Characterization-Guided GPU Fault Resilience in NVIDIA MPS
Pith reviewed 2026-06-29 16:15 UTC · model grok-4.3
The pith
NVIDIA MPS fault resilience isolates dominant memory faults via open driver changes and recovers others with virtual memory state sharing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that a characterization of end-to-end GPU fault pipelines reveals memory faults as the dominant class isolatable by edits to the open driver kernel module, while remaining faults can be contained through virtual-memory-based GPU-resident state sharing, together enabling effective handling of faults in MPS with minimal overhead.
What carries the argument
Two complementary mechanisms: fault isolation for memory-related faults performed by software intervention in the open GPU driver kernel module, and fast recovery via virtual memory based GPU-resident state sharing for faults whose handling stays inside proprietary software.
If this is right
- Memory faults no longer propagate across MPS processes once the open-driver isolation is applied.
- Faults inside proprietary code can be recovered without full process restart by reusing shared virtual-memory state.
- The combined mechanisms maintain low overhead when evaluated on varied GPUs and workloads.
- MPS becomes usable in multi-tenant clusters that require fault containment.
Where Pith is reading between the lines
- The same characterization method could be repeated on future GPU generations to check whether memory faults remain the dominant isolatable class.
- If more of the driver stack becomes open, the isolation mechanism could be extended to additional fault categories.
- Virtual-memory state sharing might shorten recovery times in other GPU sharing schemes that lack MPS-style process separation.
- The approach could be tested on workloads with higher fault rates to quantify how overhead scales with fault frequency.
Load-bearing premise
The systematic fault characterization correctly identifies memory-related faults as dominant and reachable for isolation through changes inside the open driver kernel module.
What would settle it
A memory fault injected into one MPS process that still terminates co-running processes despite the driver isolation changes, or a measured recovery latency that exceeds the low-overhead bound reported for the tested workloads.
Figures

read the original abstract
NVIDIA Multi-Process Service (MPS) enables fine-grained GPU sharing by allowing multiple processes to execute concurrently on the same GPU, making it an important mechanism for improving GPU utilization. However, MPS has weak fault resilience: a fault in one process can terminate all co-running processes, limiting its adoption in resilience-critical settings such as multi-tenant GPU clusters. In this work, we design fault-resilient MPS to solve this problem. Our design is guided by insights from a systematic characterization of GPU faults and a deep analysis of their end-to-end processing pipeline. Based on these insights, we design two complementary mechanisms. A fault isolation mechanism for the dominant memory-related faults that can be fully isolated by software intervention in the open GPU driver kernel module. For other faults whose process is within proprietary software, we design a practical mechanism -- fast recovery using virtual memory based GPU-resident state sharing. Our evaluation on different GPUs and workloads shows that these mechanisms can handle corresponding faults effectively with minimal overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to improve fault resilience in NVIDIA Multi-Process Service (MPS) via a characterization-guided design. It identifies memory-related faults as dominant and proposes two mechanisms: (1) isolation of these faults through software changes exclusively in the open GPU driver kernel module, and (2) fast recovery for remaining faults via virtual-memory-based GPU-resident state sharing without proprietary access. Evaluation across GPUs and workloads is asserted to demonstrate effective fault handling with minimal overhead.
Significance. If the mechanisms are shown to work as described, the work would meaningfully advance practical GPU sharing in multi-tenant clusters by addressing MPS's current lack of fault isolation. The characterization-driven split between open-module and VM-sharing approaches, if substantiated, offers a pragmatic path that avoids full proprietary reverse-engineering.
major comments (2)
- [Abstract] Abstract: The central claim that dominant memory-related faults 'can be fully isolated by software intervention in the open GPU driver kernel module' is load-bearing for the first mechanism, yet the manuscript provides no explicit mapping or evidence that the relevant fault paths and isolation points reside exclusively (or even primarily) in the open driver portions rather than proprietary components. This assumption must be demonstrated with concrete pipeline analysis before the isolation claim can be accepted.
- [Abstract] Abstract (evaluation claim): The statement that the mechanisms 'handle corresponding faults effectively with minimal overhead' is the primary empirical support for the overall contribution, but the provided text contains no quantitative results, baselines, workload descriptions, or overhead measurements. Without these, the effectiveness and minimality assertions cannot be assessed.
minor comments (1)
- The abstract would be strengthened by including at least one key quantitative result (e.g., overhead percentage or fault-recovery latency) to allow readers to gauge the 'minimal overhead' claim immediately.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address the two major comments below by clarifying the supporting analysis from our characterization study and committing to targeted revisions that make the evidence more explicit without altering the core claims.
read point-by-point responses
-
Referee: The central claim that dominant memory-related faults 'can be fully isolated by software intervention in the open GPU driver kernel module' is load-bearing for the first mechanism, yet the manuscript provides no explicit mapping or evidence that the relevant fault paths and isolation points reside exclusively (or even primarily) in the open driver portions rather than proprietary components. This assumption must be demonstrated with concrete pipeline analysis before the isolation claim can be accepted.
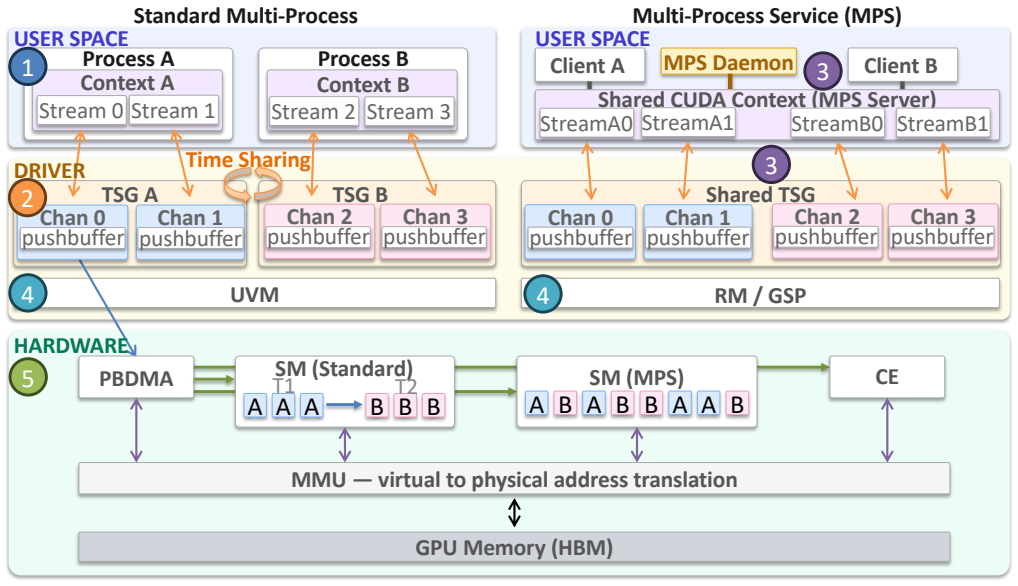
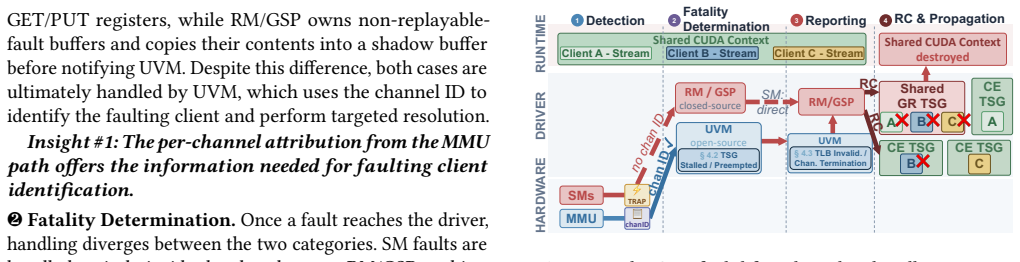
Authors: Our characterization (Section 3) performs an end-to-end pipeline analysis of fault handling in the NVIDIA driver stack, tracing memory faults to specific open-source paths in nvidia.ko (e.g., memory management and error reporting routines) that are independent of proprietary user-space components. This mapping underpins the isolation mechanism. To strengthen presentation, we will add an explicit pipeline diagram and table enumerating the open-driver intervention points in the revision. revision: yes
-
Referee: The statement that the mechanisms 'handle corresponding faults effectively with minimal overhead' is the primary empirical support for the overall contribution, but the provided text contains no quantitative results, baselines, workload descriptions, or overhead measurements. Without these, the effectiveness and minimality assertions cannot be assessed.
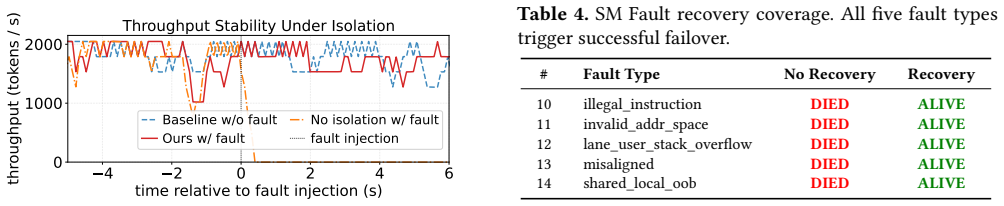
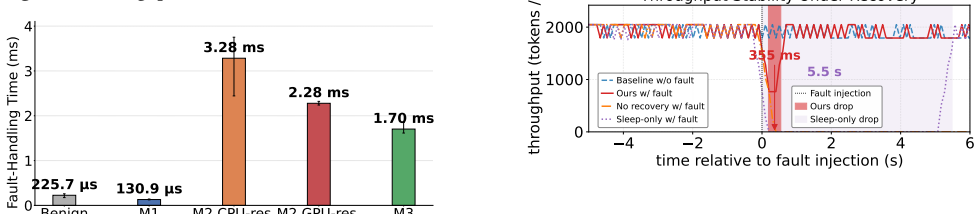
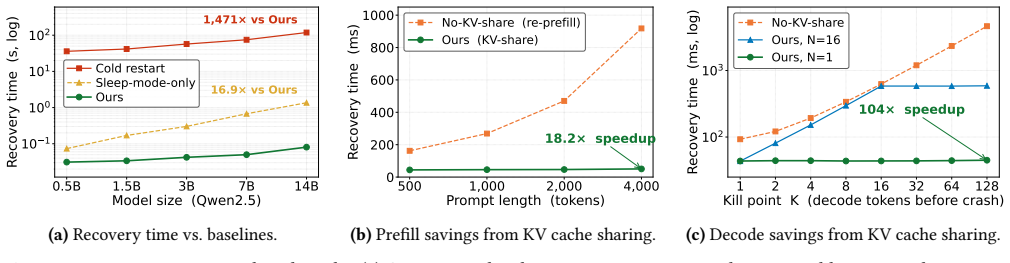
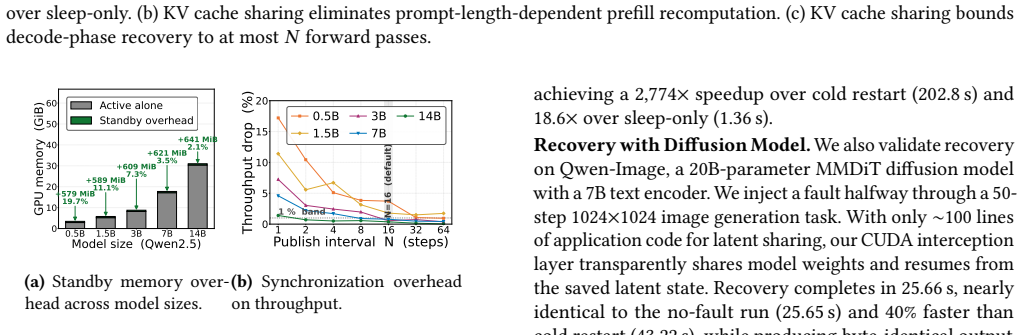
Authors: Sections 5 and 6 report the full quantitative evaluation: >95% fault coverage for memory faults via isolation, recovery latency reductions of 4-10x versus full GPU reset, and overheads of <3% (isolation) and <8% (recovery) versus vanilla MPS across Rodinia, MLPerf, and synthetic workloads on V100/A100 GPUs. We will revise the abstract to include 1-2 key metrics while preserving length constraints. revision: partial
Circularity Check
No circularity: empirical characterization directly informs design without self-referential reduction
full rationale
The paper's chain is characterization of GPU faults -> analysis of processing pipeline -> two mechanisms (open-module isolation for memory faults; VM sharing for others) -> evaluation on workloads. No equations, fitted parameters, predictions, or self-citations appear in the provided text. The design rests on external driver behavior and observed fault patterns rather than any input being redefined as output. The central claim does not reduce to its own assumptions by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multi-process service.https://docs.nvidia.com/ deploy/mps/index.html, 2025
NVIDIA Corporation. Multi-process service.https://docs.nvidia.com/ deploy/mps/index.html, 2025. Accessed: 2026-05-12
2025
-
[2]
Phi-3 technical report: A highly capable language model locally on your phone, 2024
Marah Abdin, Jyoti Aneja, et al. Phi-3 technical report: A highly capable language model locally on your phone, 2024
2024
-
[3]
MobileLLM-r1: Exploring the limits of sub-billion language model reasoners with open training recipes
Changsheng Zhao, Ernie Chang, Zechun Liu, Chia-Jung Chang, Wei Wen, Chen Lai, Sheng Cao, Yuandong Tian, Raghuraman Krishnamoor- thi, Yangyang Shi, and Vikas Chandra. MobileLLM-r1: Exploring the limits of sub-billion language model reasoners with open training recipes. InThe Fourteenth International Conference on Learning Repre- sentations, 2026
2026
-
[4]
Notebookos: A replicated notebook platform for inter- active training with on-demand gpus
Benjamin Carver, Jingyuan Zhang, Haoliang Wang, Kanak Mahadik, and Yue Cheng. Notebookos: A replicated notebook platform for inter- active training with on-demand gpus. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Lan- guages and Operating Systems, Volume 1, ASPLOS ’26, page 183–202, New York, NY, USA, 20...
2025
-
[5]
Analysis of Large-Scale Multi- Tenant GPU clusters for DNN training workloads
Myeongjae Jeon, Shivaram Venkataraman, Amar Phanishayee, Junjie Qian, Wencong Xiao, and Fan Yang. Analysis of Large-Scale Multi- Tenant GPU clusters for DNN training workloads. In2019 USENIX Annual Technical Conference (USENIX ATC 19), pages 947–960, Renton, WA, July 2019. USENIX Association
2019
-
[6]
AntMan: Dynamic scaling on GPU clusters for deep learning
Wencong Xiao, Shiru Ren, Yong Li, Yang Zhang, Pengyang Hou, Zhi Li, Yihui Feng, Wei Lin, and Yangqing Jia. AntMan: Dynamic scaling on GPU clusters for deep learning. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), pages 533–548. USENIX Association, November 2020
2020
-
[7]
MLaaS in the wild: Workload analysis and scheduling in large-scale heterogeneous GPU clusters
Qizhen Weng, Wencong Xiao, Yinghao Yu, Wei Wang, Cheng Wang, Jian He, Yong Li, Liping Zhang, Wei Lin, and Yu Ding. MLaaS in the wild: Workload analysis and scheduling in large-scale heterogeneous GPU clusters. In19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22), 2022
2022
-
[8]
Megatron-lm: Training multi- billion parameter language models using model parallelism, 2020
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi- billion parameter language models using model parallelism, 2020
2020
-
[9]
Multi-instance gpu user guide.https://docs
NVIDIA Corporation. Multi-instance gpu user guide.https://docs. nvidia.com/datacenter/tesla/mig-user-guide/latest/, 2025. Accessed: 2026-05-12
2025
-
[10]
Bamboo: Making preemptible instances resilient for affordable training of large DNNs
John Thorpe, Pengzhan Zhao, Jonathan Eyolfson, Yifan Qiao, Zhihao Jia, Minjia Zhang, Ravi Netravali, and Guoqing Harry Xu. Bamboo: Making preemptible instances resilient for affordable training of large DNNs. In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), pages 497–513, Boston, MA, April 2023. USENIX Association
2023
-
[11]
Oobleck: Resilient distributed training of large models using pipeline templates
Insu Jang, Zhenning Yang, Zhen Zhang, Xin Jin, and Mosharaf Chowd- hury. Oobleck: Resilient distributed training of large models using pipeline templates. InProceedings of the 29th Symposium on Operating Systems Principles, SOSP ’23, page 382–395, New York, NY, USA, 2023. Association for Computing Machinery
2023
-
[12]
Nvidia open gpu kernel modules.https://github
NVIDIA Corporation. Nvidia open gpu kernel modules.https://github. com/NVIDIA/open-gpu-kernel-modules, 2024. Accessed: 2026-03-23
2024
-
[13]
Kalbar- czyk, and Ravishankar K
Shengkun Cui, Archit Patke, Hung Nguyen, Aditya Ranjan, Ziheng Chen, Phuong Cao, Gregory Bauer, Brett Bode, Catello Di Martino, Saurabh Jha, Chandra Narayanaswami, Daby Sow, Zbigniew T. Kalbar- czyk, and Ravishankar K. Iyer. Story of two GPUs: Characterizing the resilience of hopper H100 and ampere A100 gpus. InProceedings of the International Conference ...
-
[14]
Association for Computing Machinery
-
[15]
Cuda programming guide: Virtual memory man- agement.https://docs.nvidia.com/cuda/cuda-programming-guide/04- special-topics/virtual-memory-management.html, 2023
NVIDIA Corporation. Cuda programming guide: Virtual memory man- agement.https://docs.nvidia.com/cuda/cuda-programming-guide/04- special-topics/virtual-memory-management.html, 2023. Accessed: 2026-03-23
2023
-
[16]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th Symposium on Operating 13 Systems Principles, SOSP ’23, page 611–626, New York, NY, USA, 2023. Association for Computing Machinery
2023
-
[17]
Denoising diffusion proba- bilistic models, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion proba- bilistic models, 2020
2020
-
[18]
Deep residual learning for image recognition, 2015
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition, 2015
2015
-
[19]
NVIDIA H100 Tensor Core GPU Architecture Whitepaper.https://resources.nvidia.com/en-us-hopper-architecture/ nvidia-h100-tensor-c, 2022
NVIDIA Corporation. NVIDIA H100 Tensor Core GPU Architecture Whitepaper.https://resources.nvidia.com/en-us-hopper-architecture/ nvidia-h100-tensor-c, 2022. Accessed: 2026-05-15
2022
-
[20]
NVIDIA Blackwell Architecture Technical Brief.https://resources.nvidia.com/en-us-blackwell-architecture/ blackwell-architecture-technical-brief, 2024
NVIDIA Corporation. NVIDIA Blackwell Architecture Technical Brief.https://resources.nvidia.com/en-us-blackwell-architecture/ blackwell-architecture-technical-brief, 2024. Accessed: 2026-05-15
2024
-
[21]
Qoserve: Breaking the silos of llm inference serving
Kanishk Goel, Jayashree Mohan, Nipun Kwatra, Ravi Shreyas Anupindi, and Ramachandran Ramjee. Qoserve: Breaking the silos of llm inference serving. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ASPLOS ’26, page 1492–1507, New York, NY, USA, 2026. Association for Co...
2026
-
[22]
GMI-DRL: Empowering Multi-GPU DRL with Adaptive-Grained parallelism
Yuke Wang, Boyuan Feng, Zheng Wang, Guyue Huang, Tong (Tony) Geng, Ang Li, and Yufei Ding. GMI-DRL: Empowering Multi-GPU DRL with Adaptive-Grained parallelism. In2025 USENIX Annual Technical Conference (USENIX ATC 25), pages 89–103, Boston, MA, July 2025. USENIX Association
2025
-
[23]
Taming the long-tail: Efficient reasoning rl training with adaptive drafter
Qinghao Hu, Shang Yang, Junxian Guo, Xiaozhe Yao, Yujun Lin, Yuxian Gu, Han Cai, Chuang Gan, Ana Klimovic, and Song Han. Taming the long-tail: Efficient reasoning rl training with adaptive drafter. In Proceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ASPLOS ’26, page 19...
1933
-
[24]
Muxflow: Efficient and safe gpu sharing in large-scale production deep learning clusters, 2023
Yihao Zhao, Xin Liu, Shufan Liu, Xiang Li, Yibo Zhu, Gang Huang, Xuanzhe Liu, and Xin Jin. Muxflow: Efficient and safe gpu sharing in large-scale production deep learning clusters, 2023
2023
-
[25]
Accessed: 2026-05-14
Nouveau: Accelerated open source driver for NVIDIA cards.https: //nouveau.freedesktop.org/. Accessed: 2026-05-14
2026
-
[26]
vLLM documentation: Sleep mode.https://docs.vllm.ai/ en/latest/features/sleep_mode/, 2024
vLLM Team. vLLM documentation: Sleep mode.https://docs.vllm.ai/ en/latest/features/sleep_mode/, 2024. Accessed: 2026-03-23
2024
-
[27]
ShareGPT: Share your wildest ChatGPT conversations with one click, 2023
2023
-
[28]
Anderson
Joshua Bakita and James H. Anderson. Hardware compute partitioning on nvidia gpus. In2023 IEEE 29th Real-Time and Embedded Technology and Applications Symposium (RTAS), pages 54–66, 2023
2023
-
[29]
Multi-process service: Static SM partition- ing.https://docs.nvidia.com/deploy/mps/when-to-use-mps.html# static-sm-partitioning, 2025
NVIDIA Corporation. Multi-process service: Static SM partition- ing.https://docs.nvidia.com/deploy/mps/when-to-use-mps.html# static-sm-partitioning, 2025. Accessed: 2026-05-12
2025
-
[30]
Trans- parent GPU sharing in container clouds for deep learning workloads
Bingyang Wu, Zili Zhang, Zhihao Bai, Xuanzhe Liu, and Xin Jin. Trans- parent GPU sharing in container clouds for deep learning workloads. In20th USENIX Symposium on Networked Systems Design and Imple- mentation (NSDI 23), pages 69–85, Boston, MA, April 2023. USENIX Association
2023
-
[31]
Orion: Interference- aware, fine-grained gpu sharing for ml applications
Foteini Strati, Xianzhe Ma, and Ana Klimovic. Orion: Interference- aware, fine-grained gpu sharing for ml applications. InProceedings of the Nineteenth European Conference on Computer Systems, EuroSys ’24, page 1075–1092, New York, NY, USA, 2024. Association for Computing Machinery
2024
-
[32]
Gaiagpu: Sharing gpus in container clouds
Jing Gu, Shengbo Song, Ying Li, and Hanmei Luo. Gaiagpu: Sharing gpus in container clouds. In2018 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Ubiquitous Computing & Communications, Big Data & Cloud Computing, Social Computing & Networking, Sustain- able Computing & Communications (ISPA/IUCC/BDCloud/SocialCom/- SustainCom), pages...
2018
-
[33]
Efficient performance-aware gpu sharing with compatibility and isolation through kernel space interception
Shulai Zhang, Ao Xu, Quan Chen, Han Zhao, Weihao Cui, Zhen Wang, Yan Li, Limin Xiao, and Minyi Guo. Efficient performance-aware gpu sharing with compatibility and isolation through kernel space interception. InProceedings of the 2025 USENIX Conference on Usenix Annual Technical Conference, USENIX ATC ’25, USA, 2025. USENIX Association
2025
-
[34]
Coppock, Brian Zhang, Eliot H
Patrick H. Coppock, Brian Zhang, Eliot H. Solomon, Vasilis Kypriotis, Leon Yang, Bikash Sharma, Dan Schatzberg, Todd C. Mowry, and Dimitrios Skarlatos. Lithos: An operating system for efficient machine learning on gpus. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, SOSP ’25, page 1–17, New York, NY, USA, 2025. Association...
2025
-
[35]
Serving heterogeneous machine learning models on Multi-GPU servers with Spatio-Temporal sharing
Seungbeom Choi, Sunho Lee, Yeonjae Kim, Jongse Park, Youngjin Kwon, and Jaehyuk Huh. Serving heterogeneous machine learning models on Multi-GPU servers with Spatio-Temporal sharing. In2022 USENIX Annual Technical Conference (USENIX ATC 22), pages 199–216, Carlsbad, CA, July 2022. USENIX Association
2022
-
[36]
Aditya Dhakal, Sameer G Kulkarni, and K. K. Ramakrishnan. Gslice: controlled spatial sharing of gpus for a scalable inference platform. In Proceedings of the 11th ACM Symposium on Cloud Computing, SoCC ’20, page 492–506, New York, NY, USA, 2020. Association for Computing Machinery
2020
-
[37]
Check- Freq: Frequent, Fine-Grained DNN checkpointing
Jayashree Mohan, Amar Phanishayee, and Vijay Chidambaram. Check- Freq: Frequent, Fine-Grained DNN checkpointing. In19th USENIX Conference on File and Storage Technologies (FAST 21), pages 203–216. USENIX Association, February 2021
2021
-
[38]
Zhuang Wang, Zhen Jia, Shuai Zheng, Zhen Zhang, Xinwei Fu, T. S. Eu- gene Ng, and Yida Wang. Gemini: Fast failure recovery in distributed training with in-memory checkpoints. InProceedings of the 29th Sym- posium on Operating Systems Principles, SOSP ’23, page 364–381, New York, NY, USA, 2023. Association for Computing Machinery
2023
-
[39]
Crac: checkpoint-restart architec- ture for cuda with streams and uvm
Twinkle Jain and Gene Cooperman. Crac: checkpoint-restart architec- ture for cuda with streams and uvm. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’20. IEEE Press, 2020
2020
-
[40]
Unicron: Economizing self-healing LLM training at scale, 2023
Tao He, Xue Li, Zhibin Wang, Kun Qian, Jingbo Xu, Wenyuan Yu, and Jingren Zhou. Unicron: Economizing self-healing LLM training at scale, 2023
2023
-
[41]
Songyu Zhang, Aaron Tam, Myungjin Lee, Shixiong Qi, and K. K. Ramakrishnan. Making MoE-based LLM inference resilient with Tar- ragon, 2026
2026
-
[42]
Shangshu Qian, Kipling Liu, P. C. Sruthi, Lin Tan, and Yongle Zhang. Towards resiliency in large language model serving with KevlarFlow, 2026. 14 A Implementation We implement our fault isolation mechanism by modifying NVIDIA’s open-source UVM kernel module with∼500 lines of C code. Our fast recovery mechanism consists of ∼500 lines of C for the build-tim...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.