On the Error-Correcting Effects of Stochasticity in Discrete Diffusion
Pith reviewed 2026-06-29 19:57 UTC · model grok-4.3
The pith
Redundant transitions in discrete diffusion correct sampling errors by symmetrically exchanging mass between states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
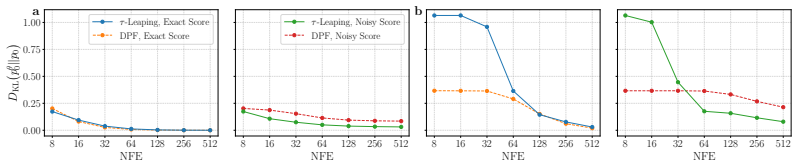
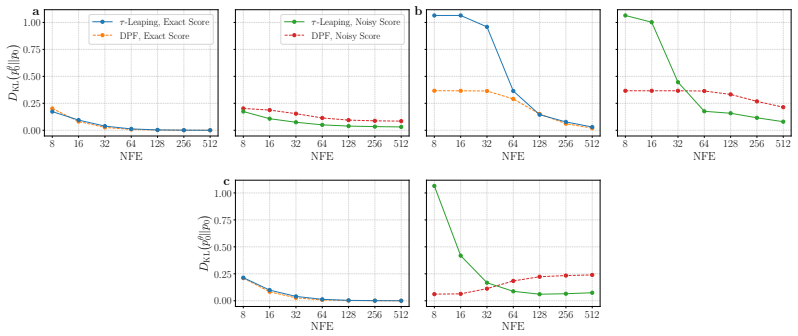
Using an information-theoretic analysis, we identify the underlying mechanism as an error-correcting effect induced by redundant transitions that symmetrically exchange mass between states, and show that these transitions can provably contract sampling errors. Motivated by this analysis, we propose Discrete Churn and Restart Sampling (DCRS), a novel inference algorithm that injects controlled stochasticity by alternating between forward and reverse diffusion processes.
What carries the argument
Redundant transitions that symmetrically exchange mass between states in the Markov chain and provably contract sampling errors.
If this is right
- Highly deterministic transitions converge rapidly but suffer from error accumulation.
- More stochastic transitions converge more slowly yet achieve higher final sample quality.
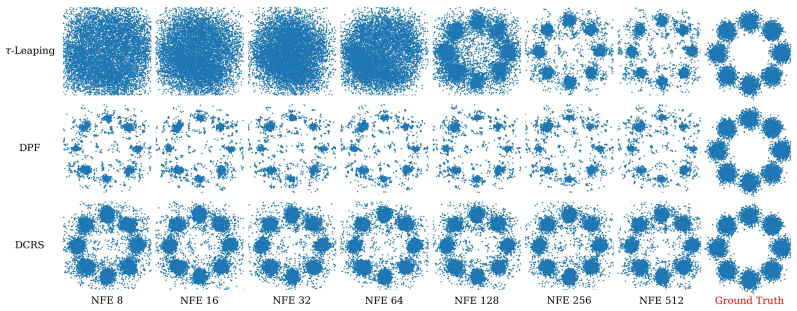
- DCRS improves the speed-quality tradeoff in the low number of function evaluations regime.
- On image datasets DCRS achieves up to a 10x reduction in sampling steps while maintaining competitive sample quality.
Where Pith is reading between the lines
- The contraction mechanism could be tested by constructing transition matrices that explicitly maximize symmetric mass exchange and measuring error reduction rates.
- Similar redundant exchange components might be engineered into other discrete generative processes to reduce error accumulation without increasing step count.
- The analysis suggests that sampling procedures could be designed around information contraction bounds rather than solely around convergence speed.
Load-bearing premise
The Markov transitions in discrete diffusion include redundant components capable of symmetrically exchanging mass between states in a manner that contracts sampling errors.
What would settle it
A calculation or experiment that measures whether sampling errors contract under transitions with redundant symmetric mass exchange and expand when those components are removed would directly test the claim.
Figures



read the original abstract
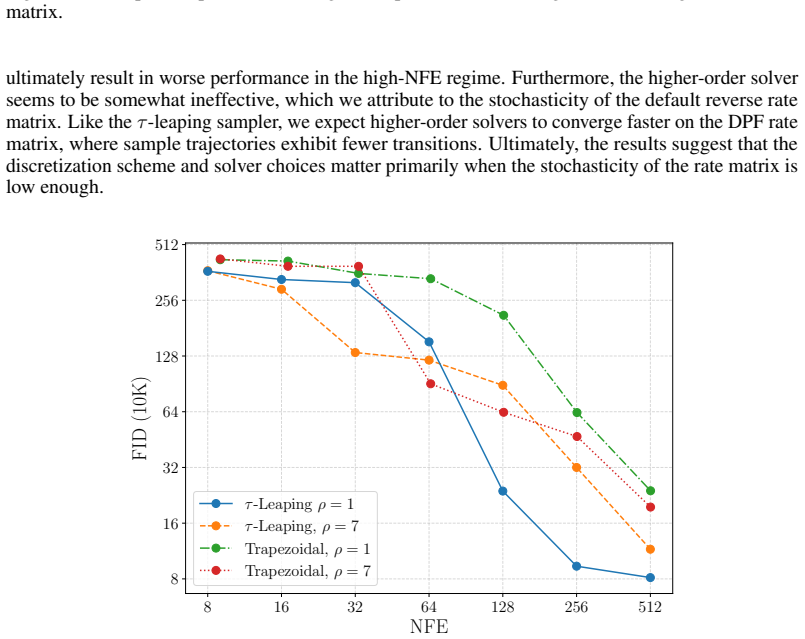
Discrete diffusion models achieve strong performance in text and image generation, but their inference remains slow and must inherently balance sampling efficiency and sample quality. In this work, we present a systematic study of how the \emph{degree of stochasticity} in Markov transitions governs the sampling tradeoff. We show that highly deterministic transitions converge rapidly but suffer from error accumulation, while more stochastic transitions converge more slowly yet can achieve higher final sample quality. Using an information-theoretic analysis, we identify the underlying mechanism as an error-correcting effect induced by \emph{redundant transitions} that symmetrically exchange mass between states, and show that these transitions can provably contract sampling errors. Motivated by this analysis, we propose \emph{Discrete Churn and Restart Sampling} (DCRS), a novel inference algorithm that injects controlled stochasticity by alternating between forward and reverse diffusion processes. Experiments on synthetic datasets and large-scale benchmarks show that DCRS improves the speed-quality tradeoff in the low number of function evaluations regime. On image datasets, DCRS achieves up to a $10\times$ reduction in sampling steps compared to standard samplers while maintaining competitive sample quality, whereas on language benchmarks, we observe more nuanced behavior depending on the corruption process and sampling procedure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the degree of stochasticity in the Markov transitions of discrete diffusion models controls a fundamental speed-quality tradeoff during sampling: highly deterministic transitions converge quickly but accumulate errors, while more stochastic ones converge slowly but achieve higher final quality. Using an information-theoretic analysis, the authors identify the mechanism as an error-correcting effect arising from redundant transitions that symmetrically exchange probability mass between states; they prove that such transitions contract sampling errors. Motivated by the analysis, they introduce Discrete Churn and Restart Sampling (DCRS), which injects controlled stochasticity by alternating forward and reverse diffusion steps. Experiments on synthetic data and large-scale image and language benchmarks show that DCRS improves the tradeoff in the low-NFE regime, including up to a 10× reduction in sampling steps on images while preserving competitive quality.
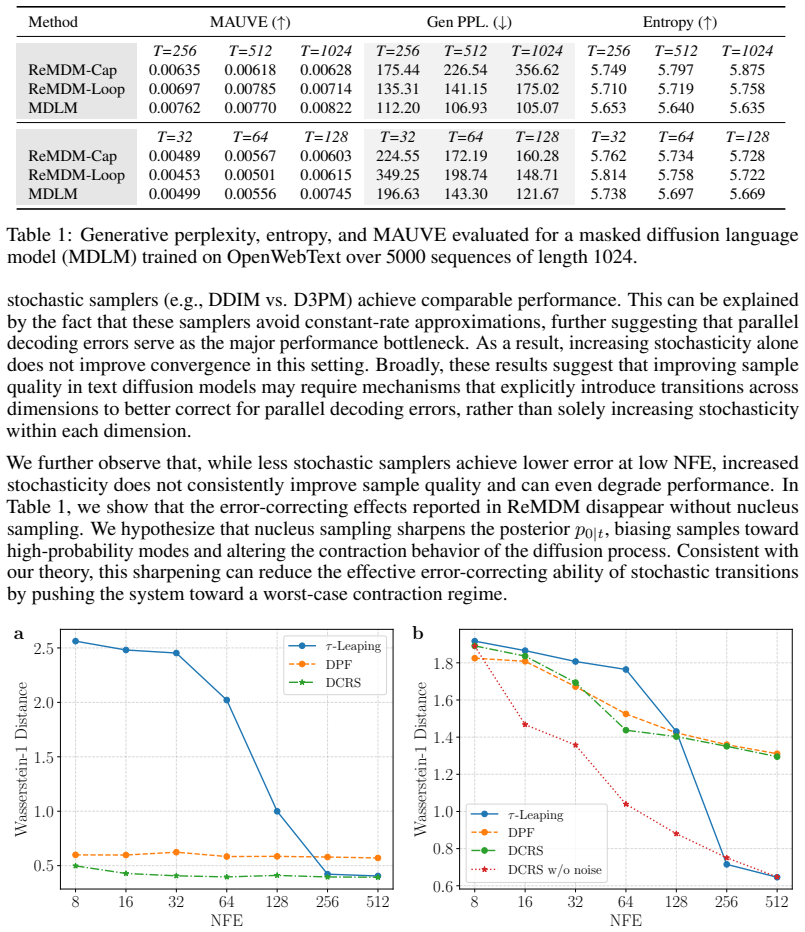
Significance. If the contraction result holds for the transition kernels actually used in discrete diffusion, the work supplies a principled, information-theoretic explanation for why stochasticity can be beneficial and yields a practical sampling algorithm with measurable efficiency gains. The empirical improvements on image benchmarks are substantial enough to be of interest to practitioners, and the framing around redundant symmetric transitions could guide future kernel design. The absence of free parameters in the core mechanism and the attempt at a provable statement are positive features.
major comments (2)
- The central information-theoretic argument (abstract and theoretical analysis) asserts that redundant transitions with symmetric mass exchange provably contract sampling errors. However, the manuscript does not derive or verify that the concrete kernels employed in standard discrete diffusion (multinomial or absorbing transitions with a fixed corruption schedule) satisfy the required pairwise symmetry between forward and reverse probabilities. Without this step the contraction does not automatically transfer to the models used in the DCRS experiments, which is load-bearing for both the theoretical claim and the motivation for the proposed algorithm.
- The abstract states that the analysis yields a 'provable contraction,' yet the provided manuscript text supplies no derivation details, explicit symmetry conditions on the transition matrix, or verification that the kernels satisfy them. This omission prevents assessment of whether the result is internal to the paper's assumptions or extends to the experimental setting.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed report. The two major comments both highlight the need for explicit derivation of the contraction result and verification that the symmetry conditions hold for the concrete transition kernels used in standard discrete diffusion models and in our DCRS experiments. We agree that these elements are necessary for the theoretical claims to be fully assessed and for the motivation of the algorithm to be clear. We will revise the manuscript to address both points.
read point-by-point responses
-
Referee: The central information-theoretic argument (abstract and theoretical analysis) asserts that redundant transitions with symmetric mass exchange provably contract sampling errors. However, the manuscript does not derive or verify that the concrete kernels employed in standard discrete diffusion (multinomial or absorbing transitions with a fixed corruption schedule) satisfy the required pairwise symmetry between forward and reverse probabilities. Without this step the contraction does not automatically transfer to the models used in the DCRS experiments, which is load-bearing for both the theoretical claim and the motivation for the proposed algorithm.
Authors: We agree that the manuscript must explicitly connect the general contraction result to the specific kernels. In the revision we will add a new subsection in the theoretical analysis that (i) states the precise pairwise symmetry condition on the forward and reverse transition matrices, (ii) derives the contraction of sampling error under this condition, and (iii) verifies that both the multinomial transition and the absorbing-state transition (with the standard linear or cosine corruption schedules) satisfy the required symmetry. This verification will be performed analytically for the kernels and will directly support the applicability of the contraction result to the DCRS experiments. revision: yes
-
Referee: The abstract states that the analysis yields a 'provable contraction,' yet the provided manuscript text supplies no derivation details, explicit symmetry conditions on the transition matrix, or verification that the kernels satisfy them. This omission prevents assessment of whether the result is internal to the paper's assumptions or extends to the experimental setting.
Authors: We acknowledge that the current version lacks the requested derivation details and kernel-specific verification. The revised manuscript will expand the theoretical section to include the full derivation of the contraction, the explicit symmetry conditions on the transition matrix, and the verification step for the multinomial and absorbing kernels. These additions will make it possible for readers to evaluate whether the provable contraction extends to the experimental setting. revision: yes
Circularity Check
No circularity: information-theoretic contraction result derived from standard Markov properties without reduction to inputs or self-citations.
full rationale
The paper's central derivation uses an information-theoretic analysis of redundant symmetric transitions in Markov chains to show error contraction. This step is presented as following from general properties of transition matrices and does not reduce by construction to fitted parameters, self-definitions, or load-bearing self-citations from the authors' prior work. No equations or claims in the abstract or described chain equate a prediction to its own input via renaming or ansatz smuggling. The result is therefore self-contained against external benchmarks of Markov information theory.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Discrete diffusion sampling can be modeled as Markov chains whose transitions admit a decomposition into deterministic and stochastic components with symmetric redundant mass exchanges.
Reference graph
Works this paper leans on
-
[1]
Argmax flows and multinomial diffusion: Learning categorical distributions
Emiel Hoogeboom, Didrik Nielsen, Priyank Jaini, Patrick Forré, and Max Welling. Argmax flows and multinomial diffusion: Learning categorical distributions. InAdvances in Neural Information Processing Systems, 2021
2021
-
[2]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Struc- tured denoising diffusion models in discrete state-spaces. InAdvances in Neural Information Processing Systems, 2021
2021
-
[3]
A continuous time framework for discrete denoising models
Andrew Campbell, Joe Benton, Valentin De Bortoli, Tom Rainforth, George Deligiannidis, and Arnaud Doucet. A continuous time framework for discrete denoising models. InAdvances in Neural Information Processing Systems, 2022
2022
-
[4]
Discrete diffusion modeling by estimating the ratios of the data distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution. InForty-first International Conference on Machine Learning, 2024
2024
-
[5]
Simple and effective masked diffusion language models
Subham Sekhar Sahoo et al. Simple and effective masked diffusion language models. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[6]
Vector quantized diffusion model for text-to-image synthesis
Shuyang Gu et al. Vector quantized diffusion model for text-to-image synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10696–10706, June 2022
2022
-
[7]
Simplified and generalized masked diffusion for discrete data
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis Titsias. Simplified and generalized masked diffusion for discrete data. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[8]
Why masking diffusion works: Condition on the jump schedule for improved discrete diffusion
Alan Nawzad Amin, Nate Gruver, and Andrew Gordon Wilson. Why masking diffusion works: Condition on the jump schedule for improved discrete diffusion. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[9]
Pan, Hyeji Kim, Sham Kakade, and Sitan Chen
Jaeyeon Kim, Seunggeun Kim, Taekyun Lee, David Z. Pan, Hyeji Kim, Sham Kakade, and Sitan Chen. Fine-tuning masked diffusion for provable self-correction, 2025
2025
-
[10]
Simple guidance mechanisms for discrete diffusion models
Yair Schiff et al. Simple guidance mechanisms for discrete diffusion models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[11]
The diffusion duality
Subham Sekhar Sahoo, Justin Deschenaux, Aaron Gokaslan, Guanghan Wang, Justin T Chiu, and V olodymyr Kuleshov. The diffusion duality. InForty-second International Conference on Machine Learning, 2025
2025
-
[12]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021
2021
-
[13]
Remasking discrete diffusion models with inference-time scaling
Guanghan Wang, Yair Schiff, Subham Sahoo, and V olodymyr Kuleshov. Remasking discrete diffusion models with inference-time scaling. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[14]
Formulating discrete probability flow through optimal transport
Pengze Zhang, Hubery Yin, Chen Li, and Xiaohua Xie. Formulating discrete probability flow through optimal transport. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[15]
Jaakkola
Andrew Campbell, Jason Yim, Regina Barzilay, Tom Rainforth, and Tommi S. Jaakkola. Generative flows on discrete state-spaces: Enabling multimodal flows with applications to protein co-design. InThe Forty-First International Conference on Machine Learning, 2024
2024
-
[16]
Discrete flow matching
Itai Gat et al. Discrete flow matching. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[17]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021. 10
2021
-
[18]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. InAdvances in Neural Information Processing Systems, 2022
2022
-
[19]
Exploring the optimal choice for generative processes in diffusion models: Ordinary vs stochastic differential equations
Yu Cao, Jingrun Chen, Yixin Luo, and Xiang Zhou. Exploring the optimal choice for generative processes in diffusion models: Ordinary vs stochastic differential equations. InAdvances in Neural Information Processing Systems, volume 36, pages 33420–33468. Curran Associates, Inc., 2023
2023
-
[20]
The probability flow ODE is provably fast
Sitan Chen, Sinho Chewi, Holden Lee, Yuanzhi Li, Jianfeng Lu, and Adil Salim. The probability flow ODE is provably fast. InAdvances in Neural Information Processing Systems, volume 36, pages 68552–68575. Curran Associates, Inc., 2023
2023
-
[21]
Markov chains
J R Norris. Markov chains. InMarkov Chains. Cambridge University Press, Cambridge, February 1997
1997
-
[22]
Concrete score matching: Generalized score matching for discrete data
Chenlin Meng, Kristy Choi, Jiaming Song, and Stefano Ermon. Concrete score matching: Generalized score matching for discrete data. InAdvances in Neural Information Processing Systems, 2025
2025
-
[23]
Rotskoff, and Lexing Ying
Yinuo Ren, Haoxuan Chen, Grant M. Rotskoff, and Lexing Ying. How discrete and continuous diffusion meet: Comprehensive analysis of discrete diffusion models via a stochastic integral framework. InNeurIPS 2024 Workshop on Mathematics of Modern Machine Learning, 2024
2024
-
[24]
Strong data-processing inequalities for channels and Bayesian networks
Y . Polyanskiy and Y . Wu. Strong data-processing inequalities for channels and bayesian networks.arXiv preprint arXiv:1508.06025, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[25]
Strong data processing inequalities and $\Phi$-Sobolev inequalities for discrete channels
M. Raginsky. Strong data processing inequalities and-sobolev inequalities for discrete channels. arXiv preprint arXiv:1411.3575, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[26]
Fast solvers for discrete diffusion models: Theory and applications of high- order algorithms
Yinuo Ren et al. Fast solvers for discrete diffusion models: Theory and applications of high- order algorithms. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[27]
Score-based continuous-time discrete diffusion models
Haoran Sun, Lijun Yu, Bo Dai, Dale Schuurmans, and Hanjun Dai. Score-based continuous-time discrete diffusion models. InThe Eleventh International Conference on Learning Representa- tions, 2023
2023
-
[28]
Distillation of discrete diffusion through dimensional correlations
Satoshi Hayakawa, Yuhta Takida, Masaaki Imaizumi, Hiromi Wakaki, and Yuki Mitsufuji. Distillation of discrete diffusion through dimensional correlations. InForty-second International Conference on Machine Learning, 2025
2025
-
[29]
Beyond autoregression: Fast LLMs via self-distillation through time
Justin Deschenaux and Caglar Gulcehre. Beyond autoregression: Fast LLMs via self-distillation through time. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[30]
Informed correctors for discrete diffusion models
Yixiu Zhao, Jiaxin Shi, Feng Chen, Shaul Druckmann, Lester Mackey, and Scott Linderman. Informed correctors for discrete diffusion models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[31]
Jaakkola
Yilun Xu, Mingyang Deng, Xiang Cheng, Yonglong Tian, Ziming Liu, and Tommi S. Jaakkola. Restart sampling for improving generative processes. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[32]
Generalized interpolating discrete diffusion
Dimitri von Rütte, Janis Fluri, Yuhui Ding, Antonio Orvieto, Bernhard Schölkopf, and Thomas Hofmann. Generalized interpolating discrete diffusion. InForty-second International Confer- ence on Machine Learning, 2025
2025
-
[33]
Flow matching with general discrete paths: A kinetic-optimal perspective
Neta Shaul et al. Flow matching with general discrete paths: A kinetic-optimal perspective. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[34]
Cambridge University Press, 2025
Yury Polyanskiy and Yihong Wu.Information Theory: From Coding to Learning. Cambridge University Press, 2025
2025
-
[35]
Y . Gu and Y . Polyanskiy. Non-linear log-sobolev inequalities for the potts semigroup and applications to reconstruction problems.Communications in Mathematical Physics, 404(2): 769–831, December 2023. doi: 10.1007/s00220-023-04785-3. 11 A CTMC Background A.1 CTMC Simulation Details Given Rt, one can approximate the forward process of the CTMC by discret...
-
[36]
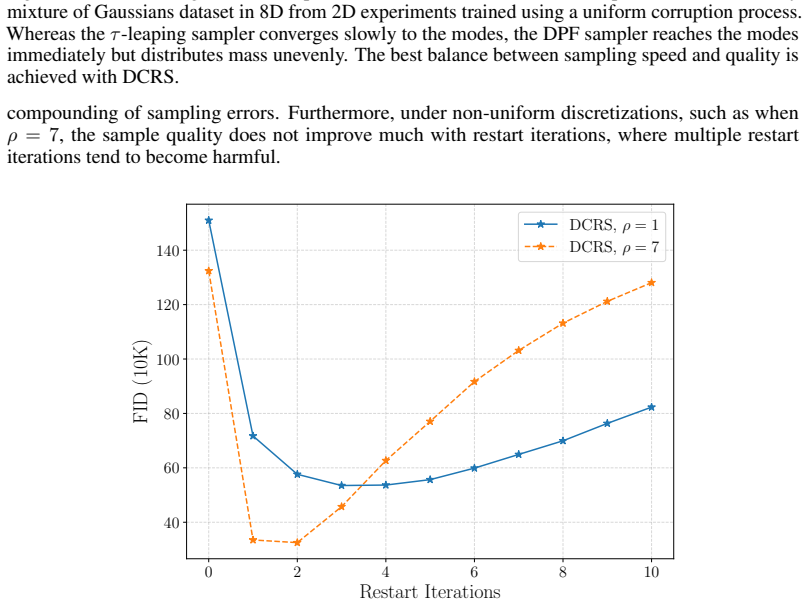
and Zhang et al. [14]. All experiments are conducted on 8 NVIDIA A6000 GPUs. To enable comparisons between sampling algorithms, each sample is generated starting from a unique fixed seed. D.4.2 Effect of Multiple Restart Iterations We provide results using a time discretization of8 steps and a restart window of[tmin,max] = [0.7,0.8] with 3 discretization ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.