Traceable Knowledge Graph Reasoning Enables LLM-Assisted Decision Support for Industrial VOCs in the Steel Industry
Pith reviewed 2026-06-29 17:37 UTC · model grok-4.3
The pith
A traceable knowledge graph from steel-industry VOCs literature powers a multi-agent LLM system with 96.93 percent precision on specialized questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
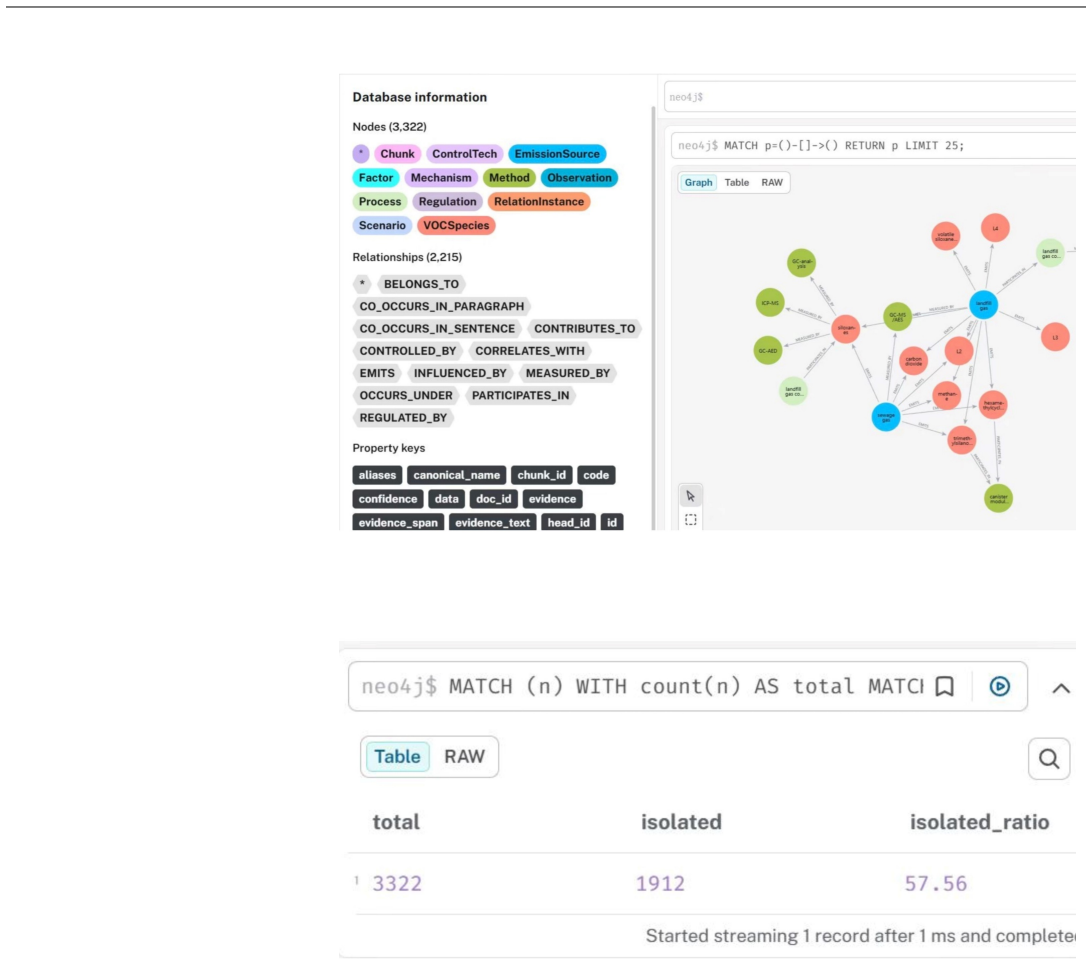
Chat-ISV parses a curated steel-industry VOCs literature corpus, builds a Neo4j knowledge graph containing 27180 nodes and 81779 semantic edges, applies chunk-centered topology optimization to cut isolated nodes from 57 percent to 4.08 percent, and combines this graph with prompt-constrained extraction, multi-agent routing, source-backtracking, local literature retrieval, and subgraph visualization to reach 96.93 percent precision, 72.63 percent recall, and an F1-score of 0.830 with a mean expert score of 1.69 out of 2.00.
What carries the argument
The Neo4j knowledge graph with chunk-centered topology optimization that supplies traceable, queryable links among processes, pollutants, and control technologies to constrain LLM outputs.
If this is right
- Fragmented environmental-engineering literature becomes queryable and decision-support-oriented knowledge.
- Source-backtracking retrieval lowers hallucination risk on low-frequency industrial questions.
- Interactive subgraph visualization supports pollution-control decision making.
- The same pipeline offers a scalable environmental-informatics paradigm for reliable LLM use in other specialized domains.
Where Pith is reading between the lines
- The same graph-construction plus topology-optimization steps could be applied to VOCs or emissions data in other heavy industries such as petrochemicals or cement.
- Adding real-time sensor or regulatory-update feeds into the graph might turn the system into a live monitoring aid rather than a static literature tool.
- If the precision holds on out-of-corpus queries, the approach could serve as a template for regulated industries that must justify AI-assisted decisions with traceable evidence.
Load-bearing premise
The curated steel-industry VOCs literature corpus is representative and complete enough that the resulting knowledge graph captures the necessary process, pollutant, and control-technology relationships without critical omissions or extraction errors.
What would settle it
Running the system on a fresh set of steel-industry VOCs papers published after the corpus was built and checking whether the answers remain accurate or begin to hallucinate facts that the new papers contradict.
Figures







read the original abstract
Key knowledge for steel-industry volatile organic compounds (VOCs) governance is scattered across unstructured scientific literature, making it difficult to integrate process, pollutant, and control-technology evidence and increasing the risk of hallucination when general large language models (LLMs) answer low-frequency industrial questions. Here we developed Chat-ISV, a knowledge graph (KG) enhanced multi-agent Q&A system that parses a curated steel-industry VOCs literature corpus, constructs a Neo4j KG with 27180 nodes and 81779 semantic edges, and combines prompt-constrained extraction, chunk-centered topology optimization, multi-agent routing, source-backtracking retrieval, local literature retrieval, open-domain knowledge access, and interactive subgraph visualization. Benchmark tests and 400 expert blind evaluations showed that topology optimization reduced isolated nodes from 57% to 4.08% and that Chat-ISV achieved high factual reliability, with 96.93% precision, 72.63% recall, an F1-score of 0.830, and a mean score of 1.69/2.00. By converting fragmented environmental-engineering literature into traceable, queryable, and decision-support-oriented knowledge, Chat-ISV establishes a scalable environmental-informatics paradigm for reliable LLM deployment and intelligent pollution-control decision support in specialized industrial domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Chat-ISV, a knowledge-graph-enhanced multi-agent Q&A system for steel-industry VOCs governance. It parses a curated literature corpus to build a Neo4j KG (27,180 nodes, 81,779 edges), applies chunk-centered topology optimization, multi-agent routing, source-backtracking retrieval, and interactive visualization. Benchmark tests and 400 expert blind evaluations are reported to show topology optimization reducing isolated nodes from 57% to 4.08%, with Chat-ISV achieving 96.93% precision, 72.63% recall, F1=0.830, and mean expert score 1.69/2.00, positioning the system as a scalable paradigm for traceable, hallucination-resistant decision support in specialized industrial domains.
Significance. If the corpus completeness and evaluation rigor hold, the work demonstrates a concrete, traceable KG+LLM pipeline that converts fragmented environmental-engineering literature into queryable decision-support knowledge, with measurable gains in factual reliability and reduced isolation in the graph. The combination of topology optimization, multi-agent routing, and expert blind validation provides a reproducible template for domain-specific LLM deployment where general models risk hallucination on low-frequency industrial questions.
major comments (3)
- [Abstract and Methods (corpus construction)] The central performance claims (96.93% precision, 72.63% recall, F1=0.830, expert mean 1.69/2) rest on an unverified assumption that the curated steel-industry VOCs literature corpus is representative and complete. No protocol is supplied for source selection, deduplication, coverage audit against known review papers, or post-extraction error sampling; if recent control-technology studies or regional literature are systematically omitted, both the topology-optimization result and the Q&A metrics become conditional on an untested completeness assumption.
- [Abstract and Evaluation section] Evaluation protocol details are absent: the abstract states specific performance numbers from 400 expert blind evaluations and topology optimization, but provides no information on how recall was measured against a gold standard, inter-rater agreement, question sampling strategy, or blinding procedure. This directly undermines the factual-reliability claims.
- [KG construction and topology optimization] The claim that the KG 'faithfully encodes the domain' for decision support is load-bearing, yet the manuscript supplies no quantitative validation (e.g., coverage sampling against external review papers or expert audit of extracted relations) that would confirm absence of critical gaps in process-pollutant-control relationships.
minor comments (2)
- [Results] Clarify the exact definition and measurement of 'isolated nodes' before and after topology optimization; the 57% to 4.08% reduction is a key result but the metric is not defined in the provided text.
- [System architecture] The multi-agent routing and source-backtracking mechanisms are described at a high level; a diagram or pseudocode would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and will revise the manuscript accordingly to provide the requested protocols and validations.
read point-by-point responses
-
Referee: [Abstract and Methods (corpus construction)] The central performance claims (96.93% precision, 72.63% recall, F1=0.830, expert mean 1.69/2) rest on an unverified assumption that the curated steel-industry VOCs literature corpus is representative and complete. No protocol is supplied for source selection, deduplication, coverage audit against known review papers, or post-extraction error sampling; if recent control-technology studies or regional literature are systematically omitted, both the topology-optimization result and the Q&A metrics become conditional on an untested completeness assumption.
Authors: We agree that the manuscript does not supply a full protocol for corpus construction. The original text refers only to a 'curated' corpus without detailing selection criteria or audits. In the revised manuscript we will add a dedicated Methods subsection describing the literature search strategy (databases, keywords, date range), inclusion/exclusion criteria, deduplication procedure, and any coverage or error-sampling steps performed. This addition will allow readers to evaluate the representativeness assumption directly. revision: yes
-
Referee: [Abstract and Evaluation section] Evaluation protocol details are absent: the abstract states specific performance numbers from 400 expert blind evaluations and topology optimization, but provides no information on how recall was measured against a gold standard, inter-rater agreement, question sampling strategy, or blinding procedure. This directly undermines the factual-reliability claims.
Authors: The evaluation details were condensed in the initial submission. We will expand the Evaluation section to specify the question sampling strategy, the construction of the gold-standard answers used for recall, the blinding procedure applied to the 400 expert evaluations, and inter-rater agreement metrics. These additions will make the reported precision, recall, and expert scores fully reproducible. revision: yes
-
Referee: [KG construction and topology optimization] The claim that the KG 'faithfully encodes the domain' for decision support is load-bearing, yet the manuscript supplies no quantitative validation (e.g., coverage sampling against external review papers or expert audit of extracted relations) that would confirm absence of critical gaps in process-pollutant-control relationships.
Authors: We acknowledge that the manuscript provides no external quantitative validation of KG coverage beyond the internal topology-optimization metrics. In the revision we will add a validation subsection that reports coverage sampling against external review papers and/or expert audit of a random subset of extracted relations, confirming the absence or presence of gaps in process-pollutant-control relationships. revision: yes
Circularity Check
No significant circularity; claims rest on external expert validation
full rationale
The manuscript presents an applied KG+LLM system whose headline metrics (precision 96.93%, recall 72.63%, expert mean 1.69/2.00 from 400 blind evaluations) are obtained from independent human raters and node-isolation statistics. No equations, fitted parameters, or self-referential definitions appear in the abstract or described derivation. The single load-bearing assumption (corpus representativeness) is an empirical completeness claim, not a definitional or self-citation loop that forces the reported performance numbers. Therefore the result does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The curated steel-industry VOCs literature corpus is representative and complete enough that the resulting knowledge graph captures the necessary process, pollutant, and control-technology relationships without critical omissions or extraction errors.
Reference graph
Works this paper leans on
-
[1]
Agrawal et al
A. Agrawal et al. Large language models for knowledge graph extraction from scientific literature.Patterns, 5(1):100913, 2024
2024
-
[2]
X. Bai, S. He, Y. Li, Y. Xie, X. Zhang, W. Du, and J.-R. Li. Construction of a knowledge graph for framework material enabled by large language models and its application.npj Computational Materials, 11:51, 2025
2025
-
[3]
A. M. Bran et al. Chemcrow: Augmenting large-language models with chemistry tools.Nature Machine Intelligence, 6(5):481–487, 2024
2024
-
[4]
Chen et al
Z. Chen et al. Multi-pollutant collaborative control technologies in the iron and steel sintering process: Status and perspectives.Sci. Total Environ., 908:168291, 2024
2024
-
[5]
Y. Ding. Dataset for Chat-ISV: A knowledge graph-enhanced large language model for question answering on VOC emission control in the steel industry. Zenodo, 2026
2026
-
[6]
Dreger, K
M. Dreger, K. Malek, and M. Eikerling. Large language models for knowledge graph extraction from tables in materials science.Digital Discovery, 4:1221, 2025
2025
-
[7]
Y. Duan, Y. Tian, S. Ghosh, V. Venugopal, J. Chen, and E. A. Olivetti. Llm-empowered literature mining for material substitution studies in sustainable concrete.RESOURCES CONSER V ATION AND RECYCLING, 221:108379, 2025
2025
-
[8]
Edge et al
D. Edge et al. From local to global: A graph RAG approach to query-focused summarization.arXiv, 2024
2024
-
[9]
Gao et al
Y. Gao et al. Retrieval-augmented generation for large language models: A survey.arXiv, 2023
2023
-
[10]
X. He, Y. Tian, Y. Sun, N. V. Chawla, T. Laurent, Y. LeCun, X. Bresson, and B. Hooi. G-retriever: Retrieval-augmented generation for textual graph understanding and question answering.Advances in Neural Information Processing Systems, 37, 2024
2024
-
[11]
Hogan et al
A. Hogan et al. Knowledge graphs.ACM Computing Surveys, 54(4):1–37, 2021
2021
-
[12]
Huang et al
L. Huang et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.arXiv, 2023
2023
-
[13]
Jafarzadeh, F
P. Jafarzadeh, F. Ensan, M. A. A. Alavi, and F. Zarrinkalam. A knowledge graph embedding model for answering factoid entity questions.ACM Transactions on Information Systems, 43(2):Article 34, 2024
2024
-
[14]
S. Ji, S. Pan, E. Cambria, P. Marttinen, and P. S. Yu. A survey on knowledge graphs: Representation, acquisition, and applications.IEEE Transactions on Neural Networks and Learning Systems, 33(2):494–514, 2022
2022
-
[15]
Ji et al
Z. Ji et al. Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12):1–38, 2023
2023
-
[16]
Kumar, F
A. Kumar, F. Nazemi, H. Kodamana, M. Ramteke, and B. R. Bakshi. A large language model-based framework to retrieve life cycle inventory and environmental impact data from scientific literature.ENVIRONMENTAL SCIENCE & TECHNOLOGY, 59(42):22533–22543, 2025. 33/36
2025
-
[17]
Y. Lan, Z. Hu, L. Wang, Y. Wang, D. Ye, P. Zhao, E.-P. Lim, H. Xiong, and H. Wang. LLM-based agent society investigation: Collaboration and confrontation in Avalon gameplay. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 100–113, 2024
2024
-
[18]
Lewis et al
P. Lewis et al. Retrieval-augmented generation for knowledge-intensive NLP tasks.Advances in Neural Information Processing Systems, 33:9459–9474, 2020
2020
-
[19]
S. Li, J. Liao, Z. Zhang, and G. Xu. Catalytic decomposition of methane over Fe2O3-Al2O3 catalysts with high iron contents and at high CH4 space velocities. Resources Chemicals and Materials, 4(4):100123, 2025
2025
-
[20]
Y. Li, D. Song, Y. Tian, H. Wang, C. Zhou, and S. Zhang. A framework of knowledge graph-enhanced large language model based on global planning.IEEE Transactions on Knowledge and Data Engineering, 38(2):736–748, 2026
2026
-
[21]
M. Lin, T. Wu, and K. Xie. Low-carbon scheduling for power-hydrogen integrated energy system using large language model enhanced deep reinforcement learning.IEEE Transactions on Sustainable Energy, 2026
2026
-
[22]
Z. Lin, J. Chen, Y. Fang, S.-h. Deng, H. Li, Y. Yang, and J. Yao. Rapidly tailor metal–organic frameworks for arsenate removal using graph convolutional neural networks.Separation and Purification Technology, 354:129334, 2025
2025
-
[23]
Z. Lin, D. Ren, K. Ran, J. Sun, S. Yu, X. Bai, X. Huang, H. He, P. Pan, Y. Fang, Z. Li, H. Li, and J. Yao. Reshaping MOFs synthesis conditions mining with a dynamic multi-agents framework of large language model.Transactions of Materials Research, 2(1):100176, 2026
2026
-
[24]
Liu et al
Z. Liu et al. Characterizing the emission behaviors of cumulative VOCs from automotive solvent-based paint sludge.Journal of Environmental Management, 317:115369, 2022
2022
-
[25]
Miret et al
S. Miret et al. From text to insight: Large language models for chemical data extraction.Chemical Society Reviews, 54(3):1125–1150, 2025
2025
-
[26]
Ouyang et al
L. Ouyang et al. Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022
2022
-
[27]
S. Pan, L. Luo, Y. Wang, C. Chen, J. Wang, and X. Wu. Unifying large language models and knowledge graphs: A roadmap.IEEE Transactions on Knowledge and Data Engineering, 36(8):3534–3554, 2024
2024
-
[28]
C. Su, Y. Guo, H. Chen, J. Zou, Z. Zeng, and L. Li. VOCs adsorption of resin-based activated carbon and bamboo char: porous characterization and nitrogen-doped effect.Colloids and Surfaces A: Physicochemical and Engineering Aspects, 601:124983, 2020
2020
-
[29]
C. Su, Y. Guo, L. Yu, J. Zou, Z. Zeng, and L. Li. Insight into specific surface area, microporosity and N, P co-doping of porous carbon materials in the acetone adsorption.Materials Chemistry and Physics, 258:123930, 2020
2020
-
[30]
C. Su, W. Jiang, Y. Guo, G. Yi, Z. Li, and H. Li. Rational molecular design of P-doped porous carbon material for the VOCs adsorption.Chinese Journal of Chemical Engineering, 79:155–163, 2025. 34/36
2025
-
[31]
J. Sun, C. Xu, L. Tang, S. Wang, C. Lin, Y. Gong, L. M. Ni, H.-Y. Shum, and J. Guo. Think-on-graph: Deep and responsible reasoning of large language model on knowledge graph.International Conference on Learning Representations, 2024
2024
-
[32]
K. Sun, Z. Zhao, H. Yang, J. Zhang, and G. Q. Huang. Curriculum engineering: Structured learning for large language models (LLMs) through curriculum based retrieval.IEEE Transactions on Industrial Informatics, 22(1):555–566, 2026
2026
-
[33]
Multi-Agent Collaboration: Harnessing the Power of Intelligent LLM Agents
Y. Talebirad and A. Nadiri. Multi-agent collaboration: Harnessing the power of intelligent LLM agents.arXiv preprint arXiv:2306.03314, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Tang et al
L. Tang et al. Characteristics and health risks of volatile organic compounds emitted from a typical iron and steel industry in north china.Environ. Res., 212:113337, 2022
2022
-
[35]
Taylor et al
R. Taylor et al. Galactica: A large language model for science.arXiv, 2022
2022
-
[36]
F. Wang, D. Shi, J. Aguilar, X. Cui, J. Jiang, L. Shen, and M. Li. Llm-kgmqa: large language model-augmented multi-hop question-answering system based on knowledge graph in medical field.KNOWLEDGE AND INFORMATION SYSTEMS, 67(8):6461–6503, 2025
2025
-
[37]
H.-T. Wang, X. Bai, Z. Zheng, X. Zhang, R. Jin, H.-T. An, Z.-H. Xie, X.-L. Lv, and J.-R. Li. Chat-rfb: A flow battery chat system leveraging knowledge graphs and large language models.Digital Discovery, 5:1401–1410, 2026
2026
-
[38]
Wang et al
L. Wang et al. A survey on large language model based autonomous agents. Frontiers of Computer Science, 18(6):186345, 2024
2024
-
[39]
Y. Wang, N. Lipka, R. A. Rossi, A. Siu, R. Zhang, and T. Derr. Knowledge graph prompting for multi-document question answering. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19206–19214, 2024
2024
-
[40]
A. D. White et al. The future of chemistry is language.Nature Reviews Chemistry, 7(7):457–458, 2023
2023
-
[41]
Wu et al
Q. Wu et al. Autogen: Enabling next-gen LLM applications via multi-agent conversation.arXiv, 2023
2023
-
[42]
Wu et al
X. Wu et al. Augmented and programmatically optimized llm prompts reduce chemical hallucinations.Journal of Chemical Information and Modeling, 2025. Published online ahead of print
2025
-
[43]
J. Xu, H. Zhang, H. Zhang, J. Lu, and G. Xiao. Chattf: A knowledge graph-enhanced intelligent q&a system for mitigating factuality hallucinations in traditional folklore.IEEE ACCESS, 12:162638–162650, 2024
2024
-
[44]
S. Xu, L. Li, Z. Li, Y. Yao, F. Xu, Z. Chen, Q. Lu, and H. Tong. On the vulnerability of graph learning-based collaborative filtering.ACM Transactions on Information Systems, 41(4):Article 87, 2023
2023
-
[45]
Yao et al
S. Yao et al. React: Synergizing reasoning and acting in language models. In International Conference on Learning Representations, 2023
2023
-
[46]
Zhang, L
J. Zhang, L. Sang, Y. Xu, and H. Sun. Networked multiagent-based safe reinforcement learning for low-carbon demand management in distribution networks.IEEE Transactions on Sustainable Energy, 15(3):1528–1545, July 2024. 35/36
2024
-
[47]
Zhang et al
X. Zhang et al. Recent advances in the catalytic oxidation of volatile organic compounds: A review based on pollutant sorts and sources.Chemical Reviews, 116(6):3622–3673, 2016
2016
-
[48]
Zhang, X
Y. Zhang, X. Bo, Y. Zhao, C. P. Nielsen, J. Zhang, S. Zhang, X. Li, B. Zhao, G. Geng, and Q. Zhang. Benefits of current and future policies on emissions of china’s coal-fired power sector indicated by continuous emission monitoring. Environmental Pollution, 251:415–424, 2019
2019
-
[49]
Zhang et al
Y. Zhang et al. Emission characteristics and synergistic control technologies of volatile organic compounds in typical industrial processes.Journal of Hazardous Materials, 424:127645, 2022
2022
-
[50]
Zheng and G
P. Zheng and G. Xu. Expert systems: Grounding cross-disciplinary LLMs in reality.Resources Chemicals and Materials, 5(1):100164, 2026
2026
-
[51]
Zheng et al
Z. Zheng et al. Chatgpt in chemical research and education.ACS Central Science, 9(8):1459–1466, 2023
2023
-
[52]
B. Zhou, X. Li, T. Liu, K. Xu, W. Liu, and J. Bao. Causalkgpt: Industrial structure causal knowledge-enhanced large language model for cause analysis of quality problems in aerospace product manufacturing.Advanced Engineering Informatics, 59:102333, 2024
2024
-
[53]
Y. Zhu, X. Wang, J. Chen, S. Qiao, Y. Ou, Y. Yao, S. Deng, H. Chen, and N. Zhang. Llms for knowledge graph construction and reasoning: recent capabilities and future opportunities.WORLD WIDE WEB-INTERNET AND WEB INFORMATION SYSTEMS, 27(5):58, 2024. 36/36
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.