TrackRef3D: Multi-View Consistent Track-then-Label for Open-World Referring Segmentation in 3D Gaussian Splatting
Pith reviewed 2026-06-29 18:37 UTC · model grok-4.3
The pith
TrackRef3D achieves open-world referring segmentation in 3D Gaussian Splatting without manual annotation by decoupling object discovery from semantic grounding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
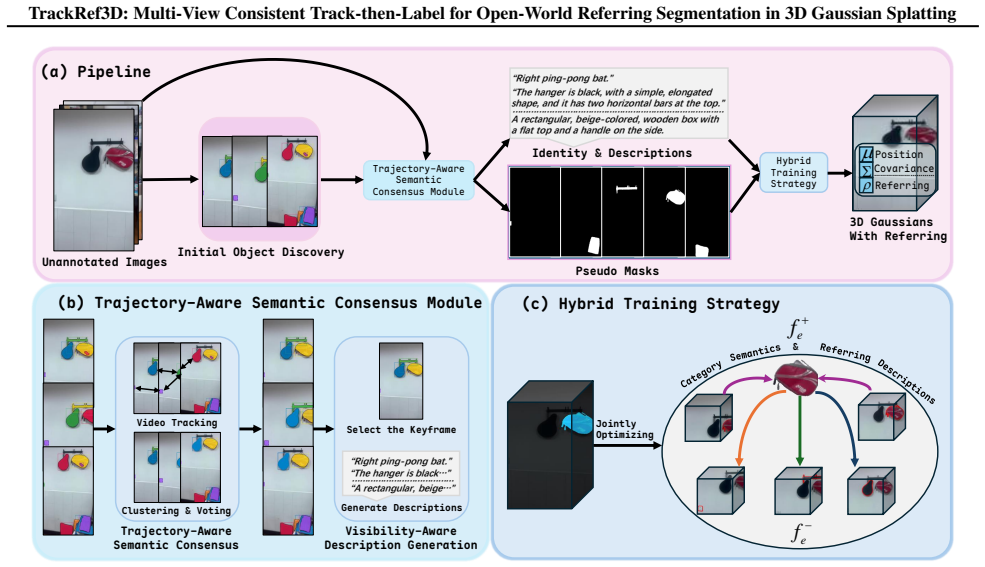
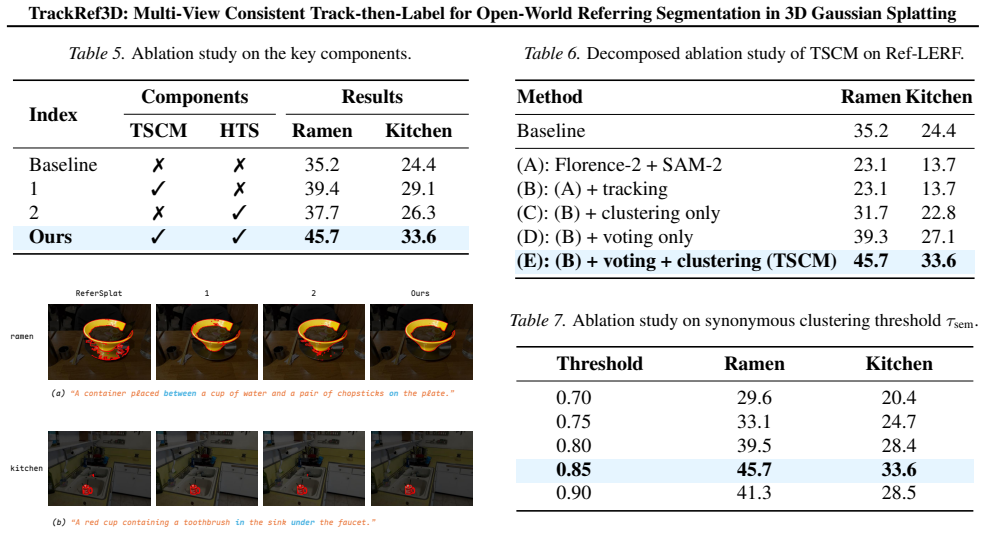
TrackRef3D presents a fully automatic pipeline that achieves open-world referring segmentation in 3D Gaussian Splatting without manual annotation by introducing a multi-view consistent track-then-label paradigm that fundamentally decouples object discovery from semantic grounding, with the Trajectory-Aware Semantic Consensus Module aggregating cross-view predictions via synonymous clustering and trajectory-aware voting and a Hybrid Training Strategy optimizing coarse and fine-grained cues.
What carries the argument
The track-then-label paradigm with the Trajectory-Aware Semantic Consensus Module (TSCM), which aggregates cross-view predictions via synonymous clustering and trajectory-aware voting to establish a canonical semantic identity.
Load-bearing premise
The Trajectory-Aware Semantic Consensus Module can reliably aggregate cross-view predictions via synonymous clustering and trajectory-aware voting to establish a canonical semantic identity that remains correct under varying query specificities and view inconsistencies.
What would settle it
A scene and set of queries where the module assigns inconsistent semantic identities to the same tracked object across rephrased natural language inputs or additional viewpoints.
Figures



read the original abstract
Referring 3D Gaussian Splatting (R3DGS), which utilizes natural language for 3D object segmentation, has emerged as a crucial capability for embodied AI. However, existing methods typically rely on expensive per-scene manual annotation and per-view pseudo mask generation, which suffer from multi-view inconsistency and poor generalization to varying query specificities. To address this, we present TrackRef3D, a fully automatic pipeline that achieves open-world referring segmentation in 3D Gaussian Splatting (3DGS) without manual annotation by introducing a multi-view consistent track-then-label paradigm that fundamentally decouples object discovery from semantic grounding. Specifically, we propose a Trajectory-Aware Semantic Consensus Module (TSCM) which aggregates cross-view predictions via synonymous clustering and trajectory-aware voting to establish a canonical semantic identity, thereby ensuring multi-view consistency. Furthermore, we employ a visibility-aware description generation strategy to mitigate ambiguity and propose a Hybrid Training Strategy (HTS) that jointly optimizes coarse category semantics and fine-grained referential cues to ensure robustness under varying query specificities using a multi-positive contrastive objective. Extensive experiments on benchmarks demonstrate that TrackRef3D achieves state-of-the-art performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents TrackRef3D, a fully automatic pipeline for open-world referring segmentation in 3D Gaussian Splatting. It introduces a multi-view consistent track-then-label paradigm that decouples object discovery from semantic grounding, along with the Trajectory-Aware Semantic Consensus Module (TSCM) that uses synonymous clustering and trajectory-aware voting, a visibility-aware description generation strategy, and a Hybrid Training Strategy (HTS) that jointly optimizes coarse category semantics and fine-grained referential cues via a multi-positive contrastive objective. The work claims state-of-the-art performance on benchmarks without requiring manual per-scene annotation.
Significance. If the central claims hold under detailed scrutiny of the methods and results, the work would represent a meaningful contribution to referring 3DGS and embodied AI by removing reliance on expensive manual annotations and addressing multi-view inconsistency and query-specificity generalization. The explicit decoupling of discovery from grounding via tracking is a conceptually clean framing that could influence subsequent pipelines.
minor comments (2)
- [Abstract] Abstract: the claim of 'state-of-the-art performance' and 'extensive experiments on benchmarks' is stated without naming the datasets, metrics, baselines, or quantitative margins, which prevents verification of the performance assertions.
- [Abstract] Abstract: the description of the Hybrid Training Strategy mentions a 'multi-positive contrastive objective' but provides no equation, loss formulation, or positive/negative sampling details, leaving the training procedure opaque.
Simulated Author's Rebuttal
We thank the referee for their summary of TrackRef3D and for recognizing the potential contribution of the track-then-label paradigm, TSCM, visibility-aware descriptions, and HTS in enabling fully automatic open-world referring segmentation in 3DGS. We are prepared to address any specific concerns that would resolve the current uncertainty in the recommendation.
Circularity Check
No significant circularity detected
full rationale
The abstract presents a methodological pipeline (TrackRef3D with TSCM for cross-view aggregation via clustering/voting and HTS for joint optimization) as a contribution without any equations, fitted parameters, self-citations, or derivation steps that reduce outputs to inputs by construction. No load-bearing claims are shown to be equivalent to their own definitions or prior self-references. The decoupling of discovery from grounding is described at the level of paradigm and modules, remaining self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chiou, Y .-J., Cheng, W.-T., and Yang, Y .-F. Profuse: Effi- cient cross-view context fusion for open-vocabulary 3d gaussian splatting.arXiv preprint arXiv:2601.04754,
-
[2]
Bert: Pre-training of deep bidirectional transformers for lan- guage understanding
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: Pre-training of deep bidirectional transformers for lan- guage understanding. InProceedings of the 2019 confer- ence of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186,
2019
-
[3]
CogVLM2: Visual Language Models for Image and Video Understanding
Hong, W., Wang, W., Ding, M., Yu, W., Lv, Q., Wang, Y ., Cheng, Y ., Huang, S., Ji, J., Xue, Z., et al. Cogvlm2: Vi- sual language models for image and video understanding. arXiv preprint arXiv:2408.16500,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Liang, S., Wang, S., Li, K., Niemeyer, M., Gasperini, S., Lensch, H., Navab, N., and Tombari, F. Supergseg: Open-vocabulary 3d segmentation with structured super- gaussians.arXiv preprint arXiv:2412.10231,
-
[5]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V ., Hu, Y .-T., Hu, R., Ryali, C., Ma, T., Khedr, H., R ¨adle, R., Rolland, C., Gustafson, L., Mintun, E., Pan, J., Alwala, K. V ., Carion, N., Wu, C.-Y ., Girshick, R., Doll ´ar, P., and Feichtenhofer, C. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
and Gurevych, I
Reimers, N. and Gurevych, I. Making monolingual sentence embeddings multilingual using knowledge distillation. In Proceedings of the 2020 Conference on Empirical Meth- ods in Natural Language Processing (EMNLP). Associa- tion for Computational Linguistics,
2020
-
[7]
Ren, T., Jiang, Q., Liu, S., Zeng, Z., Liu, W., Gao, H., Huang, H., Ma, Z., Jiang, X., Chen, Y ., et al. Grounding dino 1.5: Advance the” edge” of open-set object detection. arXiv preprint arXiv:2405.10300, 2024a. Ren, T., Liu, S., Zeng, A., Lin, J., Li, K., Cao, H., Chen, J., Huang, X., Chen, Y ., Yan, F., et al. Grounded sam: Assembling open-world model...
-
[8]
Wang, S., Li, K., Liang, S., Alegret, E., Ma, J., Navab, N., and Gasperini, S. Visibility-aware language aggre- gation for open-vocabulary segmentation in 3d gaussian splatting.arXiv preprint arXiv:2509.05515,
-
[9]
Hierarchical open-vocabulary 3d scene graphs for language-grounded robot navigation
Werby, A., Huang, C., B¨uchner, M., Valada, A., and Bur- gard, W. Hierarchical open-vocabulary 3d scene graphs for language-grounded robot navigation. InFirst Work- shop on Vision-Language Models for Navigation and Manipulation at ICRA 2024,
2024
-
[10]
Wu, C., Ji, J., Wang, H., Ma, Y ., Huang, Y ., Luo, G., Fei, H., Sun, X., Ji, R., et al. Rg-san: Rule-guided spatial awareness network for end-to-end 3d referring expression segmentation.Advances in Neural Information Process- ing Systems, 37:110972–110999, 2024a. Wu, C., Liu, Y ., Ji, J., Ma, Y ., Wang, H., Luo, G., Ding, H., Sun, X., and Ji, R. 3d-gres:...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.