learning Representations (ICLR) (2015)
Romero, A., Ballas, N., Kahou, S.E., Chassang, A., Gatta, C., Bengio, Y.: Fitnets: Hints for thin deep nets. In: International Conference on Learning Representations (ICLR) (2015)
2015
-
[22]
In: International Conference on Medical image computing and computer-assisted intervention
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedi- cal image segmentation. In: International Conference on Medical image computing and computer-assisted intervention. pp. 234–241. Springer (2015)
2015
-
[23]
Advances in neural information processing systems6(1993)
Ruderman, D., Bialek, W.: Statistics of natural images: Scaling in the woods. Advances in neural information processing systems6(1993)
1993
-
[24]
In: Proceedings of the IEEE/CVF international conference on computer vision
Shu, C., Liu, Y., Gao, J., Yan, Z., Shen, C.: Channel-wise knowledge distillation for dense prediction. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5311–5320 (2021)
2021
-
[25]
Proceed- ings of the IEEE84(4), 626–638 (1996).https://doi.org/10.1109/5.488704
Unser, M., Aldroubi, A.: A review of wavelets in biomedical applications. Proceed- ings of the IEEE84(4), 626–638 (1996).https://doi.org/10.1109/5.488704
-
[26]
arXiv preprint arXiv:2405.18368 (2024)
de Verdier, M.C., Saluja, R., Gagnon, L., LaBella, D., Baid, U., Tahon, N.H., Foltyn-Dumitru, M., Zhang, J., Alafif, M., Baig, S., et al.: The 2024 brain tumor Detail Consistent Stage-Wise Distillation for Efficient 3D MRI Segmentation 11 segmentation (brats) challenge: Glioma segmentation on post-treatment mri. arXiv preprint arXiv:2405.18368 (2024)
-
[27]
In: International Conference on Medical Imaging with Deep Learning
Wang, Y., Blackie, L., Miguel-Aliaga, I., Bai, W.: Memory-efficient segmentation of high-resolution volumetric microct images. In: International Conference on Medical Imaging with Deep Learning. pp. 1322–1335. PMLR (2022)
2022
-
[28]
In: European Conference on Computer Vision
Wang, Y., Zhou, W., Jiang, T., Bai, X., Xu, Y.: Intra-class feature variation distil- lation for semantic segmentation. In: European Conference on Computer Vision. pp. 346–362. Springer (2020)
2020
-
[29]
Frontiers in neuroinformatics13, 46 (2019)
Xu, Y., Raj, A., Victor, J.D.: Systematic differences between perceptually relevant image statistics of brain mri and natural images. Frontiers in neuroinformatics13, 46 (2019)
2019
-
[30]
Communications on Applied Mathematics and Computation7(3), 827– 864 (2025)
Xu, Z.Q.J., Zhang, Y., Luo, T.: Overview frequency principle/spectral bias in deep learning. Communications on Applied Mathematics and Computation7(3), 827– 864 (2025)
2025
-
[31]
Xu, Z.Q.J., Zhang, Y., Luo, T., Xiao, Y., Ma, Z.: Frequency principle: Fourier anal- ysis sheds light on deep neural networks. arXiv preprint arXiv:1901.06523 (2019)
-
[32]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, L., Chen, X., Tu, X., Wan, P., Xu, N., Ma, K.: Wavelet knowledge distillation: Towards efficient image-to-image translation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12464– 12474 (2022)
2022
-
[33]
In: International conference on machine learning
Zhang, R.: Making convolutional networks shift-invariant again. In: International conference on machine learning. pp. 7324–7334. PMLR (2019)
2019
-
[34]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition
Zhang, Y., Huang, T., Liu, J., Jiang, T., Cheng, K., Zhang, S.: Freekd: Knowledge distillation via semantic frequency prompt. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition. pp. 15931–15940 (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.